支持高效查询检索的大数据资源描述模型
2014-09-18张文燚项连志王小芳
张文燚, 项连志, 王小芳
(1. 哈尔滨工程大学 电子政务建模仿真国家工程实验室,北京 100037; 2. 哈尔滨工程大学 计算机科学与技术学院,黑龙江哈尔滨 150001)
大数据的多样性(Variety)决定了组成大数据各种不同来源的数据资源之间不可避免地存在着多种形式的结构差异和语义冲突[1]。因此,建立一种能够屏蔽结构差异和语义冲突的大数据资源统一描述模型,使之以统一的查询接口形式,支持面向完整大数据资源的高效查询检索,对于推动大数据查询分析应用发展有着重要的理论贡献和实用价值。
1994年,Gupta P等以DataJoiner的形式给出了一个面向异构分布关系数据资源的统一访问视图[2],1995年,M. J. Carey等通过扩展ODMG-93对象模型,给出了一种为不同来源的异构分布数据资源,提供面向对象的统一视图的Garlic方法[3]。DataJoiner和Garlic主要研究屏蔽结构差异的技术方法,不能有效解决语义冲突屏蔽问题。Michael Siegel等于1991年给出了一种基于规则的语义规约方法,支持协调不同来源的数据资源的语义冲突[4],这种语义规约方法虽然具有较高的形式化水平,但它并不提供对数据资源统一描述的支持。1998年,由ORA LASSILA以语义元数据形式给出的资源描述模型RDF,可以有效地用于支持内部大规模、分布式的web数据资源统一描述和查询导航[5]。2003年,Akiyoshi MATONO给出了一种通过抽取RDF和RDF模式的路径表达式形成按字典排序后缀数组,支持高效数据资源检索的索引模式[6]。2006年,YounHee Kim等进一步给出了基于结构的路径索引和关键字索引等两种RDF和RDF模式索引技术[7],其关键字索引技术发展了1996年Ycmg Kyu Lee等人给出的基于k-ary的关键字倒排索引技术[8],使得基于关键字搜索返回的是相关资源而不是整个文档或标记,从而使大规模、分布式数据资源查询检索的效率大幅提高。但是,由于RDF的形式化水平不高,且它没有给出能够支持屏蔽结构差异和语义冲突的描述形式,因而它作为数据资源统一描述模型的普适性无法准确判定,同时也无法作为支持高效查询检索的大数据资源描述模型直接应用。
可见,建立一种高度形式化的大数据资源统一描述和查询接口模型,在大数据应用技术发展中具有基础性地位。拟基于大数据分区管理模型[9]扩展其痕迹属性,用以构建差异化的大数据信息资源组织模式和支持差异屏蔽的大数据字典;借助由痕迹属性表达的后缀路径,并结合大数据字典建立支持大数据资源高效查询检索的倒排索引;从而建立一种支持高效查询检索的、完全形式化的大数据资源描述模型。
1 大数据分区管理模型及其扩展
其中,场景sT={st1,st2,...|t1,t2,...∈T}是基于活动痕迹st、实体实例消息me(o)和消息m(o)定义的。
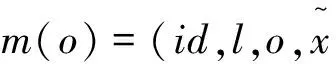

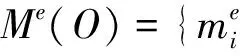
1.1 面向场景的切片规则扩展
为了更好地表达大数据信息资源组织模式,需分别面向活动场景和实体实例标识的切片规则扩展相应的痕迹属性。本小节借助实体实例消息的生成时间、空间和宿主等痕迹属性,形成3种基于活动场景的切片规则,同时扩展大数据分区管理模型中的一般化子场景为时间子场景、空间子场景和宿主子场景。

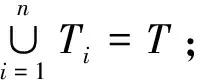
2)Ti∩Tj=∅,i≠j。
称sTi={stj|tj∈Ti}为场景sT的时间子场景。

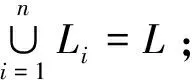
2)Li∩Lj=∅,i≠j。
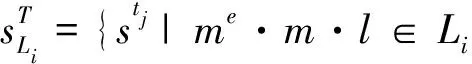
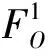
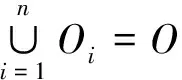
2)Oi∩Oj=∅,i≠j。

1.2 面向实体实例标识的切片规则扩展

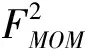
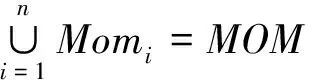
2)Momi∩Momj=∅,i≠j。


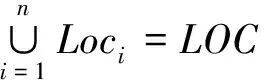
2)Loci∩Locj=∅,i≠j。
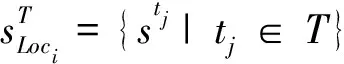
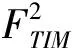
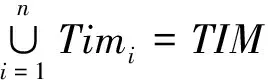
2)Timi∩Timj=∅,i≠j。

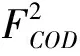
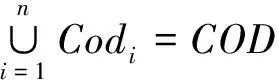
2)Codi∩Codj=∅,i≠j。

1.3 面向场景的分配规则扩展
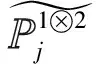
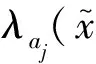
2 差异化大数据信息资源组织模式
通过引入扩展项泛函刻画差异化的大数据资源,结合扩展的大数据分区管理模型定义了差异化的大数据资源组织结构及其构造运算,并由此形成支持大数据资源差异屏蔽的大数据字典。
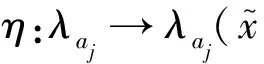
性质1对于扩展项泛函η,有以下等价关系:
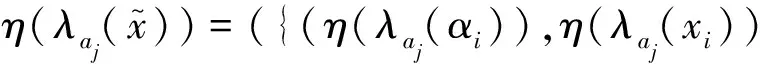

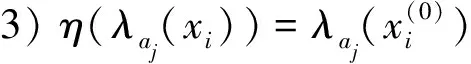
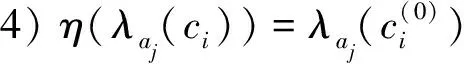
5)η(λaj(f))=λaj(f(0))。
证明略。
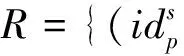
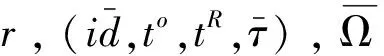
定义14(属性值r)称形如r=(α′,x′) =(η(λaj(α)),η(λaj(x)))的二元组为差异化的属性值(方言),其中α′为名称项,x′为值项,aj∈A为分配主体,A为分配主体集合。一般地,称rs=(α,x)为标准属性值。
在大数据资源组织结构中除了表达实体实例状态的属性值之外,还存在着一类刻画资源组织结构标识的元属性值(αm,xm),包括:
下面就大数据资源组织结构的构造过程展开讨论,该构造过程也为刻画大数据资源检索的析构过程提供了研究基础。
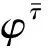
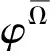
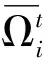
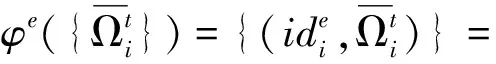
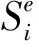

定义19(属性值关系≤d)设R为属性值r的集合,≤l为字典序,≤d为R上的二元关系, ≤d定义如下:对于任意ri=(αi,xi),rj=(αj,xj)∈R,如果满足以下任意一个条件:
1)αi 2)αi=αj,xi≤lxj 则ri≤drj。 基于差异化大数据信息资源组织模式讨论大数据资源高效检索机制。首先,定义了大数据资源检索问题,并通过刻画析构运算及其复合运算,给出了一般化地大数据资源检索运算;其次,探讨了两种主要的大数据资源检索模式:遍历检索模式和层次检索模式。同时,基于大数据字典和后缀路径形成支持大数据资源高效查询检索的倒排检索模式,并将其与遍历和层次检索模式进行收敛速度的对比分析。最后,给出了方言模式下的统一查询机制。 定义22(索引匹配∝cδ)设cδ为索引,对于给定的索引项γ=(αc,xc),若存在(γk,Sk)∈cδ,使得γ≈γk,≈为索引项等关系,则称γ在索引cδ上匹配Sk,记为γγcδSk。 索引项等关系≈在不同索引类型下为不同的关系,当cδ为属性值或多结构化状态关系标识索引时,≈为取值=;当cδ为场景标识或切片标识索引时,≈为条件等关系。 显然,析构索引是影响析构运算收敛速度的关键要素,依据析构运算各级索引的不同,一般有以下2种检索模式: 上述检索模式是逐级析构展开的,下面讨论基于倒排索引的一维倒排检索模式。倒排索引是通过引入类似于RDF路径表达式后缀数组[6]的后缀路径,并结合大数据字典形成的。 定义29(检索运算成本ρ(φ))设φ(R,Λ)为检索运算,R为大数据资源组织结构,Λ为检索输入,则检索成本ρ(φ)=ρ*(φ)+ρ⊙(φ),其中ρ*(φ)为索引匹配成本,ρ⊙(φ)为遍历成本。 不重点讨论由于索引匹配算法导致的成本差异,假设所有索引匹配均采用二分查找匹配的方法完成。在实际过程中,可通过算法优化使得索引匹配产生不低于二分查找匹配的收敛效率。 定理1 对于大数据资源检索问题Q(Λ),大数据资源倒排检索运算φcδ su(R,Λ)比φ(R,Λ)更高效地支持大数据资源检索。 情形1:当φ(R,Λ)为遍历运算时,检索成本ρ1(φ)>ρ(φcδ su)。 情形2:当φ(R,Λ)为层次检索运算时,检索成本ρ2(φ)>ρ(φcδ su)。 由此可知,遍历检索的收敛阶为1/nSe,层次检索的收敛阶为1/nSe,倒排检索的收敛阶为1/lb(nSe),显然,基于倒排索引的倒排检索模式要远优于遍历检索模式和层次检索模式。 本小节把大数据资源描述模型应用于国家住房信息系统,并基于大数据分区管理模型,给出了其差异化的大数据资源组织结构和支持资源高效检索的大数据资源倒排索引,以及方言模式下的统一查询机制。国家住房信息系统要统一管理全国近300个城市的个人或企事业单位的房产信息,并提供全国房产信息的查询检索服务。 1)基于大数据分区管理模型,面向活动场景,扩展实体实例消息的生成时间、空间、宿主等痕迹属性用于表达切片规则;面向实体实例标识,扩展实体实例的产出母体、产出地点、产出时间、批量编码等痕迹属性用于表达切片规则;基于扩展后切片规则形成的大数据切片集和分配主体集,扩展了分配规则,从而形成了支持大数据资源分布式定位描述的基础。 2)通过引入扩展项泛函刻画了由分配主体导致的差异化大数据资源,并结合扩展的大数据分区管理模型,给出了差异化大数据信息资源组织模式和支持差异屏蔽的大数据字典。 3)基于差异化信息资源组织模式,给出了大数据资源倒排检索模式,并证明了其远比遍历检索模式和层次检索模式高效。 4)把大数据资源描述模型应用于国家住房信息系统,说明了大数据资源描述模型对大数据资源差异屏蔽、高效检索和方言模式下统一查询的有效支持。 参考文献: [1]DUMBILL E. Planning for big data [M]. Sebastopol:O' Reilly Media, Inc.,2012:9-16. [2]GUPTA P, LIN E. Datajoiner: a practical approach to multi-database access[C]//Proceedings of the Third International Conference on Parallel and Distributed Information Systems. Austin, USA, 1994: 264. [3]CAREY M J, HAAS L M, SCHWARZ P M, et al. Towards heterogeneous multimedia information systems: the garlic approach[C]//Fifth International Workshop on Research Issues in Data Engineering. Taipei, 1995: 124-131. [4]SIEGEL M D, MADNICK S E. A metadata approach to resolving semantic conflicts[C]//Proceedings of the 17th International Conference on Very Large Database Systems. Barcelona, Spain, 1991: 133-145. [5]LASSILA O, SWICK R R.WD-rdf-syntax-19980216, Resource Description Framework (RDF) model and syntax specification [S]. Boston:W3C,1998. [6]MATONO A, AMAGASA T, YOSHIKAWA M, et al. An indexing scheme for RDF and RDF schema based on suffix arrays[C]//SWDB. Berlin, Germany, 2003: 151-168. [7]KIM Y H, KIM B G, LIM H C. The index organizations for RDF and RDF schema[C]//The 8th International Conference of Advanced Communication Technology . Dublin, Ireland , 2006, 3: 1871-1874. [8]LEE Y K, YOO S J, Yoon K, et al. Index structures for structured documents[C]//Proceedings of the First ACM International Conference on Digital Libraries. Bethesda,USA, 1996: 91-99. [9]张文燚, 项连志, 王小芳. 大数据分区管理模型及其应用研究[J]. 哈尔滨工程大学学报, 2014,35(3):353-360. ZHANG Wenyi, XIANG Lianzhi, WANG Xiaofang. Big data partition management model and its application research[J].Journal of Harbin Engineering University, 2014,35(3):353-360.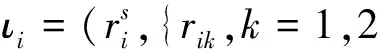
3 大数据资源高效检索机制
3.1 大数据资源检索问题和检索运算

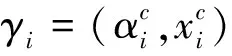

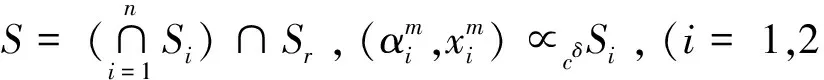
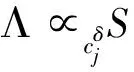
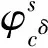
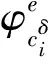


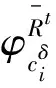
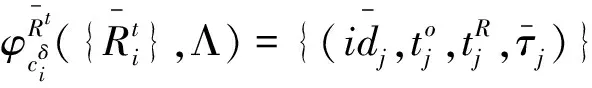
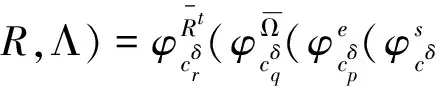
3.2 大数据资源检索模式
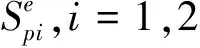
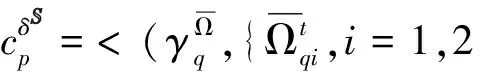
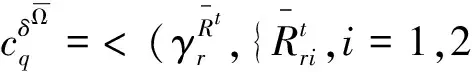



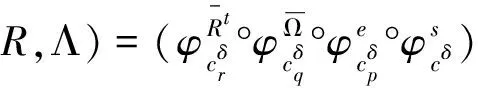

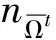


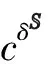
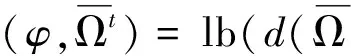

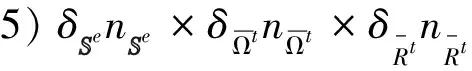

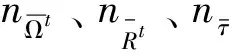
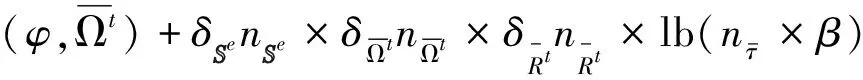

4 应用
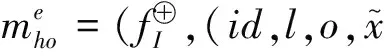
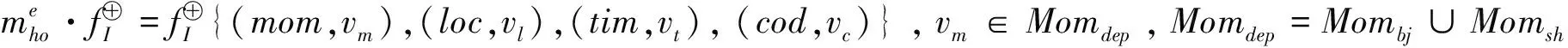
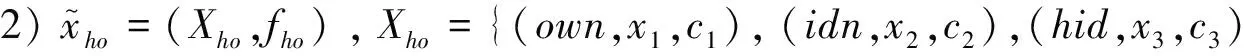
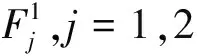
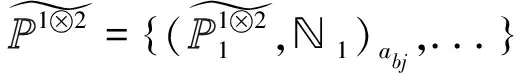
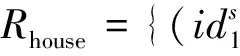
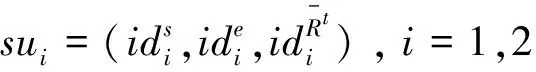
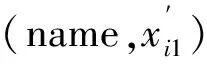
5 结束语
