基于Windows平台的双通道回声抵消系统
2014-08-23付中华
刘 扬,付中华,唐 玲
(西北工业大学计算机学院,陕西 西安 710129)
0 引言
随着互联网和多媒体技术的日益进步和普及,多终端、多通道的语音通信产品渐渐走入市场,在各行各业中得到广泛的应用[1]。双端语音通信过程中,远端语音信号传输到近端后从扬声器播放,经近端房间环境的反射后形成回声被本地麦克风接收,随即和近端语音信号一起传回远端并被远端扬声器播放[2],从而对语音通信质量造成严重影响。因此,如何消除或者抑制回声便成为了实时语音通信中的一个研究热点。回声抵消(Acoustic Echo Cancelation,AEC)的原理是估计近端房间的声音反射环境,通过这个估计的反射环境得到近端实际回声的模拟信号,最后由本地回声信号减去这一模拟信号,达到抵消回声的目的[3]。回声抵消系统不仅在手机等移动通讯设备、医疗监测设备和网络通信中有着重要的应用,其中涉及的关键技术还可以在视频会议、IP电话、远程教学等领域中得到广泛的应用。
随着数字信号处理技术特别是自适应滤波理论的不断成熟与完善,回声抵消技术逐渐从实验室走入市场,世界上第一台商用回声抵消器在20世纪70年代问世。经过多年的研究与应用,回声抵消技术经历了由单通道到多通道、低采样率到高采样率的更新与发展[4-5]。双通道(立体声)情况下,近端自适应滤波器的2路输入信号之间具有高度的相关性,这将导致自适应滤波器结果的“非唯一性”问题,即近端自适应滤波器模拟得到的抽样响应结果有无穷多个,从而使其不能准确模拟远端房间的实际抽样响应,降低回声抵消效率[6-8]。随着研究的深入,各种去相关方法也被相继提出[9],通道间去相关的难点在于如何保证滤波器快速收敛同时保持立体声像质量。本文设计一个基于Windows平台的双通道回声抵消系统,这个系统采用一种较新的通道间去相关方法,该方法基于重采样技术,具有较好的有效性和较小的计算量,实验表明使用这种去相关技术的系统具有较好的回声抵消效果。
1 系统设计
1.1 基本原理
图1描述了一个双端点对点双通道通话模型:近端网络接口接收远端房间麦克风采集的声音信号x1(n)、x2(n),这个通道的信号经过近端房间环境的各种反射和衰减之后形成回声信号d1(n)、d2(n)。将x1(n)、x2(n)输入回声抵消自适应滤波器得到模拟近端房间反射信号y1(n)、y2(n),由d1(n)、d2(n)和y1(n)、y2(n)相减得到残余回声信号e1(n)、e2(n),最后通过近端网络发送接口将e1(n)、e2(n)发送至远端。

图1 双通道回声抵消原理示意图
1.2 总体架构
整个软件系统的结构组成如图2所示,系统由4个部分组成:音频驱动模块、重采样器、回声抵消模块、Socket网络通信模块。
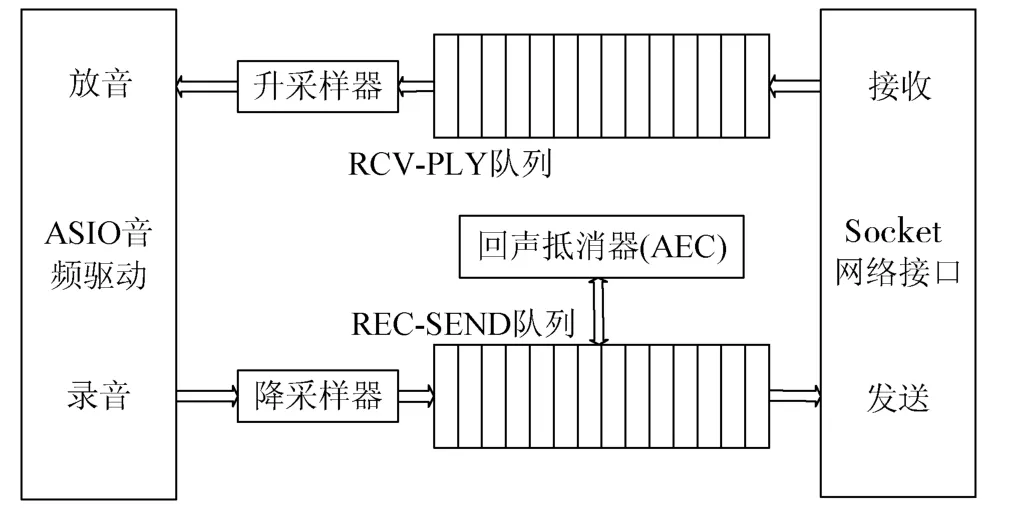
图2 系统架构图
图2中箭头所指方向为音频流输入输出的方向:系统中的接收和录放音数据分别存放于2个循环缓冲队列中,RCV-PLY(接收-播放)缓冲队列存放的是从网络接收到的低采样率立体声数据,经过升采样器之后输入音频驱动接口ASIO放音接口进行播放;同时ASIO录音端口不间断地将本地录音数据存放到REC-SEND(录音-发送)缓冲队列中,同时网络发送端口将这一缓冲区内的数据发送至远端。
1.3 音频驱动模块
音频输入输出模块是系统和声卡的接口,负责系统的双通道立体声录放。这里使用的音频流输入输出接口 (Audio Stream Input Output,ASIO)支持44100Hz和48000Hz采样率的声音信号。ASIO接口绕过Windows操作系统对声卡I/O的控制,直接驱动PC声卡,从而具有较高的响应速度和较低的录放延迟[11]。此外ASIO技术还支持多通道录放音功能。本软件系统设置为2个放音通道和2个录音通道,分别对应2个扬声器的放音输出和2个麦克风的录音输入。
系统将ASIO的初始化、启动录放、停止录放、释放资源操作封装到4个函数中。系统开始运行之后ASIO随即进行初始化:设定录放音通道数、一次录放音的帧长、音频I/O采样率等。ASIO启动录放后将在连续地录取近端声音的同时播放从远端接收的声音数据,由于ASIO内部录音缓冲切换的速度极快,近端的录音数据块必须及时保存;同时接收的远端声音数据需要被保存到一个声音接收缓存中,这个缓存的长度和初始指针位置必须严格设定,避免ASIO放音时由于网络拥塞等原因导致的话音断续。
1.4 网络通信模块
网络通信模块负责近端和远端之间的数据交互。其主要任务就是将降采样之后的近端ASIO录音数据存放到发送队列,然后发送到远端;同时接收远端发送来的声音数据,存放到近端的ASIO放音队列。
系统采用Windows操作系统提供的网络套接字(Socket)接口实现实时双端网络通信。Socket接口通过IP地址和端口号来定位远端,它可以工作于有连接的传输控制协议(TCP)和无连接的用户数据报协议(UDP)之上。考虑到满足音频流传输的实时性要求,同时尽量节省计算机和网络资源,在本系统中使用的是UDP协议。
系统每次初始化时启动Socket发送线程和Socket接收线程,通过这2个并发的线程实现全双工的语音通话。系统中预定义了每次接收和每次发送音频流数据块的长度,以此实现较好的音频流同步。为达到节省网络资源的目的,网络通信模块收发的音频流是11025Hz采样率的低采样率数据,接收线程需将低采样率数据升采样到ASIO支持的44100Hz采样率,因此网络通信模块必须先将接收到的每块音频数据转换长度,然后再存放到Socket接收缓冲区中。
1.5 线程间的数据交互
由于网络模块收发的音频流数据块和ASIO模块录放音的数据块长度和采样率均不同,为了保证ASIO的声音流畅度,在音频模块和网络模块之间进行较好的数据交互是软件系统需要重点解决的问题。
如图3所示ASIO录音线程和Socket发送线程共同访问REC-SEND队列,ASIO录音线程负责对REC-SEND队列存放数据,而Socket发送线程负责从REC-SEND队列读取数据并发送,系统为了保护队列中的数据安全地被线程访问,定义了REC-SEND队列的互斥访问操作。ASIO录音线程工作时会连续不断地将音频流数据块存放到REC-SEND缓冲区中,因此要求REC-SEND队列时刻保持有一定的空余容量,使得ASIO录音数据不至于溢出;而在网络情况良好的条件下,Socket发送数据块的速度要比ASIO录制数据块的速度快,因此系统采用了消息机制来实现ASIO录音线程和Socket发送线程之间的同步。回声抵消(AEC)模块从REC-SEND队列中读取一段连续的声音数据进行处理,处理完之后将数据写回REC-SEND队列。AEC处理模块进行回声抵消运算将造成一定的声音延迟,系统在初始化时设定AEC模块头尾指针的位置,以保证REC-SEND队列不发生溢出的同时,网络发送线程发送的数据都经过AEC模块的处理。
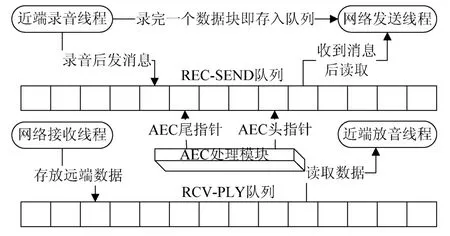
图3 线程交互示意图
相比之下,近端放音线程和网络接收线程之间的同步关系要直观很多:网络接收线程源源不断地接收较低采样率的远端数据,将数据转换成高采样率后存放至RCV-PLY队列。ASIO放音线程连续不断地从RCV-PLY队列中读取处理后的数据进行实时播放。系统初始化时在RCV-PLY队列中预存适量数据,以防当网络拥塞时近端放音产生断续。
2 系统实现的关键技术
2.1 重采样器的原理
声音信号的采样率表示在一秒钟时间内计算机采集的声音样本个数,采样率越高信号对声音波形的描述也更为精确,同时信息量也更大。将原始声音信号x(n)经过L倍的插值之后再通过抗混叠低通滤波器h(n)进行卷积运算,最后对卷积结果进行1/M倍的抽取操作即可以得到采样率为原来L/M倍的信号,这个过程称为信号的重采样。系统中重采样器的实现过程如图4所示,设定抽取系数M=4,插值系数L=1,若x(n)的原始信号块长度为N,则重采样后数据块长度变为N/4。
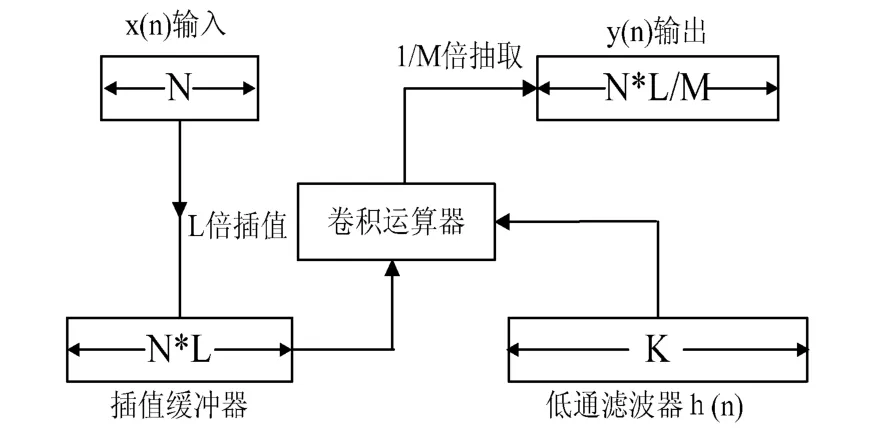
图4 时域重采样器
软件系统中重采样功能被封装到动态链接库中,系统启动时初始化4个重采样器,分别对应远端和近端的左、右通道。如图2所示,ASIO模块录制的近端数据通过重采样器将信号频率从44100Hz降低到11025Hz之后存放到 REC-SEND队列中;对应地,RCV-PLY队列中的远端放音数据通过重采样器后信号采样率从 11025Hz升高到 44100Hz,然后送至ASIO模块放音。采用重采样器之后,用于回声抵消运算和网络传输的声音信号采样率降低为原来的1/4,回声抵消器的运算负载和声音信号的网络传输负载都被大大降低。
2.2 重采样技术用于通道间去相关的实现
多通道回声抵消领域中的一个重要问题是所处理的输入信号具有较高的线性相关性,使得大多数的自适应回声抵消算法都没有唯一解,进而严重影响回声抵消器的工作效率。Fred Juang等人采用改变2路高度相关的输入信号的采样率的方法,使得信号间的采样率不同,以此有效降低通道间相关度[12]。为了采样率抖动后不引入大的失真,声音信号采样率的改变极其微小,在这种情况下时域重采样器的运算量巨大,无法实时实现[13-14]。频域重采样技术引入了快速傅里叶变换(FFT),使得时域重采样器中运算量最大的卷积运算由频域的乘积运算实现,从而节省大量运算时间。
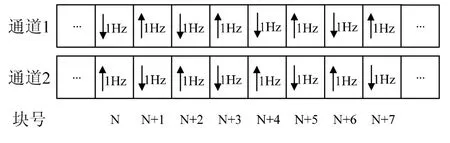
图5 使用重采样技术实现去相关
本系统中RCV-PLY队列存放的是11025Hz采样率的远端双通道声音数据,在回声抵消运算开始之前系统将为这个队列中的数据初始化2个重采样器以进行去相关操作,这2个重采样器的输出分别为11024Hz(降低 1Hz,下文简称 A重采样器)和11026Hz(升高1Hz,下文简称B重采样器)的声音数据。去相关的具体实现如图5所示,对2个声道内的数据块按时间顺序编号,以编号为N和N+1的数据块为例——A重采样器先将通道1的第N号数据块的采样率降低1Hz,同时B重采样器将通道2的第N号数据块的采样率升高1Hz;当处理N+1号数据块时,A、B重采样器交换所工作的通道,即A重采样器将通道2的第N+1号数据块的采样率降低1Hz,同时B重采样器将通道1的第N+1号数据块的采样率升高1Hz。这2个重采样器对这2个数据流内的后续块重复以上的操作,直到回声抵消运算停止。这样操作之后2个通道相同编号的数据块采样率不同,并且每个通道的数据总量保持不变,以此实现通道间去相关的目的。
3 实验结果分析
本实验在一个长6.25米、宽3.75米、高2.5米的封闭会议室内进行。以房间左下角为坐标原点,双麦克风摆放于距离坐标原点长2米、宽2.5米、高0.6米的位置,麦克风间距为15厘米;2个扬声器距离麦克风的距离为1米,分别摆放于麦克风前方左、右30度的位置,扬声器高度与麦克风齐平。
系统运行于Windows XP Professional平台之上,使用的 ASIO版本是 ASIO4ALL V2,CPU为主频3GHz的奔腾双核E5700处理器,内存大小1.87G。系统设定的音频I/O信号采样率为44100Hz,系统每一次录放音写/读512个采样点,对应约11.6ms的声音数据。网络数据采样率为11025Hz,网络缓冲队列长度为3072个采样点,约合280ms。为了测试系统在较为理想情况下的回声抵消性能,笔者设计了单端实验来验证效果,实验在进行时近端无讲话声。
程序开始运行之后本地网络接口持续接收远端发送的语音信号,将其存放至RCV-PLY队列播放同时进行去相关操作后保存为远端输入信号x1(n)、x2(n),同时本地录音线程开始记录近端回声d1(n)、d2(n),将 x1(n)、x2(n)和 d1(n)、d2(n)输入回声抵消模块得到回声抵消结果e1(n)、e2(n)。
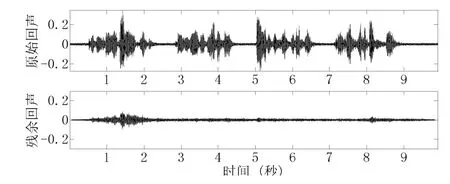
图6 回声抵消前后声音波形示意图
图6记录了系统开始运行之后10秒左右的本地回声信号和回声抵消处理之后的残余回声信号(为了简化,d1(n)、d2(n)和 e1(n)、e2(n)分别画在一个坐标系内)。从图6中可以直观地看到系统运行之后回声的衰减。
衡量回声抵消器性能的一个重要指标是回声抑制比(Echo-Return Loss Enhancement,ERLE),ERLE代表回声抵消前后信号的能量的比值,值越大说明回声抵消的效果越好,ERLE为d(n)与e(n)平方的数学期望之比,公式(1)给出了ERLE的定义。

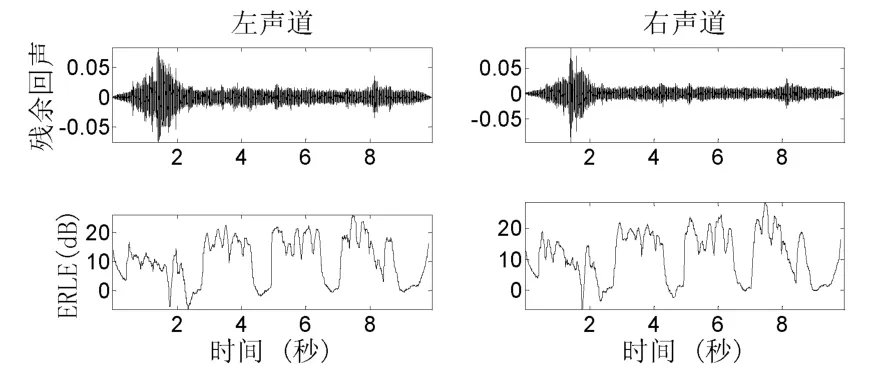
图7 左右声道的ERLE
左右通道的残余回声及其对应的ERLE如图7所示。在有说话人语音的时间段(大约0.5秒~2秒、3秒 ~4.5秒、5秒 ~6.5秒、7秒 ~9秒)ERLE 值在10dB~20dB附近变化。由于本次实验过程中并未考虑近端说话人说话、说话人方位不断变化以及房间环境变化等复杂情况,在实际使用中系统的ERLE值可能会低于图7中显示的结果。
4 结束语
本文设计并实现了运行于Windows操作系统之上的双通道立体声回声抵消系统。系统采用循环队列、消息机制、线程同步等技术来实现对音频流的实时控制;重采样技术的使用有效减少了大数据量情况下系统对计算资源和网络资源的占用。实验表明系统具有良好的回声抑制效果。
:
[1]张子刚.具有立体声效果的多声道网络通话系统[J].现代电子技术,2011,34(20):70-74.
[2]Sondhi M,Morgan D R.Stereophonic acoustic echo cancellation:An overview of the fundamental problems[J].IEEE Signal Processing Letters,1995,2(8):148-151.
[3]Sondhi M.The history of echo cancellation[J].IEEE Signal Processing Magazine,2006,23(5):95-102.
[4]Wu Sheng,Qiu Xiao Jun,Wu Ming.Stereo acoustic echo cancellation employing frequency:Domain preprocessing and adaptive filter[J].IEEE Audio,Speech and Language Processing,2011,19(3):614-623.
[5]Ahgren P.Acoustic echo cancellation and doubletalk detection using estimated loudspeaker impulse responses[J].IEEE Speech and Audio Processing,2005,13(6):1231-1237.
[6]Benesty J,Morgan D R,Sondhi M.A better understanding and an improved solution to the specific problems of stereophonic acoustic echo cancellation[J].IEEE Transactions on Speech and Audio Processing,1998,6(2):156-165.
[7]Cioffi J,Kailath T.Windowed fast transversal filters adaptive algorithms with normalization[J].IEEE Transactions on Acoustics Speech and Signal Processing,1985,33(3):607-625.
[8]Benesty J,Rey H,Rey V L,et al.A nonparametric VSS NLMS algorithm[J].IEEE Signal Processing Letters,2006,13(10):581-584.
[9]Khong A W H,Naylor P A.Selective-tap adaptive algorithms in the solution of the nonuniqueness problem for stereophonic acoustic echo cancellation[J].IEEE Signal Processing Letters,2005,12(4):269-272.
[10]Nitsch B H.Real-time implementation of the exact block NLMS algorithm for acoustic echo control in hands-free telephone systems[M]//Gay S L,Benesty J.Acoustic signal Processing for Telecommunication.MA:Kluwer Academic Publishers,2000:135-152.
[11]Steinberg Media Technologies GmbH.ASIO4ALL-Universal ASIO Driver for WDM Audio[EB/OL].http://www.asio4all.com,2013-06-07.
[12]Wada T S,Wung J,Juang B H.Decorrelation by resampling in frequency domain for multi-channel acoustic echo cancellation based on residual echo enhancement[C]//2011 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics.2011:289-292.
[13]Wung J,Wada T S,Juang B H.Inter-channel decorrelation by sub-band resampling in frequency domain[C]//2012 IEEE International Conference on Acoustics,Speech,and Signal Processing.2012:29-32.
[14]Wung J,Wada T S,Juang B H.On the performance of the robust acoustic echo cancellation system with decorrelation by subband resampling[C]//2013 IEEE International Conference on Acoustics,Speech,and Signal Processing.2013:635-638.
