基于聚类的双说话人混合语音分离
2014-10-14梁正友
吴 春,梁正友
(广西大学计算机与电子信息学院,广西 南宁 530004)
0 引言
双说话人语音分离是在单声道的情况下,对包含2个说话人语音中的目标语音进行分离。考虑到2个语音信号高度重叠在一段混合语音中,这将是一个非常有难度的任务。尽管这是一项艰巨的任务,但是人类在这种情况下有选择性地听取其中一个人的说话却显示出令人难以置信的能力。这种听觉现象被Bregman称之为听觉场景分析模型[1],主要分为分解和组合2个过程。在分解过程中,到达人耳的混合声音信号被分解为一组独立的单元,称为时频单元。初始信号是在时域和频域上的观测量,并且是多个声源信号的混合,而分解过程将混合信号变换到一个可以区分出混合信号中各个分量的变换域中[2];在组合过程中通过有选择性地分离时频单元形成各个声源的听觉流。在组合过程中包含同时组合和序列组合,同时组合是将同时存在的不同频率范围的声音分量组合在一起,序列组合则是将一串声音分量按时间先后组合到一个或者多个声音流中。本文主要研究如何在序列组合中通过聚类的方法完成对声音分量的组合。
目前对双说话人语音分离的研究在序列组合过程中主要通过基于训练的语音模型。在Shao和Wang[3]的研究中,通过高斯混合模型(GMM),在序列组合中通过最大化说话人识别得分获得一切可能的分组和语音对来完成分离。另一个基于训练模型的方法通过隐马尔科夫模型(HMM)和自动语音识别识别完成语音分离[4]。最新的语音识别中基于训练的方法中所使用的模型有HMMs、GMMs,例如文献[5-6]。目前基于训练模型的分离方法,当训练样本与被分离的语音信号类似时,可以达到令人满意的分离。然而,这种情况在实际应用中往往不现实。
在本文中,提出一种基于聚类的语音分离方法来处理双说话人语音分离。这种方法与基于训练模型的方法相比,在序列组合阶段不需要对语音数据集进行训练获取先验知识,而是采用特征提取和计算的聚类方法完成语音流分离。实际结果表明,该方法与基于训练模型的方法相比具有更好的语音分离效果。
1 分离结构图
系统遵循计算听觉场景模型的2个过程:分解和组合。分解阶段将语音信号分解为时频单元(T-F),组合阶段则有选择性地形成对应说话人的语音流。系统首先通过外围处理模块将语音信号分解成时频单元,然后通过多基音跟踪算法形成语音的基音段和相应的二值掩码,接着提取混合语音的倒谱特征,最后利用特征进行聚类。在聚类中,通过搜索一个目标分类函数使类间散布矩阵和类内散布矩阵的迹有最大值,系统模型如图1所示。
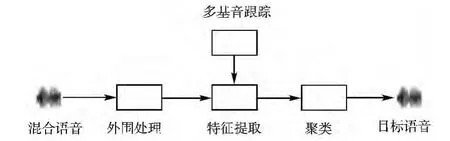
图1 系统流程图
2 外围处理和特征提取
外围处理和特征提取是语音分离过程中对混合信号的分解阶段。通过外围处理的时频分解,输入的时域信号被转化为时频域的表现形式。再通过特征提取,得到输入信号在时频域的特征,为后继的聚类和语音分离提供输入。
2.1 外围处理
在外围处理阶段,基于人耳的听觉感知机制,系统采用128个gammatone滤波器组成的滤波器组对输入声音信号进行带通滤波,滤波器的中心频率以等矩形带宽的方式分布在80Hz到5000Hz之间。然后,采用交叠分段方法,以20ms为帧长、10ms为帧移,对每一个频率通道的滤波相应做时域分帧处理,得到输入信号的时频域表示[7]。接着对128个滤波通道的输出在时间维上降低采样至100Hz并通过立方根操作压缩降低采样后的输出,得到gammatone特征单元(GF 单元)[8]。
2.2 特征提取
提取特征阶段先应用多基音跟踪算法[9]对输入信号进行处理。通过基音跟踪和时频单元标记,得到输入信号的基音轨迹和对应的同时语音流。其中,同时语音流用二值掩码表示,即对理想二值掩码(IBM)[10]的估计值。在理想二值掩码中,1代表对应时频单元被标记,0则相反。为了在序列组合阶段通过聚类完成语音分离,需要提取语音信号gammatone频率倒谱系数(GFCC)[8]。首先,通过二值掩码和对应的同时语音流过滤GF单元,获得被1标记的单元并将没有被标记的单元移除。然后,依次处理每一帧,将获得的被1标记的单元通过离散余弦变换操作转换成GFCC单元,最终形成语音信号的GFCC特征矩阵。
3 基于聚类的序列组合
3.1 目标函数
在双说话人语音分离中,系统将序列组合过程视为一个聚类过程,即将同时流聚集成2个说话人的语音流。在聚类中通过一个目标函数来评价不同聚类可能性的优劣,具有最高目标函数得分的聚类就是最终的结果。
本文中,聚类的目标函数是基于类内和类间距离的比率[11],即:

其中,g代表一种假设的分类向量,SB(g)和SW(g)分别表示类内散布矩阵和类间散布矩阵,它们的计算公式分别为:
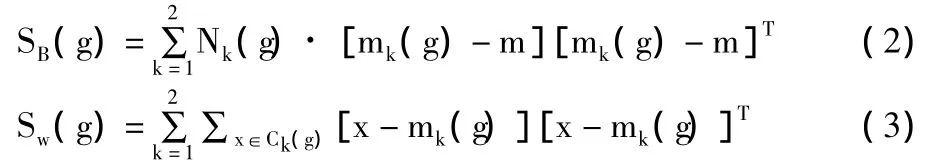
其中,x代表GFCC特征矩阵,Ck(g)代表假设的分类向量g中第k维分量,Nk(g)和mk(g)分表代表分类向量g中第k维分量的GFCC特征矩阵的元素个数及均值,m代表GFCC特征矩阵的均值,T为矩阵的转置操作。
3.2 搜索最佳分类
在给定目标函数的情况下,聚类可以转为一个求最优解的问题,即求一个分类向量使得目标函数O(g)有最大值。要寻找一个最优解,可以通过穷举的方法,当输入的语音信号长度较短时可以得到一个不错的结果。但是对于较长的语音信号,可以使用基于剪枝搜索方法[12]。
系统开始先随机挑选同时语音流中2个单位,分配到2个类别中。然后对未被挑选的同时语音流中单位进行排序,排序的规则为按照它们第一帧的先后次序,接着将它们一个一个的组合。对于同时语音流中的每个单位,先假设它的分配值(0或1),并且仅仅根据目标函数的分值保持w条具有较高分值的路径。在处理完同时语音流最后一个单元后,选择使目标函数具有最高分值的路径为解决方案。通过实验,可以发现w=8是一个好的权值,在速度和性能方面可以得到一个不错的结果。
4 实验与评估
为了方便比较,系统使用SSC语音数据集[13]中的双说话人混合语音进行测试。SSC语音数据集包含34个不同人的语音,每段语音材料存在一个目标语音以及另一个不同的说话人的语音,每段语音信号的信噪比有-6dB、0dB、6dB三种情况。随机挑选50个双说话人混合语音材料分别在-6dB、0dB、6dB三种信噪比条件下进行测试,并且所有语音材料的采样频率为16kHz。
本文通过衡量系统在分离多说话人语音时信噪比(SNR)的提升程度来评价系统的分离性能。信噪比提升由经过系统分离得到的输出语音材料的信噪比减去输入材料的信噪比得到。输出语音材料的信噪比计算公式为:

其中,SI[n]和 SE[n]分别代表从理想二值掩模和评估的二值掩模重新合成的语音材料。
本文将系统的分离性能与分离中基于训练的背景模型(BM)[14]进行比较。在BM模型中,通过训练SSC数据集中语音材料,将每个说话人模拟成64维的GMM模型,并且将SSC数据集中34个说话人语音分为2部分,随机挑选10人作为目标语音,剩余24人为干扰语音,从而形成目标语音的先验知识,使得系统对于目标语音更为熟悉。在分离中,BM模型与本文的方法都是先完成同时组合,但是在序列组合中BM方法通过最大化语音识别得分形成目标语音,本文则通过聚类完成分类。为了得到系统的最佳分离性能,笔者测试了在进行搜索时,w在不同值下的分离性能。
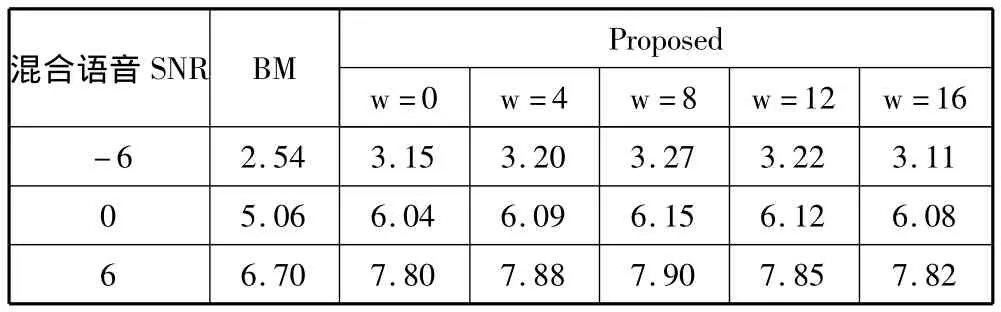
表1 不同混合信噪比和剪枝过程不同w值下SNR提升(dB)
分解结果的比较如表1所示,“BM”列表示基于训练的背景模型的方法的分离性能,“Proposed”列表示本文提出的方法,w值表示剪枝过程中保留枝数不同所得到的分离性能。由表中结果可知本文提出的方法在3种SNR条件和不同w值下的分离的性能都比BM方法要好,尤其在混合语音材料SNR越高,分离的性能就越好。这得益于基于聚类的序列组合方式在SNR较高或越高时,提取混合语音材料特征的差异就越明显使得分离效果更好。另外,从表1中可知当剪枝过程中保留枝数为8时,比较适合本文的搜索方法,得到的分离性能优于其他w值。
5 结束语
基于计算机听觉场景模型,本文提出一种基于聚类的双说话人混合语音分离方法。该方法引用计算听觉场景分析模型的分离与组合过程,与基于训练的语音分离模型相比,在序列组合阶段采用聚类的方法,不需要训练过程以及被分离混合语音材料的先验知识,通过提取特征以及基于剪枝的搜索方法完成语音分离。实验结果表明,与基于训练的语音分离模型相比,该方法不仅所需要的前提条件更少,在分离性能上也有所提升,为双说话人的语音分离提供了一种新的思路。
[1]Bregman A S.Auditory Scene Analysis:The Perceptual Organization of Sound[M].MIT press,1994.
[2]吴镇扬,张子喻,李想,等.听觉场景分析的研究进展[J].电路与系统学报,2001,6(2):68-73.
[3]Shao Y,Wang D L.Model-based sequential organization in cochannel speech[J].IEEE Transactions on Audio,Speech,and Language Processing,2006,14(1):289-298.
[4]Barker J,Coy A,Ma N,et al.Recent advances in speech fragment decoding techniques[C]//Proceedings of Interspeech.2006:85-88.
[5]Hershey J R,Rennie S J,Olsen P A,et al.Super-human multi-talker speech recognition:A graphical modeling approach[J].Computer Speech & Language,2010,24(1):45-66.
[6]Weiss R J,Ellis D P W.Speech separation using speakeradapted eigenvoice speech models[J].Computer Speech& Language,2010,24(1):16-29.
[7]Wang Deliang,Guy J Brown.Computational Auditory Scene Analysis:Principles,Algorithms,and Applications[M].Wiley-IEEE Press,2006.
[8]Shao Y.Sequential Organization in Computational Auditory Scene Analysis[D].The Ohio State University,2007.
[9]Jin Z,Wang D L.Reverberant speech segregation based on multipitch tracking and classification[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(8):2328-2337.
[10]Narayanan A,Wang D L.Robust speech recognition from binary masks[J].The Journal of the Acoustical Society of America,2010,128(5):EL217-EL222.
[11]Xu R,Wunsch D.Clustering[M].Wiley Press,2008.
[12]Shukla Shubhendu S,Vijay J.Applicability of artificial intelligence in different fields of life[J].International Journal of Scientific Engineering and Research,2013,1(1):28-35.
[13]Cooke M,Lee T.Speech Separation Challenge[DB/OL].http://staffwww.dcs.shef.ac.uk/people/M.Cooke/SpeechSeparationChallenge.htm,2006-11-11.
[14]Shao Y,Wang D L.Sequential organization of speech in computational auditory scene analysis[J].Speech Communication,2009,51(8):657-667.
