基于支持向量机的股票预测系统
2014-08-22姚宏亮
杨 培,姚宏亮
(1.淮北职业技术学院 计算机系,安徽 淮北 235000;2.合肥工业大学,安徽 合肥 230009)
股票预测是指对股市具有深刻了解的证券分析人员根据股票行情的发展进行的对未来股市发展方向以及涨跌程度的预测行为。这种预测行为只是基于假定的因素为既定的前提条件为基础的。
但是在股票市场中,行情的变化与国家的宏观经济发展,法律法规的制定,公司的运营,股民的信心等等都有关联。因此所谓之预测难于准确预计。证券分析师的预测也只能作为股民入市操作的一般参考意见。[1]
1 支持向量机的原理
支持向量机是美国著名学者Corinna Cortes以及Vapnik8在1995年共同提出的。支持向量机的主要优势体现在解决小样本、非线性数据以及高维模式识别方面。除此之外,支持向量机还有一个优点就是其比较适合推广,可以将其应用到其他各个方面比如说数据的拟合度分析。[2]
事实上,所谓的小样本并不是我们所想的那样样本的绝对数量少,它只不过是相对于问题的复杂度来说,支持向量机算法所需要的样本数并不多。非线性主要是指支持向量机算法能够对那些数据线性不明显的情况进行处理,主要方法是通过松弛变量以及核函数技术来完成。高维模式识别主要是因为需要处理的样本维数相对于其它样本来说非常高,在这种情况下,支持向量机同样都能进行处理。支持向量机之所以能够用于高维模式识别,是因为它所产生的分类器相对来说更加简洁,需要借助的相比信息相对来说就更少,因此,就算维数很高,其在存储以及计算过程中都不会有大的困难。
支持向量机方法是建立在一定的理论基础之上的,主要有两个理论来对其进行支持,第一个是统计学习理论;第二个是VC维理论。除此之外,其还结合了结构风险最小原理,以期获得最好的推广能力。[3]
VC维如果作最简单的解释,它的意思就是用来描述问题的难易程度,如果这个指标越大,也就越说明这个问题比较难;如果VC维越低,那就说明这个问题越简单。由于支持向量机注重的仅仅是VC维,因此,当支持向量机解决问题的时候,并不会去考虑样本的维数。例如,上万维的样本它可以解决,如此一来,支持向量机可以用于解决文本分类类似的问题。
2 实验结果及分析
2.1 预测数据的来源
为了保证该算法预测分析的有效性,从大智慧软件上下载了2014年1月份到5月份的上证指数和深证成指的开盘数作为这次预测的金融时序数据。
2.2 SVM回归预测算法的原理
有效的预测大盘指数可以为整体上观测股市变化提供强有力的信息,因此预测大盘指数对于上证指数预测很有意义,通过对今年1月份到5月份的每日上证指数和深证成指的开盘指数进行回归分析,拟合的结果如下:上证指数均方误差 MSE=0.000698138相关系数 R=96.4776%;深证成指均方误差 MSE=0.000897312相关系数R=95.886%。由此可以看出,SVM的拟合结果还是比较准确的,并且对上证指数的拟合更加精准。
2.3 SVM回归预测算法的背景
把一组数据存储在shangzhengdata.mat文件中,数据是一个100*6的double型的矩阵,记录的是从2014年1月到2014年5月的100个交易日的每日上证综合指数的各种指标,6列分别表示开盘指数,指数最高值,指数最低值,收盘指数,当日交易量,当日交易额。
把另外的一组数据存储在shenzheng.mat文件中,数据依然用一个100*6的double型矩阵记录,时间同上,6列分别表示深证成指的开盘指数,指数最高值,指数最低值,收盘指数,当日交易量和当日交易额。
2.4 回归模型建立
模型目的:利用SVM建立回归模型,然后对上证指数的每日开盘指数进行回归拟合。
模型假设:假设上证指数和深证成指每日的开盘指数和前一天的开盘指数,最高值,最低值,收盘数,交易量,交易额相关,也就是把前一天的开盘指数,最高值,最低值,收盘数,交易量,交易额作为当天开盘指数的自变量,当天的开盘指数作为因变量。
2.5 根据模型选择假设选定自变量和因变量
选取第一个到第99个交易日内每日的开盘指数,最高值,最低值,收盘指数,交易量,交易额作为自变量,选取第二个到第100个交易日内每日的开盘指数作为因变量。
Matlab实现代码如下:
% 载入测试数据上证指数
% 数据是一个100*6的double型的矩阵,每一行表示每一天的上证指数
%6列分别表示当天上证指数的开盘指数,指数最高值,指数最低值,收盘指数,当日交易量,当日交易额.

% 提取数据

深证成指的数据提取方法与此类似。
2.6 数据的预处理
在数据的预处理之前,先说明预处理的必要性,这里的预处理就是将数据进行归一化处理。
2.7 交叉验证选择最佳回归参数
归一化后进行交叉验证选择最佳回归参数松弛变量c和核函数值g。对libsvm工具包中的SVMcg-ForClass.m稍微修改就可以用来寻找回归的最佳参数c和g,由SVMcgForRegress.m实现,可以精确的选取c和g的最佳值。
2.8 训练和回归预测
在获取到最为合适的c和g的值后,可以用这两个参数值对SVM进行训练。训练完成之后,再对最初输入的数据做回归预测。利用svmpredict函数即可进行回归预测:

得到的预测结果和实际结果的对比如图1所示。红色代表回归预测结果,蓝色代表原始数据。
图2预测结果和实际结果之差除以实际结果所得的相对误差率图。由图可见,相对误差量大部分在百分之十五以内。误差结果很小,说明这种方法精度很高。
3 结论
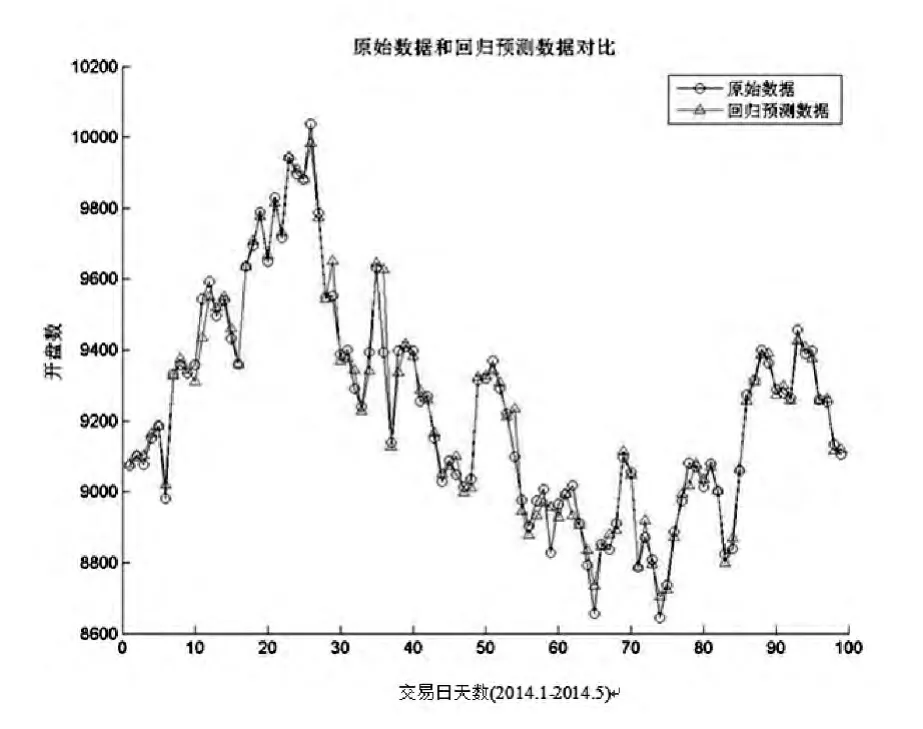
图1

图2
本文算法是根据上一个交易日的所有数据特征值作为自变量,预测出下一个交易日的周线,这个算法预测的准确率相对较高,因为它考虑到了上一个交易日的数据,但是也有一定局限性,因为每一个特征值对于因变量的影响程度是不一样的,因此下一步可以把不同的特征给予不同的权值,即用特征加权支持向量机去进行股票走势的预测,这里给不同的特征给予不同的权值以及给予权值之后怎样导入支持向量机将是我下一步工作的重点,相信考虑特征加权这个因素之后,预测的准确率会进一步提高的。
[1]邓华丽,李修全.基于混沌时间序列分析的股票价格拐点预测方法[J].统计与决策,2007(9).
[2]彭丽芳,孟志青,姜华,田密.基于时间序列的支持向量机在股票预测中的应用[J].计算技术与自动化,2006(3).
[3]王巍,赵宏,梁朝晖,马涛.基于EMD和SVR的混合智能预测模型及实证研究[J].计算机工程与应用,2012(4).
