基于电力公司的多格式文档智能信息检索系统的设计与实现
2014-08-14方跃胜姚宏亮
方跃胜 姚宏亮
(1.安徽水利水电职业技术学院, 合肥 231603; 2.合肥工业大学计算机与信息学院, 合肥 230009)
随着互联网的发展,用户采集到的信息数据量大、格式繁多,使得发掘有用信息的难度变大。本系统旨在克服多种文档格式给检索造成的困难,同时提高检索的质量,使用户浏览较少文档即可找到需要的文档。
系统设计目标如下:将多格式文档转换为txt文档,克服文档格式对检索造成的困难;生成自动文摘,用户花费较少时间即可了解文档内容;采用基于词索引的全文检索技术,信息模型采用向量空间模型,同时加入“去停用词”处理,实现信息检索。
1 文档格式转换简介
文档格式分为纯文本文档和非纯文本文档。纯文本文档是只包含纯文字的文件,这些文字没有格式,如扩展名为“.txt”、“.html”的文档。使用任何编辑器都可以打开纯文本文档,在编程中用文件操作函数即可读取文件内容。另一类文档为非纯文本文件,如扩展名为“.pdf”、“.doc”、“.xls”的文档。打开非纯文本文档需要特殊的编辑器,读取内容需要使用特殊解析工具[1]。
目前已有多种工具可以解析“.pdf”文档的格式并读取其内容。最常见的“.pdf”文本抽取工具包括PDFBox和Xpdf。PDFBox是一个开源的Java PDF库。Java PDF库允许用户访问“.pdf”文档的各项信息,通过PDFBox提供的API,可从“.pdf”文档中提取出文本信息。用PDFBox处理“.pdf”文档,需要下载PDFBox,并在Java工程中调用相应的jar包。相对于PDFBox,Xpdf可对中文文件提供更强大的支持。除了下载相应的Xpdf版本,使用Xpdf还需下载一个中文包“Xpdf-chinese-simplified.tar.gz”,并在Java工程中调用相应的jar包。同时,Xpdf提供的可执行文件可以在PHP中直接调用,但是经常出现乱码。
DOC和XLS文档作为Microsoft Office系列的办公软件,实现了自动化的COM组件,可以通过调用COM组件读取其内容。“.xls”文档还提供可供PHP调用的类spreadsheet_excel_reader,以读取“.xls”文档内容。经过测试,COM组件读取“.xls”文档的质量较高,而spreadsheet_excel_reader类读取“.xls”文档的速度较快。
“.html”文本是由HTML命令组成的描述性文本,HTML命令可以说明文字、图形、动画、声音、表格、链接等。HTML的结构包括头部和主体两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。由于转换成txt文档的过程中不需要HTML标签的信息,因此,在读取完字符串后应运用PHP中的字符串处理函数对其做相应处理,去除不必要的HTML标签。
2 自动文摘方法
文摘是全面准确地反映文献中心内容的简单连贯的短文,自动文摘是指利用计算机自动地从原始文献中提取文摘[2]。生成自动文摘的主要方法包括基于统计的自动文摘、基于理解的自动文摘、信息抽取和基于结构的自动文摘[3]。基于统计的自动文摘将句子视为词的线性序列,将文本视为句子的线性序列,通过计算词的权值,从而计算句子的权值,再针对句子权值排序,将权值最高的若干句子作为文摘句,按照其在原文中出现的顺序输出。基于理解的自动文摘以人工智能,特别是自然语言理解技术为基础而发展起来的文摘方法,不仅需要语言学知识判断语言结构,而且需要利用领域知识进行判断、推理,得到文摘的意义,从而生成摘要。信息抽取适用于特定的领域。基于结构的自动文摘把篇章作为一个结构体,对篇章结构的引入可以提高文摘质量,但实现较为困难。
2.1 中文分词
中文分词是指将一个汉字序列切分成一个一个单独的词,分词就是将连续的字序列按照一定的规范组合成词的序列[4]。中文分词是自动文摘以及信息检索的基础,其算法有基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[5]。
基于字符串匹配的分词方法又称做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。基于理解的分词方法通过计算机模拟人对句子的理解,达到识别词的效果。其基本思想是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象,目前基于理解的分词系统还处于试验阶段。基于统计的分词方法认为:词是稳定的字的组合,在上下文中,相邻的词出现的次数越多,就越有可能构成一个词。这种方法只需对语料中的字组频率进行统计,不需要切分词典,又叫做无词典分词法或统计取词方法。对于任何一个成熟的分词系统,不可能单独依靠某一种算法来实现,都要综合不同的算法。
ICTCLAS是中科院研制的汉语词法分词系统,全部采用CC++语言编写,支持Linux、FreeBSD及Windows系列操作系统,同时支持CC++C#DelphiJava等主流的开发语言。ICTCLAS系统主要功能包括:中文分词;词性标注;命名实体识别;新词识别;用户词典。ICTCLAS3.0版分词速度达到单机996kBs,分词精度98.45%,API不超过200kB,各种数据压缩后不到3M。本实验室的分词系统采用基于memcached的动态四字双向词典机制[6],将词典按一定的数据结构首先储存于数据库中,在服务器启动后通过程序自动载入内存,利用memcached对其进行管理,为以后的分词提供服务。四字词典与传统词典相比,增加了四字内字串的前后缀信息。因为文本大部分词都在四字以内,这样有利于使用双向最大匹配算法,以最少的词典访问数切分出最大匹配词。
2.2 基于句子特征的文本摘要生成方法
基于句子特征的文本摘要技术通过计算文中句子的权重,将句子按照权重排序,输出权重较高的句子作为文摘句[7]。在计算句子权重之前,需要对txt文件进行分词和词性标注,系统采用C++调用ICTCLAS分词系统来实现。句子的权重通过句子的位置特征、句子的长度特征、句子的词项特征、句子中包含的专有名词个数、句子中包含的数字信息的特征、句子与标题的相似度等几项特征来计算。
句子的位置特征,如式(1)所示:
(1)
式中,Si为文本中的第i个句子,N为句子的总数。
句子的长度特征,如式(2)所示:
(2)
式中,Len(Si)为句子第i个句子中包含实名词的个数。
句子的词项特征,通过式(3)(4)反映:
TF.IDF(w,S)=TF(w,S)
×g(|S|SF(w))
(3)
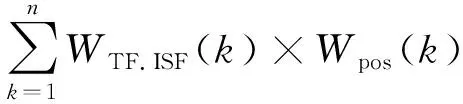
×Wposition(k)
(4)
式中:TF(w,S)为词语w在句子S中出现的次数;|S|为句子的总数;SF(w)表示包含词语w的句子的数目;n为句子中词项的格式;WTF.ISF(k)为句子Si的第k个词项的TF.ISF值;Wpos(k)为句子Si的第k个词项的词性权重;Wposition(k)为句子Si的第k个词项的位置权重。
句子中包含的专有名词个数,通过式(5)反映:
W4(Si)=句子Si中专有名词的个数句子Si中词的总数
( 5)
式中,专有名词是指特定的某人、地方或机构的名称,如人名、地名、国家名、单位名、组织名,等。
句子包含数字信息的特征,通过式(6)反映:
W5(Si)=句子Si中数字信息的个数句子Si中词的总数
(6)
句子与标题的相似度,通过式(7)反映:
( 7)
在对句子特征分析基础上,可以决定句子的特征计算公式:
(8)
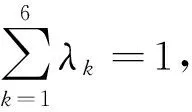
2.3 性能评测
自动文摘模块性能评价采用内部评价方法,通过直接分析摘要的质量来评价文摘系统[8]。以覆盖率作为评价指标,选取25篇文章共496句话,由3人手工选取20%的摘要句作为系统理想文摘。由于主观因素的影响,3人选取的文摘句可能不同,通过对文摘句赋权值削弱这一因素的干扰,当一句话同时被3人选择则其权值为1,被两人同时选取则权值为23,只被一人选取则权值为13。把理想文摘与系统生成文摘作比较,不是理想文摘的句子赋值为0,将系统文摘的权值之和与理想文摘最高权值做除法,所得即为该文摘的覆盖率。通过测试,覆盖率根据文章的不同有所变化,最高可达100%,最低可达0%,平均覆盖率为37.7%。文摘覆盖率如图1所示。

图1 文摘覆盖率
3 全文检索
全文检索是指计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。功能上全文检索系统需要具有建立索引,处理查询返回结果集,增加索引,优化索引结构等功能。系统采用基于倒排表的中文全文检索方式[9]。
3.1 索引数据库
依据基于倒排表的检索方式中依据词索引的检索要求[10],系统索引数据库包括三部分:存储文件的表、存储关键词的表和倒排表。文件表(如图2所示)存储文件名和文件序号,关键词表(如图3所示)存储关键词及其序号,倒排表(如图4所示)存储关键词在文件中出现的次数。

图2 文件表结构截图

图3 关键词表结构截图
3.2 向量空间模型
向量空间模型(VSM:Vector Space Model)[11]把对文本内容的处理简化为空间向量中的向量计算,并且它以空间上的相似度表示语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量间的相似性来度量文档间的相似性。文本处理中最常用的相似度度量方式是余弦距离。

图4 倒排表结构截图
系统首先对检索语句进行分词和去停用词处理[12],分别将词及词出现的次数存入数组,形成索引向量。然后在关键词表中查询对应词得到该词出现的倒排表及其在倒排表中位置,每一文档针对关键词形成文档向量,运用向量空间模型计算文档向量与关键词向量夹角的余弦值,作为相关度。设定阈值为0.7,将相关度高于阈值的文档信息输出。
当检索句较长时,文中包含关键词的句子可能很多,通过计算句子向量与关键词向量的相似度,将相似度最高的三个句子输出,同时输出文档的摘要信息、创建时间以及链接供用户选择。
4 结 语
本系统基本实现了对存储的多格式文档进行智能检索。运用了将多种格式文档进行转换从而方便检索的思想,同时对文档生成自动文摘,方便用户参考;在检索模块,运用空间向量模型计算相似度,同时加入了去停用词处理,提高检索速度和质量。但是,系统还存在不足,下一步的目标是进一步提高自动文摘的质量,同时尝试用PHP直接实现PDF格式文档的转换,实现编程语言的统一。
[1] 张秀秀,张立峰.PDF文件文本内容提取研究[J].科技情报开发与经济,2008(3):118-120.
[2] 袁津生,李群,蔡岳.搜索引擎原理与实践[M].北京:邮电大学出版社,2008:1-2,28.
[3] 李晓明,闫宏飞,王继民.搜索引擎:原理、技术与系统[M].北京:科学出版社,2005.
[4] Sproat R,Emerson T.The First International Chinese Word Segmen-tion Bakeoff[C]Proceedings of the Second SIGHAN Workshop on Chinese Language Processing.Sapporo,Japan,2003:133-143.
[5] 史伟.中文自动分词关键技术研究与实现[D].成都:电子科技大学,2008:100-103.
[6] 张培颖,李村合.一种中文分词词典新机制:四字哈希机制[J].微型电脑应用,2006(10):35-36.
[7] 张培颖.基于句子特征和语义距离的文本摘要技术[J].微计算机应用,2009(7):14-18.
[8] 黄丽琼,何中市,张杰慧.基于文本相似度的自动文摘评价方法[J].计算机应用研究,2007(8):97-99.
[9] 杨安生.基于倒排表的中文全文检索研究[J].情报检索,2009(7):77-80.
[10] 熊回香,夏立新.基于词索引的中文全文检索关键技术及其发展方向[J].中国图书馆学报,2007(4):45-49.
[11] Salton G,Wong A,Yang C S.A Vector Space Model for Automated Indexing [J].Communications of ACM,1975,18(11):613-620.
