聚类算法在入侵检测中的应用研究
2014-08-07卢秉亮曲超毅
朱 健,卢秉亮,曲超毅
(1.沈阳航空职业技术学院,沈阳110034;2.沈阳航空航天大学计算机学院,沈阳110136;3.中航工业沈阳飞机工业(集团)有限公司,沈阳110034)
聚类算法在入侵检测中的应用研究
朱 健1,卢秉亮2,曲超毅3
(1.沈阳航空职业技术学院,沈阳110034;2.沈阳航空航天大学计算机学院,沈阳110136;3.中航工业沈阳飞机工业(集团)有限公司,沈阳110034)
应用聚类算法对入侵检测数据集进行聚类,通过对其聚类结果的分析,发现聚类的部分簇中存在划分不够紧凑的问题。为此,提出应用加权聚类算法对簇中与聚类中心距离较远的数据进行聚类,解决了聚类结果中存在“子簇”的问题。结果表明,簇的紧凑性有较大提升,同时由于子簇数量的减少使得检测率有所提升,加快了检测速度。
网络安全;入侵检测;聚类分析;加权聚类算法
1 引 言
随着网络技术的逐渐发展,不断出现新的入侵和新类型的攻击,为了解决此问题,必须应用智能入侵检测技术。常见的入侵检测方法主要包括统计方法、神经网络、模式匹配、规则推理以及人工免疫理论等方法[1-3]。为了获得网络行为模式,需要通过带标签数据或者完全正常的网络行为数据进行训练。然而,标签数据和完全正常的网络行为数据是很难实现的,这是由于数据的海量性和复杂的网络环境造成的。为了提高入侵检测效率,以聚类(Clustering)为代表的无监督入侵检测算法[4-6]被用来直接处理无标签原始网络数据。
通过使用应用加权的聚类算法在局域网中进行实际的入侵检测验证,对DOS和Probe两类攻击进行检测,结果表明有较好的检测性能,并对未知网络入侵具有一定的自适应性。
2 聚类分析算法
2.1 聚类算法进行聚类的原理
聚类分析算法[7-8]可以描述为:给定m维空间R中的n个向量,把每个向量归属到k个聚类中的某一个,使得每一个向量与其聚类中心的距离最小。聚类可以理解为:类内的相关性尽量大,类间相关性尽量小。在这里对链路流量进行聚类,初始设定一个链路流量大的链路A作为类A和一个链路流量小的链路B作为类B。
2.2 聚类分析算法原理
聚类算法包括划分方法、层次方法、基于密度的方法、基于网格的方法以及基于模型的方法[7]。典型的基于划分的聚类分析算法是K-means算法:给定一个有N个元组或者纪录的数据集构造K个分组,每一个分组代表一个聚类,这里的K<N。K个分组满足下列条件:①每一个分组至少包含一个数据纪录;②每一个数据纪录属于且仅属于一个分组;对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,最终使得同一分组中的记录越近,而不同分组中的纪录越远。
K-means算法把n个向量xi(i=1,2,…,n)分成k个类Gi(i=1,2,…,k)并求每类的聚类中心,使得非相似性(或距离)指标的目标函数达到最小。当选择第i个类Gi中向量xl与相应的聚类中心Ci间的度量为欧几里德距离时,目标函数可以定义为
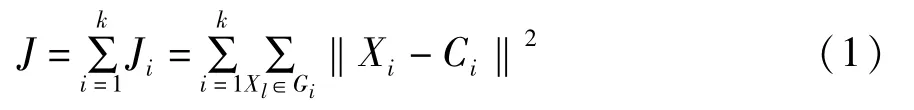
这里Ji是类Gi内的目标函数,显然J的大小取决于聚类中心Ci和Gi的形状,J越小,表明聚类的效果越好。
K-means算法的基本思想是:
(1)首先从n个数据对象任意选择k个对象作为初始聚类中心;
(2)而对于剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;
(3)设U是一个c×n矩阵,若xj∈类i,则uij=1,否则uij=0,即当‖Xj-Ci‖≤‖Xj-Ck‖(k≠j)时,uij=1,否则uij=0;
(4)根据uij计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);
(5)根据uij计算标准测度函数的值,直到标准测度函数开始收敛为止,否则回到步骤(3)。
2.3 加权的聚类算法[7]
采用K-means算法也有其局限性,在聚类分析的时候,它考虑了所有因素,而且认为这些因素对距离的影响是等同的[9],会出现由不相关属性导致的“维数陷阱”。要解决这一问题,需要对每一个属性加上特征参数[10],让不同的属性在聚类中起不同作用。从欧氏空间上来说就是拉长相关属性对应的轴,缩短无关属性对应的轴。为此,就要把目标函数中的‖Xi-Ci‖2换为,这样目标函数J还依赖于权值Wj,权值的大小由经验确定,从而解决“维数陷阱”问题。
3 聚类技术在入侵检测中的应用
3.1 应用聚类分析进行入侵检测的基本思想
为了能够实现聚类,要求网络环境中的正常网络行为要远大于入侵网络行为并且两种行为必须是可以区分的,使得算法能够将网络行为数据集划分为不同的类别,在实际网络环境中,入侵网络行为远小于正常网络行为并且可以区别开来,因此在网络入侵检测中可以应用聚类分析算法。聚类后的结果可以应用簇标记算法[11-12]判断簇是正常网络行为还是入侵网络行为。
3.2 应用聚类算法进行入侵检测主要过程
应用聚类分析技术进行入侵检测主要经过数据收集、特征向量标准化、聚类分析、标记生成簇、实时检测、结果验证等过程。
3.2.1 数据收集
将原始的网络数据包恢复成TCP/IP层的连接,每个连接记录包括网络协议、起始时间、结束时间、端口号、源IP地址、目的IP地址、连接终止状态、TCP标志等属性。同时要记录一段内与当前连接具有相同服务类型的连接数和错误的连接百分数等。
3.2.2 特征向量标准化
聚类算法的输入通常有 N个数据点的集合D={x1,x2,…,xn},具有不同的特征向量,其单位也是不同的,如果直接进行聚类会影响聚类结果,通过标准化处理将所有特征向量转化为无单位,则可提高聚类结果的准确性。
3.2.3 聚类分析
在这里对链路流量进行聚类,初始设定两个类,一个是类A,代表链路流量大的链路;另一个是类B,代表链路流量小的链路,然后使用加权K-means算法进行聚类分析得到聚类结果。
K-means有其缺点,即产生类的大小相差不会很大并且对于“脏”数据很敏感,因此,要对初始聚类结果进行优化,使各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。聚类结果的具体评价标准[13]定义如下:

其中,δ(Ck,Cl)定义为簇间距离:
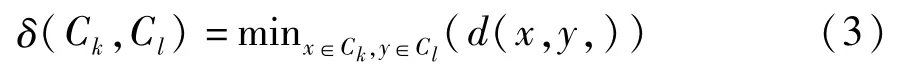
d(x,y)为记录x与y的距离,Δ(Cm)定义为簇的直径:
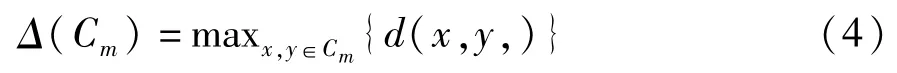
由公式2可知,簇的直径越小,聚类结果越紧凑;簇间距离越大,各聚类之间的分割性越好,公式2的值越大表示聚类的结果越好。
3.2.4 标记生成簇
由簇标记算法区分正常簇还是异常簇,进而获得其特征模式。
3.2.5 实时检测
对异常簇异常行为的特征模式应用检测器(入侵检测系统的模式信息库)对其进行判断,产生检测结果,确定并输出入侵和攻击[14-16]。
4 实验结果及其分析
由于数据集中入侵数据的比例远超过真实环境,不能满足无监督异常检测算法中“正常数据的数量要远大于入侵数据”的要求,而且数据集中含有大量重复数据,因此需要对实验数据进行筛选。选取的数据分为两部分,去掉10%数据集中的重复数据。实验中,训练集A使用了24790条记录用来生成检测模型,其中24294条为正常网络行为,496条为入侵网络行为,正常网络行为的数据比例约为98%,测试集B1和测试集B2用来检测算法的性能。
表1是以B1为测试集,改进前后的聚类精度及检测结果对比。

表1 检测率(%)及聚类精度(Intra-cluster distance)对比
由表1的实验结果可见,改进后检测率及Intra-cluster distance值都有进一步的提高,已经能够获得所有被不合理聚类的攻击数据,Intra-cluster distance提升率约为7.43%,说明簇的紧凑度有较明显的提高。同时,在聚类过程中存在将训练集中本应属于同一个簇的数据划分为多个子簇的现象,影响了检测时的速度,使得含有较少样本的正常类型簇在簇的标记过程中被误判为异常簇,导致误报率上升的现象。为解决这一问题,在聚类结束后使用簇的合并算法[3],将含有较少样本的子簇与其相似簇合并。
表2给出使用测试集B2对未知攻击类型的测试结果。算法对未知攻击类型的检测率约为58%。说明对未知攻击类型具有一定的检测能力。

表2 对未知类型的检测
表3是同其它文献中方法的对比,加下划线的数据为最优结果。

表3 与其它文献使用方法的对比
由表3的检测结果对比表明,加权聚类算法对DOS,U2R,R2L三个攻击类型的检测率有所提升,但是对Probe,normal类型的检测还存在一定的差距。
5 结束语
应用kdd cup 99入侵检测数据集对加权聚类算法进行了验证,将数据集中的数值型属性进行标准化后用于聚类算法训练。在检测过程中,算法分别测试了已知入侵和未知入侵两种情况,通过对已知入侵的测试来检测算法的检测率和误报率,通过对未知入侵来测试算法的适应性。加权聚类算法的聚类精度和检测结果都有较明显提高。
[1]吕志军,郑瑞,黄皓.高速网络下的分布式实时入侵检测系统[J].计算机研究与发展,2004,41(4):667-673.
[2]Lih-Chyau Wuu,Chi-Hsiang Hung,Sout-Fong Chen.Building intrusion pattern miner for Snort network intrusion detection system[J].The Journal of Systems and Software,2007,80(10):1699-1715.
[3]Animesh Patcha,Jung-Min Park.An overview of anomaly detection techniques:Existing solutions and latest technological trends[J].Computer Networks,2007,51(12):3448-3470.
[4]Eskin E,Arnold A,Prerau M,et al.A Geometric Framework for Unsupervised Anomaly Detection:Detecting Intrusions in Unlabeled Data,2002[C].Applications of Data Mining in Computer Security.2002:26-29.
[5]向继,高能,荆继武.聚类算法在网络入侵检测中的应用[J].计算机工程,2003,29(16):48-49,185.
[6]徐菁,刘宝旭,许榕生.基于数据挖掘技术的入侵检测系统设计与实现[J].计算机工程,2002,28(6):9-10,169.
[7]闫伟,张浩,陆剑峰,等.聚类分析理论研究及在流程企业中的应用[J].计算机工程,2006,32(17):19-21,27.
[8]雷小锋,何涛,李奎儒,等.面向结构稳定性的分裂-合并聚类算法[J].计算机科学,2010,37(11):217-222.
[9]杜强,孙敏.基于改进聚类分析算法的入侵检测系统研究[J].计算机工程与应用,2011,47(11):106-108,181.
[10]延皓,张博,刘芳,雷振明.基于量值的频繁闭项集层次聚类算法[J].北京邮电大学学报,2011,34(6):64-68.
[11]阎慧,曹元大.一种基于入侵统计的异常检测方法[J].计算机工程与应用,2002,38(22):48-50.
[12]蒋建春,马恒太,任党恩,等.网络安全入侵检测:研究综述[J].软件学报,2000,11(11):1460-1466.
[13]Dunn JC.A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters[J].J.Cybernetics,1973(3):32-57.
[14]Portnoy L,Eskin E,Stolfo S J.Intrusion Detection with Unlabeled Data Using Clustering,2001[C].Proceedings of ACM CSS Workshop on Data Mining Applied to Security(DMSA-2001),New York:ACM Press,2001:123-130.
[15]Portnoy L,Eskin E,Stolfo S J.Intrusion detection with unlabeled data using clustering,2001[C].Proceedings of ACM CSSWorkshop on Data Mining Applied to Security(DMSA-2001).Philadelphia,PA,2001:123-130.
[16]Mukkamala S,Janoski G,Sung A H.Intrusion Detection Using Neural Networks and Support Vector Machines,2002[C].Proceedings of IEEE International Joint Conference on Neural Networks,2002:1702-1707.
Research of Application of Clustering Algorithm in Network Intrusion Detection
ZHU Jian1,LU Bing-liang2,QU Chao-yi3
(1.Shenyang Aeronautical Vocational College,Shenyang 110034,China;2.School of Computer Science and Engineering,Shenyang Aerospace University,Shenyang 110136,China;3.AVIC Shenyang Aircraft Corporation,Shenyang 110034,China)
The clustering algorithm is used to cluster data set for intrusion detection,the clustering results are analyzed to find the problem of uncompacted division in partof clusters.Therefore,aweighing clustering algorithm is put forward to cluster the data far from the clustering center for solving the problem that clustering results havemany sub-clusters.The results show that the clusters aremore compact and the detection accuracy and speed are increased because of sub-clusters decreased.
Network security;Intrusion detection;Cluster Analysis;Weighted clustering algorithm
10.3969/j.issn.1002-2279.2014.05.012
TP393.07
:A
:1002-2279(2014)05-0040-03
朱健(1971-),男(满族),辽宁北镇人,硕士,教授,高级工程师,主研方向:计算机网络与数据库。
2013-10-9
