基于Lucene对文件全文检索的研究与应用
2014-08-07郭永利卢颖颖
郭永利,卢颖颖
基于Lucene对文件全文检索的研究与应用
郭永利,卢颖颖
分析了Lucene的原理,针对Lucene的IndexReader、IndexSearcher、IndexWriter、Directory的各种不足,研究了不同优化方案,并通过重写源码中的QueryParser限制效率低下的通配符查询及模糊查询,提高了搜索响应速度,最后,文章研究了Lucene的多个应用领域。
搜索引擎;全文搜索;分词;索引;优化
0 引言
随着网络技术飞速发展,产生了大量数字信息,如何从这浩如烟海的文本信息中快速而又准确地获取想要的信息,成为人们关注的焦点,也一直是国内外不断研究的课题,因此,全文检索技术成为国内外学者研究的热点。
1 全文检索技术的研究现状
全文检索的主要目的是建立索引与快速查询,以便能使用户快速从海量的信息中搜索出符合条件的信息。当前文本检索有3种建索引方式:倒排索引、下标数组和签名文件,其中最常用的是倒排索引。虽然国外的全文检索软件研究的较早,技术较先进,应用也较广泛,但对中国用户确有很多不适用之处[1]。中文以其独特的单字成词、多字成词、词前词后加字或词亦能成词,使得中文分词的实现比西文分词更为复杂,中文分词算法成为全文检索技术中的一大难题。
目前最流行的全文检索技术是Lucene,由于Lucene具有开放性及扩展性等优势,所以利用Lucene建立电子公文检索系统,一方面可以真正的实现全文检索,另一方面也可以在成本比较低的情况下扩充其功能。
2 Lucene的原理分析
2.1 分词概述
不同的语言有不同的分词,对于中国人来说主要关注的是中文分词。中文分词比英文分词要困难、复杂的多,具体表现在:
(1)在英文中,因其由单词构成句子,单词间以空格隔开,而句子之间又能以标点符号隔开,因此英文分词相对简单。
(2)在中文里,由于其特殊的语法,可以单字成词,多字成词,单字的左右两边分别加上其他的字也可能成词,因此“词”和“词组”边界模糊。
中文分词基本算法主要有:基于词典的方法、基于统计的方法、基于规则的方法。其中基于词典的方法包括正向最大匹配算法、逆向最大匹配、双向最大匹配[2]。MMSeg中文分词算法是基于正向最大匹配的算法,算法描述如下:
步骤1:对文章基于词典进行切割,获得chunks。
步骤2:使用规则1过滤chunks,判断过滤后的chunks个数是否大于或等于2。是:进入步骤3,否:进入步骤7。
步骤3:使用规则2过滤chunks,判断过滤后的chunks个数是否大于或等于2。是:进入步骤4,否:进入步骤7。
步骤4:用规则3过滤chunks,判断过滤后的chunks个数是否大于或等于2。是: 进入步骤5,否:进入步骤7。
步骤5:用规则4过滤chunks,判断过滤后的chunks个数是否大于或等于2。是: 进入步骤6,否:进入步骤7。
步骤6:抛出一个表示歧义的异常。
步骤7:分词成功。
2.2 Lucene索引
(1)Lucene索引文件分析
Lucene采用文件的方式保存索引的信息,文件格式主要有:segment,.fnm,.fdx,.fdt,.tii,.tis,deletable,cfs等[3-4]。每个segment代表Lucene的一个完整索引段。.fnm格式的文件包含了Document中的所有Field名称。.fdx和.fdt是综合使用的两类文件,其中.fdt类型文件用于存储具有Store.YES属性的Field数据。而.fdx类型文件则是一个索引,用于存储Document信息。.tis文件用于存储分词后的词条(Term),而.tii就是它的所有文件,它标明了每个.tis文件中词条的位置。deletable格式用于对删除的文件留一条记录,该记录被删除时,才将索引除去。
复合索引格式用于索引的内容可能非常大,文件数量可能非常多的情况。如果遇到这种情况,系统打开文件的数量巨大将会极大地耗费系统资源。因此,Lucene提供了一个单文件索引格式(复合索引格式)。
(2)倒排索引
在日常的检索中,通常都是按照关键词进行搜索的,所以,倒排索引可以更好地适合这种检索机制的需要,这也是倒排索引如今被大规模使用的原因[5-6]。
倒排索引用到的数据结构如下:
class WordInfo
{
int articleId;
int count;
List
}
Map
WordInfo记录了分词的位置信息与分词的个数,Map中的键值表示了分词内容。算法描述:
步骤1:将文章进行分词,并将分词保存到队列中。
步骤2:判断分词队列是否为空。是: 算法结束,否:进入步骤3。
步骤3:取出队首分词,判断该分词是否已经被存储。是:进入步骤5,否:进入步骤4。
步骤4:创建一个用于保存此分词信息的哈希表。进入步骤5。
步骤5:判断该分词的文章号是否已经被存储。是:进入步骤7,否:进入步骤6。步骤6:创建一个用于保存该文章分词信息的哈希表。步骤7:保存该分词在该文章中出现的位置,并将其个数加一。
步骤8:返回步骤2。
2.3 Lucene搜索
搜索功能定义:Lucene搜索就是通过已经建立好的索引,根据用户要搜索的关键词,将匹配的信息返回给用户。
TermQuery对索引中特定项进行搜索,是最基本的搜索方式。Term是最小的索引片段,每个Term包含了一个域名和一个文本值。
Term term = new Term(“content”,”java”);
Query query= new TermQuery(term);
使用这个TermQuery对象进行搜索,可以返回在content域中包含单词“java”的所有文件。值得注意的是,该查询值是区分大小写的,因此搜索前一定要对索引后的项的大小写进行匹配。TermQuery类在根据关键词查询文件时显得特别适用,具体的创建步骤为:
(1)创建Directory
(2)创建IndexReader
(3)创建IndexSearcher
(4)创建Term和TermQuery
(5)根据TermQuery获取TopDocs
(6)根据TopDocs获取ScoreDoc
(7)根据ScoreDoc获取相应文件
Lucene中的查询功能是非常强大的,它包含了项查询、区间查询、条件查询等各式各样的查询功能,并且可以由用户方便的扩展查询功能。Lucene中自带的查询类主要有:TermRangeQuery、NumericRangeQuery、PrefixQuery、BooleanQuery、PhraseQuery、WildcardQuery、FuzzyQuery、Queryparser等。
2.4 Lucene评分
查询q相对于文档d的分数与在文档和查询向量之间的余弦距离或者点乘积有关系,文档和查询向量存于一个信息检索(的向量空间模型)之中。一篇文档的向量与查询向量越接近,它的得分也越高,如公式(1):
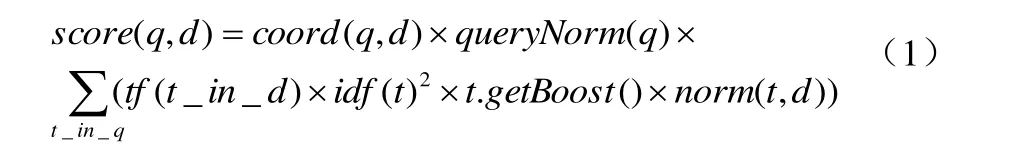
其中tf(t in d) 与term的出现次数有关系,term的次数越多的文档将获得越高的分数。缺省的tf(t in d)算法实现在DefaultSimilarity类中,如公式(2):

idf(t) 代表反转文档频率。这个分数与反转的docFreq有关系。缺省idf(t in d)算法实现在DefaultSimilarity类中,如公式(3):

coord(q,d) 是一个评分因子,在搜索的时候起作用,它在Similarity对象的coord(q,d)函数中计算。
queryNorm(q) 是一个修正因子,用来使不同查询间的分数更可比较。缺省queryNorm(q)算法实现在DefaultSimilarity类中,如公式(4):

sumOfSquaredWeights(查询的terms)是由查询Weight对象计算的,例如一个布尔条件查询的计算公式如公式(5):
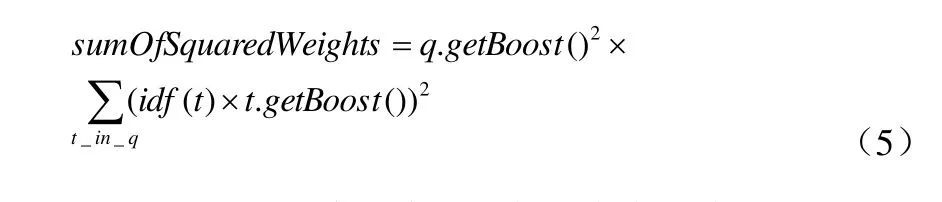
t.getBoost() 是一个搜索时的代表查询q中的term t的boost数值,查询里的一个term的boost值的访问是通过调用子查询的getBoost()方法实现的。
norm(t,d) 是提炼取得一小部分boost值(在索引时间)和长度因子。计算方法如公式(6):
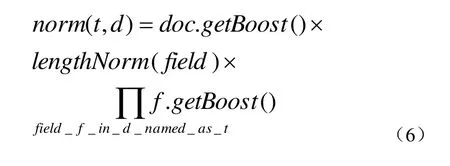
3 Lucene 优化
3.1 IndexReader优化
Indexreader不应当频繁构建,因为每构建一个IndexRe ader实例,都要对索引目录中的索引文件重新加载一遍,不仅增大了服务器的负担,而且大大降低了搜索响应时间。系统中应将IndexReader保存为单例,维持一个IndexReader。并通过采用IndexReader.openIfChanged(IndexReader oldRea der)的方式来获得最新的索引。当索引目录改变时,此方法可以避免加载全部索引,而是只加载更新部分的索引,并且返回最新的索引实例。系统中如果索引没有变化,IndexRe ader.openIfChanged会返回null。因此相对于开启新的Index Reader,该方法成本更低。
3.2 IndexSearcher优化
用IndexReader做为参数构造IndexSearcher时,把reader设为只读,通过避免并发检查,可以提高性能。而尽可能减少IndexSearcher的创建和对搜索结果的前台的缓存也是必要的。
3.3 IndexWriter优化
对IndexWriter进行缓存,让程序中只有一个IndexWriter实例。因为IndexWriter 是对索引库目录下的文件进行操作,就算在多线程情况下,每次也只会有一个线程在访问这个文件。通过在查询中复用,可以大幅度提高搜索的速度,因为每次打开,都会进行索引的加载,影响了性能,对它进行缓存后等于对查询进行了预热。因此,程序中没必要维持多个 IndexWriter实例。
3.4 Directory优化
Directory分为FSDirectory和RAMDirectory。FSDirectory 速度相对慢,但是 FSDirectory 的优点是能够在磁盘上持久化数据。RAMDirectory 读写数据的速度明显要快,但是缺点是数据在程序退出时就没有了。而且受限制于内存的大小。因此可以将两者进行结合,在程序启动的时候,将磁盘上的索引库加载到内存中来。在程序退出的时候或指定一个时机,将内存中的索引库数据状态同步到硬盘上。
3.5 自定义QueryParser优化
由于某些查询方式(FuzzyQuery,WildcardQuery)会降低查询的性能,所以考虑将这些查询取消。并且在具体的查询时,很有可能有这样一种需求:需要获取的是一个数字的范围查询。所以必须扩展原有的QueryParser才能进行查询。
实现思路:继承QueryParser类,并且重载相应方法从而达到限制性能低的查询方式及扩展居于数字和日期的查询的目的。
4 Lucene应用
经过多年的发展,Lucene全文检索以其高效的搜索响应速度,成功渗透进入各行各业,并积累了良好的声誉。本文研究了Lucene在Krugle源码搜索网站中的应用、在LinkedIn.com社区网络中的应用、在网络教学中的应用、在医学知识搜索系统中的应用、Lucene在电子档案检索系统中的应用及在SIREn中的应用,以下详细介绍Lucene前四个方面的应用。
4.1 在Krugle源码搜索网站中的应用
Krugle是一个源代码搜索引擎,连续提供了4000多个开源项目[7]。Krugle是在Lucene基础上搭建的,但由于这里的搜索文件内容都是由代码构成的,这样会为搜索引擎带来一些有趣的挑战。举例来说,当搜索“indexSearcher”时,程序必须匹配源代码中诸如“IndexSearcher”等语汇单元。诸如“=”和“(”等标点符号的搜索可能会在其他搜索网站的分析过程中被忽略,而这里却必须要进行小心处理,以便能搜索到诸如“for(int x=0”等预期结果。与自然语言中通常用停用词来区分各个项所不同的是,Krugle必须保留源代码中所有这些语汇单元。
4.2 在LinkedIn.com社区网络中的应用
LinkedIn.com是世界上最大的专业社区网络,其用户总数超过6000万,该社区的主要功能就是“搜索人”,Lucene加强了LinkedIn的搜索功能。LinkedIn有两个强大的Lucene扩展,分别为Zoie与Bobo Browse。Zoie是一个基于Lucene构建的实时搜索系统。Bobo Browse它能提供分组信息搜索功能,它的开源代码库是基于Lucene构建的,并能对任何基于Lucene的项目添加分组功能。它的索引是由简单的Lucene索引加上一些有关如何将域用于支持分组搜索的声明组成的。这些声明可以通过Spring配置文件的形式加入Lucene索引文件目录,同时可以使用bobo.spring。这些声明还可以通过建立BoboIndexReader类进行程序构建。这种架构上的选择可以使得Lucene索引在不被重新进行构建的情况下实现索引的分组浏览。
4.3 在网络教学中的应用
针对网络教学平台的教育资源研究并定制一个全文检索系统。系统可以采用分词优化组合的分词方案,即用匹配度和检索效率更高的词典/语法切词与具备较大灵活性的单字切分相结合的分词方法,从而达到透彻地分析用户输入的查询请求,以保证检索结果的质量和灵活性[8]。系统对网络教学平台中各种格式的教育资源进行有针对性地文本抽取,如对HTML网页、PDF文件、Offiee文档、Text文件、试题库资源等进行文本抽取,最终转换成建立索引所需要的固定结构,从而支持网络教育平台中各种资源的全文检索。另外,为了更好的改善索引的更新策略,系统采用了定时器启动和手工启动相结合的方案,使得索引的更新变得更加智能化。
医学知识搜索系统属于专业型数据的搜索,因此对于一般的全文搜索无法保证搜索结果的准确性,因此需要使用特殊的搜索引擎,那就是垂直搜索引擎[9]。Lucene 是一个支持全文检索的开源工具包,它提供了查询引擎、索引引擎以及部分语言的分词器。将搜索引擎应用到医学行业,是一个在 Lucene的基础上设计的专门针对医学行业的专业模型,并且结合医学领域特有的需求做了个性化的排序处理。在Lucene提供的框架的基础上,可以方便地进行二次开发,轻易建立完整的桌面或 WEB 全文检索应用。
5 总结
Lucene是两千年初的产物,距今已经有十多年的历史了,这些年来,它一直在不断的更新,其精华不是一朝一夕能研究透的,因此本研究还存在许多遗漏之处。具体表现在:
(1)本文暂时只能对txt文档进行搜索时获得比较好效果,对word之类的文档,由于会添加许多附加格式,会有一些不必要的标签,使得创建的索引存在很大的冗余。不过,tika工具已经很好的对各种类型的文档提取文本内容。
(2)由于Lucene的增删改操作都要进行IO操作,因此,若想进行及时搜索,需要对每一个刚刚添加的文档都进行索引。尽管本研究在最后对性能优化提出了一些建议,但是,若在频繁添加文档的情况下,必将增大服务器的压力,降低系统的性能。一个解决方法就是对索引的添加进行集中操作,在一定时间或者在服务器承受压力较小的某一时间进行添加索引操作。
4.4 在医学知识搜索系统中的应用
(3)本文研究主要以理论为主,加上一些功能实现代码,以控制台的形式展示测试结果,没有较好的可视化界面,在某些程度上影响了研究与测试效率。
[1] Otis Gospodnetic,Erik Hatcher. Lucene In Action中文版(谭鸿,黎俊鸿,周鹏,高承山译)[M],电子工业出版社,2007.
[2] 李雪松.中文分词及其在基于Lucene的全文检索中的应用[D] .广东:中山大学,2007.
[3] 吴众欣,沈家立.Lucene分析与应用[M].北京:机械工业出版社,2008.
[4] 赵汀,孟祥武.基于LUCENE API的中文全文数据库[D].北京:中国科学技术信息研究所,2002.
[5] 刘兴宇.基于倒排索引的全文检索技术研究[D].湖北:华中科技大学,2004.
[6] 王丽云,王华,陈刚.基于Lucene的全文检索系统的设计与实现[J].计算机工程与设计,2007,24(28):5959-5961.
[7] 张蕾.基于Lucene的电子档案检索系统的设计与实现[D].陕西:西安电子科技大学,2010.
[8] 陈宁.Lucene全文检索在网络教学平台中的应用研究[D].辽宁:大连海事大学,2007.
[9] 张平.基于Lucene的医学知识搜索系统设计与实现[D].重庆:重庆大学,2008.
Research and Application of Full-text Retrieval Technology for Document Based on Lucene
Guo Yongli, Lu Yingying
(Nanyang Radio and TV University, Nanyang 473000, China)
This paper analyses the principles and application of Lucene, according to the shortage of IndexSearcher, IndexWriter, Directory, it puts forward some methods to optimize them. and forbids WildcardQuery and FuzzyQuery which is inefficient by override the source code of QueryParser to raise the response speed, at last many applications about Lucene are researched in the paper.
Search Engine; Full-text Search; Word Segmentation; Index; Optimize
TP393
A
1007-757X(2014)01-0051-04
2013.12.22)
郭永利(1978-),男,南阳电视广播大学,讲师,硕士,研究方向:计算机网络,南阳,473000卢颖颖(1979-),女,南阳电视广播大学,讲师,研究方向:计算机网络,南阳,473000
