健康问题和医生匹配机制的研究
2014-08-07朱利岳爱珍
朱利,岳爱珍
(西安交通大学软件学院, 710049, 西安)
健康问题和医生匹配机制的研究
朱利,岳爱珍
(西安交通大学软件学院, 710049, 西安)
针对医疗社区问答系统中的健康问题,提出了一种新的问题回答者推荐机制,以提高问题解决的效率。该机制引入了医生回答问题的态度,将问题-医生的专业匹配程度和医生回答问题的态度关联起来一同考虑;使用概率超图和查询似然语言模型对问题-医生的专业匹配进行建模,利用历史数据对医生的态度进行建模;使用回归模型对问题-医生的专业匹配和态度进行自适应权衡。进行了大量基于真实数据集的实验对所提出的机制进行了验证。实验结果表明:与常用的方法相比,本文所提出的机制准确度能提高30%;很大程度上提高了问题解决的效率。
医疗社区问答系统;问题推荐;概率超图;态度建模
随着信息技术和互联网的发展,医疗社区问答系统作为一种健康知识交流和分享的有效平台开始出现,例如HealthTap、HaoDF和39健康网等。医疗社区问答系统不仅允许咨询者免费咨询健康问题,而且鼓励医生提供可靠的答案,同时也为健康咨询者提供相似问题的检索。
医疗社区问答系统中,问题的增长速度通常比医生的增长速度快得多。一方面,健康咨询者不得不长时间等待医生的回答,等待数小时甚至数天;另一方面,医生往往会淹没在海量的问题中。因此,健康咨询者和医生之间存在一个日渐变宽的鸿沟,急需一个高效的“问题-医生”映射机制来弥补这个鸿沟。
已有的问题回答者推荐研究可以分为两类:全局专家发现方法和主题级专家发现方法。前者是在特定论坛使用来自帖子和回复的链接来衡量专家的权威度[1]。例如Bouguessa等提出使用入度(最优答案数目)来找专家[2];基于链接的HITS算法比入度算法性能要高[3]。除了HITS算法外,另外一个基于链接的PageRank算法在社交媒体中也取得了很大的成功[4]。全局专家发现方法只能找到特定论坛的专家,没有考虑问题内容和专家的专业是否匹配;主题级的专家发现方法则在更细粒度上考虑了问题敏感的专业匹配问题。Zhou等在文献[5]中提出了基于专业的在线论坛问题推荐。Li等在文献[6]中深入研究了分类敏感的语言模型。除了专业估算外,在文献[7]中提出了考虑专家是否在线问题的基于语言模型的框架。主题级专家发现方法虽然可以根据问题的内容找到相应领域的专家,但不能获取专业能力与问题的匹配程度。更重要的是,目前尚未发现考虑专家态度问题的研究。为此,我们提出了一种针对医疗社区问答系统中医生推荐的机制QDM(question-doctor mapping),同时考虑了问题和医生的专业匹配以及医生的态度,能够准确地解决“健康问题医生”之间的映射问题,提高了问题解答的效率。机制主要由3部分组成:①问题和医生的专业匹配建模;②医生的态度建模;③问题-医生的专业匹配和医生态度的自适应权衡。其中,①用来表示医生对问题的专业程度,②用来表示医生回答问题的态度。对于不同的问题,对医生的专业和态度有不同的倾向。因此,③用来自适应地权衡问题-医生专业匹配和医生态度的重要性。
1 问题和医生的专业匹配建模
使用D={d1,d2,d3,…,dn}表示n个医生集合,di表示一个医生。每个医生的信息包括两部分:医生的信息简介和医生回答过的问题答案对。简介部分包括医生的教育背景、出版物、奖励以及来自其他医生和健康咨询者的投票等信息。问题答案对包括问题、答案、和答案相关的标签以及其他医生对答案的赞同情况。我们将医生回答过的问题答案对看作其积累的经验。
使用E(di,q)表示医生di对问题q的专业程度。受文档主题生成模型(latent dirichlet allocation, LDA)的启发,我们认为每个医生的专业知识是综合的,呈现加权分布特征。每种专业被解释为可以使用相同专业知识回答的问题集合。因此,可以得到医生和所给问题的相关程度为
(1)
式中:p(εj|di)表示医生di在专业εj上的专业程度,即医生-专业分布,而p(q|εj)表示问题q需要专业εj解决的概率,即专业-问题分布。
1.1 医生-专业分布
通过对HealthTap上的3 000多个医生的简介进行分析,发现每个医生平均有3.4个专业技能。因此,p(εj|di)的计算就可以看作是在医生集合D上的模糊专业聚类。不像传统的硬聚类,每个医生只属于一个集合。在这里,医生可根据相应概率p(εj|di)属于多个集合。
目前存在多种计算p(εj|di)的聚类技术,例如K均值、LDA和基于简单图[8]的聚类,可是这些方法都存在一些约束。首先,这些方法通常假设所感兴趣的物体之间的关系成对存在。在我们研究的工作中,医生之间的关系比成对关系更复杂,如果简单地将这种复杂关系转换成成对关系将会导致我们想要了解的信息丢失。其次,它们不能处理异构信息。在医疗社区问答系统中,医生通常同时拥有几种关系,例如医生间的社交关联、相似的简介和经验等。为了解决这些问题,我们构建概率超图,然后在超图上进行模糊划分。超图允许超边连接两个及以上的顶点。同时,不同类型的超边可以表示不同的异构关系。
超图(V,E,W)由顶点集合V、超边集合E和超边的权重集合W组成。每条超边e连接两个或两个以上的顶点,且e都分配一个权值w(e)。在所研究的问题中,医生集合D中的n个医生被看作n个顶点。根据医生的信息,可以构建3种类型的超边。对于第一种类型的超边,每个医生作为一个顶点,该医生和与他简介相似度最高的k个医生组成一条超边。这种构建超边的方式在文献[9]中第1次被采用。第1种类型的超边集合定义为E1。第2种类型的超边是基于医生积累的经验。对于每个医生,将他回答过的所有问题答案对合并成一个文档,使用这个文档来表示该医生积累的经验。将具有相同积累经验的医生构建成一条超边,这种超边集合定义为E2。第3种类型的超边利用了医生之间的社交关系。对于超图中的每个医生,将该医生和与他回答过相同问题的医生组成一条超边,这种超边集合定义为E3。
概率超图G可以被表示为|V|×|E|的关联矩阵H,H中的元素为

(2)
式中:p(di,ej)是超边ej连接顶点di的概率。p(di,ej)的定义为

(3)
式中:dej是超边ej连接的医生;S(di,dej)是医生di和医生dej简介(第1类超边)或积累的经验(第2类超边)的相似度。
超边的权重大小表示超边中的顶点属于同一组的可能程度。对于一条超边,它的权重定义为
(4)
式中:di∈ej表示超边ej连接顶点di。
对于每条超边,它的度定义和权重相同
(5)
根据H的定义,顶点di的度为

(6)
在本文中,利用了一种高效且实现简单的算法[10]来划分超图,但是与算法中的超图不同,我们构建的超图是一个概率模型。在构建的超图上定义了正则项

(7)
式中:矩阵f∈RD包含了每个医生和想要学习的、潜在的专业类别相关概率。通过定义,可得

(8)
式中:I是单位矩阵。定义Δ=I-Θ,Δ是一个半正定矩阵,即超图的拉普拉斯算子[10]。Ω(f)可被重新写为
(9)

1.2 专业-问题分布
p(q|εj)=p(q|qεj)
(10)
(11)
根据Jelinek-Mercer平滑法得
P(w|qεj)=(1-α)P(w|qεj)+αP(w|C)
(12)

(13)

(14)
式中:C是所有的问题集合;α是一个调整平滑权重的加权系数;f(w,qεj)表示项w在专业εj的问题集合qεj中出现的频率;f(w,C)表示项w在所有问题集合C中出现的频率。根据经验值,设置α=0.8。至此,可以得到每个医生和给定问题的专业相关程度E(di,q)。
2 医生态度建模
除了问题和医生的专业匹配外,根据文献[12]中的研究,我们假设问题答案的质量也取决于医生的态度。根据医疗问题回答系统中的可用信息,本文从积极性、责任感和声誉3个不同的角度对医生的态度进行建模。这些都需要使用历史数据进行估算,它们的乘积表示医生的态度。
积极性可用来测量问题出现时医生的积极程度。积极性的定义为
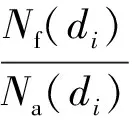
(15)
式中:Nf(di)表示医生di是第1个问题回答者的问题数目;Na(di)表示医生di回答的问题数目;A(di)表示医生di回答问题的积极性,A(di)越大,医生di回答问题的时间就越短。
责任感用来测量医生对给定问题回答的满意程度,它直接反映在答案质量上。我们认为如果一个医生di回答了问题q,则di有相应的专业能力解决q。同时,如果提供的答案被其他医生选为最优答案,我们认为医生di对该答案有责任。di的责任感的估算为
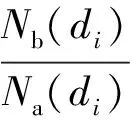
(16)
式中:Nb(di)表示医生di提供的答案被选为最优答案的数目。
医生的声誉是指其他医生和健康咨询者对这个医生的看法或想法。本文使用取值范围在0~1之间的Sigmoid函数来估算名声。

(17)
式中:Np(di)和Ns(di)分别表示支持医生di的医生和健康咨询者的数目。
3 专业匹配和态度自适应权衡
对于一个新的用自然语言描述的问题q,我们的目标是从D中选择出一些匹配的医生,并且将q推荐给这些医生。匹配分数为
S(di,q)=(1-λ)E(di,q)+λA(di)
(18)
式中:E(di,q)是问题和医生的专业匹配模型,表示从专业的角度考虑医生di可以回答问题q的可能性。A(di)是态度模型,可以从历史行为中推测出来。另外,λ是一个自适应的参数,用来平衡专业和态度的影响。
根据观察,不同的问题对专业和态度有不同的倾向。对于简单问题,入门级医生就可以回答。这种问题答案的质量主要由医生的态度决定而不是医生的专业知识。对于高难度问题,需要根据病人症状找出发病的原因以及告诉病人应该如何做,此时医生的专业知识对于给出高质量回答起到了主要作用。因此可以得出结论,参数λ是一个关于给定问题的自适应函数,它平衡专业和态度对答案质量的重要性。当λ=1时,给定的问题将被推荐给态度最好的医生,而他们的专业能力将被忽视。相反,如果λ=0,将不考虑医生的态度问题。
将λ的自适应估计任务看作监督回归问题,其目标是根据类似训练问题的有效权重,为每个新的问题预测一个合适的权重。对于训练集中的每个问题,首先使用固定的λ来估算问题推荐的性能。λ的最优值通过在[0,1]之间使用固定步长得到。利用这些最优值作为真实值来训练回归模型。在实验中,使用了线性回归、保序回归和pace回归等不同的回归模型。
4 实 验
4.1 实验设置
在实验中使用了从HealthTap上收集的3 123个医生的简历。每个医生的简历包括医生的简介和该医生以前回答过的问题答案对。表1展示了我们统计的实验数据。
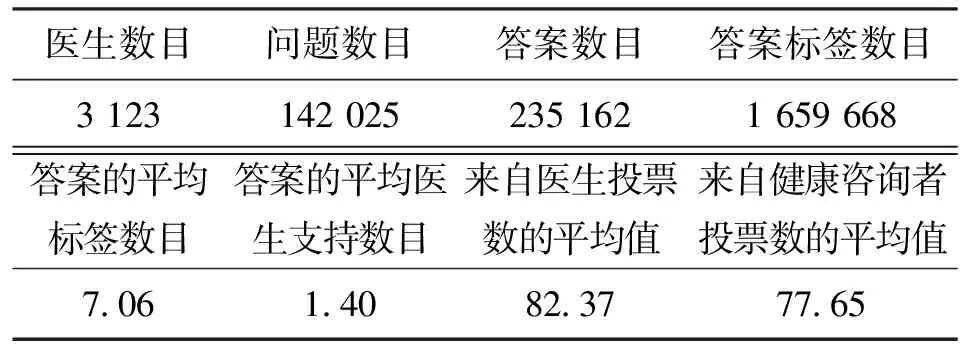
表1 收集到的数据的统计
本文使用了基于LDA的主题级别的数据表示。对于一个数据集,LDA按照语义将内部相关联的健康概念分配到一个潜在的组,它可以按照主题描述健康数据的底层语义结构。每个潜在组被视为一维特征。特征空间维度通过困惑度(perplexity)[10]得到。困惑度是一种计算统计模型,设为

(19)
式中:li表示di的词数。困惑度的值越小表示所用的LDA模型越好。我们将医生的简历分为两部分,80%的数据用来训练LDA模型,20%用来评估性能。LDA建模和困惑度矩阵通过Stanford建模工具集来实现。当潜在组的组数变化时,困惑度取值如图1所示。由图1可知,当潜在组数为110时,困惑度最低。因此,对于给定的一个医生或者问题,它可以表示成110个语义主题级别特征的混合。

图1 困惑度随专业类别数变化曲线
对于随后的主观评价,我们邀请了3个来自不同背景的自愿者并进行了训练。在3个志愿者中采用多数表决方案来解决有分歧的问题。对于那些有两类选票数相同的情况,通过讨论来获得最后的决定。
4.2 问题推荐性能比较
对于专家推荐问题,准确度是最重要的性能指标。因此,采用了客观评估和主观评估两种指标从不同的方面获取准确度。从数据集中随机选择了1000个问题作为测试样本。对于客观评估,采用了平均的H@K[13]。如果真正回答该问题的医生排在前K位,则认为H@K=1,否则H@K=0。这种评估方法的优点是使用了真实数据且不需要构建其他的真实值。可是这种评估方法可能受这种场景的影响,医生di回复了问题q,尽管医生dj有能力回答问题q,但由于未知的原因没有回答问题。尽管本文提出的机制很可能将dj排在一个高的位置,但是H@K却忽略了。因此,H@K不能全面公平地评估本文提出的推荐机制。
作为对H@K的补充,采用了主观的指标S@K,来测量在推荐的K个医生中能找到一个匹配的医生回答问题的概率,即如果推荐的前K个医生中有能力回答该问题,则S@K=1,否则S@K=0。不同于主观评估,此时的真实值需要志愿者手动构建。他们需要查看医生的简介和历史数据,如果认为某个医生有能力并且有可能回答这个问题,将标记该医生有能力回答该问题,否则标记不能回答该问题。本文中使用Kappa分析[14]来评估志愿者间的一致性。Kappa的值在0~1之间,值越大,一致性越高。Kappa值大于0.7表示一致性很强。在本文的工作中,采用了在线的Kappa计算工具。表2展现了分析结果,结果证明它能标记志愿者之间的一致性。

表2 使用Kappa方法的志愿者之间的一致性评估
我们将本文提出的问题推荐机制与最新技术进行了比较。为了确保公平,它们将同时考虑或不考虑态度问题。
K均值为医生-专业相关程度使用K均值估算的机制。LDA为医生-专业相关程度使用LDA估算的机制。
由于K均值的结果是离散的,只能得到一个医生是否属于某个专业类别,而得不到该医生属于某个专业类别的概率。为了得到医生属于某个专业类别的概率,本文使用下式计算

(20)
式中:半径参数σ是所有医生对之间的欧氏距离的均值,cj是专业类别εj的中心。
图2和图4分别列出了使用H@K和S@K来评估推荐性能的对比结果。当引入医生的态度时,结果在图3和图5中给出。由图可见,本文方法的性能明显高于其他方法。综合分析这4个图可以看出,考虑医生态度时的性能要高于不考虑医生态度时的性能,这证明了医生的态度确实影响答案的质量。另一方面,实验结果也证明使用自适应的λ来平衡专业匹配和态度的影响比使用固定λ的要优越。

图2 不考虑医生态度时使用H@K评估的性能比较

图3 考虑医生态度时使用H@K评估的性能比较

图4 不考虑医生态度时使用S@K评估的性能比较

图5 考虑医生态度时使用S@K评估的性能比较
4.3 专业和态度权衡
从数据集中随机选择了1000个问题。对于每个问题,使用固定步长0.05在[0,1]之间找到了最优性能。为了节省时间,性能通过H@K测量。这些问题分为两部分,80%用来训练,20%用来测试。我们采用了4种回归模型,它们的性能比较见表3。可以看出,pace回归模型取得了最好的性能。对于一个新问题,它的自适应参数λ是可预测的,这个值影响到问题需要对医生的专业更关注还是对态度更关注。

表3 使用平均绝对误差回归模型的性能比较
5 结 语
本文研究的医疗社区中的问题推荐方法包含3个主要步骤:①对医生和问题的专业匹配度进行建模;②从积极性、责任感和名声3个角度对医生的态度进行建模;③根据问题的内容自适应地权衡问题和医生的专业匹配和医生态度的影响。实验证明,本文提出的“健康问题-医生”推荐机制具有很高的准确度和问题回答效率,可实际应用于网上医疗社区中,能够弥补目前这个应用方面的空白。
由于目前很难获得中文的问题集,本文的方法和实验都是针对英文问题集的。后面我们将通过技术方法收集中文数据集,来验证本文提出机制的通用性,并尝试将该机制应用到其他领域。
[1] JURCZYK P, AGICHTEIN E. Discovering authorities in question answer communities by using link analysis [C]∥Proceedings of the 16th ACM Conference on Information and Knowledge Management. New York, USA: ACM, 2007: 919-922.
[2] MOHAMED B, BENOIT D, WANG Shengrui. Identifying authoritative actors in question-answering forums: the case of yahoo! answers [C]∥Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2008: 866-874.
[3] KLEINBERG J M. Authoritative sources in a hyperlinked environment [J]. Journal of the ACM, 1999, 46(5): 604-632.
[4] ZHOU Guangyou, LAI Siwei, LIU Kang, et al. Topic-sensitive probabilistic model for expert finding in question answer communities [C]∥Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2012: 1662-1666.
[5] ZHOU Yanhong, CONG Gao, CUI Bin, et al. Routing questions to the right users in online communities [C]∥Proceedings of the 25th IEEE International Conference on Data Engineering. Piscataway, NJ, USA: IEEE, 2009: 700-711.
[6] LI Baichuan, KING I, LYU M R. Question routing in community question answering: putting category in its place [C]∥Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2011: 2041-2044.
[7] LI Baichuan, KING I. Routing questions to appropriate answerers in community question answering services [C]∥Proceedings of the 19th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2010: 2041-2044.
[8] 苏金树, 张博锋, 徐昕. 基于机器学习的文本分类技术研究进展 [J]. 软件学报, 2006, 17(9): 1848-1859. SU Jinshu, ZHANG Bofeng, XU Xin. Advances in machine learning based text categorization [J]. Journal of Software, 2006, 17(9): 1848-1859.
[9] HUANG Yuchi, LIU Qingshan, ZHANG Shaoting, et al. Image retrieval via probabilistic hypergraph ranking [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 3376-3383.
[10]HUANG Yuchi, LIU Qingshan, LV Fengjun, et al. Unsupervised image categorization by hypergraph partition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(6): 1266-1273.
[11]ZHAI Chengxiang, LAFFERTY J. A study of smoothing methods for language models applied to information retrieval [J]. ACM Transactions on Information Systems, 2004, 22(2): 179-214.
[12]GUAGNANO G A, STERN P C, DIETZ T. Influences on attitude-behavior relationships [J]. Journal of Environment and Behavior, 1995, 27(5): 699-718.
[13]XUAN Huiming, YANG Yujiu, PENG Chen. An expert finding model based on topic clustering and link analysis in CQA website [J]. Journal of Network and Information Security, 2013, 4(2): 165-176.
[14]WARRENS M J. Inequalities between multi-rater kappas [J]. Advances in Data Analysis and Classification, 2010, 4(4): 271-286.
[15]NIE Liqiang, YAN Shuicheng, WANG Meng, et al. Harvesting visual concepts for image search with complex queries [C]∥Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2012: 59-68.
(编辑 武红江)
RoutingHealth-OrientedQuestionstoAppropriateDoctors
ZHU Li,YUE Aizhen
(School of Software Engineering, Xi’an Jiaotong University, Xi’an 710049, China)
A novel mechanism connecting health seekers to appropriate doctors is proposed to improve the efficiency of question resolving in community-based health service systems. Attitudes of doctors answering questions are introduced in the mechanism, and both the professional matching degree between doctors and questions and the doctor’s attitudes are associated and considered at the same time. The probabilistic hypergraph and the query likelihood language model are used to model the professional matching degree, and a doctor’s attitude is modeled from his historical data. Meanwhile, a regression model is used to trade off between the professional matching degree and the doctor’s attitude. Extensive experimental results on several real-world datasets show that the matching precision of the proposed mechanism increases by about 30%, and the efficiency of resolving problems is greatly improved.
community-based health service system; question routing; probabilistic hypergraph; attitude modeling
2014-5-20。
朱利(1968—),男,副教授。
国家重点基础研究发展规划资助项目(2012CB327902HZ)。
时间:2014-10-31
10.7652/xjtuxb201412009
TP181
:A
:0253-987X(2014)12-0057-06
网络出版地址:http:∥www.cnki.net/kcms/detail/61.1069.T.20141031.1643.017.html
