一种工业酶非分类关系抽取仿真研究
2014-08-03徐一红
徐一红
(山东管理学院机电学院,山东 济南 250100)
本体是概念模型的明确规范说明[1],是描述某个领域内的概念以及概念间的关系,使得这些概念和关系在共享的范围内具有大家共同认可的、明确的、唯一的定义[2].近年来,本体被广泛应用到语义web、智能信息检索、信息集成及人工智能等多个领域.但是本体的构建大多采用人工构造,需耗费大量的人力、物力,本体学习应运而生.非分类关系是本体学习中的高层概念.当前,国外对英文非分类关系的提取常采用3种模式:词汇-句法模式[3]、句法分析模式[4]以及关联规则模式[5].文献[6]中对英文,利用了词汇-句法模式和关联规则模式抽取英文的非分类关系.中文本体非分类关系抽取的研究相对较少,文献[7]大多利用挖掘关联规则的方式抽取中文的非分类关系.
一些科研人员意识到了关联规则挖掘在中文非分类关系抽取中的应用价值.仿生智能算法以其寻优速度快,鲁棒性强等优势已成挖掘关联规则的重要研究算法,应用较广泛的有Marco Dorigo在1992年提出的蚁群算法(ACO)[8], 1995 年由Eberhart博士和Kennedy博士提出的粒子群算法(PSO)[9],Ferreira于2001年提出的基因表达式编程算法(GEP)[10],Karaboga在2005年提出的人工蜂群算法(ABC)[11],Yang于 2008 年提出了一种启发式随机优化算法——萤火虫算法 (FA)[12].FA算法在函数寻优方面得到了广泛应用[13],但由于FA算法本身的局限性易使寻优陷入局部最优.本文提出了一种基于小生境技术的萤火虫算法,该方法整合了萤火虫算法及小生境技术的优势,克服了传统方法存在的容易出现早熟现象和易陷入局部最优的问题,在有效规则的抽取效率上优于传统的算法.
1 基本概念
1.1 萤火虫算法(FA)[12]
萤火虫算法是模拟自然界中萤火虫的生物特性发展而来的,通过迭代完成寻优的一种随机搜索算法.萤火虫算法包含2个要素,即亮度和吸引度.亮度体现了萤火虫所处的位置的好坏,吸引度决定了萤火虫移动的距离,通过吸引度和亮度的不断更新实现目标寻优.
萤火虫的相对荧光亮度为式(1):
I=I0×e-γrij.
(1)
I0定义为萤火虫的最大荧光亮度,γ为光强吸收系数,一般设为1.0,rij为萤火虫i与j之间的距离.
萤火虫的吸引度为式(2):
(2)
β0定义为最大吸引度,γ,rij意义同式(1).
萤火虫i被萤火虫j移动的位置更新由式(3)定义:
xi=xi+β×(xj-xi)+α×(rand-1/2). (3)
1.2 小生境技术
小生境是指生物在进化过程中的一种生存环境,在小生境中同种生物存在着信息交换及相互竞争.小生境技术的基本思想是根据个体之间的相似特征形成多个小生境,在各个小生境中利用融合及演化机制对个体进行调整,以保证种群的多样性,同时根据平均适应度的变化,对规模的大小进行动态调整[14-15].
在萤火虫算法中引进小生境技术的概念, 让个体在不同的小生境环境中进化,而不是全部聚集在一种环境中,这样可以使算法在整个解空间中搜索,以找到更多的最优个体.
小生境融合算法流程设计如下:
Step1:把n个小生境个体(nich1,…,nichn,分别为S1,…,Sn)全部存入nich1中;


小生境演化算法流程设计如下:
Step1:执行萤火虫算法得到子代G;将子代G与父代合并得P(t+1)=P(t)∪G;
Step2:在P(t+1)上执行小生境融合算法;对其进行笛卡儿交叉,得到非劣集合OP(P(t+1),);
Step3:选取子代中适应度函数值最高的5%个体替换父代较差个体.
2 工业酶非分类关系抽取组合模型
2.1 适应度函数
适应度函数的设计对寻优结果的影响非常重要[16].在挖掘关联规则中,由于支持度及置信度是关联规则挖掘的重要参数,分析中文非分类关系数据特点,组合模型的适应度函数f(i)定义如下:
(4)
spt(i)、cnf(i)分别是第i条规则的支持度值和置信度值;min-spt、min-cnf分别是最小支持度和最小置信度.
2.2 萤火虫算法挖掘强关联规则
设I={i1,i2,…,im}是m个项目构成的集合,关联规则的表示可以定义为R:X⟹Y,其中:X⊂I,Y⊂I且X∩Y=∅,同时大于最小支持度min-spt和最小置信度min-cnf的规则被定义为强关联规则[17-18].强关联规则的挖掘过程可描述为个体聚集在亮度最高的萤火虫的位置上,实现寻优的过程,其中萤火虫i与j的坐标位置设置如下:首先对文档按抽取的有效概念个数进行排序,对排好序的文档依次抽取有效概念,按出现次数对有效概念从大到小依次排序,去除重复概念,构成有效概念序列,组对(X-Y)出现的下标即为概念X和概念Y的序列号.
萤火虫算法实现寻优的过程如下:首先随机产生萤火虫群体,每一只萤火虫因所处位置不同,根据式(4)适应度函数值也不同,通过比较适应度函数值,适应度函数值高的萤火虫吸引适应度函数低的萤火虫向自己移动,根据式(2)吸引度的大小决定移动的距离.为了避免过早陷入局部最优,在更新过程中增加了干扰项α×(rand-1/2),能扩大解的多样性,根据式(3)计算更新取整后的位置.通过多次寻优迭代后,萤火虫个体将聚集在亮度高的萤火虫位置上,从而实现寻优.萤火虫行为与强关联规则挖掘对应关系如表1所示.
FA算法挖掘强关联规则流程设计如下:
Step1:初始化参数.包括:萤火虫个数m,最大吸引度β0,光强吸收系数γ,步长因子α,最大迭代次数maxT,随机生成萤火虫的位置.
Step2:按照式(4)和式(2)计算萤火虫的相对荧光亮度和吸引度,根据荧光亮度决定萤火虫的移动距离.
Step3:根据式(3)更新萤火虫的空间位置,对处在最佳位置的萤火虫进行随机扰动.

表1 萤火虫寻优行为与强关联规则对应关系
Step4:根据更新后萤火虫的位置,重新计算萤火虫的荧光亮度.
Step5:当达到最大搜索次数则转下一步;否则,搜索次数增加1,转Step2,进行下一次搜索.
Step6:输出强关联规则.
算法的时间复杂度为O(m2),m是萤火虫数目.
2.3 组合模型设计
组合模型的基本思想是通过普通的关联规则法,可得出具有非分类关系的概念对[20].萤火虫算法的本质是模拟萤火虫的随机寻优原理,由于算法自身的特点易使算法陷入局部最优,针对这一问题,本文利用小生境技术的演化、融合算法增加种群的多样性,能够解决传统的萤火虫算法过早陷入局部最优的问题,使寻优过程更加优化.其流程设计如下:
Step1:将本体概念集随机平均分配到各小生境中;
Step2:如果满足结束条件,则执行Step7,如果不满足结束条件则继续执行;
Step3:执行小生境演化、融合算法;
Step4:如果存在相似的个体,则去除适应度小的个体,添加随机个体;
Step5:转到Step2继续执行;
Step6:生成频繁项集;
Step7:输出非分类关系.
2.4 评价函数
评价多样性的分析函数定义如下:
(5)
其中:N是群体的规模;dm,n表示个体之间的距离.
3 算法验证
3.1 强关联规则
为验证算法的可靠性,从中国知网选取2012年120篇关于工业酶的文章作为领域文本集,背景语料集选取中文文本分类语料库TanCorpV1.0中的12个类别的语料库.在这些关于工业酶的文章中,利用概念提取算法[19],得到2 044个有效概念,对获得的有效概念进行统计,设阈值为10,得到143个有效概念,其中次数最高者为工业酶,共343次;次数最少者为棉线磨光等56个候选术语,仅用1次.在这些本体概念上对非分类关系进行抽取实验,取min-spt=0.1,min-cnf=0.8, 抽取关系747个.其中次数最高者为“制剂——产品”,其频次为2.92,频次超过0.1的关系有160个,得到关系如表2所示.

表2 关系抽取结果
3.2 与其他算法的比较
分别应用Apriori算法、萤火虫算法与组合模型进行验证,所有实验运行100次,实验结果如表3所示.

表3 工业酶非分类关系
综合比较可以发现,组合模型比FA算法、Apriori算法在运行效率、挖掘有效关联规则的数量以及平均适应度上都有较明显的提高.
图1是萤火虫算法与组合模型的多样性对比.通过分析可以发现,随着迭代的增加,FA算法与组合模型的多样性都呈下降趋势,但是组合模型的多样性进化到800代时保持较高,解决了FA算法易陷入局部最优的问题,为不断获得新解,获取全局最优提供了保障.
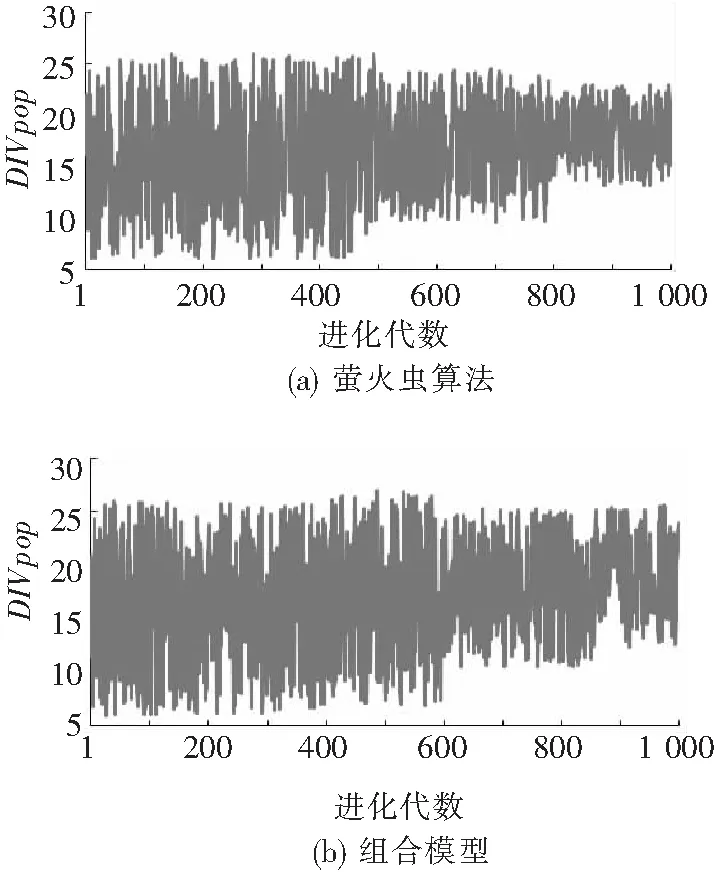
图1 个体多样性对比
图2是FA算法与组合模型迭代过程的平均适应度比较.通过对比可以发现,组合模型的平均适应度与FA算法的平均适应度都逐渐增加,但组合模型的平均适应度明显高于FA算法的平均适应度.
4 结 语
非分类关系抽取的研究在国内才刚刚起步,本文在借鉴已有的挖掘关联规则的经验基础上,提出一种基于小生境技术的萤火虫算法,该算法利用小生境技术的融合、演化算法丰富种群的多样性,结合萤火虫算法寻优速度快的优势抽取非分类关系.通过验证性实验,相对于传统的挖掘算法,该组合模型在效率、有效规则个数及平均适应度上都有明显提高.
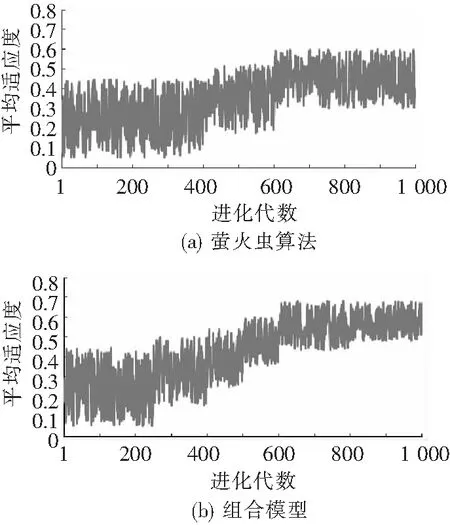
图2 平均适应度对比
通过工业酶语料数据的继续添加和合理的参数设定,以及尽量减少分词和句法分析错误对结果造成的影响,该组合模型可为工业酶非分类关系抽取提供更有价值的参考.
参考文献:
[1]Gruber T R. A translation approach to portable ontology specifications[J]. Knowledge acquisition,1993,5(2):199-220.
[2]杜小勇,李曼,王珊.本体学习研究综述[J]. 软件学报,2006,17(9):1832-1842.
[3]Girju R,Moldovan D I. Text Mining for Causal Relations[C]//FLAIRS Conference, Florida: AAAI Press,2002: 360-364.
[4]Ciaramita M, Gangemi A, Ratsch E, et al. Unsupervised Learning of Semantic Relations between Concepts of a Molecular Biology Ontology[C]//IJCAI, Edinburgh: Professional Book Center,2005: 659-664.
[5] Maedche A, Staab S. Discovering Conceptual Relations from Text[C]//Ecai,Berlin: Werner Horn IOS Press, 2000, 321(325): 27.
[6]李林,刘贺欢,刘椿年.Ontology自动构造平台OntoAGS[J]. 计算机工程,2006,32(13):212-214.
[7]方卫东,袁华,刘卫红.基于Web挖掘的领域本体自动学习[J]. 清华大学学报:自然科学版,2005,45(增刊1):1729-1733.
[8]Kennedy J. Particle Swarm Optimization[M]//Encyclopedia of Machine Learning. New York: Springer US, 2010: 760-766.
[9]Von Frisch K. Decoding the language of the bee[J]. Readings in Zoosemiotics, 2011, 8: 141.
[10] Ferreira C. Gene expression programming: a new adaptive algorithm for solving problems[J]. Complex Systems, 2001, 13(2): 87-129.
[11]Yang Xinshe. Nature-inspired Metaheuristic Algorithms[M]. UK:Luniver Press, 2010.
[12] Yang Xinshe. Firefly Algorithms for Multimodal Optimization[M]//Stochastic Algorithms: Foundations and Applications. Berlin Heidelberg: Springer, 2009: 169-178.
[13] Jumadinova J, Dasgupta P. Firefly-inspired Synchronization for Improved Dynamic Pricing in Online Markets[C]//SASO.Venezia:IEEE Press,2008: 403-412.
[14]黄钢,扬捷,李德华,等.基于GEP与小生境的关联规则挖掘的研究[J]. 计算机应用研究,2009,26(1):56-58.
[15]崔挺,孙元章,徐箭,等. 基于改进小生境遗传算法的电力系统无功优化[J]. 中国电机工程学报,2011,31(19):43-50.
[16]沈国强,覃征.一种新的多维关联规则挖掘算法[J]. 小型微型计算机系统,2006,27(2):291-294.
[17]Xu Chuanfan,Duan Haibin. Artificial bee colony (ABC) optimized edge potential function (EPF) approach to target recognition for low-altitude aircraft[J]. Pattern Recognition Letters,2010,31(13): 1759-1772.
[18]潘庆先,于萍,娄兰芳.关联规则算法的研究及其在教学评价中的应用[J]. 烟台大学学报:自然科学与工程版,2010,23(2):127-131.
[19]温春,石昭祥,辛元.基于扩展关联规则的中文非分类关系抽取[J]. 计算机工程,2009,35(24):63-65.
