高光谱图像贝叶斯分类算法GPU并行优化研究
2014-08-01赵海娜吴远峰高建威张兵
赵海娜,吴远峰,高建威,张兵
(1.中国科学院 遥感与数字地球研究所 数字地球重点实验室,北京 100094;2.中国科学院大学,北京 100049)
1 引 言
当今遥感技术正朝着更高空间分辨率、更高时间分辨率和更高光谱分辨率方向发展,这给海量遥感图像分类带来了新的挑战,尤其在灾害监测、战场目标探测以及智能卫星系统等时效性要求较高的应用领域的挑战尤为突出[1-2]。
贝叶斯分类方法具有坚实的数学理论基础以及综合先验信息和数据样本信息的能力,是遥感图像分类的实用方法[3-4]。但基于CPU的贝叶斯串行分类算法在处理较大图像时非常耗时。
传统遥感图像分类加速处理多采用由CPU组成的分布式集群系统的处理模式[5-7]。但是集群系统价格昂贵、体积大、灵活性差,很难应用到战场或星上等要求低重、高灵活性等场景。
近几年来,国内外许多研究将GPU用在遥感影像融合、混合像元分解和实时目标探测等领域,对算法进行了加速处理,获得高效的并行计算能力[8-10]。图形处理器(Graphic Processing Unit,GPU)具有运算密集、高度并行、体积小和性价比高等特点,为解决数据密集型的计算提供了有利条件[11]。本文针对贝叶斯分类算法面临大数据量图像处理速度问题,提出了基于GPU的贝叶斯并行分类算法,并从数据传输和核函数设计两方面对并行算法进行了优化设计。实验结果表明,基于GPU的贝叶斯并行分类算法(以下简称并行算法)与基于CPU的串行算法(以下简称串行算法)相比,在保证分类精度的同时,分类效率明显提高,能够获得25倍~54倍的加速比。
2 贝叶斯分类算法
2.1 算法流程
定义遥感图像为X,band、sample和line分别代表波段数、列数和行数。x={a1,a2,…,am},(m=band)为其中的一个像元,ai为x的一个特征属性;Y={y1,y2,…,yn}代表类别,n为类别数,D={d1,d2,…,dn}为训练样本,其中di代表每一类的训练样本的个数。贝叶斯分类方法[3-4]是一种基于统计模型的分类方法,并假设各对象之间是条件独立的[12],其原理是基于某地物的先验概率,利用贝叶斯公式计算出其后验概率,即该地物属于某一类的概率,选择具有最大后验概率的类作为该地物所属的类。计算步骤如下:
①计算训练样本中每个类别的先验概率
(1)
②计算训练样本的均值μyi和标准差σyi;
③根据样本均值、标准差计算每个类别条件下各个特征属性条件概率
(2)
p(x|yi)p(yi)
=P(a1|yi)P(a2|yi)…P(am|yi)P(yi)
(3)
⑤用分类器进行分类,选择概率最大的类作为X的所属类别,对每一像元进行分类。
2.2 贝叶斯分类算法计算复杂度分析
2.1节中步骤①和步骤②计算了训练样本各类别的先验概率以及均值和标准差,计算过程简单并且计算量很小,因此在整个算法中这两步运算的复杂度可以忽略不计。实验中将先验概率、训练样本的均值标准差作为已知。
表1是步骤③~步骤⑤对于处理分类类别为n,图像尺寸为line×sample×band的图像的时间复杂度。从以上的分析可以看出,数据量对算法复杂度的影响非常大,数据量的增加会严重影响算法的计算效率。

表1 各处理过程计算时间复杂度
3 基于GPU的分类算法并行优化
在CUDA架构下,程序计算分为在CPU上执行的host端和在GPU上执行的device端。Host端负责算法流程的控制以及简单的计算;device端负责图像的数据级并行计算[13]。根据上一节对贝叶斯算法复杂度的分析,基于CUDA对算法进行并行设计时,将计算流程拆分成两部分:①数据读写、GPU初始化、函数调用等流程控制逻辑由CPU执行;②计算复杂度高的步骤③~步骤⑤由GPU执行,算法流程如图1所示。
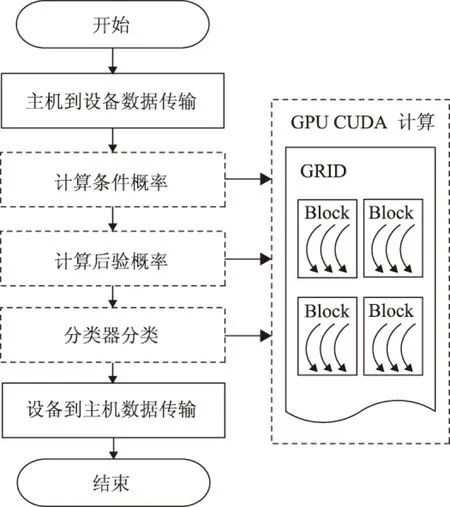
图1 基于CUDA的贝叶斯分类并行算法流程
图1中,虚线框代表该部分计算在GPU上执行,分配到GPU上并行计算的部分由处理流程中的Kernel函数(核函数)完成,每个Kernel函数对应CUDA计算模型上的一个GRID,GRID包含多个Block计算单元,Block由多个Thread线程具体执行计算,将图像像元映射到计算线程从而实现大规模的数据级并行计算。
在计算前,需要将图像数据从主机内存拷贝到GPU的设备内存,计算完成后,再将分类后的数据从GPU的设备内存拷贝回主机内存。在这个过程中CPU与GPU的计算核心都处于空闲状态。为了隐藏CPU和GPU间的数据传输时间,充分利用GPU的计算资源,本文通过CUDA创建流管理贝叶斯算法中的条件概率计算、后验概率计算以及分类器分类过程。流内的操作是按顺序执行的,而流与流之间则是乱序执行。实现一个流中数据传输与另一个流中核函数的执行同时进行,即GPU能够持续地进行计算,而不必等待数据。以3个流为例,每个流处理一块图像数据,异步优化效果如图2所示,不使用异步执行时贝叶斯并行模型的计算时间为(执行时间+传输时间);而使用流和异步后,时间降为(执行时间+传输时间/3)。
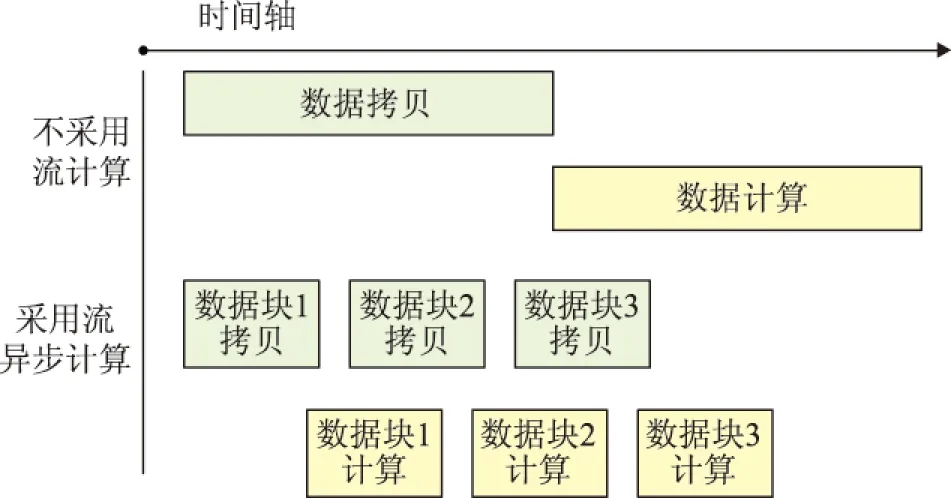
图2 异步优化示意图
同时,由于Kernel的启动会占一定的时间开销,为了提高并行算法的计算效率,本文尽可能将多个计算过程合并到一个Kernel函数中执行。贝叶斯算法中的特征属性条件概率计算、后验概率计算以及分类器分类都是针对整个遥感图像进行的,图像像元与计算线程的映射相同,将以上三个过程合并到一个Kernel中进行计算,从而可以避免不必要的时间开销。
4 实 验
4.1 数据
所用的高光谱图像是PHI航空成像光谱仪获取的日本某地区的精细农业数据,共80个波段,原始像幅为570×350。图3为原始图像假彩色合成影像以及地面样本图。经主成分分析进行特征提取,选取变换后包含信息量最大的6个波段作为实验数据。根据地面调查数据选取了中国白菜、日本白菜、萝卜、生菜、牧场、薯、森林、无植被覆盖区、地膜覆盖区等9类地物作为分类的训练样本。另外,为了分析不同数据量对算法加速比的影响,将原始图像空间维重采样,生成5幅不同空间分辨率的模拟影像,像幅分别为256×256,512×512,1024×1024,2048×2048,4096×4096。
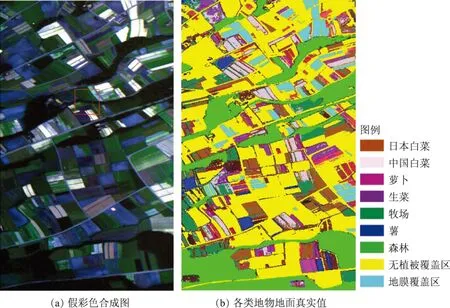
图3 PHI日本某地区的精细农业数据
4.2 计算环境
本文的实验测试平台参数为,中央处理器CPU是2.8GHz、12个计算核心的Intel(R) Xeon(R) X5660;图形处理器是NVIDIA Quadro 5000 GPU,2.5GB全局存储器,352个计算单元。操作系统是Windows 7 64位。
贝叶斯分类算法分别基于串行和并行计算环境实现,前者采用Microsoft Visual Studio 2008 C/C++编译器实现,后者采用GPU的统一计算架构CUDA4.0 C实现。
4.3 结果与分析
本文从分类精度和计算时间两个方面对提出的并行算法的性能进行分析,并与对应的串行程序进行比较。首先,对串行、并行优化算法的分类精度进行比较。从多组实验结果得出对于相同的实验数据串并行算法得到的分类精度是一致的,图4给出了分类结果。
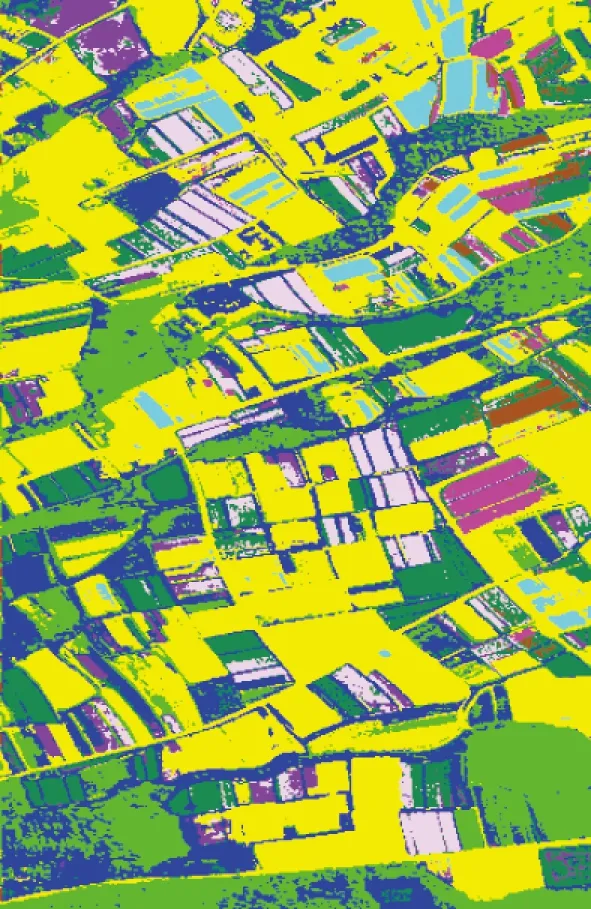
图4 PHI数据分类结果
为了定量评价分类精度,本文根据地面调查数据分别在影像的不同位置选取了4个~6个均匀区域作为验证样本,各类地物的验证样本分别包含约200个~1000个像元。通过混淆矩阵计算了贝叶斯算法的分类精度,如表2所示。
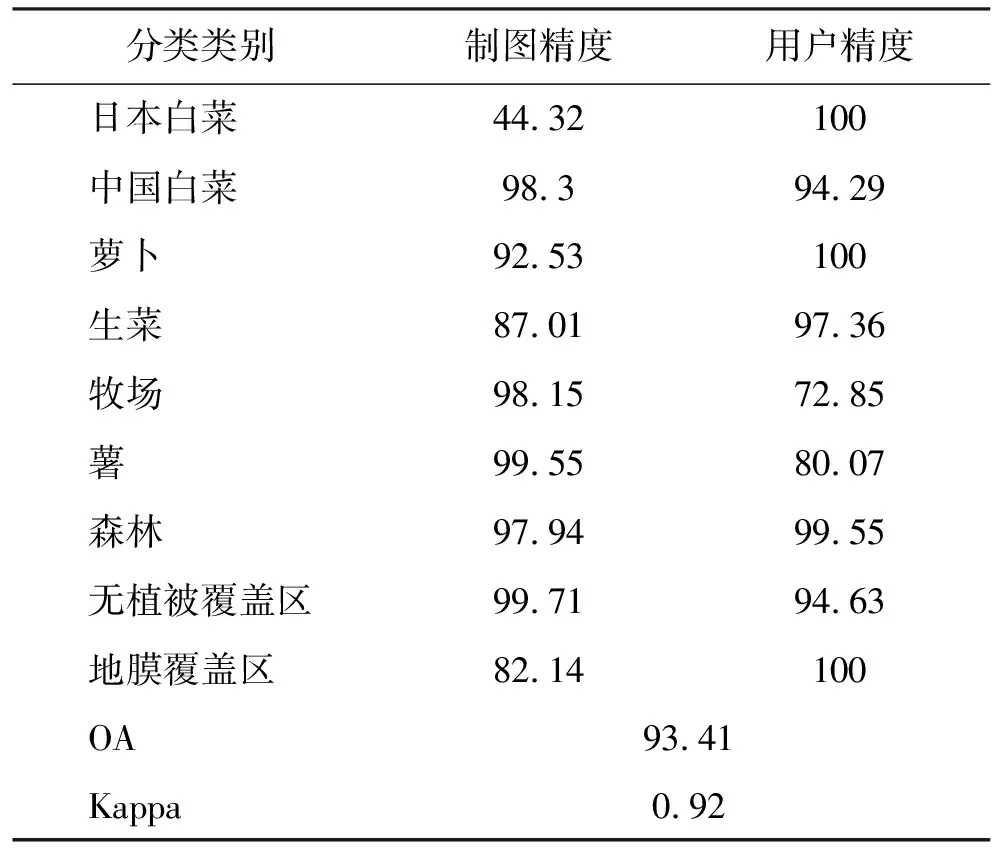
表2 贝叶斯算法分类精度
接下来对两种算法的分类效率进行对比分析。实验时间统计结果如图5、图6所示。其中并行计算时间是指包括GPU分配显存时间、数据拷贝时间以及核函数执行时间在内的总时间;由于采用了流异步执行,核函数执行时间包括了从设备端向主机端的数据拷贝时间。加速比是指串行算法与并行算法计算时间的比值。
由图5可以看出,当数据量比较小时,核函数执行时间与并行计算时间基本相同,但随着数据量的增大,并行计算时间与核函数执行时间之间的差值不断增大,原因是GPU显存分配、主机端设备端数据拷贝时间随着数据量的增大而不断增加。
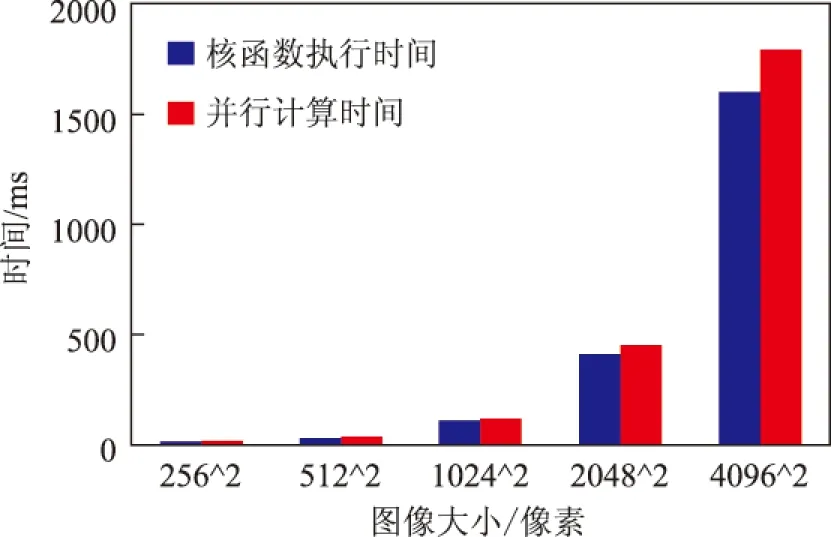
图5 核函数执行与并行计算时间在不同数据量下的比较
图6为串并行计算时间以及加速比随数据量变化图。从图6(a)中的串并行计算时间曲线可以看出,串并行计算时间随数据量的增加均呈线性增长。对于传统CPU环境下,纵坐标计算时间增量与横坐标数据量增量之比(秒每兆,s/M)超过1∶5,在这种情况下,如果数据量比较小,其分类的处理时间还能够容忍,如果数据量增大,则计算时间随之成倍增加;对于GPU环境下,纵坐标计算时间的增量与横坐标数据量的增量之比小于1∶200,即由数据量急剧增加而引起的计算时间增长十分缓慢。从图6(b)中的加速比曲线来看,基于GPU并行计算的加速比随数据量的增加呈增大趋势,当数据量达到一定量时,计算效率不再有较大的提升,加速比基本趋于稳定,说明此时GPU线程达到满载,即使增加数据量,加速比变化也不明显;从多次实验结果可知,本文提出的并行算法能够获得25倍~54倍的加速比。
更进一步,将本文提出的并行算法与ENVI软件中的最大似然算法进行对比。在处理4096×4096大小的图像时,本文的并行算法计算时间是1.78s,而ENVI软件中最大似然算法的计算时间大约是34.2s,本文的并行计算优化方法比ENVI软件同类功能的计算效率快19倍。
从以上实验结果分析可以得出结论如下:(1)本文提出的贝叶斯并行算法与串行算法的分类结果一致;(2)在保证分类结果正确的同时,并行算法的计算效率要远远高于串行算法,并能获得25倍~54倍的计算加速比;(3)串行计算时间增量与数据量增量之比大于1∶5,并行计算时间增量与数据量增量之比小于1∶200,数据量增加时,串行计算时间增长的更快;(4)加速比随数据量的增大呈增大趋势,当数据量达到一定时,加速比趋于稳定,此时GPU线程达到满载。
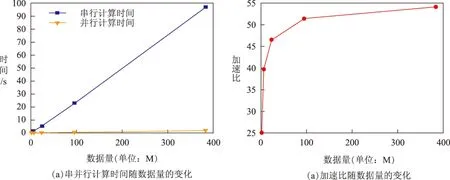
图6 串并行计算时间以及加速比随数据量的变化
5 结束语
本文基于高光谱图像贝叶斯分类算法的复杂度分析,给出了GPU并行优化计算方法,并且采用PHI航空成像光谱仪获取了日本某地区的精细农业数据,在NVIDIA GPU上进行了实验验证。结果表明,该并行分类算法在保证分类精度的同时能大大提高算法的计算效率,获得25倍~54倍的计算加速比。研究表明,基于GPU实现遥感图像并行分类算法是提高遥感图像分类处理计算效率的有效途径,可以为遥感大数据处理提供技术保障。同时,如何利用多GPU系统进一步提高算法的计算效率也是下一步研究工作的重点。
参考文献:
[1] ANTONIO P.Special issue on architectures and techniques for real-time processing of remotely sensed images[J].Journal of Real-Time Image Processing,2009,4(3):191-193.
[2] 张兵.智能遥感卫星系统[J].遥感学报,2011,15(3):415-431.
[3] DOMINGOS P,PAZZANI M.On the optimality of the simple bayesian classifier under zero-one loss[J].Machine Learning,1997,29(2-3):103-130.
[4] 彭兴媛.朴素贝叶斯分类改进算法的研究[D].重庆:重庆大学,2012.
[5] 刘晓云,康一梅,齐同军,等.遥感图像波谱角并行分类算法[J].计算机科学,2009,36(9):267-270.
[6] LUO W,ZHANG B,JIA X.New improvements in parallel implementation of N-FINDR algorithm[J].Geoscience and Remote Sensing,IEEE Transactions on,2012,50(10):3648-3659.
[7] PLAZA A J.Parallel techniques for information extraction from hyperspectral imagery using heterogeneous networks of workstations[J].Journal of Parallel and Distributed Computing,2008,68(1):93-111.
[8] 卢俊,张保明,黄薇,等.基于 GPU 的遥感影像数据融合 IHS 变换算法[J].计算机工程,2009,35(7):261-263.
[10] TARABALKA Y,HAAVARDSHOLM T V,KSEN I,et al.Real-time anomaly detection in hyperspectral images using multivariate normal mixture models and GPU processing[J].Journal of Real-Time Image Processing,2009,4(3):287-300.
[11] 袁涛,马艳,刘定生.GPU 在遥感图像处理中的应用综述[J].遥感信息,2012,27(6):110-117.
[12] KIM S,PARK S,WON D.Proxy signatures,revisited[J].Information and Communications Security,1997:223-232.
[13] NVIDIA.NVIDIA CUDA compute unified device architecture—programming guide[EB/OL].http://developer.nvidia.com/cuda.
