基于用户评价的铁路旅客信息服务推荐方法研究
2014-08-01李宗凯李洪研吕晓鹏
李宗凯,李洪研,肖 坦,吕晓鹏,刘 禹
(1.通号通信信息集团有限公司 北京 100071;2.北京航空航天大学 计算机学院,北京 100083)
基于用户评价的铁路旅客信息服务推荐方法研究
李宗凯1,李洪研1,肖 坦1,吕晓鹏1,刘 禹2
(1.通号通信信息集团有限公司 北京 100071;2.北京航空航天大学 计算机学院,北京 100083)
对用户提供个性化的服务推荐是铁路信息服务系统提高服务质量的手段之一,传统的协同过滤推荐算法的应用过程中,当用户和项目数目较大时,用户-项目矩阵极度稀疏且用户评价向量的维度不同,传统的相似性比较方法无法很好地处理此类问题,降低了推荐算法的推荐质量。本文提出基于云模型的相似性度量方法,使用云模型雾化特征对逆向云算法进行补充,对于给定的数据向量,可以将其转换成云,使用云模型数字特征进行数据表示。云模型的期望和熵决定数据对应概念的内涵相似度,熵和超熵可以反映其外延相似度,比较云之间的相似度可得到数据本身的相似程度。应用MovieLens标准测试数据集,与传统的相似性度量方法比较,实验结果表明,基于云模型相似性度量的协同过滤推荐算法推荐质量高,可为铁路信息化服务推荐提供技术积累与指导。
铁路运输;旅客服务;云模型;逆向云算法;协同过滤推荐
先进的旅客信息系统是智能交通系统中的一个重要组成部分。信息发布是其中直接和出行者相联系的一个环节,在最主要的几种信息发布技术中,互联网和移动终端无疑是最现代也是最能提供个性化功能的两种方式[11]。软件服务的应用过程形成了大量的用户行为与评价数据,如何从中挖掘和发现有用的知识以提供个性化服务成为一个有意义的研究课题。服务使用者希望服务系统能够自动地把用户最感兴趣的服务推荐出来[1]。软件应用的发展过程中,SOA、SaaS等理念的提出,将软件作为服务进行展现,云计算更是强调对终端用户按需服务[2]。为了给用户提供满足个体需求的产品与服务,推荐系统需要提供精确而又快速的推荐,研究者提出了多种推荐算法[3~6]。
最近邻协同过滤推荐是当前最成功的推荐技术[7],相似性计算是协同过滤推荐算法中最关键步骤,而用户数目和项目数据急剧增加,导致用户评分数据的极端稀疏性[7],由于用户的流动性,面向铁路的信息化服务中评价数据稀疏的问题更加突出。不同用户对不同的项目提供了不同维度的评价向量,传统相似性度量方法均存在各自的弊端。使得计算得到的目标用户的最近邻居不准确,推荐系统的推荐质量下降。文献[8]提出通过奇异值分解(SVD)减少项目空间维数的方法,但降维会导致信息损失,使得该方法在项目空间维数较高的情况下难以保证推荐效果[9]。
本文以云模型[13]为基础,提出了一个新的相似性度量方法,解决两个方面的问题:
(1)将定量的评分数据映射为云,通过本文提出的改进逆向云算法,使用云模型的3个数字特征表示定量数据,克服数据缺失、稀少、不同维度等因素对相似性比较带来的负面影响;
(2)定义云模型的相似性比较规则,通过云模型数字特征比较云相似性,从而得到原始数据的相似性度量值。最后,给出使用云模型相似性进行软件服务的协同过滤推荐的方法和实验结果。
1 定量数据云映射
李德毅院士在传统模糊集理论和概率统计的基础上提出了定性定量不确定性转换模型—云模型。与云模型理论相关的两个重要算法[12]是:正态云发生器算法解决定性至定量的转换;逆向云算法实现了由定量数据到定性知识的转换。本文将逆向云算法所实现的定量数据到定性知识的转换称为云映射。
逆向云算法完成了定量数据到定性概念之间的转换,算法如下[12]。
对由n个样本值所组成的样本空间{x1, x2,…, xn},可以使用Cloud(Ex, En, He)描述其定性概念,其中:(1)根据xi计算定量数据的样本均值一阶样本绝对中心矩样本方差计算期望:计算熵:(4)计算超熵:
2 云相似性度量
云模型的3个数字特征中Ex体现了定性概念的核心,而En是对其不确定性的衡量,He又是对En的不确定性度量。所以,对两个云的相似性进行度量时,其它数字特征等同的情况下,Ex对相似性的影响最大,En次之,而He对云相似性的影响最小。
从认知的角度,云模型所表示概念的相似性由2个方面组成:Ex和En的联合作用决定了概念的内涵相似性,代表概念的本质区别;En与He决定了概念的外延相似性,表示概念的不确定程度的异同。本文中使用α表示概念的内涵相似性,β表示外延相似性。
为了表示概念内涵相似性α,首先给出云距离的定义,对于两个云C1(Ex1, En1, He1)与C2(Ex2, En2, He2) ,其距离Dis(C1, C2)定义为:
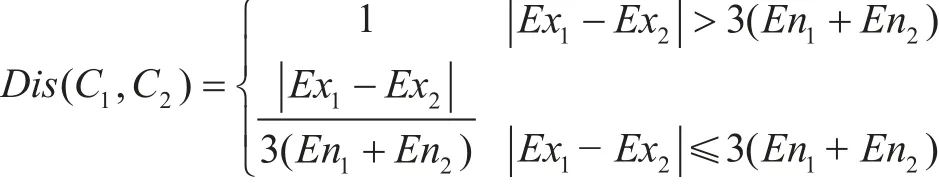
|Ex1–Ex2|表示C1(Ex1, En1, He1)与C2(Ex2, En2, He2)之间的概念核心距离,3En表示云的论域宽度。当|Ex1–Ex2|>3(En1+En2)时,两个云完全分离,没有交集,此时云距离为1;|Ex1–Ex2|≤3(En1+En2) 时,此公式表示两个概念的交叠程度;如果Ex1=Ex2,云距离为0,但此时并不意味着两个云完全重叠,而是表示两个概念核心相同。超熵He表示沿正态曲线切线放心的云滴厚度,与概念核心无关,故不参与云距离的计算。
对于给定的云C1与C2,其内涵相似性表示为:

外延相似性与En和He相关,定义 β为:
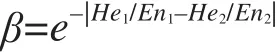
He/En代表概念外延的离散程度,当云模型趋近于正态分布时,He/En趋向于0且概念外延趋于稳定;相反,若一方概念使用云模型雾化特征表述的概念,He/En= 0.98且 β取得最小值0.375,此时两个概念的外延存在最大差异[13]。
α与 β的联合作用决定了云相似度,且前者对相似度的贡献远大于后者。许多数学解析式可以表示此类关系,本文中选用:
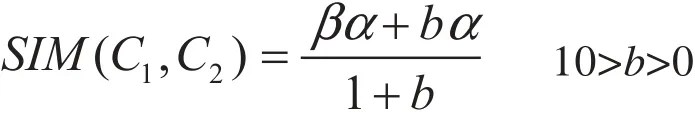
当概念内涵相似性为0时,云相似性为0且与参数b无关,而当内涵相似性与外延相似性相同时,两个云的相似性为1,同样无关参数b。参数b的大小决定了概念内涵相似性与外延相似性对云相似性的贡献比例,数据拟合结果表明,当b取值大于10之后,其变化对整个表达式结果影响已经十分微弱。针对不同实际问题,可以选择不同的参数b来决定α与 β在云相似性中的比重,若问题对概念内涵相似性要求比较苛刻,可以增大b的取值,保证α的变化对云相似性具有足够大的影响,反之可降低b的取值。

图1 β对SIM(C1, C2)的影响
图1 给出了外延相似性β对云相似性的影响曲线,本例中 b= 5。对于云C1(1, 0.1, 0.01)与C2(1.1, 0.1, He2) ,随着He2的变化,β取得最大值1 且此时云相似性等于内涵相似性α;而β的最大取值为0.375,此时代表外延相似性对云相似性的影响最大。计算表明当b = 5时β对于云相似的最大贡献占SIM(C1, C2)的10%左右。
3 云相似性在协同过滤推荐中的应用
相似性比较方法是决定最近邻协同过滤推荐算法优劣的关键因素,算法中,需要考虑2个方面的相似性:项目相似性与用户相似性。单纯的考虑用户相似性而忽略项目之间的相似性,会对算法效能产生不利的影响。文献[14]中提出了一种基于项目评分预测的协同过滤推荐算法,其核心思想是通过计算训练集中用户评价项目的并集,以并集为基础衡量用户间的相似性;在计算用户并集过程中,对于未评价项目,采用项目相似性来估算用户对项目的评分,从而实现兼顾项目相似性与用户相似性。在相似性计算时,文献[14]算法采用了余弦相似性、相关相似性与修正余弦相似性。为验证本文提出的云相似性度量方法,本文提出了基于云模型相似性比较的协同过滤推荐算法。
3.1 算法设计
算法输入:用户-项目训练集Ubase,用户-项目测试集Utest。其中:Ubase和Utest均包含用户UID、项目IID,评分SCORE这3个数据字段;Ubase与Utest的合集共包含M个用户对N各项目的k项评分,且任意n∈N或m∈M,Ubase中至少包含一项相关评价记录;算法输出:训练集项目推荐评分向量R。
算法过程:
(1)遍历Ubase,对任意项目p,获取其所有项目评分,生产向量Sp,通过本文的改进逆向云算法,计算项目评分云Cloudp(Exp, Enp, Hep);对所有项目p、q (p≠q),计算 SIM(Cloudp, Cloudq),从而得到项目相似性矩阵SimItemN•N,显然,SimItemN•N是主对角线元素为1的对称阵;
(2)根据Ubase,获取用户i评价项目集合Ui与用户j评价项目集合Uj,取Uij=Ui∪Uj;
(3)对项目p∈Uij且p∈/Ui,由SimItemN•N获取p与Ui中所有项目相似性集合Up–i,通过项目相似性评估用户i对项目p的评分Si–p:

(4)重复步骤(3),估计用户i、j在Uij上所有未评价项目的评分,将用户i、j的评分数据分别应用改进逆向云算法,获取Cloudi,与Cloudj,,计算Sim(Cloudi, Cloudj),得到用户i与j的相似性;
(5)重复步骤(4),获取所有用户的基于Ubase的相似性矩阵SimUserM•M;
(6)遍历Utest,对于用户i对项目p的评价问题:
a.依据Ubase,获取所有对项目p进行评分的用户集合Up;
b.根据SimUserM•M,获取用户i与Up内各用户最近邻向量Top={simi1, simi2,…, simih},并进行降序排序;
c.选用Top–N最近邻用户作为推荐依据,仍采用加权平均的方式计算推荐值Si–p:

(7)重复步骤(6),获取Utest内所有待测试推荐的预测评分,输出R。
3.2 算法评价
推荐性能的评价取决于算法性能。本文提及的算法中,步骤(1)~(6)属于机器学习阶段,本阶段可以离线运行,实际应用中,服务后台进程可以完成增量式机器学习,获取当前系统用户的相似性矩阵。推荐过程的时间复杂度为O(N),其中N为系统拥有的用户数,可见算法时间复杂度较低,可满足实际在线应用。
为验证本文提出的推荐算法的推荐质量,进而确定云模型相似度度量方法相比传统算法的优势,采用MovieLens 站点提供的数据集(http:// movielens.umn.edu/)进行实验分析。MovieLens是一个基于Web 的研究型推荐系统,用于统计用户对电影的评分并提供电影推荐。MovieLens对研究人员提供3种规模标准推荐测试数据集:(1)943名用户对1 682部电影的10万条评分记录;(2)6 040名用户对3 900部电影的100万条评分记录;(3)71 567名用户对10 681部电影的1000万条评分记录。本文采用数据集1作为实验数据集,其中每个用户至少对20 部电影进行了评分。训练集与测试集数据划分方式采用MovieLens提供的标准划分方式,划分所产生的文件u1.base包含8万条训练样本,文件u1.test包含2万条测试样本。其数据集的稀疏等级[13]为1-100000/(943×1 682)= 0.9370。
采用相同的推荐策略,我们构造3种对比方法:(1)项目相似性采用余弦相似性进行度量,用户相似性采用相关相似性进行度量;(2)项目相似性与用户相似性均采用余弦相似性进行度量(文献[14]采用此方法);(3)本文提出的推荐方法,采用云模型相似性度量项目与用户的相似性。3种方法均在上述数据集1上进行实验。
采用Top-2作为推荐依据时,推荐质量最低,此时MAE=0.908;当最近邻居选取超过8之后,推荐质量趋于稳定, 维持在0.8左右;虽然随着最近邻居选择数量的增多,推荐质量呈现更好的趋势,但对于实际应用,不可能找到无穷多的最近邻居,所以对于MovieLens数据集,我们认为选用8~20个推荐邻居,即可得到最佳的推荐质量。
3种推荐方法的对比如图2所示。图中给出了最近推荐邻居为4、8、12、20的4种情况。在4种情况下,本文提出的方法3均取得了较小的值,说明推荐结果更加接近实际用户评分。同时,3种算法的比较,实际是基于云模型的相似性比较方法与传统余弦相似性、修正余弦相似性(相关相似性)方法的比较,结果表明,对待推荐问题云模型相似性度量方法更加适用,可取得更好的推荐结果。

图2 3种方法推荐质量比较
4 结束语
逆向云算法可以完成定量知识到定性概念的转换,但对于分布偏离正态分布的定量数据的转换能力不足。将云模型雾化性质与逆向云算法相结合,可以扩展云模型的知识表示范围。对于给定的数据向量,可以将其转换成两个云,使用云模型数字特征进行数据表示。云模型的期望和熵决定数据对应概念的内涵相似度,熵和超熵可以反映其外延相似度,度量云之间的相似度可得到数据本身的相似程度,而此方法与数据之间的对应关系、是否稀疏无关。
对于旅客分析服务的推荐问题,使用云模型可以表示项目的评分与用户的评分数据,进而衡量用户-用户、项目-项目之间的相似程度,从而对未知的用户-项目进行评分估计。通过实验可知,基于云模型的相似性度量方法较传统方法在解决推荐问题时更加优秀,可以为旅客提供个性化、定制化服务,增强服务水平,提高旅客乘车体验。
[1] Arwar B, Karypis G, Konstan J, et a1. Analysis of recommendation algorithms for E-commerce[C]. Processing of 2nd ACM Conference on Electronic Commerce, 2000, 158-167.
[2] Wikipedia. Cloud computing[EB/OL]. http://en. wikipedia. org/wiki/Cloud_comp-uting, 2009-07.
[3] You Weng, Ye Shui-sheng. A survey of collaborative filtering algorithm applied in E-commerce recommender system. Computer Technology and Development[J]. 2006, 16(9): 70-72.
[4] Wang Zhi-meig, Yang Fan. P2P recommendation algorithm based on hebbian consistency learning. Computer Engineering and Applicationsg, 2006g, 42(36): 110-113.
[5] Wang Wei-pingg, Liu Ying. Recommendation algorithm based on customer behavior locus. Computer Systems&Applicationsg[J]. 2006, 15(9): 35-38.
[6] Gao Jingg, Ying Ji-kang. A recommendation system based on attificial immune system. Computer Technology and Developmentg[J]. 2007, 17(5): 180-183.
[7] Breese Jg, Hecherman Dg, Kadie C. Empirical analysis of predictive algorithms for collaborative filtering. Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence[C]. 1998, 43-52.
[8] Sarwar BMg, Karypis Gg, Konstan JAg, Riedl J. Application of dimensionality reduction in recommender system-A case study[C]. ACM WebKDD 2000 Workshop, 2000.
[9] Aggarwal CC. On the effects of dimensionality reduction on high dimensional similarity search[C]. In: ACM PODS Conferenceg, 2001.
[10] Li De-yi. Uncertainty in Knowledge Representation Engineering Scienceg[J]. 2000, 2(10): 73-79.
[11] 涂颖菲,陈小鸿. 法国城市旅客手机信息服务系统[J].城市交通,2007(2): 92-96.
[12] 张飞舟,范跃祖,沈程智,李德毅. 基于隶属云发生器的智能控制[J]. 航空学报,1999,20(1):89-92.
[13] 刘 禹,李德毅,张光卫.云模型雾化特征及在进化算法中的应用[J].电子学,2009,8(37):1651-1658.
[14] 邓爱林,朱扬勇,施伯乐. 基于项目评分预测的协同过滤推荐算法[J].软件学报, 2003,14(9):1621-1628.
责任编辑 方 圆
Recommendation method of railway passenger information service based on user ranking
LI Zongkai1, LI Hongyan1, XIAO Tan1, LV Xiaopeng1, LIU YU2
( 1.CRSC Communication & Information Corporation, Beijing 100071, China; 2. School of Computer Science and Engineering, Beihang University, Beijing 100083, China )
Personalized service recommendation was one of important directions of China railway information service system. In collaborative fi ltering recommendation algorithm, the traditional similarity measurement methods could not deal with large number of users and items which formed a sparse User-Item matrix. This article proposed the similarity measure method based on Cloud Model, applied atomized feature of the Cloud Model to the reverse cloud algorithm. A given data vector could be converted into a cloud. Quantitative data was represented with the numerical characters of the Cloud Model. Cloud similarity was depended on two aspects, such as the concept of connotation similarity and extension similarity. The connotation similarity of data in the corresponding concept was depended on the entropy and expectation of the Cloud Model and extension similarity was reflected by the entropy and excess entropy. A new collaborative filtering recommendation algorithm based on the Cloud Model similarity measurement method was constructed and the experiment result showed that the new algorithm was with reliable and accurate performance.
railway transportation; passenger service; Cloud Model; Reverse Cloud Algorithm; collaborative fi ltering recommendation
U293.3∶TP39
A
1005-8451(2014)11-0005-05
2014-05-06
李宗凯,工程师;李洪研,工程师。
