基于隐马尔科夫模型的中文发音动作参数预测方法
2014-07-25蔡明琦凌震华戴礼荣
蔡明琦 凌震华 戴礼荣
(中国科学技术大学电子工程与信息科学系,合肥,230027)
引 言
语音是从肺部呼出的气流通过声门、声道等各种器官作用而发出的。声道的形状主要由唇、颚、舌等的位置决定。不同的声道形状决定了不同的发音[1]。人们用发音动作参数描述发音器官在发音过程中的位置及运动,这些发音器官包括舌、下颚、嘴唇等。发音动作参数可以通过多种技术来采集,例如 X 射线微束影像[2]、磁共振成像[3]、超声波[4]、图像采集外部发音器官运动[5]及电磁发音仪(Electro magnetic articulography,EMA)[6]等。发音动作参数不仅可以有效地描述语音特征,而且相对于声学参数还具有以下优势:
(1)因为发音器官的物理运动能力有限,所以发音动作参数相对于声学参数变化缓慢且平滑,更适合使用隐马尔科夫模型(Hidden Markov model,HMM)进行建模。
(2)对语音中存在的某些现象,发音动作参数可以进行更直接的解释。例如,语音中的第二共振峰从高到低的变化,可以通过发音动作参数解释为舌位从前往后的运动。
(3)发音动作参数直接记录发音器官的位置,它们不受声学噪音的影响且较少受录音环境的影响。因此发音动作参数相对于声学参数更加鲁棒[7]。
基于发音动作参数的以上优点,已有研究人员将发音动作参数应用到语音识别与语音合成的方法研究中,例如将发音动作参数作为语音识别的额外特征参数以降低识别错误率[8],在语音合成中融合发音动作参数以提高合成语音的自然读与灵活可控性[9]等。
此外,在给定文本或者语音输入时的发音动作参数预测也是发音动作参数研究的热点之一,其潜在的应用场景包括语音驱动的人脸动画系统、语言学习中的发音位置问题检测、基于调音的语音合成方法中的发音器官运动预测等。目前发音动作参数预测方法按照输入主要分为两类:(1)输入文本:利用时间对齐的音素序列及高斯分布描述音素中点发音动作参数的分布,通过一个协同发音模型预测发音动作参数[10];利用目标逼近模型进行发音动作参数预测[11];基于HMM的发音动作参数预测[12]。(2)输入语音:基于高斯混合模型的声学-发音动作参数映射,并使用最大似然估计准则考虑动态参数[13];利用人工神经网络和最大似然参数生成(Maximum likelihood parameter generation,MLPG)算法训练一个轨迹模型[14]。由于缺少中文发音动作参数数据库,目前少有对中文发音动作参数的研究。
本文对基于HMM的中文发音动作参数预测方法进行研究。在模型训练阶段,利用电磁发音仪完成了中文连续语流的发音动作参数采集、处理与数据库制作,构建了包含声学与发音动作参数的双流HMM模型来表征两种参数之间的关系[12];在预测阶段,利用输入的文本及声学参数,基于最大似然准则实现发音动作参数的预测。此外,本文还研究了建模过程中不同的上下文属性、模型聚类方式、流间相关性假设以及转换矩阵绑定方式对于中文发音动作参数预测性能的影响。
1 中文连续语流EMA数据库构建
利用EMA可以便捷、准确、实时地采集发音动作参数。本文采用NDI公司的Wave System设备录制中文发音人连续语流的发音动作参数及语音波形,并经过预处理制作成中文连续语流EMA数据库。由于使用EMA采集发音动作参数,因此后续介绍中“发音动作参数”也用“EMA参数”来表示。
本文设计的中文数据库包括音素平衡的390句中文语句,由一名普通话女发音人在隔音密闭专业录音室里采用AKG领夹式麦克风朗读录制。使用NDI公司的Wave System设备平行录制语音波形与EMA参数。波形录制使用16kHz采样,16bit量化的PCM格式。通过在发音人的各发音器官放置小的传感器,并利用电磁信号对发音过程中各传感器进行定位来实现EMA数据的采集。实验中分别在感兴趣的6个发音器官位置放置了传感器,其位置如图1所示。利用 Wave System设备,可以采集每个传感器在发音过程中的空间三维位置。

图1 EMA传感器位置示意图Fig.1 Placement of EMA receivers in database
由于EMA参数是由EMA传感器直接记录的位置信息,在对EMA参数进行HMM建模前必须对其进行预处理。预处理主要分为两个步骤:头部运动规整和咬合面规整。
1.1 头部运动规整
原始的EMA数据记录的是发音器官相对于固定参考系的位置信息,而实际感兴趣的信息是发音器官相对于发音人头部的运动信息。因此,需要对EMA数据进行规整以消除头部运动的影响。本文利用NDI公司Wave System提供的一个6D参考传感器,并将这个参考传感器放置在说话人鼻梁处(认为鼻梁在发音时始终与头部保持相对静止),可以较为便捷地得到其他传感器发音器官相对此传感器的头部规整后的EMA数据。
1.2 咬合面规整
将发音人牙齿自然咬合时所形成的平面定义为咬合面,如图2所示,在一块硬纸板上安置A,B,C三个传感器(直线AB垂直于BC),让发音人自然咬住硬纸板来测量发音人的咬合面。咬合面规整就是将原始以鼻梁参考点为中心的xyz坐标系变换成x′y′z′坐标系,其中x′y′平面为咬合面、y′z′平面为垂直于咬合面的头部中轴面。利用咬合面对发音动作参数进行规整可以使发音动作参数物理意义更明显,并且可以较好保证不同发音人EMA参数的可比性。
做完头部运动规整的EMA数据,每个传感器分别有x,y,z三维数据,如图1所示,其中x表示左右方向位移、y表示前后方向位移、z表示上下方向位移。在图2中,假设M点为需要规整的点,T为点M在咬合面的投影,S为TS在直线BC上的垂足。将MT,TS的长度作为z′,y′的模。由于所有传感器均安置在发音人的头部中轴面上,所以x′的模很小可以忽略。z′,y′的正负符号信息由BM与咬合面的法向量及AB直线夹角决定。经过咬合面规整,每个传感器所对应EMA数据由三维降为两维。
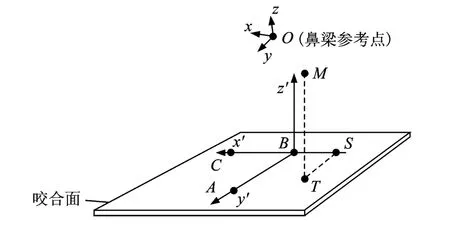
图2 咬合面规整过程示意图Fig.2 Schematic diagram for occlusal surface normalization
2 应用HMM的中文发音动作参数预测
将HMM用于中文发音动作参数预测,其框架类似于基于HMM的参数语音合成系统[15]。首先需要训练统一的声学-发音动作参数HMM模型以表示声学参数与发音动作参数之间的关系;在生成过程中,利用最大似然准则和动态参数约束生成最优发音动作参数[12]。
2.1 发音动作参数预测方法
整个发音动作参数预测系统主要分为训练和预测两部分[7]。系统框架如图3所示。
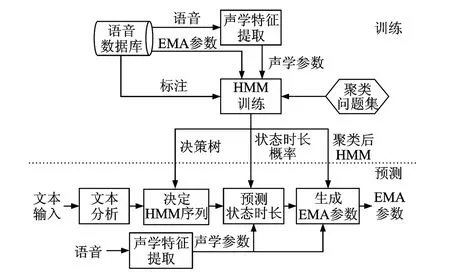
图3 基于HMM的发音动作参数预测系统Fig.3 HMM-based articulatory movement prediction system
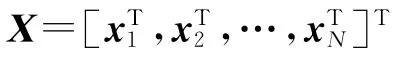
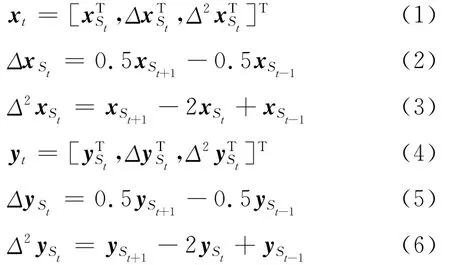
初始化上下文相关的HMM训练后,用最小描述长度(Minimum description length,MDL)准则和上下文属性问题集训练一棵决策树,利用该决策树对HMM进行聚类[16],这样可以解决由数据稀疏引起的过拟合问题。在对发音动作参数与声学参数进行基于决策树的模型聚类时,可以对两种参数分别构建决策树(独立聚类);也可以为这两种参数构建一棵共享的决策树(共享聚类)。然后使用训练得到的上下文相关HMM进行状态切分并且训练状态的时长概率模型[17]。通过上述训练流程,最后训练得到的模型包括谱、基频、时长及发音动作参数的聚类HMM以及各自的决策树。
预测过程中,首先利用前端文本分析得到的结果和决策树确定HMM序列,然后利用MLPG算法生成最优发音动作参数[18]如下
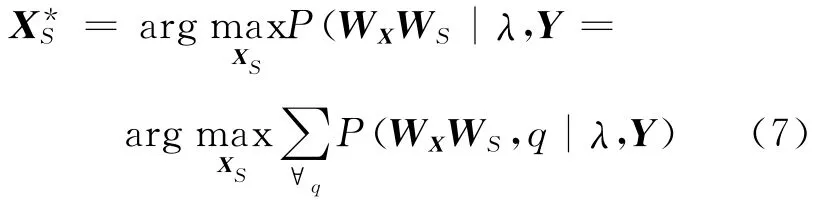
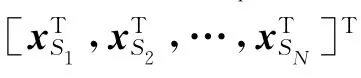
2.2 流间相关性建模
因为声学信号是由发音器官的运动引起的,所以声学参数与发音动作参数是彼此相关的。因此在对声学参数与发音动作参数建模时,应考虑这种相关性。根据发音的物理机制,本文选择采用状态同步系统[7],状态同步系统假设声学参数和发音动作参数是由相同的状态序列生成的。在状态同步系统的基础上,对声学参数和发音动作参数之间的依赖关系进行直接建模。此时声学参数的生成不仅依赖于当前的上下文相关音素的声学模型,还依赖于当前帧对应的发音动作参数。特征生成模型结构如图4所示。
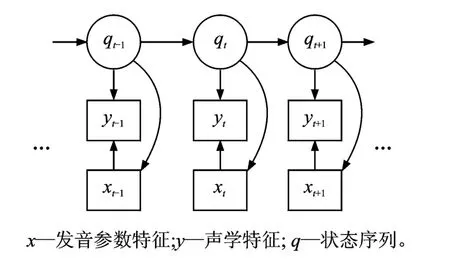
图4 特征生成模型结构Fig.4 Feature production model for combined acoustic and articulatory modeling
在之前的工作中,作者采用一无偏置的线性变换来对声学参数与发音动作参数的依赖关系进行直接建模[9,12]。本文在此基础上改进为一有偏置的线性变换对声学参数与发音动作参数的依赖关系进行建模,并且考虑该线性变换的分回归类绑定以减少需要估计的模型参数数目。因此,声学参数与发音动作参数的联合分布可以写成
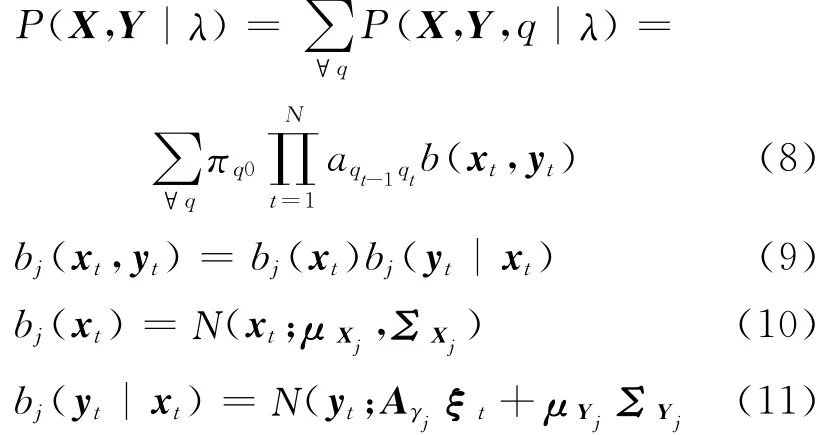
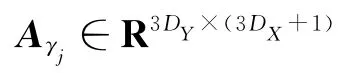
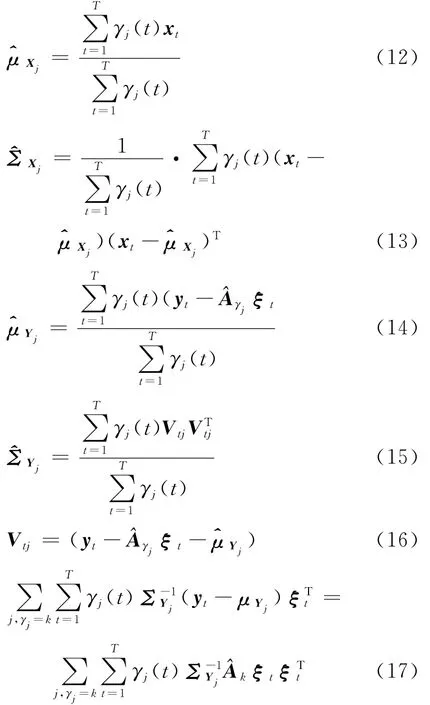

2.3 参数生成及迭代更新
发音动作参数生成公式见式(7),下面简化这一优化过程,只考虑发音动作参数在最优状态序列下的情况,因此式(7)可简化为式(18)

采用迭代更新方法来交替更新发音动作参数与状态序列,每一次迭代包括两步[12]:
(1)在给定声学特征Y与状态序列q的情况下,优化发音动作参数XS。
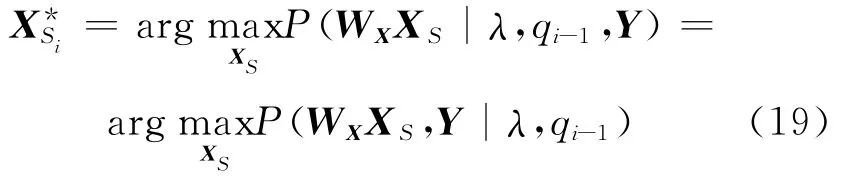
式中:i∈(1,2,…}表示第i次迭代,q0表示利用一个纯声学特征模型用Viterbi对齐算法对声学特征序列Y切分出的初始状态序列。如果假设X与Y在给定状态序列下没有依赖关系,采用传统的MLPG算法可以直接求解式(19)。一旦在建模时考虑声学参数与发音动作参数之间的依赖关系,如式(11)和式(19)中的联合分布可以写成式(20)。
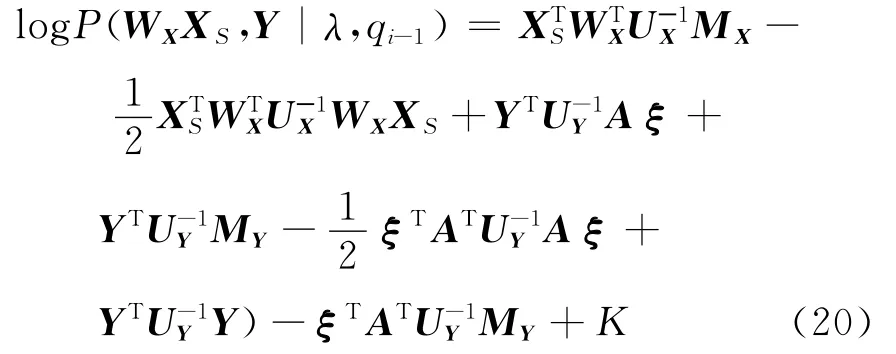
其中
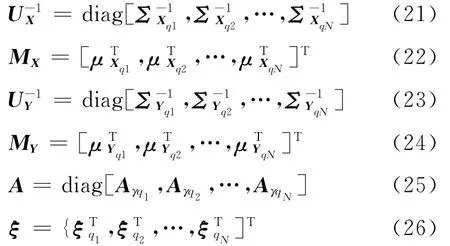
式中:K为 常 数 项。由 式 (26),ξt= [xTt,1]T,
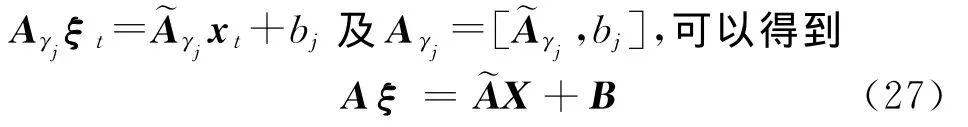
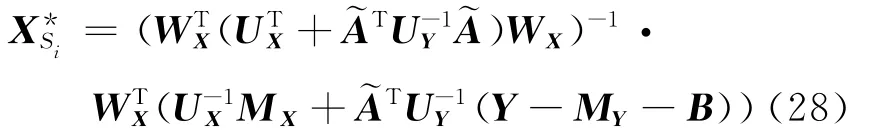
(2)给定和Y优化状态序列q

更新的状态序列将用在下一次的迭代中。
3 实验结果和分析
实验使用一个中文女发音人连续语流EMA数据库,它同时包含语音波形和EMA参数,具体信息可参考第2节。本文采用40阶线谱对(Line spectral pair,LSP)和1阶增益作为频谱声学参数,使用经过咬合面规整的12维特征(6个传感器,每个传感器两维)作为发音动作参数。选择380句作训练,剩余的10句用作测试。
3.1 上下文属性
为了研究上下文相关HMM训练过程中使用的上下文属性集对于发音动作参数预测系统的影响,本文训练了3个模型系统:单音素模型、三音素模型及完全上下文相关模型系统。这里,采用独立聚类的频谱模型与发音动作参数模型聚类方式,并且暂不考虑2.2节中提出的流间相关性建模。其中,三音素模型的上下文属性包含当前音素及前后各一个音素;完全上下文相关模型的上下文属性除了包含三音素模型中的音素特征,还包含一组广泛的语言韵律特征。表1列出了其中一部分上下文属性,表中L0表示音节,L1表示韵律词,L3表示韵律短语。
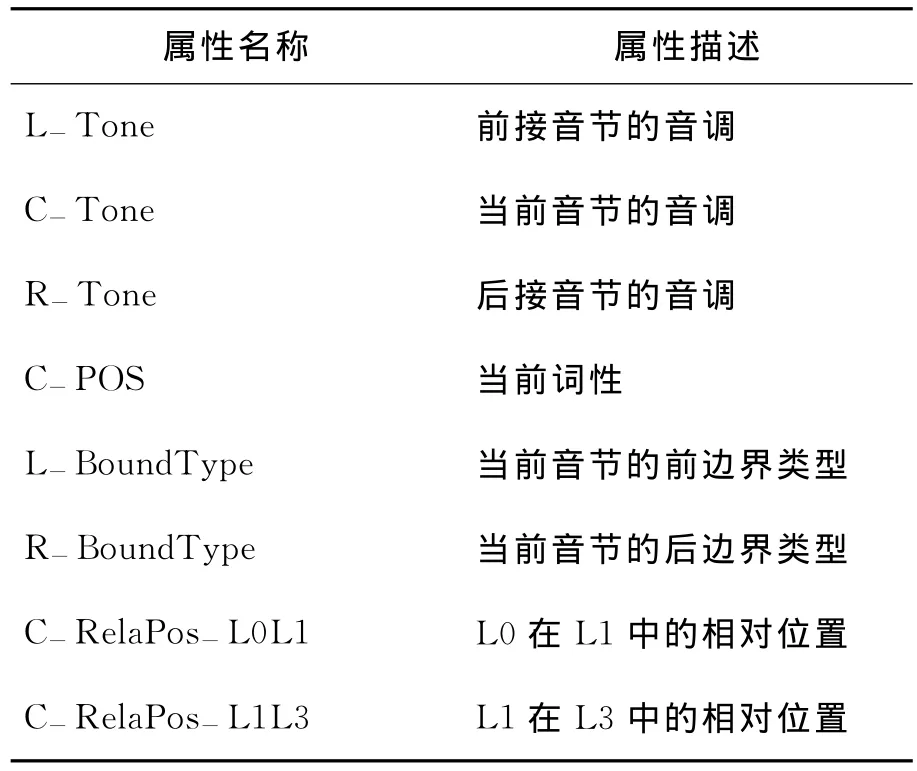
表1 完全上下文相关模型训练中使用的部分上下文属性列表Table 1 Some context descriptions used in full context dependent model
分别采用单音素模型、三音素模型和完全上下文相关模型,计算10句测试句生成LSP参数的均方根误差(Root mean square error,RMSE)作为客观评价标准。3个系统的实验结果如图5所示,单音素模型系统的系能明显低于三音素模型、完全上下文相关模型系统,因为后两种上下文模型都考虑了当前音素与前后音素的协同发音现象。完全上下文相关模型相对三音素模型增加的上下文属性主要体现的是对基频、时长等韵律参数的影响,因此对于提升发音动作参数的预测精度作用不大。后续的实验都将基于三音素模型进行。
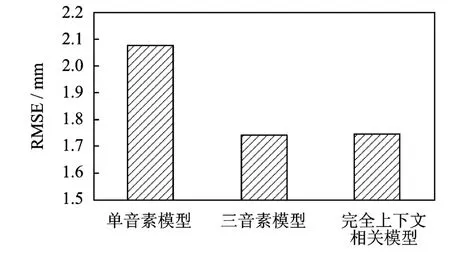
图5 采用单音素模型、三音素模型与完全上下文相关模型时的发音动作参数预测客观测试结果Fig.5 Objective evaluation of articulatory RMSE on monophone model,triphone model and full context model
3.2 聚类方式
在本文的实验数据库上,分别采用共享聚类和独立聚类的决策树叶子节点数目如图6所示。采用独立聚类时,EMA参数的决策树比采用共享聚类的决策树要大,这表明发音动作参数对比声学参数在发音变化上具有更好的区分性。
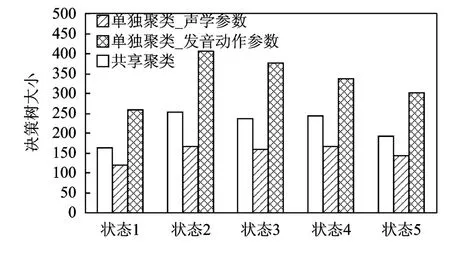
图6 采用共享聚类与独立聚类方式的各状态决策树叶子节点数目对比Fig.6 Node numbers of decision trees on each state for shared clustering and separate clustering
共享聚类与独立聚类的客观测试对比试验结果如图7所示。采用独立聚类可以提高EMA参数的预测精确性。因此,之后的实验都将采用独立聚类的方式。
3.3 流间相关性建模

图7 采用共享聚类与独立聚类时的发音动作参数预测客观测试结果Fig.7 Objective evaluation of articulatory RMSE on shared clustering system and separate clustering system
进一步验证2.2节提出的流间相关性建模方法对于发音动作参数预测性能的影响。为了考虑流间相关性建模中转换矩阵的数目对于系统的影响,采用回归类的方法对转换矩阵和决策树叶子节点进行绑定。因此,本文训练了5个系统进行回归类影响的分析,如表2所示。

表2 回归类方法实验的系统配置Table 2 Configuration for different regression systems
实验结果如图8所示,可以看出加入声学参数与发音动作参数之间的依赖性可以明显提高预测的准确性。并且当增加转换矩阵的数目时,可以提高发音动作参数的预测准确性,在绑定到每个叶子节点时得到最优结果。
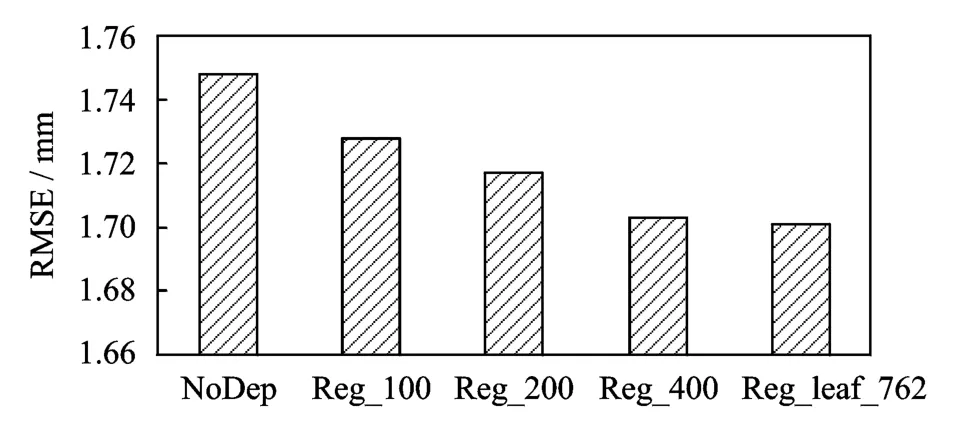
图8 考虑流间相关性并采用不同绑定方式训练转换矩阵时的系统客观测试结果Fig.8 Objective evaluation of articulatory RMSE on different regression systems
4 结束语
本文首先阐述了制作中文连续语流发音动作参数数据库及发音动作参数预处理方法。并且在中文数据库上进行了基于HMM的发音动作参数预测实验,对比了不同上下文模型、聚类方式对发音动作参数预测性能的影响,结果表明采用三音素模型与单独聚类的模型结构可以得到较好的结果。本文还采用有偏置的线性变换对流间相关性进行建模,并且对转换矩阵的回归类训练方法进行研究。实验表明,随着使用的转换矩阵回归类数目的增多,预测的发音动作参数误差明显下降。未来计划在声学参数与发音动作参数联合模型训练准则、引入非线性变换表征两种参数间依赖关系等方面开展进一步的研究工作。
[1] 赵力.语音信号处理[M].北京:机械工业出版社,2009:14-16.
Zhao Li.Speech signal processing[M].Beijing:China Machine Press,2009:14-16.
[2] Kiritani S.X-ray microbeam method for the measurement of articulatory dynamics:Technique and results[J].Speech Communication,1986,45:119-140.
[3] Bare T,Gore J C,Boyce S,et al.Application of MRI to the analysis of speech production[J].Magnetic Resonance Imaging,1987,5:1-7.
[4] Akgul Y,Kambhamettu C,Stone M.Extraction and tracking of the tongue surface from ultrasound image sequences[J].IEEE Comp Vision and Pattern Recog,1998,123:298-303.
[5] Summerfield Q.Some preliminaries to a comprehensive account of audio visual speech perception[M].Hillsdale,NJ England:Lawrence Evlbaum Associates,1987:3-51.
[6] Schönle P W,Gröbe K,Wening P,et al.Electromagnetic articulography:Use of alternating magnetic fields for tracking movements of multiple points inside and outside the vocal tract[J].Brain Lang,1987,31:26-35.
[7] 凌震华.基于声学统计建模的语音合成技术研究[D].合肥:中国科学技术大学,2008.
Ling Zhenhua.Research on statistical acoustic model based speech synthesis[D].Hefei:University of Science and Technology of China,2008.
[8] Kirchhoff K,Fink G,Sagerer G.Conversation speech recognition using acoustic and articulatory in-put[C]//ICASSP.Istanbul,Turkey:IEEE,2000:1435-1438.
[9] Ling Zhenhua,Richmond K,Yamagishi J,et al.Integrating articulatory features into HMM-based parametric speech synthesis[J].IEEE Transacions on Audio,Speech,and Language Processing,2009,17(6):1171-1185.
[10]Blackburn C S,Young S.A self-learning predictive model of articulator movements during speech production[J].Acoustical Society of America,2000,107(3):1659-1670.
[11]Birkholz P,Kröger B J,Neuschaefer-Rube C.Model-based reproduction of articulatory trajectories for consonant-vowel sequences[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,10(5):1422-1433.
[12]Ling Zhenhua,Richmond K,Yamagishi J.An analysis of HMM-based prediction of articulatory movements[J].Speech Communication,2010,52:834-846.
[13]Toda T,Black A W,Tokuda K.Statistical mapping between articulatory movements and acoustic spectrum using a Gaussian mixture model[J].Speech Communication,2008,50:215-227.
[14]Richmond K.Trajectory mixture density networks with multiple mixtures for acoustic-articulatory inversion[C]//NOLISP.Berlin,Heidelberg:Springer-Verlag,2007:263-272.
[15]Tokuda K,Zen H,Black A W.HMM-based approach to multilingual speech synthesis[M].United States:Prentice Hall,2004.
[16]Shinoda K,Watanabe T.MDL-based context-dependent sub-word modeling for speech recognition[J].Journal of Acoustical Society of Japan (E),2000,21(2):79-86.
[17]Yoshimura T,Tokuda K,Masuko T,et al.Duration modeling in HMM-based speech synthesis system[C]//ICSLP.Sydney,Australia:[s.n.],1998,2:29-32.
[18]Tokuda K,Yoshimura T,Masuko T,et al.Speech parameter generation algorithms for HMM-based speech synthesis[C]//ICASSP.Istanbul,Turkey:[s.n.],2000,3:1315-1318.
