基于VC++的视频字幕自动提取系统的设计与实现*
2014-07-25季丽琴
季丽琴
(苏州健雄职业技术学院 电气工程学院,江苏 太仓 215411)
0 引言
随着计算机科学的飞速发展,海量的视频出现在数字图书馆、电视广播和互联网上。在这些视频中,大多数都嵌入了一些解说性的、含有丰富语义信息的文字,例如:说话者姓名、电视节目介绍、节目名称、滚动文字新闻、实时比分、运动员号码、时间等信息[1-3]。如果能将这些文字自动提取出来,将对视频的索引起到关键的作用,有利于用户迅速准确地从海量视频中找到自己感兴趣的内容[4],在信息化的时代背景下,视频字幕自动定位与提取的应用价值越来越高。本系统的开发是基于Windows环境下的MFC平台,利用Visual C++[5-7]面向对象的编程语言而完成的。实验结果表明,该系统具有文字提取较精准、运行稳定等优点。
1 系统总体设计
1.1 系统实现目标
该系统实现的基本目标是基于Visual C++6.0开发环境,对一个含有字幕信息的24位真彩色的JPEG文件,通过文字提取算法的处理来实现视频图像中字幕的自动定位与提取。
在文字提取方面,国内外学者都做了一定的研究,大致可以分为基于边缘、基于纹理和基于连通区域三类方法。KEECHUL J等人[8]提出一种综合运用纹理和连通组元分析的方法来定位文字,组建基于多层感知器(MLP)的纹理分类器和基于连通分量(CC)的滤波器,整个算法复杂,且需要足够的训练样本。KIM K I等[9]人提出用支持向量机(SVM)的纹理分类器来检测视频中的文字,该方法的检测结果虽然较好,但是计算量大。ADRIAN C R等人[10]提出基于颜色聚类的方法进行文字定位,其主要针对手机上的视频图像有一定的局限性。本文在分析以上文字提取算法的基础上,提出一个新的、有效的文字提取算法,即利用垂直、水平、对角3个方向的边缘检测算子检测出3个方向的文字边缘信息;在此基础上,利用形态学对3个方向的边缘图像进行处理,最终,将3个方向的图像进行与融合,消除大量的噪声,从而定位并提取出字幕区域。实验验证,该算法能较好地提取出视频中的字幕信息。
1.2 系统的体系结构设计实现
该系统采用MFC单文档单视图的结构设计,通过文件→打开的方式读取图像文件,并判断文件是否满足处理要求(24位真彩色的JPEG文件)。该系统的处理流程如图1所示。该工程的工程名为“ViewDIB”,图像文件打开与数据读取在类CViewDIBDoc中的CViewDIBDoc::OnOpenDocument(LPCTSTR lpszPathName)函数中实现,而图像的显示及对各种处理算法菜单命令的响应在类CViewDIBView中实现。系统的主界面如图2所示。
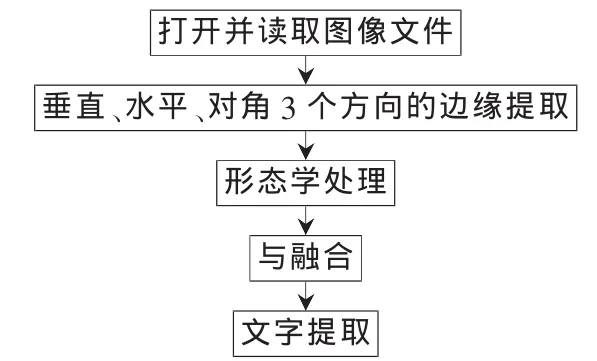
图1 系统的处理流程图

图2 系统界面图
2 垂直、水平、对角方向的边缘提取
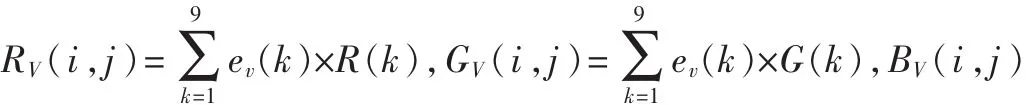

图3 3个方向的彩色边缘检测算子
在编写程序时,在视类CViewDIBView中建立3个消息响应函数OnVertedge()、OnHorzedge()和OnVerthorzedge(),分别提取垂直、水平和对角方向的边缘信息。以垂直方向为例,其函数具体实现代码如下:

完成代码的编写、编译和链接后,即可在调试出的系统界面中的工具栏中点击“VE”、“HE”、“DE”轻松获取3个方向的边缘图像。图4给出了3个方向的边缘检测结果。

图4 3个方向的边缘图像
3 形态学处理
数学形态学的基本运算有4个:膨胀、腐蚀、开启和闭合[11-12]。本文利用这4个运算设计了一个针对3个方向边缘图像的形态学处理方案,每个方向的边缘图像都经过下面的处理,具体实施如下:(1)利用一次闭合运算,填补字幕区域内的空洞;(2)利用一次开启运算,删除字幕区域以外的噪声;(3)利用6次水平方向的膨胀与3次水平方向的腐蚀扩大和缩小字幕区域,此处采用水平方向的结构元素B={1,1,1,1,1}。实验证明此结构大小适中,且能有效地形成文字连通域,如图5所示。
在编程时,视类CViewDIBView中建立OnCloseOperate()、OnOpenOperate()、OnHDilation()、OnHErosion()4个消息响应函数,它们分别代表闭合、开启、水平膨胀、水平腐蚀运算。在系统界面中,只需在工具栏中点击与上面4个函数对应的图标“C”、“O”、“HD”、“HE”即可完成以上4个运算。其中闭合运算“C”的代码实现如下:

图5 三个方向的连通域图

4 与融合
为了较精准地判断出字幕区域,在得到了垂直、水平、对角3个方向的文字连通域图TV(x,y)、TH(x,y)、TD(x,y)后,本系统采用“与”融合的方法,将3个方向的文字连通域图进行相与运算。
MFC编程实现时,在系统界面中添加“AND”图标,同时在视类CViewDIBView中建立起与之对应的消息响应函数OnTextVerify(),其程序代码实现如下:

实验证明,采用与融合方法能去除很大部分的噪声区域,能较准确地定位出字幕区域TI(x,y)。但也发现在TI(x,y)中仍存在小部分的伪字幕区域,因此,本文运用递归算法[13]统计出各候选文字区域的白色像素总数PixelNum,若PixelNum<areapixel(areapixel为图像高度×图像宽度/150),则伪字幕区域就被删除。实验证明,此方法简单且能有效地判断出字幕区域,图6给出了与融合的处理结果。

图6 与融合的结果
5 字幕区域的坐标定位与提取
在去除了伪字幕区域后,本文采用以下算法完成字幕区域的坐标定位。
(1)判断像素点(x,y)是否为白色,若不是,则算法结束;
(2)若像素点(x,y)是白色,则扫描(x,y)的4个邻域,若4个邻域内无白色像素,则算法结束,并返回文字区域的左上角和右下角坐标值;
(3)若(x,y)的4个邻域仍存在白色像素点,则调整文字区域的左上角和右下角坐标,并继续判断其他像素点及其邻域是否为白色像素点,最终返回一个确定的左上角和右下角坐标值。
在编写程序时,在系统界面的工具栏中建立“L”和“EX”图标,分别代表字幕区域的坐标定位(Location)与提取(Extraction),同时,在视类CViewDIBView中创建与两个图标对应的消息响应函数OnTextLocate()和OnTextExtract()来完成字幕区域的坐标定位与提取,其结果如图7所示。

图7 字幕区域的坐标定位与提取
6 结论
本系统基于字幕的边缘特征信息,利用了垂直、水平、对角方向的边缘检测算子获取字幕的边缘信息,在此基础上,结合数学形态学的处理,得到3个方向的字幕连通域图,最后将这3个不同方向的连通域图进行逻辑与融合,定位并提取出最终的字幕区域。实验结果表明,基于Visual C++6.0环境下并结合文字提取算法实现的字幕自动提取系统具有字幕定位准、运行速度快且稳定等特点。
提取出字幕信息后,本系统下一步的研究方向为:(1)对字幕信息进行二值化等处理,并将其送入OCR系统进行识别;(2)基于Visual C++6.0开发环境,结合开源发行的跨平台计算机视觉库OpenCV,进一步优化和完善本系统。
[1]张洋.电视视频字幕文字的提取方法研究[D].合肥:中国科学技术大学,2009.
[2]陈义,李言俊,孙小炜.利用OCR识别技术实现视频中文字的提取[J].计算机工程与应用,2010,46(10):180-183.
[3]姜晓希,冯靖怡,冯结青.视频内容敏感的动态字幕[M].计算机辅助设计与图形学学报,2011,23(5):855-862.
[4]章毓晋.基于内容的视觉信息检索[M].北京:科学出版社,2003.
[5]王占全,徐惠.Visual C++数字图像处理技术与工程案例[M].北京:人民邮电出版社,2009.
[6]张宏林.精通Visual C++数字图像处理典型算法及实现(第2版)[M].北京:人民邮电出版社,2008.
[7]俞朝晖,庞也驰,于涛.Visual C++数字图像处理与工程应用实践[M].北京:中国铁道出版社,2012.
[8]KEECHUL J,HAN J H.Hybrid approach to efficient text extraction in complex color images[J].Pattern Recognition Letters,2004(25):679-699.
[9]KIM K I,JUNG K C,RARK S H,et al.Support vector machines for texture classification[C].IEEE Transactions on Image Processing,2002,24:1542-1550.
[10]ADRIAN C R,KIM J H,KIM S H.Efficient text extraction algorithm using color clustering for language translation in mobile phone[J].Signal and Information Processing,2012(3):228-237.
[11]李敏,蒋建春.基于腐蚀算法的图像边缘检测的研究与实现[J].计算机应用与软件,2009,26(1):82-84.
[12]范立南,李金峰,张义鑫.基于Visual C++的广义形态图像边缘检测算法[J].计算机应用与软件,2006,23(7):8-10.
[13]徐慧.Visual C++数字图像实用工程案例精选 (第1版)[M].北京:人民邮电出版社,2004.
