基于IQMath自适应速度前瞻算法的设计与优化*
2014-07-18陈智殷陆小虎
彭 鹏,胡 毅,于 东,陈智殷,陆小虎
(1.中国科学院大学 研究生院,北京 100049;2.中国科学院沈阳计算技术研究所 高档数控国家工程研究中心,沈阳 110168;3.沈阳高精数控技术有限公司,沈阳 110168)
基于IQMath自适应速度前瞻算法的设计与优化*
彭 鹏1,2,胡 毅2,3,于 东3,陈智殷1,2,陆小虎1,2
(1.中国科学院大学 研究生院,北京 100049;2.中国科学院沈阳计算技术研究所 高档数控国家工程研究中心,沈阳 110168;3.沈阳高精数控技术有限公司,沈阳 110168)
自适应速度前瞻控制算法作为数控系统实现高精、高速加工控制的核心算法,其运行效率以及运算结果的精度直接影响着整个工件的加工效率以及加工质量,文章基于ARM+DSP构建的双核架构嵌入式数控系统,研究和分析了自适应速度前瞻控制算法实现的基本原理、IQMath库的优化原理、以及线性汇编级的优化方法,在此基础上设计并实现了自适应速度前瞻控制算法,针对实验室嵌入式数控系统定点DSP的特点,对该算法先后进行了基于IQMath库的优化,以及线性汇编级的优化,并对优化前与优化后算法进行了性能评估以及误差分析,结论表明优化后的算法在性能上较好地满足了嵌入式数控系统对实时性的要求。
自适应;前瞻算法;IQMath;线性汇编
0 引言
IQMath库是TI公司编写的一个高优化、高精度的数学函数库,主要是针对定点DSP,由于定点DSP中没有浮点运算单元FPU的支持,因此在定点DSP中做浮点运算是通过软件模拟的方式实现,其效率比软低,IQMath库主要是将C语言编写的含有浮点运算的程序,转换成定点运算,IQMath的使用能够获取比标准ANSI C语言更快的执行速度。
数控系统作为数控机床实现高精、高速、高质量加工的控制核心,其内部运行的运动算法的优劣直接影响着数控机床的加工质量与加工效率,并且一直是评价数控系统加工质量的重要指标。数控系统中运动轨迹的复杂多变,轨迹衔接点处的进给速度的处理,是衡量数控系统运动控制算法优劣的重要指标,如果处理的不好,很容易造成系统的抖动,对机床具有很大的冲击,因而会降低工件的加工精度以及加工效率。自适应速度前瞻控制算法采用前瞻思想,对拐点处的速度提前进行预估,将刀具的速度提前降下来,避免了刀具速度的突变,对系统稳定至关重要;因此对该算法进行性能上的优化具有非常重要的意义。
针对上述问题,本文基于OMAP3530构建的嵌入式数控平台,研究了IQMath库的优化原理、汇编级的优化、自适应速度前瞻算法的设计思想,设计并实现了自适应速度前瞻算法,并对算法进行了基于IQMath库的优化以及汇编级的优化,对优化前与优化后的算法在上述两种平台上分别进行了性能测试。
1 Q格式的数据类型
浮点数在定点DSP上的运算一般采用两种方式进行: ①直接采用浮点(float)格式来表示浮点数,采用float格式表示的浮点数,在定点DSP上的运算采用的是软件模拟的方式进行的,例如在TMS320C64X+上进行浮点乘法,DSP内部是通过_mpyf函数实现的,而对于定点乘法,则有专门的乘法指令MPY在2个时钟周期内完成,因此在定点机上直接使用float类型进行浮点数的运算影响算法的性能;②浮点数放大,通过将浮点小数放大若干倍后变成整数,然后在定点DSP上以定点数的形式运算,通过浮点放大变成整数的方式可以提高算法的运行效率,但是在算法的移植性方面效果不佳。
为了提高定点DSP在浮点运算方面的性能以及可移植性,TI公司专门编写了进行浮点运算的IQMath库,IQMath库中函数的输入与输出一般都是32位的定点数,根据定点数小数点位置的不同,可以将定点数分成32类,在IQMath库里面称为Q格式,其变化范围为Q0~Q31,其中下标表示定点数的小数点位置,Q格式表示的定点小数如公式(1)所示,其中S表示符号位,Ik(k∈{0≤k≤30})表示第k位的二进制数。
(1)
由于定点数小数点位置的固定,因此Q格式的数据类型表示精度也随着小数点位置的不同而不同,如文献[1]中所示的不同Q格式数据类型的精度取值范围,从中可以看出Q格式数据类型随着下标的增大,表示的精度越来越高,但是表示的范围却越来越小。
2 IQMath库的优化原理
2.1 内联函数与宏定义的使用
C语言中过多的函数调用,虽然可以提高程序的结构化与规范化,但是会降低程序的运行效率,函数调用本身就是一个复杂的过程,调用的过程中涉及到函数调用上下文环境的交换,函数参数的传递,堆栈的操作等一系列复杂的过程,如果一个算法中涉及到太多的函数调用,以及函数的嵌套调用,势必会影响到算法的运行时间以及算法的空间开销,内联函数类似于宏定义,都是在调用处对代码进行展开,替换掉调用处的代码,只不过一个处于预编译阶段,而另一个处于编译阶段,IQMath库中大量的使用inline、define关键字,避免由于函数调用造成的程序运行时间的开销,如IQ类型之间的转化,浮点类型到Q格式的转换函数:
#define_IQtoIQ31(A)((I32_IQ)(A)<<(31-GLOBAL_Q))
static inline I32_IQ _FtoIQN(float input, U32_IQ qfmt)
2.2 数据表的使用
IQMath库为了提高程序的运行效率,将一些常用的函数值打包成静态库的形式,在程序加载时,直接加载到内存中,函数在运算的过程中,通过查表的形式,可以显著提高程序的运行效率,如sin(x)的计算是通过Taylor展开式在x0=0处展开计算的,其每一项的系数均为常数:
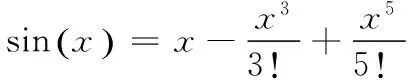
2.3 数据类型的转化
2.4 其他技术的使用
IQMath提供的都是静态库,相比于动态库的好处,程序在编译的时候,将静态库链接到目标代码中,程序在运行的过程中,不再需要此静态库,而动态库是在程序运行的时刻才被载入,因此在速率上不如静态库,将相关的函数改成与特定DSP架构相关的汇编语言或线性汇编语言实现,速度上比高级语言执行的要快。
3 链接器配置文件
链接器配置文件确定了程序链接成最终可执行代码时的选项,其中有很多的条目,实现不同方面的选择,最为重要的就是为可执行文件进行存储器的分配,如图1所示,其中MEMORY指定的是存储空间布局,SECTIONS段指定的是目标文件中相关段的在存储空间的分配位置,高级语言编写的程序生成的目标文件一般有以下几个段级成(.cinit程序中变量初值和常量,.const存放程序中的字符串常量、浮点常量、const声明的常量,.switch存放switch语句的跳转表,.text存放代段,.bss为全局变量与静态变量保留存储空间)。
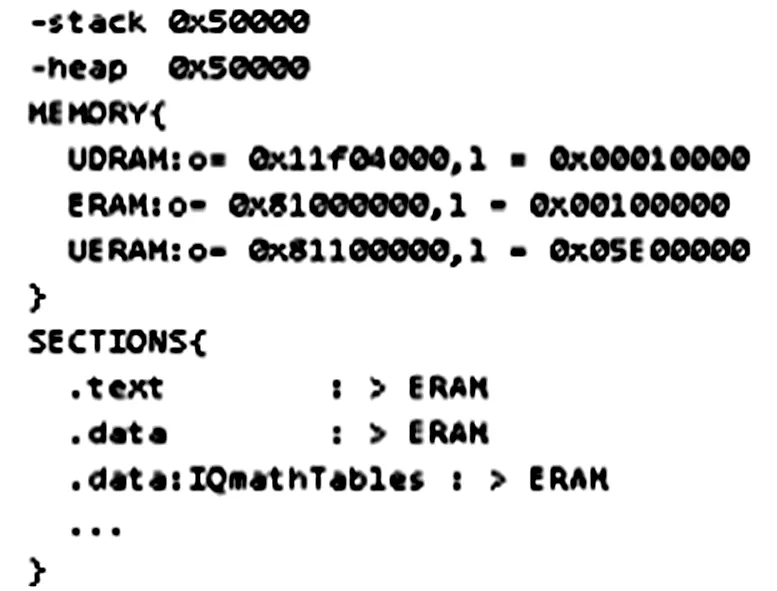
图1 CMD文件内存配置
由于RAM的访问速度要快于ROM,因此在使用IQMath库时可以将IQMath的相关函数查询表以及数据表通过链接配置文件在程序运行时直接加载进RAM中,以提高算法的性能,如:
.data:IQmathTables :>ERAM
.data:IQmath :>ERAM
4 线性汇编与汇编
实现DSP算法一般分为3个阶段,第一阶段产生C代码,第二阶段优化C代码,第三阶段编写线性汇编代码,相关程序的编写流程如下图2如示,通过C语言编写的程序由于未能充分考虑DSP内部架构的特点,因此在性能上往往达不到要求,这时可以考虑使用线性汇编或者汇编语言进行代码的改写,线性汇编与汇编类似,它的扩展名必须是.sa,用做汇编优化器的输入文件,线性汇编代码的编写无需考虑寄存器的分配、功能单元的分配、指令的并行性等,汇编优化器在优化线性汇编代码时仅对伪指令对.proc与.endproc之间的代码进行优化。

图2 DSP程序的编译流程
5 自适应速度前瞻算法
以直线加减速为例,对连接微小路径段的速度衔接建立数学模型,分析出其速度变化的规律,以实现微小路径段之间速度的高速衔接,一条路径段的加工一般有加速,匀速,减速中一种或几种情况(如图3所示),图中加速,匀速,减速阶段的位移长度分别为S1、S2、S3,vs、ve、vmax分别代表任一路径段的起始速度、终止速度、以及数控系统允许的最大速度,假设数控系统中允许的最大加速度以及插补周期为amax、T,某一路径段的长度为L,根据位移、加速度、速度之间的物理模型可以计算出速度的临界值vm,如公式(2)所示。
(2)

图3 刀具的运动学模型
数控机床在加工的过程中,轨迹衔接点之间有一些硬性条件对速度进行了限制,因此机床在加工的过程中,刀具的运动速度必须要小于此速度的限制,假设此速度限制为vx,由文献[2,4,7]可以得出此速度的限制公式(3)。
(3)
自适应前瞻算法的关键点主要在于前瞻段数的确定,算法的思想如文献[2]所示,算法的程序流程图如文献[11]所示。
6 前瞻算法的优化
数控系统主要是对刀具运动轨迹的精确控制,因此算法主要是针对浮点数进行运算,在定点DSP中,由于没有浮点运算单元FPU的支持,因此浮点运算在保证精度的情况下采用的是软件模拟方式进行实现的,影响了算法的执行效率,对算法依据IQMath库进行改写,将浮点运算转化成定点运算可以显著提高算法的效率,实验中为了保证精度,以及算法运行的正确性,选择了Q24的数据类型。
高级语言编写的代码由于未能充分考虑DSP处理器的架构,因此对时间要求比较苛刻的算法,其性能往往达不到指定的要求,因此需要根据DSP处理器的体系结构对算法进行线性汇编级的优化,算法中由于需要多次计算坐标系中两点之间的距离,通过C语言编写的代码在CCS调试运行时查看其汇编代码数据的加载采用的是LDW指令,由于数据是连续存放的,采用LDW指令在6个时钟周期内只能取出一个字的数据,而采用LDDW指令在6个时钟周期内可以取出2个字的数据,增加了数据传输的带宽,函数进行线性汇编改写后的代码如图4所示。
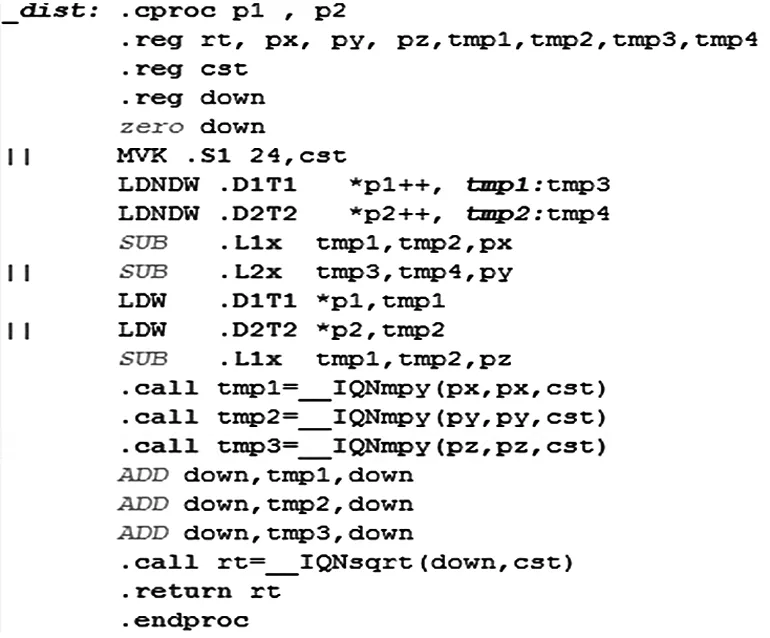
图4 三维坐标系中两点距离的线性汇编代码
7 实验与性能评估
实验采用高精数控总线实验室(如图5)现有的基于OMAP3530的嵌入式数控平台,OMAP3530是TI生成的一款集成ARM 以及DSP的异构双核高性能嵌入式处理器,实验中编程给定的最大进给速度vmax=6mm/s,插补周期为2ms,系统允许的最大加速度amax=20mm/s2,最大轮廓误差为ecmax=0.001mm,实验中测试的运动轨迹由 25个插补坐标点构成,对前面的自适应前瞻算法分别进行了优化前与优化后算法的性能测试。
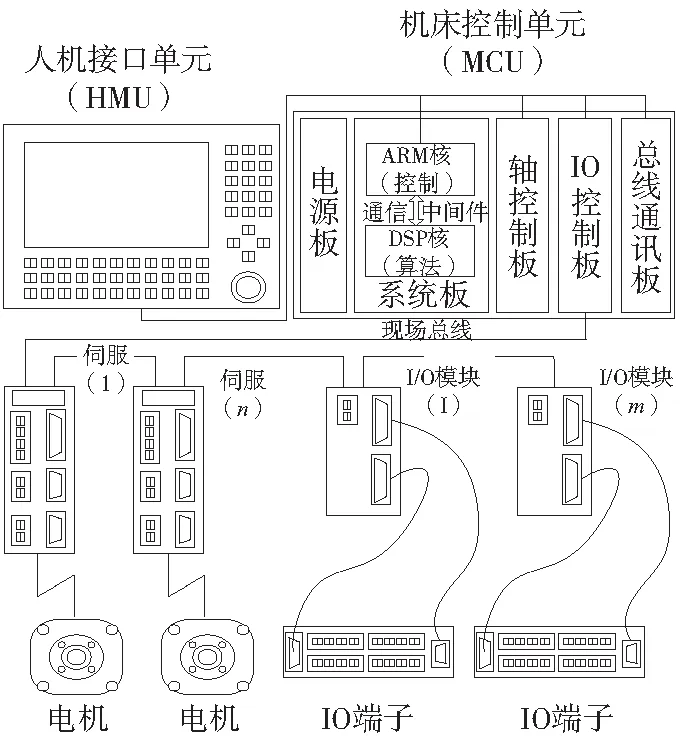
图5 OMAP3530嵌入式数控系统平台
实验结果主要以算法的运行时间以及运算时产生的误差作为衡量标准,为了保证实验的精度,每次实验均以算法运行1000次的结果作为分析,如下图6所示为算法在未优化前的执行时间图,图7为算法采用IQMath库优化后的执行时间图,图8为算法在IQMath库优化的基础上采用线性汇编再次优化后的执行时间图。
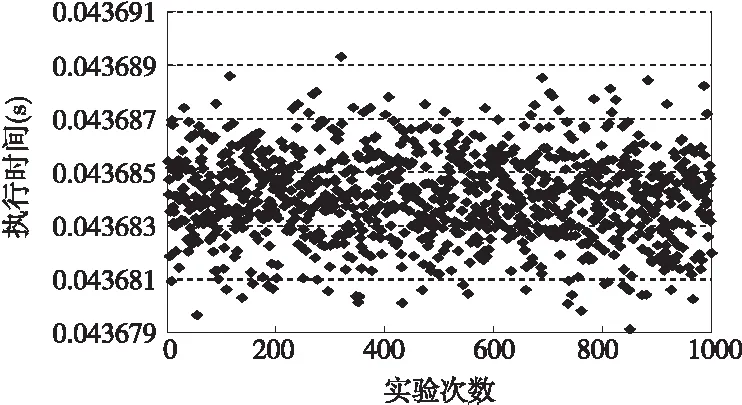
图6 未优化前算法执行时间图
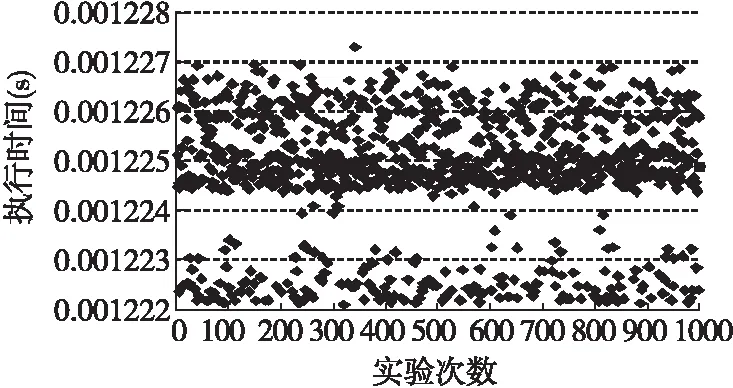
图7 IQMath优化后算法执行时间图
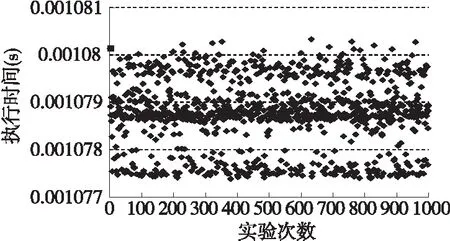
图8 线性汇编优化后算法执行时间图
由实验结果可知优化前与优化后的算法之间执行时间最大相差42.68498ms,算法执行1000次时未优化的算法期望执行时间是43.6841ms,采用IQMath库优化后的算法期望执行时间1.2248ms,对关键代码进行线性汇编改写后算法的期望执行时间是1.07738ms,表1为优化前与优化后算法执行1000次时的平均时钟周期数。

表1 算法执行的时钟数对比
算法的误差是以算法执行过程中对刀具的速度规划进行衡量的,相同时间点优化前与优化后规划的速度之间的差值即为使用IQMath库优化算法后产生的误差,使用IQMath库优化前与优化后算法的误差为5.164×10-5,由于线性汇编级的优化是在IQMath库的基础上做的,因此对算法的速度规划结果不产生影响,误差值保持不变。
嵌入式数控系统OMAP3530在ARM运行的是EMC2,适应前瞻速度控制算法运行在DSP端,为了保证系统的实时性需求,ARM端将轨迹点写入缓存,DSP端从缓存中取出数据,并进行运算,为了保证系统的实时响应,系统能允许的极限时间为20ms,因此优化后的算法能够很好的满足系统的实时性需求。
8 结论
自适应速度前瞻控制算法作为数控系统实现高精、高速加工控制的核心算法,其运行效率以及精度直接影响着整个工件的加工效率以及加工质量,本文基于OMAP3530构建的双核架构嵌入式数控系统,研究和分析了IQMath库的优化原理、线性汇编级的优化、自适应前瞻算法实现的原理,设计并实现了自适应前瞻算法,基于IQMath库以及线性汇编的前瞻算法,对优化前与优化后的算法进行了性能评估,对于目前的高精、高速数控加工具有一定的的理论与实际意义。
[1] Texas Instruments.TMS320C64X+ IQmath Library User’s Guide.2008 December.
[2] 徐志明,冯正进,汪永生.连续微小路径段的高速自适应前瞻插补算法[J].制造技术与研究,2003(12):20-22.
[3] 于东,周雷,黄燕,等.微小程序段的动态前瞻处理方法及实现装:中国,ZL200510047751.X[P].2005,11,18.
[4] 王海涛,越东标,高素美.CNC自适应速度前瞻控制算法的研究[J].机械科学与技术.2009(3):346-349.
[5] 彭志明,李琳.基于IQmath库的定点DSP算法设计[J].单片机与嵌入式系统应用,2010(9):39-41.
[6] 李珊珊.嵌入式弹载计算机性能优化与实现[J].航空兵器,2011(2):56-59.
[7] 张晓辉.数控系统高速高精运动轨迹控制技术的研究与实现[D].北京:中国科学院研究生院,2011.
[8] 郑回青,林嘉宇,张镔.基于TMS320C64x DSP的汇编优化方法[J].微处理机,2010(2):105-108.
[9] 宋巍.基于TMS320DM6446的AVS编码器的实现[D].太原:太原理工大学,2008.
[10] 胡毅,于东,李培楠,等.基于现场总线的开放式数控系统的设计与实现[J].小型微型计算机系统,2008,29(9):1745-1749.
[11] 冯强,胡毅,于东,等.基于多核嵌入式数控系统的速度前瞻算法研究[J].组合机床与自动化加工技术,2013(3):16-20.
(编辑 李秀敏)
Speed Look-ahead Algorithm Design and Optimization Based on IQMath
PENG Peng1,2,HU Yi2,3,YU Dong3,CHEN Zhi-yin1,2,LU Xiao-hu1,2
(1. University of Chinese Academy of Sciences, Beijing 100049,China;2. National Engineering Research Center For High-End CNC, Shenyang Institute of Computing Technology, Chinese Academy of Sciences, Shenyang 110168,China)
Execution efficiency and The accuracy of the operation result have directly impact on the processing efficiency and processing quality of the workpiece, Based on ARM&DSP dual-core embedded CNC system, This paper studies and analyzes the basic principals of CNC adaptive speed look-ahead algorithm,the optimization theory of the IQMath Library, and the linear assembly level optimization methods, Base on the above theory,design and implement adaptive look-ahead control algorithm, For the characteristics of the laboratory’s fixed -point DSP embedded CNC system,adopt IQMath library and linear assembly to optimize the algorithm,at last,the performance evaluation and error analysis of un-optimized and optimized algorithm are made.
adaptive; speed look-ahead algorithm ; IQMath; linear assembly
1001-2265(2014)07-0049-04
10.13462/j.cnki.mmtamt.2014.07.014
收稿日期:2013-11-13;修回日期:2013-12-19
高档数控机床与基础制造装备国家科技重大专项:基于二次开发平台的专用数控系统开发与应用(2013ZX04007-011)
彭鹏(1988—),男,河南信阳人,中国科学院大学硕士研究生,主要研究方向为数控技术,(E-mail)pengpeng03@baidu.com。
TH166;TG65
A
