面向可信和行为模式匹配的两层服务选择方法
2014-07-11孟宪佳马建峰王一川
孟宪佳, 马建峰, 卢 笛, 王一川
(西安电子科技大学 计算机学院,陕西 西安 710071)
目前,日益增长的电子商务、电子政务、电子医疗等社会化活动已不断融入人们的日常生活.然而,如何将这些不同载体、不同用户、不同背景的应用融合,已成为不可避免的问题.面向服务的框架(SOA)正是解决这一问题的关键.实现Web服务在无人监管的状态下进行自选、自组并最大限度地满足用户需求是当下服务计算(SOC)的研究热点.在这一领域中,“信任”被视为基于因特网的交互和面向服务的环境(SOE)必不可少的部分.正如在文献[1-2]中描述的,“如果要发挥SOC的全部潜力,信任是一切的基础”.用户本身往往由于经验不足或是在特定的环境下与服务提供者进行交互,对服务的评价趋于主观或片面.这样的交互经验用于对其他用户的评价进行指导或者比对往往不足以为信.
开放系统内在的不确定性直接影响到用户对他人建立正确的信任与理解.在一个存在着恶意用户的背景中,由于服务信息的描述或评价者的个人态度和能力不同,一个本质上是诚实的评价可能被认为是不值得信赖的[3-5].用户为了降低被误导的风险,也更加倾向于向自己最相似的评价者寻求建议.
针对上述问题,笔者提出一种两层选择的结构.第1层着眼于修正自身的交互记录,提高内含的可用性与可信度;第2层对推荐者进行筛选,首先将恶意的、可信度低的用户过滤掉,其次与修正过的用户交互记录进行比对,选择出与用户行为模式最为相近的邻居作为推荐者.
1 二层选择结构

图1 选择流程示意图
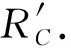
1.1 第1层(自优化)
用户C在以往与服务提供者Pr的交互过程中能够生成一份交互记录,这份记录包括了用户达到需求的交互次数a以及未达到需求的交互次数b.用这份记录来刻画用户对服务的信任度.
假设C与Pr成功交互的概率为P,C对Pr的信任度用贝塔分布来描述[6-7]:
同时,将用户C对服务提供者Pr信任度的准确度进行量化,用c表示准确度[8]:
c是一个在区间[0,1]的数.
由于用户对某服务的交互经验不足或者交互环境的差异,会对一个服务提供者的评价与服务提供者本身的可信度不符.笔者提出结构的第1层结构着力于解决这一问题.首先引入贝塔分布的倾斜度来描述不同的可信度分布函数的差异.用S来表示倾斜度[9],即
S(B(P;a,b))=2(b-a)(a+b+1)1/2/((a+b+2)(ab)1/2) .
倾斜度很直观地反映出对一个服务可信度的全局趋势.当S为负值时,可信度曲线高度集中在右半部分,左侧只有尾部;当S为正时,反之.

用户C的邻居集合N= {N1,N2,…,Ni}.
C对Prj的倾斜度S(C,Prj)=2(b-a)(a+b+1)1/2/ ((a+b+2)(ab)1/2).


图2 C与群体有相似信任趋向
第1种情况,用户C与群体的信任倾斜度同向,D>0,表明C与群体具有相似的信任趋向,依然使用C自身的交互记录a和b,图2描述了这一情况.实线表示用户的信任度函数,交互记录a=5,b=2;虚线表示群体的信任函数,交互记录A=53,B=23.
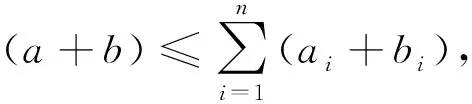
g的计算方法为g=E(Ni,Prj)Ci,其中,E(Ni,Prj)表示用户N与服务提供者Prj交互产生期望结果的概率,E(Ni,Prj)= (ai+1)/ (ai+bi+2).
图3描述了第2种情况.实线表示用户的信任度函数,交互记录a=2,b=5;虚线表示群体的信任函数,交互记录A=53,B=23.

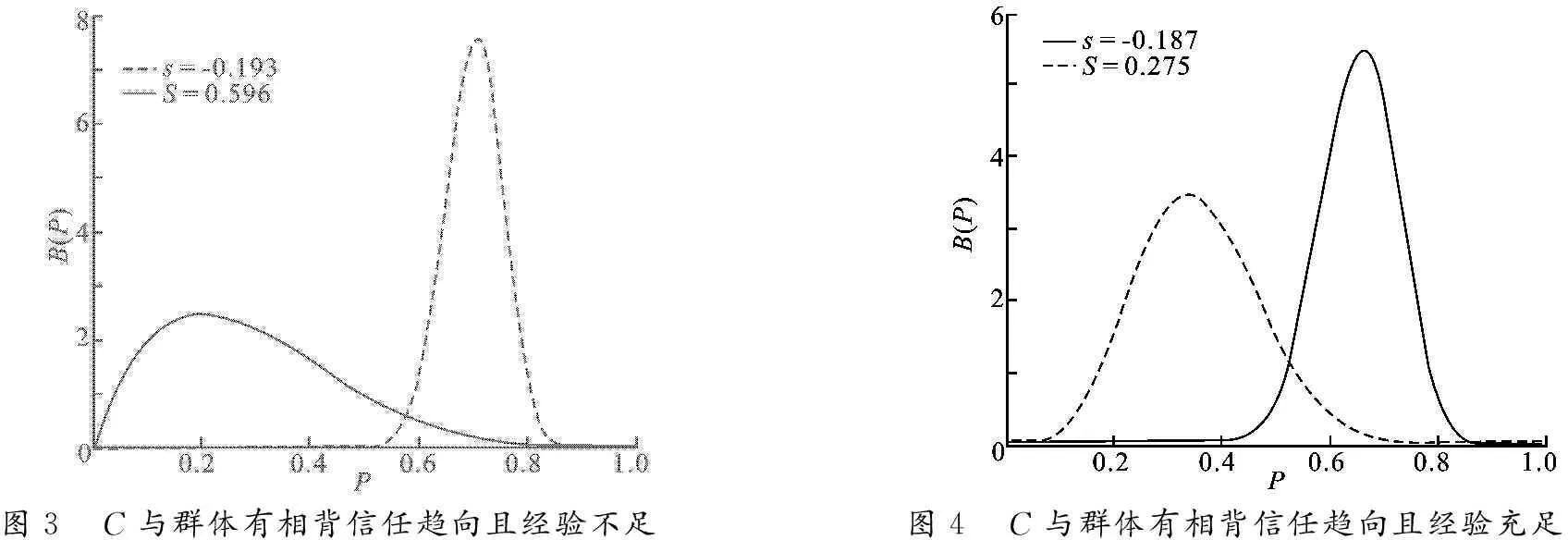
图3 C与群体有相背信任趋向且经验不足图4 C与群体有相背信任趋向且经验充足
1.2 第2层(邻居评估)
首先通过计算用户与邻居对每个服务提供者的不同认识和其准确度的差异,来筛选出最优秀的能为用户提供建议的邻居.接下来通过不同的建议者对各个邻居以及用户的评价来确定行为模式与用户最为接近的邻居,进而采取其意见[10].
1.2.1 计算各个邻居的优势度
较低的准确度会影响用户对一个服务提供者的评定,即使一个服务拥有高的可信度,但是其准确度很低,依然无法对其进行公正的判断.用户需要按照其自身的经验与各个邻居进行比对,计算出准确度的差值用于衡量邻居的准确度[9, 11],即
一个服务提供者可能会在大部分时间或接受请求时提供满足需求的服务,而在不满足特定条件的情况下不提供服务,这与用户的行为模式有着密切的关系.为了描述这一问题,比对E(C,Prj)和E(Ni,Prj),得到
为了确定各个邻居的优势度Ysup(Ni),综合以上两个方面得到
在得到各个邻居的优势度后,用户可选择满足条件的邻居.选取标准取决于用户自身的需求,通常有两种方式:第1种是用户根据精确度的要求,选择优势度达到特定标准的用户.在这种情况下,选择标准是一个固定的值.第2种方式,用户需要在所有的邻居中选择一定数量的邻居作为建议者,那么优势度的临界条件是一个动态的值,该值是由邻居的总数和选取的比例决定的.在这一步骤中,将过滤掉大部分描述不准确或者可信度低的邻居,对剩下的邻居将进行更深一步的分析.
1.2.2 行为模式比对
每个评价者对一个服务都会有某种服务质量的考量,比如价格、性价比、资源消耗、速度等,这些考量不同程度地反映着该评价者对于此服务的偏好.为了能使用户选择出最具有参考价值的邻居,必须考虑用户对于服务的选择偏好,从而找到一个和用户行为模式或选择偏好最为相似的邻居.假设对于服务提供者Prj有m种基于不同偏好的评价,用PF(Prj,Am,T)来记录.T是一个[1,10]之间的常数,T的取值方法如下:在所有的评价的时间记录中,以最早的交互的时间记录与最后交互的时间的跨度为时间区间长度,平均分为10段,并分别用1到10记录,1代表最近的时间段,2稍晚于1,……,10是距现在最远的时间.PF用一个权值和评价值的二元组{Wm,Vm|m=1,2,…,m}来量化.用户和邻居的偏好相似度用PF来进行比较.为了能够区别用户和邻居,用户的PF值用{CWm,CVm|m=1,2,…,m}表示.不同的邻居偏好可能存在着极大的差异,从而使权值Wm难以在统一标准下定量.所以,将和用户进行比较的邻居的PF升级为{CWm,Vm|m=1,2,…,m},以下给出用户和邻居偏好差异的计算方法:
式中,λ表示时间影响因子,取值为(0,1]的常数.当λ取1时,表示需要无差别地考虑任何时期的评价;当λ取值接近零时,越近期的评价越受到重视.
当DPF(Ni)确定后,按照用户的需求选择差异最小的邻居或是一个阈值范围内的邻居作为建议者.
2 算法分析
在多代理系统和云计算环境下,为了衡量用户的信任值和避免不公正的评价,学者们提出了多种方案.Josang等[6]提出了一种基于贝塔分布的信任系统,但是这种系统仅仅能提供线性的信任评价,并且对于不公正评价的过滤能力较低.Yu和Singh 提出了一种分布式的评价管理模型,此模型能够较好地定位正确的评价,并且过滤恶意的用户,但是这种模型利用单一的评价标准管理不同类型的评价,随着用户交互对象的增加,信任数据很难准确.笔者提出的方案与以上提及的依靠评估建议者的不公正评价的概率建立信任关系的机制不同,通过多层的过滤,考虑多维度的要素,综合计算建议者的信任值.也就是说,不仅评估用户的评价信息,并且将其行为特点作为考虑内容,综合得出建议者的信任值.在这种模式下,每一个用户不同行为特征是能够通过多维度评级方法客观地评估建议者的相似程度.此外,用户自适应地对不同的用户采用不同的信任评价标准,非常适合各类建议者.算法具体流程如图5所示.

图5 算法流程图
3 实验结果
笔者提出的两层选择结构可以有效地用在数字家庭社区等公开可评论环境中,以下分别对自优化层和邻居选取层进行充分的实验.
为了更好地说明自优化层的实验结果,把用户按照诚实度和能力(h,e)进行划分[12-13].如图6所示,区域1的用户既缺乏专业知识也不诚实,他们对服务的描述极不准确.区域2的用户缺乏Web服务方面的知识,但是能够准确地描述自己的感受,由于对Web服务知识的缺乏,他们的描述趋于主观,不能客观地反映服务本身.区域3的用户极为危险,他们拥有专业知识并且不诚实,这意味着他们的评价往往与事实相反.区域4的用户是最理想的用户,评价专业并且诚实,他们对服务的评价十分客观.设置自优化层的目的即是要使用户的交互记录尽可能地接近于理想用户,为此用100位邻居与30组服务提供者的交互记录来对用户数据进行优化.图7表明,在不公正记录的百分比不断提高的情况下,未优化的用户记录与理想用户的记录差异增加很快,而经过自优化后可以取得令人满意的结果.

图6 不同用户分类
在邻居选取层,笔者对拥有不同经验邻居的优势度进行了评估.对邻居N拥有5个服务交互者以及100个服务交互者在不同不公正评价百分比的情况下的优势度进行比较,实验结果如图8所示.结果表明,随着不公正评价的增多,N的优势度不断降低.同样也说明,用户即使在很少服务提供者的情况下,也能有效地评估N的优势度.
在对邻居行为模式的差异度计算方面,选取30位邻居与5个评价者对5种服务进行评价来进行有效性的测试,时间影响因子λ=0.6.表1是部分邻居差异度的计算结果.N1与N2的评价相同,而由于评价时间不同造成了较大的区别.N3与用户C的评价相去甚远,因此有较大的差异度.
4 总 结
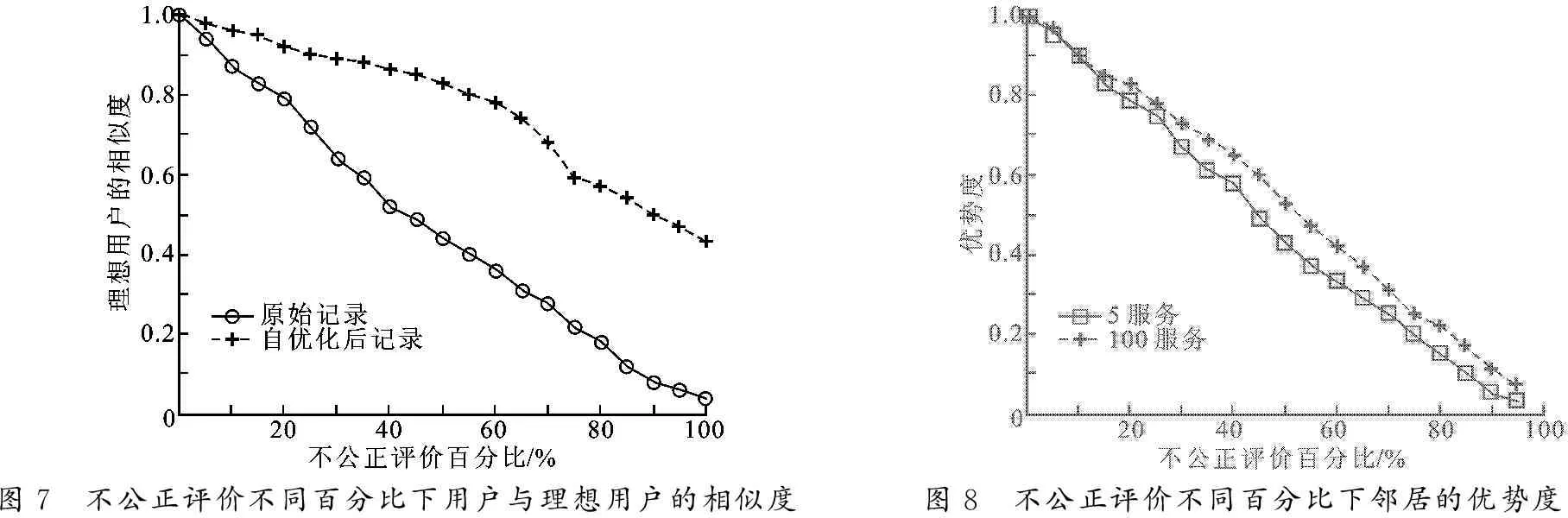
图7 不公正评价不同百分比下用户与理想用户的相似度图8 不公正评价不同百分比下邻居的优势度

表1 邻居行为差异度表
[1] Falcone R, Castelfranchi C. Generalizing Trust: Inferencing Trust Worthiness from Categories[C]//Lecture Notes in Artificial Intelligence: 5396. Berlin: Springer-Verlag, 2008: 65-80.
[2] 万涛, 廖维川, 马建峰. 面向多服务器架构的认证协议分析与改进[J]. 西安电子科技大学学报, 2013, 40(6):174-179.
Wan Tao, Liao Weichuan, Ma Jianfeng. Analysis and Improvement of Anauthentication Protocol for the Multi-server Architecture[J]. Journal of Xidian University, 2013, 40(6): 174-179.
[3] Huynh T D, Jennings N R, Shadbolt N R. An Integrated Trust and Reputation Model for Open Multi-agent Systems[J]. Autonomous Agents and Multi-Agent Systems, 2006, 13(2): 119-154.
[4] Kerr R, Cohen R. Smart Cheaters Do Prosper: Defeating Trust and Reputation Systems[C]//Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems: 2. Budapest: IFAAMAS, 2009: 798-805.
[5] Noorian Z, Ulieru M. The State of the Art in Trust and Reputation Systems: a Framework for Comparison[J]. Journal of Theoretical and Applied Electronic Commerce Research, 2010, 5(2): 97-117.
[6] Jsang A, Quattrociocchi W. Advanced Features in Bayesian Reputation Systems[C]//Lecture Notes in Computer Science: 5695. Heidelberg: Springer Verlag, 2009: 105-114.
[7] Whitby A, Josang A, Indulska J. Filtering Out Unfair Ratings in Bayesian Reputation Systems[C]//Proceedings of 7th International Workshop on Trust in Agent Societies. NewYork: IEEE, 2004: 48-64.
[8] Wang Yonghong, Singh M P. Formal Trust Model for Multiagent Systems[C]//Proceedings of the 20th International Joint Conference on Artifical Intelligence. San Francisco: IJCAI, 2007: 1551-1556.
[9] Keung S, Griffiths N. Building a Trust-based Social Agent Network[C]//Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems: 1. Budapest: IFAAMAS, 2009: 68-79.
[10] Sen S, Malone N, Chakraborty K. Comprehensive Trust Management[C]//Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems: 1. Budapest: IFAAMAS, 2009: 129-146.
[11] Maximilien E M, Singh M P. Toward Autonomic Web Services Trust and Selection[C]//Proceedings of the 2nd International Conference on Service Oriented Computing. New York: Springer, 2004: 212-221.
[12] Salehi-Abari A, White T. Detecting and Dealing with Naive Agents in Trust-aware Societies[C]//Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems: 1. Budapest: IFAAMAS, 2009: 117-128.
[13] Maximilien E M, Singh M P. Reputation and Endorsement for Web Services[C]//SIGecom Exchanges: 3. Berlin: Springer, 2001: 24-31.
[14] Noorian Z, Marsh S, Fleming M. Prob-COG: An Adaptive Filtering Model for Trust Evaluation[C]//IFIP Advances in Information and Communication Technology: 358. New York: Springer, 2011: 206-222.
[15] 邓凡, 陈平, 张立勇, 等. 授权服务中策略决策点的高效评估方法[J]. 西安电子科技大学学报, 2013, 40(6): 105-112.
Deng Fan, Chen Ping, Zhang Liyong, et al. Study of High Efficiency of Evaluation of a PDP in Authorization Service[J]. Journal of Xidian University, 2013, 40(6): 105-112.
