基于LLVM的程序关注点影响分析
2014-07-10陈泓旭
陈泓旭
(上海交通大学软件学院,上海 200240)
0 引言
分析影响程序关注点的程序片段在程序分析上具有基础性作用。
在软件开发过程中,往往仅关心程序的某特定关注点,为此可通过静态分析找出影响该关注点的程序片段,在代码理解、程序除错上意义重大。
近年来符号执行工具[1-3]在现实程序排错及测试覆盖率上取得了令人瞩目的结果。但现有符号执行工具仍然会因为程序规模扩大导致状态爆炸。根据程序的影响分析削减不相关程序,可以减少符号执行过程中的状态,从而在一定程度上减少状态爆炸带来的性能瓶颈。本文根据减小符号执行程序规模这一需求,首先对程序关注点部分进行了影响性分析。
LLVM(Low Level Virtual Machine,底 层 虚 拟机)[4,11]是一个编译框架,提供了类似 RISC(Reduced Instruction Set Computing,精简指令集计算机)指令的中间形式,可进行编译时期、链接时期、执行时期以及闲置时期的优化。任何语言(C/C++,Java字节码等)只需通过LLVM编译器前端转化为LLVM的中间形式(Intermediate Representation,IR),就可以使用LLVM框架进行转化,故在中间代码上的研究具有普遍意义。
本文的实现依赖于LLVM提供的应用程序接口,实现准确的指向分析、变量修改信息、调用图、过程间可达性分析及过程间程序切片算法,定位程序中对关注点的有影响的程序片段,削减不相关的程序代码。最终经过LLVM的本地代码生成工具,得到经过削减的可执行文件。
1 静态分析技术
1.1 指向分析
指向分析用于建立指针类型变量和它可以指向的变量地址之间关系。精确的指向分析的开销很大,广泛使用的是上下文不敏感和流不敏感的Andersen算法[5]和 Steensgaard 算法[6]。前者基于子集的指向集求解,更为精确;后者基于类型系统上的等价类划分,时间复杂度低。
1.2 调用图
调用图是一种表征主调函数和被调函数之间关系的有向多图。不同的程序输入会带来不同的调用图。对于静态分析,在给定了程序的起始执行函数之后,需要建立包含所有可能被调函数的调用关系,不同精度的指向分析结果会得到不同的调用图。
1.3 可达性分析
可达性分析研究程序中的节点是否可以通过某种方式执行到另一节点。过程内的可达性可以规约到控制流图上的图可达问题。过程间的可达性建立在控制流图和函数调用图之上,与过程内分析不同,需要区分每个调用点前后的程序可达性情况。
1.4 程序切片
程序切片根据给定的程序关注点,找出影响该关注点的程序子集[12]。程序关注点包含单个变量及该变量在程序中的位置,在控制流图上根据数据依赖及控制依赖关系,采用不动点迭代求解[14-15]。
2 实现细节
实现时以流不敏感、上下文不敏感的Andersen指向分析为基础,根据外部配置信息,构建准确的调用图并削减未被调用函数,在编译单元上计算对关注点过程间的可达性片段,最终以关注点为切片准则进行切片。流程如图1所示,其中程序切片对可达性分析的依赖关系是可选的。
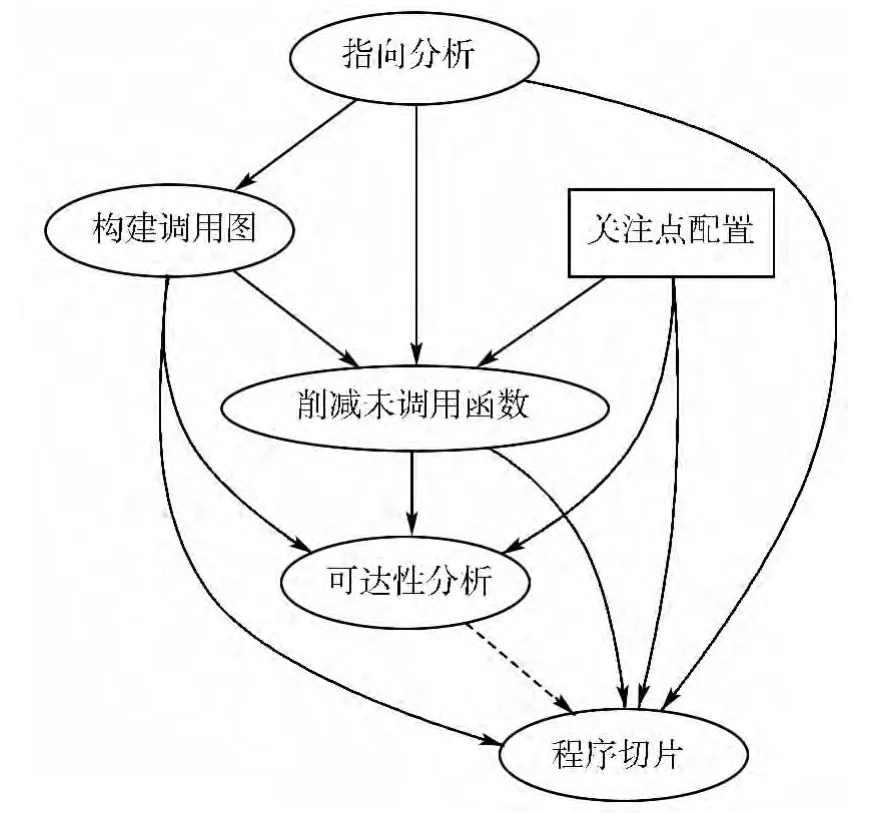
图1 实现流程依赖
2.1 关注点配置
出于程序除错的要求[7,10],目前仅将关注点局限于C语言中的assert宏中的条件变量,在LLVM的IR上需定位特定的_assert_fail(由assert宏扩展而来)调用点,找到所有前驱基本块(basic block)的终结指令的条件变量。一般而言程序中的assert调用不止一处,需要根据程序的debug信息来定位指定的调用点。这一定位操作可细化为“由源文件的配置信息在中间形式上添加元数据”及“由元数据解析得到中间形式中的关注点信息”。
2.2 调用图的构建
LLVM使用“定义使用”的方法计算调用图,下例说明这样得到的结果(如图2所示)是粗糙的。

图2 LLVM的基本调用图

该程序中main函数存在函数指针,需要将func1和func2都作为它的直接被调函数;同时populate_array采用指针传递调用了getNextRandomValue。准确的调用图如图3所示。指定的基本块”这一问题可退化为通过深度优先(或广度优先)搜索算法求解图可达问题。下节将说明不能将过程内的可达性分析直接用于削减。
2.4.2 过程间可达性
由于所关注的语句所在函数可能被调用多次,在同一函数内对同一条语句过程内可达集合是过程间可达的子集。以下面的程序为例说明其差异性。

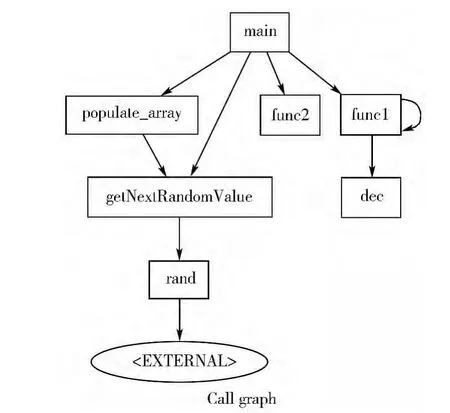
图3 准确的调用图
准确调用图的生成算法如下:
Step1 遍历整个编译单元,当遇到调用点,转至step2。
Step2 若该调用处的值为函数常量,则将该主调函数和被调函数对加入directCaller2CalleeMap中;若该调用点为间接调用,通过指向分析找出该变量指向的所有可能值,将主调函数和这些值成对加到directCaller2CalleeMap中。同时,将被调函数和调用点信息记录到directCallee2CSMap中。
Step3 重复上述2步至遍历完成,将所有直接调用映射directCaller2CalleeMap传递给间接调用映射Caller2CalleeMap。
经过该算法得到的调用图仍存在外部节点,它可能是外部库函数或未使用的函数声明。库函数不会调用该程序编译单元中的函数,故对后续分析没有影响;未使用的函数声明可通过2.3节中的方法消除。
2.3 未调用函数削减
因为编译单元中的函数有可能不会被调用,给定程序的入口函数entry后可以简化调用图。步骤如下:
Step1 遍历编译单元中的函数表,若该函数不在Caller2CalleeMapentry中,则将该函数的函数体置空,并标记为待删除函数。
Step2 遍历待删除函数集合,逐一从编译单元中删除。
该过程同时解决了2.2节中的函数声明带来的外部节点问题。本操作的必要性将在2.4.2节提及。
2.4 可达性分析
2.4.1 过程内分析
LLVM IR显式给出了每个函数的控制流图,因此“判定函数中任意基本块是否通过某种执行达到
若以函数foo中的if分支的return语句作为关注点,过程内可达性分析认为else分支不能通过任何路径达到该点。然而在main函数中存在一条“在foo2中执行了foo中else分支、而在foo执行了if分支”的可行路径,故在过程间分析中else分支语句需被计入可达关注点的集合中。
另一方面,foo1调用了foo,调用点处的语句可以达到关注点;然而foo1没有被入口函数调用,实际上不会执行到关注点。这需要通过2.3节削减未调用函数的方法将foo1从编译单元中删除。
在函数调用前后的可达性是截然不同的,过程间的分析必须特殊对待函数调用点。算法实现如下:
Step1 将每个基本块以函数调用点为界限划分为多个“子基本块”。标记所有子基本块为不可达且未访问。
Step2 对当前关注点计算过程内可达性,更新该当前子基本块为可达。将可达调用点的所有“至少有一个调用点未被访问”的被调函数及该被调函数的所有未完全被访问的被调函数(Caller2CalleeMap)的全部基本块都更新为可达,标记所有的被调函数的所有调用点为已访问。
Step3 根据directCallee2CSMap得到关注点所在函数的所有未被访问的被调用点。
Step4 将所有未被访问的调用点作为新关注点,重复Step2,Step3中的操作直至所有函数中的调用点都被访问过。
这里忽略特殊的函数调用对可达性的影响:例如exit()函数调用处于某个基本块中间,或 setjmp/longjmp函数调用等。
2.4.3 基于可达性的削减
不适当的削减会导致程序不可执行,因此并非所有的不可达语句均可削减。实现时将这些分支的内容转换为使得程序立即终止的特殊函数调用:
Step1 对编译单元中的每一个基本块计算其到关注点的可达性,将不可达节点放入不可达集合中,并将不可达节点所在的终结指令替换成LLVM IR的Unreachable指令。
Step2 遍历不可达集合中的基本块:若未被用,则将该块内容置空,并将该块从编译单元中删除;若其仍被使用,则将该块内容替换成exit(1)的函数调用。
2.5 程序切片
程序切片比基于可达性的削减更为精确,后者的削减结果仅包含实际可执行至关注点的语句,而前者进一步剔除那些可达到关注点,但并不影响关注点结果的语句。与可达性分析不同,这里的分析用于LLVM的指令层次。切片算法采用了Mark Weiser提出的基于控制流图的过程内分析和过程间调用点传递的方式[8,13]。细节上有如下改变:
(1)由于部分LLVM的IR中的指令的结果本身为变量(如LoadInst/CastInst),迭代求解程序相关集时并不区分语句和变量。
(2)经典切片算法不涉及程序内存相关指令,为此首先使用LLVM的mem2reg这一转换,消除程序中部分内存读写指令。在每个读(或写)内存的操作上,指针变量的指向的元素添加入“使用集”或“定义集”;并在函数的调用处将该函数调用可能修改的变量加入至“定义集”中。
(3)LLVM的IR要求每个基本块必须以终结指令结束,故必须保留分支跳转语句。
程序切片是基于不动点的算法,每一次程序相关集的改变都需要重新修改整个编译单元的相关集,代价是巨大的。在基于可达性削减之后的程序上进行切片可以大大减少分析的开销。
3 实验与分析
本实验使用 Coreutils 6.10[9]中的9个含有关注点配置信息的完整程序作为测试用例,经过llvm-gcc 4.2转换为LLVM的IR,影响性分析基于LLVM 2.9。结果参见表1,选用assert调用作为关注点,选取main作为入口函数。编译单元大小为经过链接之后的LLVM IR大小;削减所需时间为基于未调用函数的削减、可达性削减和程序切片的时间总和。
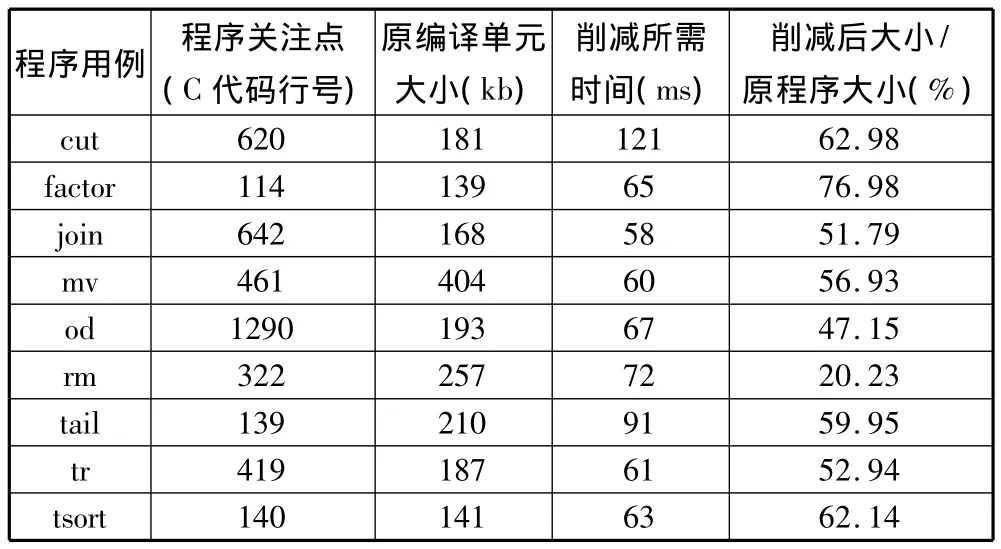
表1 程序削减结果
由实验结果可知,本方法可以高效削减程序中的不相关部分(最长时间不超过121ms)。由于Coreutils使用了大量指针、全局变量,削减后的程序仍可能较大,大部分剩余程序片段大小为原大小的47% ~63%。对于程序用例rm,程序关注点接近入口函数故削减了大部分程序;而用例factor中由于几乎所有语句均对给定关注点有影响故保留了大量程序片段。
对于削减结果的正确性使用如下方法评估:
Step1 使用llvm-lit测试框架及LLVM自带的FileCheck工具,在给定程序关注点配置信息和特定代码转换方式的条件下,验证转化后的LLVM中间形式满足:
(1)应该被削减的变量不再存在。
(2)应该被保留的变量继续存在。
Step2 给定能执行到关注点的特定程序输入,使用LLVM中间指令解释器lli分别对削减前后的IR求解,确保削减后的程序可执行,并与原有程序得到同样的输出。
实验结果表明削减后的程序均通过了上述2项测试,可认为是正确的。
4 结束语
基于LLVM框架实现了对指定程序关注点的影响分析,进而在保证程序可执行的前提之下削减不必要程序片段。实验结果表明,可以通过静态分析的方法正确、高效削减实际程序中的不相关语句。未来的工作将进一步优化削减算法,并提供对特殊函数调用的支持。
[1] Cadar C,Dunbar D,Englar D R.KLEE:Unassisted and automatic generation of high-coverage tests for complex system programs[C]//Proceedings of the 8th USENIX Con-ference on Operating Systems Design and Implementation.2008:209-224.
[2] Chipounov V,Kuznetsov V,Candea G.S2E:A platform for in-vivo multi-path analysis of software systems[C]//Proceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems.2011:265-278.
[3] Cui H,Hu G,Wu J,et al.Verifying system rules using ruledirected symbolic execution[C]//Proceedings of the 18th International Conference on Architectural Support for Programming Languages and Operating Systems.2013:329-342.
[4] LLVM.The LLVM Compiler Infrastructure[EB/OL].http://llvm.org/,2013-12-12.
[5] Andersen L O.Program Analysis and Specialization for the C Programming Language[D].University of Copenhagen,DIKU,1994.
[6] Steensgaard B.Points-to analysis in almost linear time[C]//Proceedings of the 23rd ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages.1996:32-41.
[7] Openrefactory.Openrefactory Homepage[EB/OL].http://openrefactory.org/,2013-12-12.
[8] Weiser M.Program slicing[C]//Proceedings of the 5th International Conference on Software Engineering.1981:439-449.
[9] GNU.GNU Coreutils[EB/OL].http://www.gnu.org/software/coreutils/,2013-12-12.
[10]Munawar Hafiz,Auburn A L.OpenRefactory/C:An infrastructure for developing program transformations for C programs[C]//Proceedings of the 3rd Annual Conference on Systems,Programming,and Applications:Software for Humanity.2012:27-28.
[11] Chris Lattner.LLVM:An Infrastructure for Multi-Stage Optimization[D].University of Illinois at Urbana-Champaign.2002.
[12] Susan Horwitz,Thomas Reps,David Binkley.Interprocedural slicing using dependence Graphs[C]//Proceedings of the ACM SIGPLAN 1988 Conference on Programming Language Design and Implementation.1988:35-46.
[13] Frank Tip.A survey of program slicing techniques[J].Journal of Programming Languages,1995,3(3):121-189.
[14] Agrawal H,Horgan J.Dynamic program slicing[C]//Proceedings of PLDI’90.1990:246-256.
[15] Sridharan M,Fink S J,Bodik R.Thin slicing[C]//Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation.2007:112-122.
