基于M ap-Reduce的电视新闻场景切分方法
2014-07-02崔玉斌宿玉文
崔玉斌,宿玉文,宋 征
(北京数码视讯科技股份有限公司,北京 100085)
基于M ap-Reduce的电视新闻场景切分方法
崔玉斌,宿玉文,宋 征
(北京数码视讯科技股份有限公司,北京 100085)
采用Hadoop云计算的Map-Reduce架构,对大数据电视新闻类内容进行并行的语音识别和视频分析处理,以提高效率。主要提出了基于播音员语音情节连贯性的视频段合并方法以及采用码流分析的视频场景突变检测方法。提高了新媒体生产平台自动剪切视频场景的准确性。满足用户在第一时间使用电视、平板电脑和手机等多屏终端,享受新媒体互动服务。
Map-Reduce;大数据;视频场景检测;语音识别
在当前内容爆炸的时代,电视节目的数量呈现快速增长的趋势,每天拥有数万条电视新闻资讯,涉及各个方面。以前标清分辨率的视频日积月累后就形成了海量的大数据,而随着高清的普及,以及未来4K、甚至8K的超高清电视内容,无疑会形成更加庞大的PB量级数据。为了适应移动互联网“速食主义”的时代特点,将庞大的电视新闻内容快速加以利用,需要对电视新闻节目进行及时的整理、标注和入库,并建立新媒体聚合门户,使多屏用户按需准确地检索到。
数码视讯新媒体智能互动搜索平台(IICSP)是科技部中新国际合作专项研究课题。IICSP基于业界流行的Hadoop云计算架构[1],针对PB量级的电视新闻大数据进行基于Map-Reduce架构的并行处理,实时响应大规模并发的用户请求。该平台的核心技术为基于自然语言理解的智能语音识别和基于码流分析的轻量级视频场景检测方法,实现了具有新媒体多屏点播、直播等业务的智能新媒体互动搜索平台。在三网融合不断深化的新形势下,以及移动流媒体蓬勃发展的新业态下,不断满足产业日益增加的新媒体业务需求。
1 Map-Reduce架构设计
IICSP采用了Hadoop中最核心的分布式文件系统HDFS和Map-Reduce软件编程框架技术[1]。平台的采集设备把待处理的海量电视新闻按照节目分别录制,并保存为HDFS中的文件分块,以分布式的存储方式,均匀地分配在云中的各个数据节点(DataNode)内,实现了负载均衡。在每个数据节点上,运行Map和Re⁃duce作业。Map主要执行两个操作,一是采用语音识别对电视新闻播音员的语音数据进行处理;二是进行视频场景分析和视频切分,输出新媒体数据。其中第一阶段的主要目的是对视频段进行语音识别,分析获取语音关键词作为标签,并为新媒体内容搜索建立索引;而第二阶段主要是产生三屏新媒体短视频内容。Reduce则把新媒体内容进行分类聚合,以适配新媒体聚合类应用。IICSP采用的Map-Reduce架构设计见图1。

图1 Map-Reduce架构设计图
2 电视新闻场景切分方法
电视新闻内容场景的变换很丰富,一段视频场景持续时间在几分到几秒不等,文献[2]中按照时间对视频文件进行分段是比较简单的方案,没有考虑到语音上下文的相关性。虽然并行计算能够提高系统的有效性,但存在语音识别准确率下降的问题。
IICSP中每路Map处理一个新闻节目,以保证语音识别的准确率。另外,对电视新闻内容进行深入分析可知,电视内容中视频和音频是同步的,在语义上具有强关联性。IICSP根据播音员语音内容情节上下文的连贯性,精心设计了对固定间隔切分视频段,按照语音语义进行合并的算法;并设计了计算复杂度非常低的视频场景检测方法;采用了保证主客观质量的视频切分方法。上述方法确保自动产生的新媒体视频在语义上具有连贯性、准确性和完整性,在结构上保证了音视频文件同步且完整。
IICSP采用的电视新闻场景切分方法流程见图2。新闻节目切分包括5个关键的部分:1)播音员声纹识别模块;2)基于播音员语音情节单元的视频段合并模块;3)语音情节单元边界检测模块;4)视频场景检测模块;5)文件切分模块。
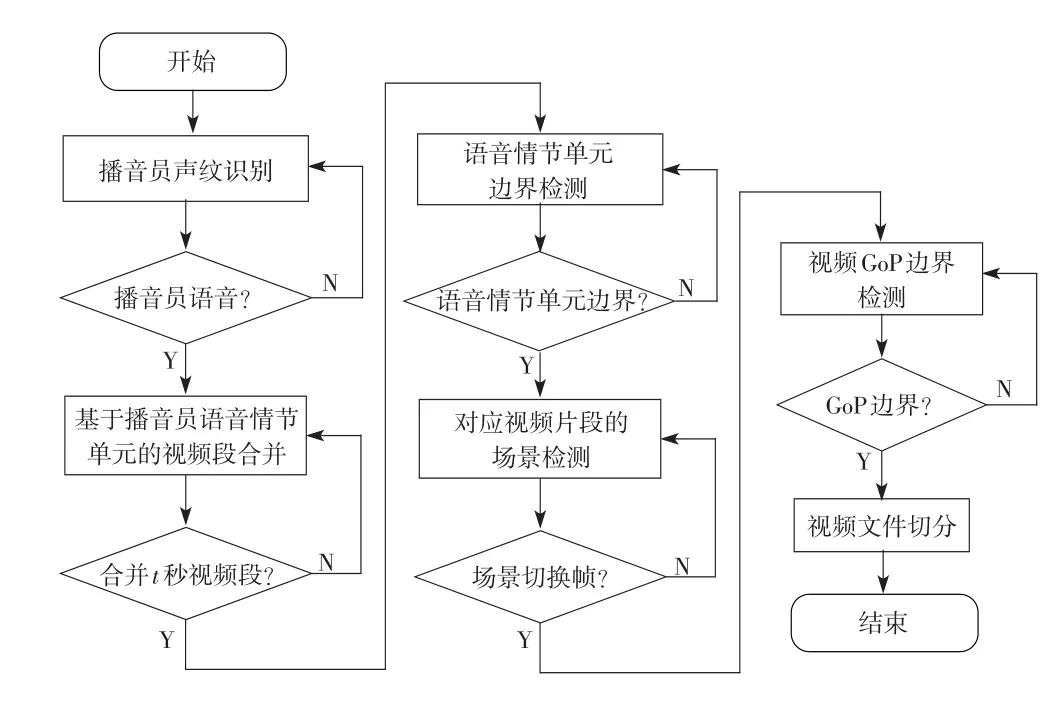
图2 电视新闻场景切分流程图
2.1 播音员声纹识别
在语音识别中,只有对新闻播音员进行标准语音识别才能获得95%以上的准确率。因此采用该模块来鉴别获得播音员的语音文件,以便后续处理。声纹识别技术目前已经非常成熟,本文采用文献[3]提出的方法进行处理。
2.2 基于播音员语音情节单元的视频段合并算法
总体设计思想是把待处理的语音文件分成等间隔的小段,根据语音段频繁出现的热词来判断相邻语音小段内容的相似性,把内容相似的小段合并为一个情节单元(CU)。定义语音的情节单元为一段内容上下文关联度很强的音视频片段。而对于非播音员的语音片段,自动划归为前一段播音员语音的CU。
1)播音员语音小段划分
设Vi代表第i个t秒间隔的采样语音段,其中i=1,2,…,n;其中t的初始值为对样本新闻视频播音员说一句话持续时间长短统计学习得到的样本均值,一般不超过10 s,并根据实际的处理视频自适应地调整t值,对于不足t秒的播音员语音,按照实际时间处理。
2)合并算法
通过对新闻内容的分析可知,一段主题新闻内容播音员都会反复提到人名、事件名、地名、时间等所谓的热词。把这类词定义为关键词,关键词数据结构如下:

上面结构体中的变量含义为:①按人、事件、物、地点、时间等设置枚举变量,设系统初始的总类数为C;②保存关键词的名称;③用(j)代表第i段语音中、第v类、第j个关键词经过统计出现的频度数量,其中变量v 基于上段所述的准则,可以认为前后两段音频内容的重点一致。接下来,进行最终的语音小段合并准则判定其中,用关键词类的权重与关键词出现频率的乘积作为最终判定分段内容相似性的参数。而TH为经验阈值,一般根据分类样本进行统计,初始值设为样本均值,并可自适应进行调整。 2.3 情节单元边界检测算法 为了确定两段内容独立的语音情节单元的精确切分点,在前后两小段t秒的语音段不能合并的情况下,记录后t秒各类经过排序的前Δ个关键词与前t秒对应各类关键词的补集内(即后t秒中新出现的关键词集合)的关键词名称。依次选取补集中频率最高的各类关键词的名称,在前后2t秒的语音中寻找该关键词第一次出现的时间点,确定2t秒内最前面的时间点为语音情节单元边界,以便在该语音对应的视频图像组(GoP)邻域内找到精确的文件切分点。 2.4 视频场景检测算法 在确定了语音情节单元边界对应的视频帧后,在该帧所在GoP和前后2个相邻的GoP内进行码流分析,获得宏块序号、DC系数、运动矢量残差值和帧内编码宏块数量等关键数据。该视频突变场景检测方法计算复杂度非常低,仅读取2.5 s左右时间内的60帧视频码流,进行比特级的解码即可。而对于视频渐变场景则采用语音关键词进行切分。 1)播音员头肩像关键帧检测 对于新闻类节目,具有播音员头肩像的视频帧是辅助进行场景划分的重要依据。采用有监督机器学习的方式,选取各个电视台新闻播音员各种播报场景帧作为样本,提取具有播音员头肩像的关键帧的宏块/块的序号和DC分量数值,进行统计,获取样本均值和方差等数字特征,形成样本特征库。在实际检测中采用最小二乘法与样本特征库内的特征数据进行比对,只要波动不超过样本方差,即可判断当前帧是播音员头肩像。 2)运动复杂度分析 在GoP邻域内,设RF为参考帧,CF为当前帧,Σmv为累加的CF解码宏块/块的解码运动矢量差值之和,如果Σmv 3)帧内宏块数统计 在GoP邻域内,设NαIntraMB代表第α帧的帧内编码宏块数量,α为视频帧的序号。设ThNumIntraMB为通过对样本分析获取的视频预测帧(P、B帧)帧内宏块的数量阈值,一般取样本均值。如果NαIntraMB≫Nα-1IntraMB,即后一预测帧的帧内编码宏块数突然成倍增加,则认为前后预测帧纹理差异较大或运动特别剧烈,存在场景切换的可能。 如果在GoP邻域内检测到播音员头肩像的关键帧,且连续GoP场景平滑,则可以判定当前场景是播音员头肩像场景,该场景的第一个GoP可以作为切分前后新闻内容短视频的备选断点。 对于两段新闻片段之间没有播报场景视频帧的情况,采用视频场景突变检测方法:如果前后预测帧运动剧烈变化,或帧内编码宏块剧烈上升,则当前GoP可以作为切分前后新闻内容短视频的备选断点。 2.5 文件切分算法 GoP从I帧开始。当检测到帧类型是I帧后,则确定为GoP边界。切分文件的原则是保持播音员语音的完整性且保持音视频同步。对于播音员语音从I帧开始且为开环GoP的情况,需要去掉I帧后面紧接着的两个B帧的前向参考然后切分,以便在解码时能正确重建。而对于闭环GoP,则无需处理,直接切分。如果播音员语音开始的时间点对应的视频帧非I帧,分为以下两种情况进行处理。 对于P帧:解码该P帧,并重新编码为全帧内宏块P帧,丢弃当前GoP中显示时间在该P帧前面的视频帧对应的码流,后面其他帧码流无变化。 对于B帧:确定其后向参考帧,如果是I帧不处理,是P帧则解码重建,并重新编码为全帧内宏块P帧。解码该B帧,再编码为全帧内宏块P帧,丢弃当前GoP中显示时间在该B帧前面的视频帧对应的码流,而对显示时间在该B帧后面的B帧,进行解码重建,并重新编码为全帧内宏块P帧。 IICSP基于云计算Map-Reduce架构并行对大数据电视新闻内容进行高效且精确地主题划分、打标签、建立索引。采用了新颖的视频场景切分算法,获得准确完整的新媒体短视频。运营商搭建IICSP后,可提供一系列智能、交互、时尚的新媒体内容服务,使其拥有的海量电视内容迅速增值。IICSP较现有的其他同类平台,具有处理效率高且更准确的优点,节省了劳动力,提高了性价比。 [1] Apache Hadoop[EB/OL].[2013-08-25].http://hadoop.apache.org/. [2]王硕,刘文.并行化语音识别系统的研究与设计[J].计算机工程和应用,2012,48(11):71-74. [3] TAN L,WEIG.Blind signal separation of convolution mixture sig⁃nals via minimum mutual information(MMI)method[J].Journal of China Institute of Communications,1999,20(10):49-55. TN949.6 B �� 雯 2013-11-22 【本文献信息】崔玉斌,宿玉文,宋征.基于Map-Reduce的电视新闻场景切分方法[J].电视技术,2014,38(6). 国家国际科技合作专项(2012DFG11800) 崔玉斌(1979—),高级工程师,主研多媒体通信、视频内容分析、语音识别、云计算等; 宿玉文(1973—),高级工程师,主研数字电视传输、媒体内容保护和增值业务技术等; 宋 征(1975—),高级工程师,主要研究方向三网融合、物联网、云计算等。
3 小结
