用于热门路径查询的动态热度路网的构建方法
2014-07-02陈依娇杨恺希
陈依娇,杨恺希
用于热门路径查询的动态热度路网的构建方法
陈依娇,杨恺希
基于位置的服务在蓬勃发展的同时,产生出大量的用户位置轨迹数据,同时基于轨迹数据的热门路径问题也越来越受到人们的重视。对于求解点到点热门路径的问题,一张带有动态热度信息的热度路网是非常必要的。首先,提出了一个高效的交叉口生成算法,用于构建静态的热度路网,并在此基础上提出一种新的时间段分割算法来使得路网中对应热度边动态化。采用希腊雅典的一部分卡车的GPS轨迹数据集,通过大量充分的实验,印证了算法的合理性和高效性。
空间数据库;轨迹数据挖掘;热门路径;随时间动态变化
0 引言
随着移动设备定位功能广泛普及和基于位置的服务的蓬勃发展,用户位置轨迹数据大量产生并被用在越来越多的研究领域中。为方便人们出行,热门路径提供了一种实用而新颖的路线参考,它从人们的位置轨迹数据中发现出行规律,从而帮助其他人找寻合适的路径。
关于利用轨迹进行热门路径的研究,从路径类型上可分为两类:第一类是点到点的热门路径问题。该类问题最先由Chen[1]提出,同时假定没有地图路网数据。它采用类似密度聚类的方法聚类出路口,使用马尔可夫模型计算路口之间的转移概率,再根据出发点和目的地点求得一条最热的路径。它的缺点在于忽略了热度路网的动态变化特性。RICK[2]是给出定点序列获取连续通过其的热门路径方法,该方法能够通过轨迹集构造可路由的路网并且在之上进行路径规划,这种方法对于低采样率下的轨迹数据和无路网信息背景较为有效。TDHP[3]给出了解决给定两点、出发时间和通过时间限制的动态热门路径问题的方法。
另一类是热门路段问题,如Li[4]等人提出了路网下基于交通密度的热门路径方法 FlowScan。该方法利用边和边序列上的交通密度抽取热门路径,并假设两条位置相近的边会共享比较大的交通量,从而可能成为同一个热门路径的一部分。Sacharidis[5]等人提出了一种在线获取距离查询点较近的热门路径的方法。该方法着重考察在最近一段时间内的运动模式,并通过滑动时间窗口放弃过时的轨迹数据,另外还考虑了轨迹数据采集到的不确定性,提高结果的精确度。
另外,关于热门路径特点的分析也有一些成果。其中Guo[6]对轨迹数据进行了分析,其实验结果体现出空间中轨迹点的密度随时间产生了大幅变化。Li[7]的工作也能反映出热度分布的动态特性。Ding[8]挖掘出在特定的一段时间内拥有相同移动路线的对象,并且发现他们有着周期性的移动规律。关于如何更好地表现和利用这种动态特性,文献[9-11]采用每隔一段时间对轨迹点进行一次聚类,进而将GPS序列转化为时间顺序的簇序列。
本文针对点到点热门路径查询同时没有路网背景数据存在的情况,构建出一张带有动态热度信息的路网,以便进行热门路径查询工作。其一,在很多情况下,路网信息并不存在,例如在一些自然环境如森林和沙漠中。当人们进行户外活动如登山、徒步或划船时,前人常走的路线往往包含着重要的参考信息。其二,路网的热度信息需要符合动态性的变化规律。例如,初到一个城市的游客打算开车过程中欣赏道路两旁的风光,白天阳光充足,拥有自然风光的道路成为首选,夜晚繁华街区的道路更佳。如果将所有游客的移动历史轨迹进行收集并分析,会发现道路的热度会有不同变化。最后,构建热度路网并非是通常的构建路网和将热度动态化的简单累加,出于热门路径问题本身的特点,本文在构建热度路网时更加重视那些热度高的道路的生成而非所有道路的生成。
本文提出了一种用于热门路径查询的动态热度路网(记为GT)构建方法。
1 系统框架
本文系统包括轨迹数据预处理、静态热度路网构建和热度路网动态化三部分。矩形内部展示了具体的系统框架如图1所示:
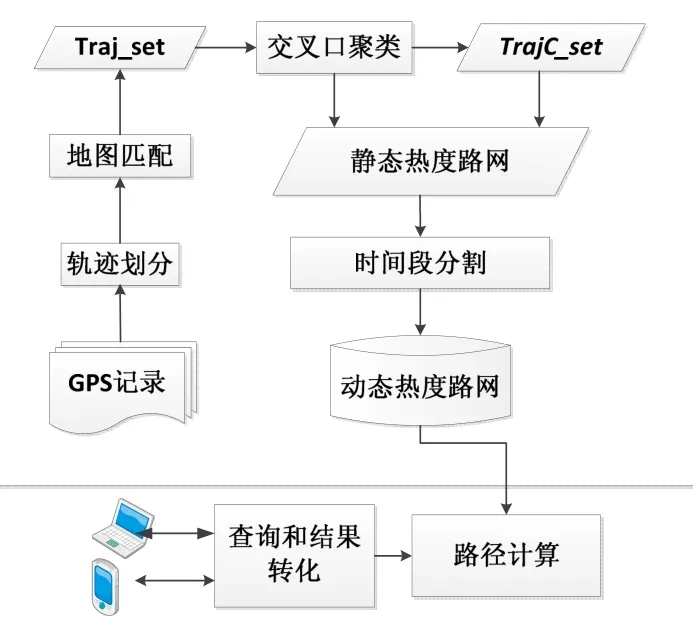
图1 系统框架
首先,利用位置点的采集时间和车辆id,划分原始记录为单独的轨迹以表示一次时间和位置都连续的移动行为,然后,对轨迹插值,以减小低采样率带来的误差。其次,以Traj_set为基础生成交叉口,并通过统计学的方法构建GS。再次,通过时间段分割方法,利用时间段热度的不同来模拟实际热度的变化,最终构建出GT。从用户的角度出发,其向服务器发出请求,服务器应答并在线计算热门路径,最后将结果返回。
受轨迹数据集限制,热度路网可能在精度和完整性方面逊于真实地图路网,但能够很好地抽取出主要路段的热度信息,而冷僻的区域会被简化甚至过滤掉,这种做法恰恰提高了查询热门路径的准确度和效率。
2 问题的定义
定义1. 点p表示移动对象出现的地理位置,由三元组(lon,lat,t)构成,其中lon和lat分别为经度和纬度,t为采集时间。
定义2. 轨迹Traj表示一次时间和位置都连续的移动行为,由一组时间连续的点构成Traj:
定义 3. 交叉口 I(P,center)表示地理上的一个小型的复杂的区域,移动对象从各个方向进入后离开。其中P是一组经过I的轨迹点,同时center为P中点的中心位置。
定义4. 热度边ei,j(len,h)是介于两个交叉口Ii和Ij.间的一条路段,其中ei,j.len代表ei,j的长度,ei,j.h代表ei,j的热度。由于热度的动态特性,ei,j.h是时间的函数 ei,j.h(t)
定义 5. 动态热度路网是一个有向图 GT(V,E)(简称为GT):V={Ii}是一组交叉口的集合;E⊆ V×V是一组热度边的集合。
问题定义给定一个轨迹数据集,以构建一个带有动态热度信息的路网GT。
3 方法介绍

3.1 构建静态热度网络
通过轨迹数据还原路网地图的研究工作已有很多,也有人开展过在无地图路网背景下生成交叉口的研究。Fathi[12]利用分类的方法生成交叉口,但是需要准确的训练数据。在文献[1]中提出一种 CohExpanding算法,聚类得到交叉口,实验表明他们的方法准确度非常高。不过CohExpanding在运行效率上并不令人十分满意,本文在其基础上提出一种改进算法 PartExpanding,在基本不影响准确度的前提下,大幅缩短了运行时间。
3.1.1 CohExpanding[1]算法简介
CohExpanding算法利用了交叉口点密度和方向夹角两特点。交叉口处减速慢行,轨迹点的密度会比其他区域高,而交叉口处两点方向夹角接近π/2(同一条道路上移动时两点方向的夹角接近于0或π)。算法提出点间相关度的概念:点p和q的相关度定义为:两点欧式距离,β为两点移动方向的夹角。一般认为,两点距离越小,运动方向越接近垂直,p和q的相关度越大,当相关度超过一定值时,则称p和q相关。
CohExpanding的思路类似于DBSCAN算法[13]。每次从轨迹数据集中任取一个不属于任何交叉口的点p,对p调用expand算法:从p开始不断向周围扩展相关点直到再也找不到任何相关点为止。如图2所示:

图2 对p点进行expand
以p为圆心、以R为半径划定寻找相关点的圆,由于圆内p1,p2两点都与p相关,则由p扩展到p1和p2。从p1出发扩展到p3,而p3找不到与它相关的点使得扩展停止,接着从p2出发扩展到p4,同样p4找不到相关的点,扩展停止,此时expand停止并返回点簇P={p,p1,p2,p3,p4}。若|P|≥φ(φ是人为设定的),则得到一个交叉口I(P,center)。
3.1.2 PartExpanding算法的提出
CohExpanding准确度较高,但时间耗费大,处理一个包含50辆车总共26万个点大小的数据集,该算法耗时超过20分钟,而实际情况处理的数据量会大很多倍。进一步分析发现,CohExpanding会在非交叉口的区域进行大量无用计算。
如图3所示:

图3 expand的两种情况
假定图中所有点实际落在道路(非交叉口)上,同时所有点之间都不相关。在对p点执行完expand操作后,需要分别对p1,p2和p3执行相同的操作,即使这4个点所处的区域显然不是交叉口。同时,由常理可知,落在道路上的点的数量要远大于落在交叉口区域的数量,这意味着无用的expand操作耗费了总时间的一大部分。针对这一缺陷,最简单的改进是不对p圆内点进行扩展,但是这有可能使本应落入交叉口中的点没有落入交叉口如图3(b)所示,假定q点附近实际有一交叉口,p1,p2和 p3被标记,当对 q调用expand时,p1点再次落入圆内,虽然p1与q相关,但是,p1不会被扩展,expand返回点簇P,假如恰好有那么q点处的交叉口就可能没有被找到。
记所有与p相关的点为集合P,总的来讲,若P中的点离p点越远,就越有可能由非交叉口进入交叉口,就越需要对它执行expand操作,否则其所处的位置还是更有可能属于非交叉处。综合考虑两方因素,我们提出一种新的方法PartExpanding将P划为稳定区域和不稳定区域,并规定在稳定区域中的点不需要 expand而不稳定区域中的点需要expand。具体划分如下:我们将P中的点按照其与P的欧式距离由小到大排序,如图4所示:

图4 用γ进行区域划分
3.1.3 边静态热度的计算
在得到了全部的交叉口之后利用统计数构建静态热度路网。表1中是下面会用到的符号的说明如表1所示:

表 1 符号表
3.2 热度路网动态化——时间段分割
本节介绍一种将热度路网动态化的时间段分割算法TSPartition,首先给出时间段分割的定义。
定义6.时间段分割,就是对eij,将一天中的时间分割为若干连续的时间段
Chen[3]中提出了一种时间段分割算法TimeParti,本文借鉴了其方法,并做了两点改进。第一,每条热度边分割后得到的时间段不应过多。时间段过多,不仅会带来较高的存储代价,同时会给热门路径查询带来很多时间上的消耗。TimeParti算法中只对聚类结果的聚合性进行了考察,缺乏对生成结果的数量的限制。TSPartition算法引入 vtsBound(算法1,第5行),对时间段数量进行有效地限制。第二,TimeParti算法得到的热度函数在时间上是非连续的,对于没有落在时间段内的时间,其热度值永远为 0。TSPartition将得到的时间段进行首尾拼接,并进行平滑处理,使得结果更加符合实际。

算法1: TimeParti输入:eij.tSeq输出:eij.vts1 ts0.creat(eij.tSeq); 2 vts.push(ts0); 3 Whiletruedo 4 max vts中SSE最大的vts[i]; 5 If(max.SSE SSEbound||vts.size vtsBound)←≤≥

6 Break; 7 vts.delete(max); 8 //采用不同的初始质心进行n次K-means试验,每次试验返回一对候选的时间段9 For i=0 to n-1 do 10 C1=max.FT+(max.center-max.FT)*i/n; 11 C2=max.LT-(max.LT-max.center)*i/n; 12 (tp1,tp2) ←K-means(C1,C2,max); 13 (ts1,ts2) ←使得SSE和最大的一对tp1和tp2; 14 vts.push(ts1);vts.push(ts2); 15 拼接时间段; 16 Returnvts;
4 实验与分析
实验分别考察构建热度路网和时间段分割的算法性能。将PartExpanding和原有算法CohExpanding进行对比,从生成交叉口的数量和运行时间两方面衡量PartExpanding的性能。其次,采用K-means作为TSPartition的对比算法,观察两者在时间段分割质量和速度上的差异。
4.1 数据集与预处理
实验环境.所有算法使用Visual C++语言实现,实验环境为AMD Athlon™ 2 X4 610e Processor 2.40 GHz,2.00 GB内存,500 GB硬盘和Windows 8操作系统。
实验数据.实验采用与对比算法CohExpanding相同的数据集,即希腊雅典卡车的GPS轨迹数据。原始轨迹记录共112203个轨迹点,平均采样间隔30s,经过轨迹分段和插值等预处理,新的用于实验的数据集Traj_set包含3943条轨迹共263386个轨迹点,平均采样间隔10秒,轨迹平均点距不超过100米。
4.2 实验结果
由于稳定阈值γ的大小可能对算法的效果有直接影响,所以本节首先考察算法随γ增大的性能情况,挑选出最佳γ值作为PartExpanding的参数。然后对两个算法的结果进行对比分析如图5所示:


图5 稳定阈值γ对热度路网的影响
γ=0时算法退化为CohExpanding。图5(a)中当γ上升到0.4到0.6时,交叉口数量只比γ=0时下降了不到10%,这说明PartExpanding确实只遗漏了很小一部分交叉点。图5(b)中,当γ上升到 1,运行时间接近于零分钟。这源于一旦一个点不需要扩展,那么会引发该点后面多个点不必扩展的连锁反应。总之,认为当,既可以得到较高质量的交叉口,也能保证运行时间较短。下面的实验中都设γ=6。
接着可视化算法结果以验证算法的质量。如图6所示:

图6 PartExpanding结果显示
我们调用API接口将通过PartExpanding构建的热度路网投影在Google地图上,结果表明其与CohExpanding的路网构建结果基本一致,热度路网和真实路网的整体形态高度吻合,仔细观察发现交叉口的位置基本落在地图上真实的路口上,或者紧挨真实路口。不过从图6中看出,仍有局部区域的边较为冗余(如矩形内),这是由于该区域内轨迹点密度过大,导致很容易满足边生成的条件如图7所示:

图7 两种交叉口生成算法的比较
图7考察了两种算法的效率。随着轨迹点数量增多,PartExpanding的运行时间和网格索引访问的点的数量呈缓慢线性增长如图7(a)所示,而CohExpanding表现逊色很多如图7(b)所示
4.3 TSPartition算法性能分析
本节从时间段分割的质量和速度上衡量TSPartition算法如图8所示:

图8 两种时间段分割算法的性能比较
图8(a)中纵坐标为平均一条边的SSE,SSE越大说明分割结果质量越差。由图8可以看出TSPartition的分割质量明显优于K-means。这是因为K-means不能在簇对之间重新分布质心,这样只能得到局部最优,而 TSPartition由于多次指派不同的初始质心,使得其不太受初始化问题的影响。图8(b)反映出TSPartition时间消耗要高于K-means,这是因为它需要多次调用K-means。
5 总结
本文提出了一种用于热门路径查询的动态热度路网构建方法。它首先利用密度聚类,提出PartExpanding算法从轨迹数据中抽取出交叉口进而生成热度边,并通过统计学方法得到对应每条热度边的静态热度信息,构建出一张静态热度路网。然后,在将边热度动态化的过程中,又提出了一种新的时间段分割方法 TSPartition,对已有工作进行了改进。本文以希腊卡车GPS轨迹为实验数据,通过大量实验和可视化结果证明了提出的方法的有效性和高效性。
[1] Chen Z, Shen H T, Zhou X. Discovering popular routes from Trajectories[C]//Data Engineering (ICDE), 2011 IEEE 27th International Conference on. IEEE, 2011: 900-911.
[2] Wei L Y, Zheng Y, Peng W C. Constructing popular routes from uncertain trajectories[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2012: 195-203.
[3] Chen Y J, Yang KX, Hu H, et al. Finding Time-Dependent Hot Path from GPS Trajectories[C].//WAIM, 2014, accepted paper.
[4] Li X, Han J, Lee J G, et al. Traffic density-based discovery of hot routes in road networks[M]//Advances in Spatial and Temporal Databases. Springer Berlin Heidelberg, 2007: 441-459..
[5] Sacharidis D, Patroumpas K, Terrovitis M, et al. On-line discovery of hot motion paths[C]//Proceedings of the 11th international conference on Extending database technology: Advances in database technology. ACM, 2008: 392-403.
[6] Guo D, Liu S, Jin H. A graph-based approach to vehicle trajectory analysis[J]. Journal of Location Based Services, 2010, 4(3-4): 183-199.
[7] Li Q, Zeng Z, Zhang T, et al. Path-finding through flexible hierarchical road networks: An experiential approach using taxi trajectory data[J]. International Journal of Applied Earth Observation and Geoinformation, 2011, 13(1): 110-119.
[8] Li Z, Ding B, Han J, et al. Mining periodic behaviors for moving objects[C]//Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010: 1099-1108.
[9] Kalnis P, Mamoulis N, Bakiras S. On discovering moving clusters in spatio-temporal data[M]//Advances in spatial and temporal databases. Springer Berlin Heidelberg, 2005: 364-381.
[10] Fosca Giannotti, Mirco Nanni, Fabio Pinelli, Dino Pedreschi.[C]Trajectory pattern mining. InKDD, pages 330-339, 2007.
[11] Jeung H, Yiu M L, Zhou X, et al. Discovery of convoys in trajectory databases[J]. Proceedings of the VLDB Endowment, 2008, 1(1): 1068-1080.
[12] Fathi A, Krumm J. Detecting road intersections from gps traces[M]//Geographic Information Science. Springer Berlin Heidelberg, 2010: 56-69.
[13] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//KDD. 1996, 96: 226-231.
Constructing Time-Dependent Hotness Road Network for Hot Path Query
Chen Yijiao, Yang Kaixi
(School of Computer Science and Technology, Fudan University, Shanghai 201203, China)
With the booming development of LBS, a huge number of users’ location trajectory data are produced and hot path problems based on trajectories are paid more and more attention. For the end-to-end hot path problem, a hotness road network with time-dependent hotness information is essential. In this paper, we first employ an efficient algorithm to generate intersections to construct a static hotness road network, then do time slot partition to make it time-dependent. The dataset is truck trajectories in Athens, Greece. Extensive experiments show that our algorithms outperform the baseline approaches in terms of both effectiveness and efficiency.
Spatial DataBase; Trajectory; Data Mining; Hot Pathtime-Dependence
TP311
A
1007-757X(2014)06-0038-05
2014.04.17)
陈依娇(1989-),女,复旦大学,硕士研究生,研究方向:空间数据库和轨迹数据挖掘,上海,201203
杨恺希(1991-),男,复旦大学,硕士研究生,研究方向:空间数据库和轨迹数据挖掘,上海,201203
