基于KIM算法和Adaboost级联的快速人脸检测
2014-06-13王自伟盛惠兴
王自伟,盛惠兴,2
(1.河海大学物联网工程学院,常州213022;
2.常州市传感网与环境感知重点实验室,常州213022)
1 引言
人脸是一个常见而复杂的视觉模式,人脸所反应的视觉信息在人与人的交流和交往中有着重要的作用和意义,对人脸进行处理和分析在视觉监控、公共安全、视频会议以及人机交互等领域都有着广泛的应用前景。人脸检测是指对任意给定的一幅图像或者一段视频采用一定的方法和策略对其进行搜索以确定其是否含有人脸以及所有人脸在图像中出现的位置[1]。近年来基于图像的方法为主要研究热点。这类方法主要有基于线性子空间的方法,基于神经网络的方法,基于SVM的方法,基于Adaboost的方法等。其中,Adaboost算法[2]和其他方法相比,其检测效果和稳定性都较好,被广泛用于人脸检测中。而在视频图像中,运动目标检测是计算机视觉领域的一个重要研究课题。预先对运动物体进行检测,然后在提取的运动区域上进行Adaboost人脸检测算法,可以很大程度上缩短人脸检测的时间。
因此将KIM算法[3]和Adaboost人脸检测方法相结合,提出了一种快速的人脸检测算法,该算法对于人脸检测具有较好的准确性和实时性。
2 运动区域的提取
常用的运动区域检测方法主要有光流法、帧间差分法和背景减法等[4-5]。
光流法是采用运动目标随时间变化的光流特性,有效地实现运动目标的检测与跟踪。该类检测方法可以适用于摄像机静止和运动两种场合。但是多数光流场计算方法相当复杂,且容易受到噪声影响,因此应用性和实时性较差。帧间差分法是通过对相邻的两帧做减法,阈值化后得到运动目标的区域。该方法简单快速,实时性好,并且对动态环境具有较好的适应性。但该方法对噪声十分敏感,而且提取的运动区域容易产生空洞现象,不能有效地提取完整目标。背景减法是利用当前帧图像与背景图像相减得出运动区域,当背景稳定的情况下,可以完整的检测出前景运动目标。而当光照突变时,容易产生将背景像素误判为前景目标的现象,引起较大的检测误差。因此该方法对于背景建模和背景更新要求较高,而且对于与背景灰度相近的目标不能够完全检测出来。
此次采用的KIM算法是将三帧差法和背景减法相结合来有效提取运动区域。这种方法既能克服背景差法易受外界环境的影响,还能够避免帧差法中运动目标重叠而检测不出来的现象,因此可以得到更加全面的运动区域。KIM算法原理框图如图1所示。

图1 KIM算法流程图
2.1 三帧差法
设 It-1、It、It+1为视频的连续 3 帧图像,利用帧间差分法原理,首先计算It-1和It的差值以及It和It+1的差值,然后通过阈值化分割得到二值图像,并将结果进行与运算,得到其共同部分,从而有效去除帧差法的“双影”效果。
因此在三帧差法中使用一种改进的自适应阈值选择方法,利用帧差图像的结果,即运动像素的均值作为阈值,然后对帧差结果进行二值化处理,公式描述如下:

其中,d(i,j)表示图像中点(i,j)的灰度值,n 为图像中像素不为0的点的个数,M,N分别为图像的高度和宽度,如果d(i,j)≥Tth,则改点为运动点。
由图2的实验结果可知,该方法得到的运动区域检测效果比采用固定阈值和OTSU法(大津法)即最大类间方差法得到的结果要好的多。手动设定阈值和OTSU法得到的二值图像明显缺失了大部分运动区域,而自适应均值法则能很好的提取出运动区域部分。
但是在视频图像中无运动目标时,轻微的环境变化会使检测的噪声很大,此次是通过设定阈值下限来改善无运动目标时噪声很大的情况。当得到差值图像Dt(x,y)时,先求得其像素的最大与最小值的差值 Xt,若 Xt<T,则令差分图像 Dt(x,y)=0,若Xt≥T,则通过上述的自适应阈值方法得到二值图像,此处使T=40。

图2 三种阈值分割方法的结果图
2.2 背景减法
背景减法一般有统计中值法、卡尔曼滤波法、高斯模型法、Surendra法等。考虑到实时性因素,这次是使用均值法进行初始背景计算,然后利用Surendra算法[6]进行背景更新和背景建模。首先利用连续的N帧视频图像取像素平均值建立初始背景B(x,y),公式描述如下:

然后将初始背景与当前帧进行差值计算,并设置阈值T,若差值小于阈值时,对当前帧进行累加求和并使计数器加一,若差值大于阈值则忽略不计。如此反复进行下一帧与初始背景的差值计算。累加到一定帧数后对累加的和进行均值计算,得到背景,如果累加和为零,则用初始背景的像素点作为新的背景。
获取背景图像后,将当前帧与背景图像做差值运算,得到的就是运动区域,即前景图像。然后通过阈值化分割得到二值化图像,阈值通过上述的自适应阈值法求得。
由于光照等外界环境的影响,背景在不断的变化,因此需要建立背景更新模型来降低背景减法所带来的检测误差。这次利用阈值分割的二值化结果TBt(x,y)使用了一种自适应背景更新模型。公式描 述如下:

其中,Bt+1(x,y)和 Bt(x,y)分别为输入第 t+1帧、第t帧图像后得到的背景,It+1(x,y)为输入的第t+1帧图像,TBt(x,y)=1 表示点(x,y)被判定为运动点,背景像素不变,TBt(x,y)=0 表示点(x,y)被判定为背景点,利用当前帧进行背景更新。α为背景模型学习速率。α值太小,则背景更新很慢,不能很好地体现出视频图像的变化,会降低对运动目标检测的正确率;而α值太大,则背景更新很快,容易产生虚假检测。因此,α的取值不能太大或者太小,经验值在0.05 到0.1 之间,取 α =0.05。
2.3 运动区域融合
将三帧差法和背景减法阈值化后得到的二值图像进行或运算,得到初步的运动区域,由于检测图像中会存在一些散点和噪声,因此对结果图像进行形态学处理来消除这些影响,一般的形态学处理有腐蚀、膨胀、开运算和闭运算。
3 基于Adaboost的人脸检测
2001年,Viola和 Jones[7]提出了积分图像的概念和基于Adaboost方法训练人脸检测分类器的方法,建立了第一个真正实时的人脸检测系统。其基本思想是在给定的训练集上反复训练,挑选出关键的分类特征(弱分类器),然后把这些在训练集上得到的弱分类器线性组合起来构成一个最终的强分类器。
此次的人脸检测方法主要是基于类Haar特征的积分图运算、Adaboost算法和级联分类器相结合的方法。人脸检测原理框图如图3所示。
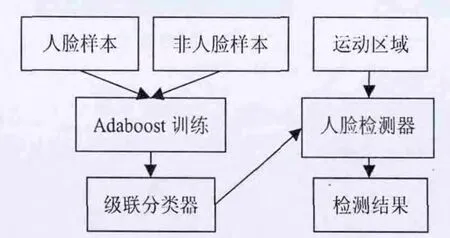
图3 人脸检测流程图
3.1 类Haar特征计算
类Haar特征是一种矩形特征,主要分为三类:边缘特征、线性特征和对角线特征。这些特征模板都是由两个及以上的全等矩形相邻组合而成,特征模板内有黑白两种矩形,并定义模板的特征值为白色矩形内的像素和减去黑色矩形内的像素和。为提高训练与检测的速度,选择了图4中3种类型5种形式的矩形特征。

图4 3种类型的5种矩形特征
利用所得的积分图矩阵可以快速计算矩形特征。矩形特征的特征值计算,只与此特征端点的积分图有关,而与图像坐标值无关。因此,不管矩形特征的尺度如何,特征值的计算所耗费时间均为常量,而且只是简单的加减运算。
3.2 Adaboost算法流程
Adaboost算法是一种迭代算法,它能自适应的调节训练样本权重的大小。起初每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点被准确分类,则在构造下一个训练集中,它被选中的概率降低,反之,则它的权重提高。在每一次迭代训练后,挑选出当前样本权重分布下分类错误率最小的弱分类器作为最佳弱分类器,并通过线性组合将这些最佳弱分类器组成一个强分类器。Adaboost算法具体步骤如下[8]:
(1)给定一系列训练样本 (x1,y1),(x2,y2),...,(xn,yn),其中 yi=1 表示人脸,yi=0 表示非人脸。
(3)迭代T次求取最佳弱分类器,即最佳特征。For t=1,2,...,T
b.对每个特征 f,训练一个弱分类器 h(x,f,p,θ),计算对应所有特征的弱分类器的加权qt的错误率 εf:εf= ∑iqi|h(xi,f,p,θ)- yi|
c.选取最佳弱分类器hi(x),即拥有最小错误率εt:
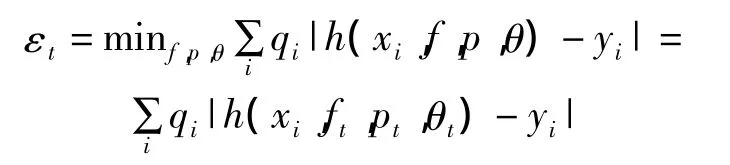
ht(x)=h(x,ft,pt,θt)
其中ei=0表示xi被正确分类,ei=1表示xi被错误分类
(4)最后的强分类器:

3.3 级联分类器结构
多层级联分类器结构的每一层都是由Adaboost算法训练得到的强分类器。级联结构可以快速有效地对输入图像中的非人脸部分进行排除,从而提高人脸检测的速度。在图像检测中,待检测子窗口依次通过每一层分类器,位于前端的强分类器所包含的特征较少,分类速度很快,可以将大部分的非人脸子窗口排除,通过每一层分类器的检测子窗口即为候选的人脸窗口。位于后面几层的强分类器包含的特征数目增多,用来区分那些与人脸类似的负样本。虽然特征数量变多了,但是能够达到这些层的子窗口数已经很少,因此在实际检测时,后面几层的检测也不耗时。这些通过训练得到的每一层分类器,都要满足一定的性能要求,即检测率和虚警率。每一层的检测率和虚警率可以依据整个系统的检测率与虚警率得到,系统的检测率和虚警率分别等于各层的检测率与虚警率的乘积。
4 实验结果
为了验证算法的有效性,使用监控摄像机在实验室中拍摄的视频进行实验,视频单帧图像大小设定为320×240进行算法测试。图5与图6为这次算法对视频中的人脸进行检测的实验结果图。实验结果表明,这种算法在视频图像中基本能够准确、实时的进行人脸检测。

图5 算法的实验过程结果图

图6 视频图像的检测结果
4 结束语
由于高原地区雾天较多,同时由于雾霾天气增加,雾景图像增强技术需求不断增强,因此科研领域产生了很多雾景图像增强新算法,它们各有其优缺点。由于自然图像的复杂性,现存的很多算法不能完全满足需要。因而,雾景图像增强领域必须解决以下几个问题:在图像增强的时候,会出现噪声扩大,细节丢失的现象,这仍是今后需要改进的地方。找到一个算法可以增强雾霾条件下图像是今后研究的重点和难点,也是今后图像去雾研究的发展方向。尽量减少人工干预的成分,使参数获得智能化、自动化。将一些性能好的智能算法、优化算法应用到雾景图像增强方面,以提高雾景图像增强的效率。
[1]刘治群,汪荣贵,杨万挺.一种改进的处理雾天降质图像的增强算法[J].淮北煤炭师范学院学报,2008,4(29):52-56.
[2]周卫星,廖欢.基于高频强调滤波和CLAHE的雾天图像增强方法[J].数字视频,2010(7):38-40.
[3]胡大南,何涛.基于雾天环境下图像增强方法研究[J].科技论坛,2011(2):14 -15.
[4]卫婷婷,纪峰,庞胜军.图像增强算法新进展[J].宁夏师范学院学报(自然科学),2012(12):6-33.
[5]黄黎洪.一种基于单尺度Retinex的雾天降质图像增强新算法[J].应用光学,2010,31(5):728 -733.
[6]ROSENMAN J,ROE C A,CROMATRIE R.Portal film enhancement:technique and clinical utility[J].International Journal of Radiation Oncology,Biology,Physics,1993,25(2):333 -338.
[7]John P.Oakley,Brenda L.Satherley.Improving Image Quality in Poor Visibility Conditions Using a Physical Model for Contrast Degradation[J].IEEE TRANSACTIONSONIMAGEPROCESSING,1998,7(2):167-179.
[8]钱徽,朱淼良.大气退化的自然山体图像复原研究[J].计算机辅助设计与图形学学报,2002,14(6):526-529.
[9]刘锦锋,黄峰.天气影响的场景影像复原方法[J].光电工程,2005,32(1):71 -73.
[10]葛君伟,谢祥华,方义秋.雾天图像清晰化方法及应用[J].重庆邮电大学学报(自然科学版),2010,22(2):223-226.
[11]汪荣贵,杨万挺,方帅.基于小波域信息融合的MSR改进算法[J].中国图象图形学报,2010,15(7):1901-1908.
[12]董慧颖,方帅,王欣威.基于物理模型的恶化天气下的图像复原方法及应用[J].东北大学学报(自然科学版),2005,26(3):217 -219.
[13]许志远.雾天降质图像增强方法研究及DSP实现[D].大连:大连海事大学博士论文,2010.
[13]胡学友.雾天降质图像的增强复原算法研究[D].合肥:安徽大学硕士论文,2011.
