适应用户兴趣变化的社会化标签推荐算法研究
2014-06-07张艳梅
张艳梅,王 璐
(中央财经大学信息学院,北京100081)
适应用户兴趣变化的社会化标签推荐算法研究
张艳梅,王 璐
(中央财经大学信息学院,北京100081)
目前许多基于社会化标签的推荐均忽视用户的兴趣变化及反复性,影响了推荐质量。针对该问题,提出一种将指数遗忘权重和时间窗口相结合的算法,既突出了近期兴趣的重要性,又强调了反复出现的早期数据。建立基准标签集,根据指数偏移后的标签向量选出目标用户的最近邻居,通过目标用户时间窗内标记的资源计算其所有资源的推荐权重向量,结合推荐权重和资源相似度给出最近邻居标记资源的推荐分数,取分数最高的前K个资源做出推荐。仿真实验结果表明,改进后的算法能动态地跟踪、学习用户的兴趣变化,提高推荐精度。
协同过滤;标签;兴趣变化;指数遗忘;时间窗;推荐
1 概述
近年来,互联网规模及Web2.0迅速发展,大量有用信息和垃圾数据充斥着网络,面对信息过载问题,信息检索领域迫切需要个性化推荐服务为用户提供有价值信息,完善用户体验,使用户由被动的信息浏览者转变为主动的参与者。当前主流的推荐方法包括协同过滤推荐[1]、基于内容推荐[2]、基于图结构的推荐[3]、混合推荐[4]等。其中,协同过滤技术是实际应用中使用最广泛的推荐技术[5]。联系用户和资源,标签就是其中一种,它既能表现用户的兴趣取向,同时还能体现资源的属性特征。文献[6-7]的研究显示标签可以准确显示用户对网页内容的判断,同时标签也是描述资源的一种好方法。目前,社会化标签系统越来越流行,比如 MovieLens,Flickr, del.icio.us,Citeulike,国内的豆瓣网站等。
标签反映了用户对物品的看法,是一种重要的用户行为,也是反映用户兴趣的数据来源。处理用户兴趣变化的方法主要有2种:时间窗口法和遗忘函数法[8],其中时间窗口法利用滑动时间窗反映用户近期兴趣及反复兴趣;遗忘函数法则利用遗忘函数对用户的兴趣权重进行衰减,从而得到真正的兴趣趋势。
文献[9]首先使用线性遗忘函数并引入了渐进遗忘的思想。文献[10]用幂函数曲线跟踪模拟用户兴趣,将基于时间窗与基于资源相似度的数据权重结合起来反映用户的兴趣度,但没有考虑标签这一联系用户和资源的主要因素。文献[11]通过指数遗忘函数衰减用户兴趣模型,以捕获用户兴趣的变化,拟合记忆遗忘机制,但忽视了兴趣的反复性与稳定性,未能准确跟踪用户兴趣变化。针对现有的基于标签协同过滤算法不能快速、准确地反映用户兴趣变化趋势的问题[12],本文在社会化标签推荐的基础上,综合处理用户兴趣变化的2种方法,提出一种适应用户兴趣变化的标签推荐算法(User Interest Change-tagging Collaborative Filtering,UIC-TCF)。
2 UIC-TCF算法描述
UIC-TCF算法大致分为2个阶段:首先根据偏移后的用户标签矩阵选出相似度最高的N个邻居用户,然后将这N个用户标记过的资源与目标用户最近一段时间内标记的资源一一计算相似度,取相似度最高的K个资源推荐给目标用户,两阶段中相似度均通过基准标签集来计算。
2.1 最近邻居选取
给定目标用户u0后,u0使用过的标签集合构成基准标签集T=(t1,t2,…,tn)。使用过基准标签集中至少一个标签ti的用户集合称为候选用户集。用户的标签权重向量中每个标签ti的权重由TF-IDF加权方案得出。一般来说,用户近期标记资源对生成未来可能感兴趣的资源起相对重要的作用,而早期的标记记录对推荐影响相对较小。因此,为拟合人脑的遗忘规律,本文采用指数遗忘曲线以提高近期标记资源的重要性。
定义1(用户标签向量) 设基准标签集T中有n个标签。用户uj的标签权重向量:

定义2(指数偏移权重) 用户uj在标签ti上的偏移权重为:
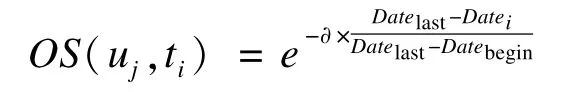
其中,∂为衰减系数,0<∂<1;Datebegin为用户uj开始使用标签系统的时间;Datelast为用户uj最后一次使用标记系统的时间;Datei为用户uj最后一次使用标签ti的时间。
定义3(偏移后的用户标签向量) 偏移后用户uj的标签向量为:
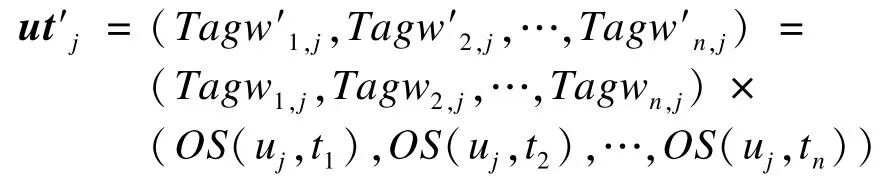
定义4(用户相似度) 目标用户u0与比对用户uj之间的余弦相似度公式为:
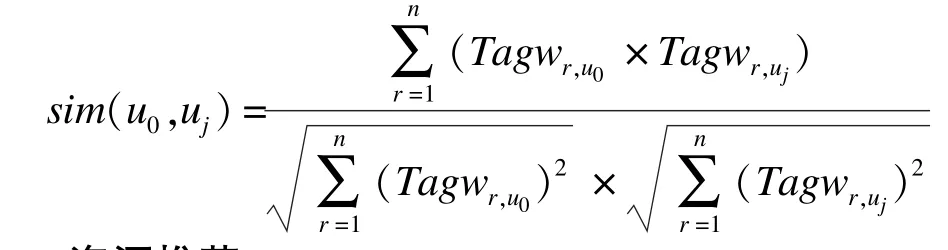
2.2 资源推荐
使用指数衰减后,用户近期标记资源的权重总是大于早期标记记录的权重,从而突出了近期数据的重要性。但一般情况下,不同用户兴趣变化速度和趋势不同。此外,用户兴趣还会经常表现出反复性,所以用户早期的标记数据往往对于生成推荐也很重要,单纯使用指数函数衰减权重,削弱所有早期资源在推荐生成中的作用,可能会降低推荐效果。
设用户u0标记过的资源集合为Iu。设定一个时间窗win,得到目标用户最近一段时间win内标记资源集合Iwin,该集合内的资源一定程度上反映了用户近期的兴趣偏好。无论资源标记时间早晚,只要和Iwin的相似度较高,说明该资源和用户当前的兴趣很相关,即有较高的推荐权重,依次算出Iu中每一资源对u0的推荐权重。在上一步最近邻居用户选定后,获取邻居用户访问资源,构成候选推荐资源集合,结合推荐权重和资源相似度算出推荐分数,给出TOP-K推荐。
定义5(资源的标签向量) 资源Rx的标签权重向量为:

定义6(资源相似度) 资源q与资源k间的余弦相似度为:
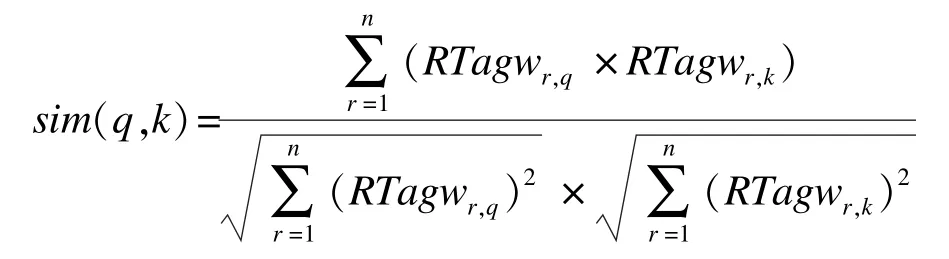


2.3 推荐算法
推荐算法描述如下:
定义8(资源推荐分数) 邻居用户标记过的资源X对目标用户u0的推荐分数为:
输入 用户标记项的矩阵;m:候选用户数;n:社区用户数;win:时间窗;u0:用户
输出 推荐给u0的分数最高的K个资源列表
Step1 标准标签集初始化T=(t1,t2,…,tn);
Step2 为u0创建标签矢量ut0,乘以指数抵消标签矢量,then得到ut′0;
Step3 For j=1 to m-1

Step4 对sim(u0,uj)降序排列,then得到分数最高的N个邻居;
Step5 Iwin=GetLatestItemSet(u0,win); Step6 For q=1 to Length(Itemu0)

Step8 降序排列rec(u0,x),产生推荐给u0的分数最好的K个资源列表。
3 实验结果与分析
3.1 实验环境
本文用Citeulike提供的公开数据集作为实验数据对UIC-TCF算法与传统的基于用户的协同过滤算法(记为CF)作比较。Citeulike是一个专门为学术研究人员提供分享、存储、组织学术文章的社会化书签网站,每条记录包括<用户,论文,标签,时间>4个字段。对获取的数据进行预处理,删除使用用户数量小于20的标签以及使用标签种类小于20的用户,同时由于用户的兴趣在较短的时间内是相对稳定的,兴趣变化只能在一段时间内体现,因此删除那些只在短期内(Datelast-Datebegin<30天)使用过标签系统的用户数据。最终从以上数据集中选取847个用户对3 597个项目的评分记录,以及相应的133个频繁标签。其中,把每个用户最近30%的数据作为测试集,剩下的70%作为训练集。实验运行环境为:Windows XP操作系统,CPU主频2.26 GHz,2 GB内存,Eclipse开发平台,SQL Server 2000数据库。
3.2 评价指标

3.3 实验结果
为了检验UIC-TCF算法效果,将UIC-TCF算法与传统基于用户的协同过滤算法作比较,对比在推荐不同数目时,2种方法准确率的变化情况。设置了3组实验,实验过程中推荐个数由5逐步增长到20,间隔为5。以下所有实验中,最近邻居数目均取为10。
图1显示了衰减系数∂不同取值时UIC-TCF算法与传统协同过滤算法推荐准确率的对比。其中,时间窗win=10,∂分别为0.3,0.5,0.7。
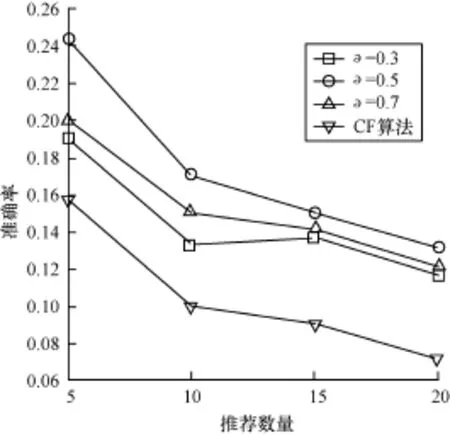
图1 不同∂取值下算法准确率的对比
通过图1可以看出,本文算法明显优于传统协同过滤算法。在准确率指标下,推荐数目越少,本文算法的优势越明显。同时,衰减系数∂的取值对实验结果也有较大影响。由于存在不同种类的标签、资源,同时用户兴趣的变化速度和变化规律也不同,权重增长过快或过慢都会降低推荐精度。在∂=0.5时,算法性能达到最优。如在推荐数目为5,∂=0.5时,推荐准确度提升了约54.8%。同时,随着推荐数量的增加,UIC-TCF算法的性能并没有迅速下降,而是与传统协同过滤算法保持稳定的推荐精度差值。
图2显示了时间窗win的取值对推荐效果的影响。实验依次取win=5天,10天,15天,其中,∂=0.5。

图2 不同w i n值下算法准确率对比
从图2可以看出,w i n的取值会对推荐结果产生一定影响。因为通过设置时间窗w i n来截取目标用户最近使用过的标签,通过这些标签找到用户反复出现的兴趣偏好(即用户重复使用过的标签),并给予这部分标签较高的推荐权重,进而影响用户间的相似度。当w i n值为5~1 0之间时达到了较好的推荐效果,过大则无法反映用户的当前兴趣,失去了设置时间窗的意义。同时,通过上述时间窗的作用原理可知,时间窗 w i n取值越小,算法的运行时间越短,推荐效率越高。
最后,在最近邻个数为1 0,推荐数量等于5的条件下,测试衰减系数∂和时间窗w i n同时变化时,对推荐精度产生的影响,如图3所示。

图3 ∂与w i n综合影响下的算法准确率对比
由图3可以看出,∂和w i n的不同取值组合会显著影响推荐效果。在前2组实验中,已得到∂和w i n的部分最优值。从图中可以看到,在∂介于0.5~0.7之间时,算法可以达到较好的推荐精度;无论∂取何值,随着w i n的增大,推荐效果均有所降低,仍然在w i n为5~1 0之间时,取得较高的准确度。但无论∂和w i n如何组合,U I C-T C F算法均在一定程度上优于传统协同过滤算法。
因此,如果推荐算法只考虑用指数衰减或是时间窗来反映用户兴趣变化,必然会损失部分精度。指数渐进衰减衡量的是用户长期的兴趣趋势,而时间窗可以捕捉用户稳定的兴趣偏好,只有综合两者的优势,才能达到更好的推荐效果。
4 结束语
针对现有基于标签协同过滤算法不能快速发现用户兴趣变化问题,本文提出了一种综合标签和时间信息的推荐算法。用户兴趣以标签权重的形式表现,使用时间窗口提高反复出现的用户早期兴趣权重,采用指数渐进遗忘对用户长期兴趣偏好进行更新。从实验结果可以看出,相比一般推荐系统以静态方式进行推荐,本文方法可以更为准确地拟合用户兴趣偏好,推荐精度更高。下一步的研究工作将在多个社会化标签网站上收集有一定时间趋势的活跃用户的大数据集,检验算法的时间效率。
[1]Middleton S E,Shadbolt N R,Roure D C.Ontological User Profiling in Recommender Systems[J].ACM Transactions on Information Systems,2004,22(1):54-88.
[2]Adomavicius G,Tuzhilin A.Toward the Next Generation of Recommender System:A Survey of the Start-of-the-Artand Possible Extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[3]Zhou Tao,Jiang Luohuo,Su Riqi,etal.Effect of Initial Configuration on Network-based Recommendation[EB/OL].(2007-11-15).http://www.doc88.com/p-2691099654385.html.
[4]Pazzani M,Billsus D.Learning and Revising User Profiles:The Identification of Interesting Web Sites[J].Machine Learning,1997,27(3):313-331.
[5]秦光洁,张 颖.基于综合兴趣度的协同过滤推荐算法[J].计算机工程,2009,35(17):81-83.
[6]Heymann P,Koutrila G,Molina H G.Can Social Bookmarking Improve Web Search[C]//Proceedings of the 1st ACM International Conference on Web Search and Web Data Mining.[S.l.]:ACM Press,2008:195-206.
[7]Sen S,Lam S K,Rashid A M,etal.Tagging Communities,Vocabulary,EvolutionC]//Proceedings of ACM Conference on Computer Supp or ted Cooperative Work.[S.l.]:ACM Press,2006:181-190.
[8] 郭新明,弋改珍.混合模型的用户兴趣漂移算法[J].智能系统学报,2010,5(2):181-184.
[9]Koychev I,Schwab I.Adaptation to Drifting User's Interests[C]//Proceedings of Workshopon Machine Learningin New Information Age.Barcelona,Spain:[s.n.],2000:39-46.
[10]于 洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报:自然科学版,2010,46(5):520-527.
[11] 李克潮,梁正友.适应用户兴趣变化的指数遗忘协同过滤算法[J].计算机工程与应用,2011,47(13):154-156.
[12] 邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
编辑 顾逸斐
Research on Social Tagging Recommendation Algorithm Incorporated with User Interest Change
ZHANG Yanmei,WANG Lu
(School of Information,Central University of Finance and Economics,Beijing 100081,China)
Many recommendation methods based on social tagging ignore the change and repeatability of user interests,which may lead to unsatisfactory results.In order to solve these problems,a new method which efficiently combines exponential forgetting-based data weight and time windows is proposed.The method not only highlights the importance of recent interest, but also stresses the recurring early data.Based on standard tag set of the target user,the nearest neighbour set can be gained according to exponential offset tag vectors,and then calculates weight vectors via items within time windows.Recommendation values of the nearest neighbour set are computed by weight vectors and similarity.Finally,it makes recommendation of items within the top K predicted values.Simulation experimental results show that the proposed algorithm for recommendation can dynamically track the changes in user`s interest and has high quality of precision to some extent.
collaborative filtering;tag;interest change;exponential forgetting;time window;recommendation
1000-3428(2014)11-0318-04
A
F724.6
10.3969/j.issn.1000-3428.2014.11.062
教育部人文社会科学研究基金资助项目(11YJC880163);北京市哲学社会科学规划基金资助项目(11JGC136)。
张艳梅(1976-),女,副教授、博士,主研方向:电子商务,服务计算;王 璐,硕士研究生。
2013-09-24
2013-12-27E-mail:jlzym0309@sina.com
中文引用格式:张艳梅,王 璐.适应用户兴趣变化的社会化标签推荐算法研究[J].计算机工程,2014,40(11):318-321.
英文引用格式:Zhang Yanmei,Wang Lu.Research on Social Tagging Recommendation Algorithm Incorporated with User Interest Change[J].Computer Engineering,2014,40(11):318-321.
