基于增量式贝叶斯模型的中文问句分类研究
2014-06-06王小林镇丽华杨思春邰伟鹏
王小林,镇丽华,杨思春,邰伟鹏,郑 啸
(安徽工业大学计算机科学与技术学院,安徽马鞍山243002)
基于增量式贝叶斯模型的中文问句分类研究
王小林,镇丽华,杨思春,邰伟鹏,郑 啸
(安徽工业大学计算机科学与技术学院,安徽马鞍山243002)
固定训练集生成的分类器性能不理想且不能跟踪用户需求,为此,提出一种将增量式贝叶斯思想用于问句分类的方法。采用遗传算法选取最优特征子集优化分类器,从而避免训练集特征过分冗余,使分类器在学习过程中动态地扩大训练集并修改分类器参数。在对问句进行分类时,提取问句的疑问词、句法结构、疑问意向词和疑问意向词在知网的首项义原作为分类特征。为了验证增量式贝叶斯方法的有效性,从语料库中随机抽取不同规模的问句构成增量集,基于不同的增量集对同一测试集中的问句进行分类。实验结果表明,增量式贝叶斯分类器较朴素贝叶斯分类器有更高的分类精度,大类和小类的准确率分别达到90.2%和76.3%,在提高准确率的同时优化了运行效率。
问句分类;问答系统;增量式贝叶斯;朴素贝叶斯;改进贝叶斯;遗传算法
1 概述
自动问答系统一般包括3个主要部分:问句分析,信息检索和答案抽取[1]。几乎所有的问答系统在问句分析阶段都有问句分类这个过程,问句分类就是根据问句答案的类型将问句分到相应的语义类别中去。问句分类作为问答系统的一个重要子模块,它的重要性不言而喻,可以说问句分类的准确性直接影响了整个问答系统的性能。
问句分类方法大致分为2种:基于规则的方法和基于统计的方法。基于规则的方法简单、准确率高,但存在的主要问题是建立规则库的工作量大,人工负担重,而且灵活性也不高[2]。因此,当前基于统计的方法占主导地位,分类算法也层出不穷,具有代表性的有朴素贝叶斯、K-近邻、最大熵和支持向量机等。朴素贝叶斯分类器以其结构简单、效率高、抗干扰能力强已成为分类研究的重要方法。
在中文问句分类研究上,贝叶斯分类器受到广泛应用并且效果显著,但大多数仍是基于固定训练集训练,这显然不能满足现在爆炸式增长的信息需求。针对这一情况,本文提出将增量式学习[3]的思想用于中文问句分类研究,并用遗传算法[4]选取最优特征子集优化分类器的方法。
2 朴素贝叶斯问句分类模型
对问句分类的研究大多还是借鉴文本分类的思想,假设问句中的词与词之间相互独立,将句中的词作为特征并进行符号化表示,使用朴素贝叶斯公式找到问句所属的语义类别其数学模型简化表示为:
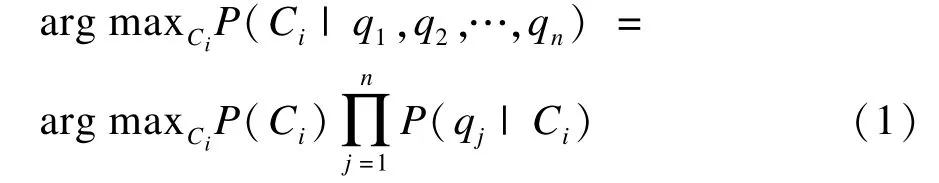
其中,Ci表示问句类别变量;q1,q2,…,qn为问句经过分词、去除停用词后的特征项;n为特征项个数,式中:
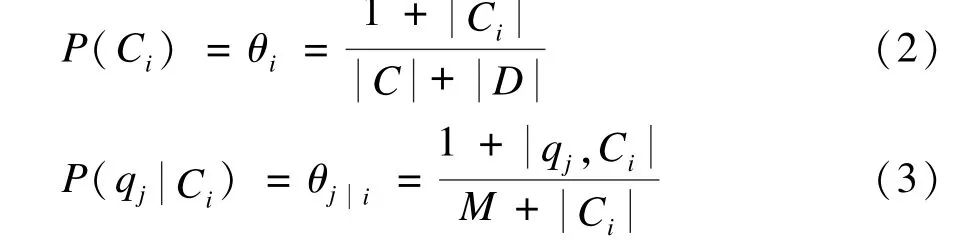
朴素贝叶斯分类是根据训练样本的类先验概率和特征的类条件概率计算后验概率,从而预测测试问句的类别。如果训练样本没有很好的完备性,那得出的准确率就可能很低。事实上,有限大小的训练集不可能有很完备的数据,很多领域的自动问答系统也是分批获取数据的。
3 增量贝叶斯相关理论
3.1 贝叶斯增量学习模型
Bayes概率是测量某个个体对某一未知事件发生的置信度,测量个体根据先验信息和现有的统计数据,用概率的方法预测未知事件发生的可能性,正是这种充分利用先验信息的特性使之成为增量学习的最佳模型。

3.2 增量分类思想
有限的训练集不能完全表示所有问句的分布情况,因此,需要找到一种方法使得训练集更加完备,从而优化分类效果。增量学习的思想就是将测试集中未标注类别的问句用现有分类器进行分类,对分类结果运用某种严格的选择策略进行判断,符合加入条件的问句实例加入到训练集扩充训练数据。用新加入的问句实例修正当前分类器参数,使得各类别的类先验概率和各特征项的类条件概率更加精确,从而使分类器的分类效果更好。
4 特征提取
问句分类和文本分类类似,都是通过文本中包含的特征信息来确定文本所属类别,但也有所区别[6]。问句一般都较短,所包含的信息比较少,没有足够的上下文环境,这就使得问句分类比文本分类更加复杂。因此,通过提取更优特征信息来提高问句分类准确率就显得尤为重要。本文共选取了4种分类特征:问句疑问词,句法结构,疑问意向词以及疑问意向词在知网中的首项义原。下面以问句“迪克·克拉克的生日是什么时候?”为例对本文的特征抽取方法进行说明。
4.1 疑问词
疑问词对于问句有很好的区分作用[7],是最重要的分类特征。对问句进行分词和词性标注后得到“迪克·克拉克|nh;的|u;生日|n;是|v;什么|r;时候|n”,选取词性标记为“|r”的词作为疑问词。该问句的疑问词特征为{什么}。
4.2 句法结构
句法分析是分析问句中词与词之间的关系,若2个词之间有弧相连,说明他们之间有依存关系,弧发起的词依存于弧指向的词。利用句法分析的结果找出问句的主干,可以减少修饰性词汇对问句分类的干扰。本文采用哈尔滨工业大学社会计算与信息检索研究中心的句法分析器对示例问句进行句法分析,结果如图1所示,提取出的问句主干为“生日 是什么时候”,该问句的句法结构特征为{生日,是,什么,时候}。

图1 句法分析结果
4.3 疑问意向词
疑问意向词是个能说明“问句到底要问什么”这一含义的概念。按照汉语问句的表达习惯,疑问词附近的名词最能表达整个问句的语义信息,并且疑问词右边的名词信息比疑问词左边的名词信息更加丰富和有效。采用以下步骤提取疑问意向词:
(1)把词性为“n、nd、nh、ni”等各类名词统一标注为“n”;
(2)从疑问词开始往右搜索,把第一个搜索到的标记为“n”的词作为疑问意向词,若疑问词右边没有标记为“n”的词,则转步骤(3);
(3)从疑问词开始往左搜索,把第一个搜索到的标记为“n”的词作为疑问意向词,若没有搜索到,则该问句没有疑问意向词。
示例问句疑问词后面第一个标记为“n”的是“时候”,该问句的疑问意向词特征为{时候}。
4.4 疑问意向词在知网中的首项义原
提取疑问意向词在知网中的首项义原作为分类特征,能够使问句的特征更具一般性,从而能更容易更准确地得到问句分类。疑问意向词“时候”在知网中的首项义原是“时间”,所以该问句的疑问意向词在知网中的首项义原特征为{时间}。
5 结合遗传算法的贝叶斯增量学习方法

其中,m表示训练集中与类别Ci相关的问句数;Qj表示训练集中与类别Ci相关的问句。
5.1 遗传算法
遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化概率搜索算法[11],它向高一级搜索的过程中不断发现新的最优解领域从而找到全局最优点,避免算法陷入局部最优解领域。由于遗传算法是对特征子集进行优劣评估,而不是对某个特征进行评价,使得在获取最优特征子集的同时无需考虑特征之间的关联性。用遗传
绝大部分文本增量学习都是从未标注类别的增量集中选择类别相关度大的文本加到训练集中,文本含有的特征信息可以更新分类器参数,从而影响分类器的分类性能。但并不是文本的每个特征都能表现出明显的类别信息,冗余或不相关的特征总会降低分类器或分类算法的性能和预测准确度,所以特征选择是分类问题中非常关键的一步[8]。本文先通过设置阈值将问句属于某一类别的概率大于阈值的问句视为类别相关问句加入到反馈集[9-10],再使用基于遗传算法的搜索技术从反馈集中选择最优特征子集,以下为阈值计算公式:算法对反馈集特征选择的关键步骤如下:
(1)遗传个体表示。编码问题的关键在于要使得所得编码能够代表所给特征集的所有可能子集的解空间。本文采用一个二进制位表示所选特征子集里的一个特征,二进制位为1时表示该特征项包含于所选特征子集,相反,如果二进制位为0表示排除该特征。
(2)初始种群的选择。遗传算法总是代表问题可能潜在解集的一个种群,种群由若干遗传个体组成,每个个体就是一个可能解。本文针对反馈集生成初始种群T,每个个体的每一位基因位按等概率在{0,1}中选择。
(3)适应度函数的定义。适应度函数的选择是否合适是遗传算法能否成功解决问题的关键。本文在选择适应度函数的时候主要考虑3个因素:1)选出的特征子集在训练集中应有较大比重;2)选出的特征子集对类别区分有较大贡献;3)特征子集包含的特征尽可能地少。综合这3个因素,选择的适应度函数如下:
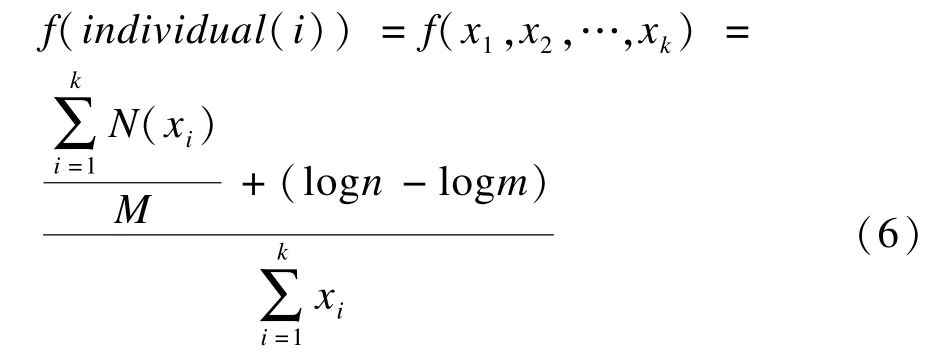
其中,xi代表一个特征项,等于1时表示该特征被选入特征子集,否则等于0;M表示压缩后的训练集中的特征总数;N(xi)表示特征xi在训练集出现的频次;(logn–logm)表示所选特征子集对类别的贡献度;n表示总的类别数;m表示用原始训练集对删除了特征子集中未出现特征项的压缩训练集进行分类能正确分出的类别数。
(4)遗传算子设计。在遗传算法中通过选择算子、交叉算子和变异算子来决定后代。选择算子使用排序选择,对群体中的所有个体按其适应度大小进行排序,根据排序来决定个体被选中的概率;交叉算子选择单点交叉操作,在个体编码串中随机设定交叉点,对该点后的2个个体部分结构进行互换;变异算子选择基因位变异操作,对个体编码串以变异概率随机指定某一位或某几位进行变异操作。
(5)终止条件的选择。设置最大进化代数,进化结束后选取适应度最大的个体进行解码后就得到所需要的最优特征子集。
5.2 本文算法描述
基于以上描述,将算法思想整理并描述如下:
输入 初始训练集D={d1,d2,…,dn},增量集S={s1,s2,…,sm},测试集T={t1,t2,…,tk},反馈集R=∅
输出 分类器C
Step 1 利用训练集D,学习初始分类器C;
Step 2 WhileS!=∅,对S中的每一元素,重复:
Step 2.1 利用现有分类器C分类si,获得最大后验概率Pmax和类别C′i;
Step 2.2 IfPmax>λ(λ为相应类别阈值)thenR=R+{<si,C′i>},else go on;
Step 2.3S=S-{si};
Step 3 对于反馈集用遗传算法(种群大小为100,遗传代数为1 000,交叉概率为0.5,变异概率为0.1)生成最优特征子集;
Step 4 根据反馈集修正分类器参数。
算法主要是利用样本中的有用信息修正分类器参数得到更精确的分类器。假设实例sp经过最优特征提取后为,将其加入到训练集中,根据Dirichlet先验分布特性和拉普拉斯概率估计[5],调整式(2)的类别先验概率和式(3)的特征项的类条件概率如下:
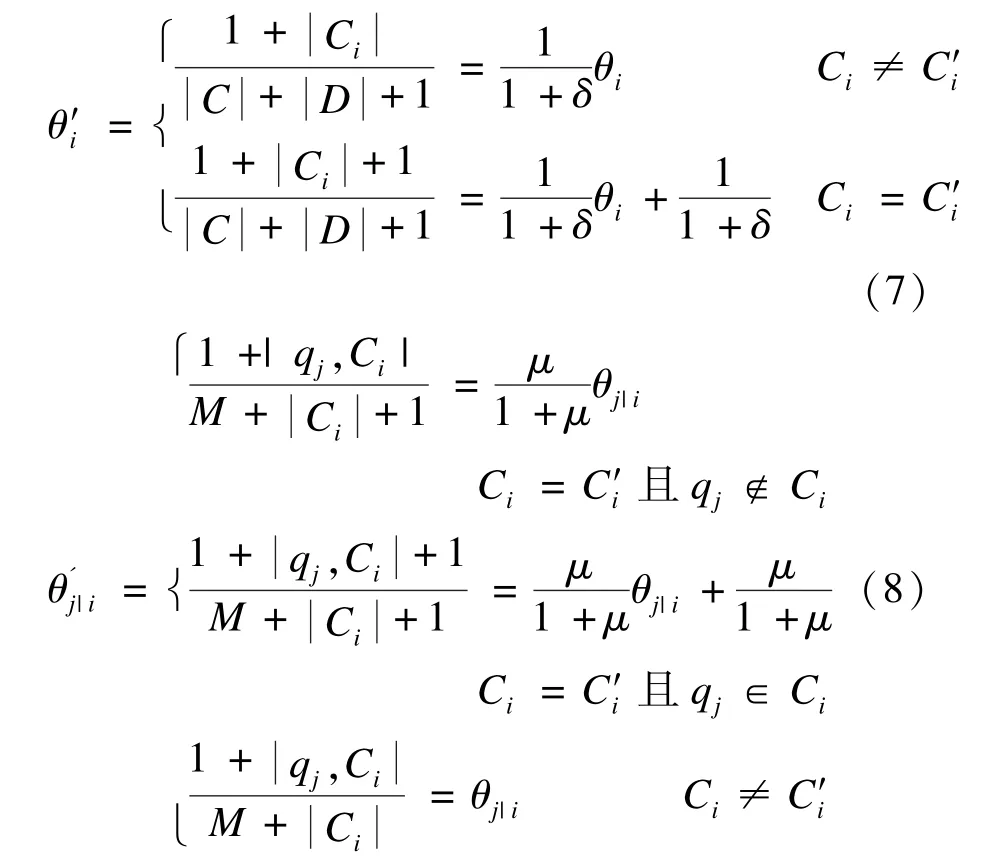
6 实验结果及分析
6.1 实验数据
本文采用的哈尔滨工业大学信息检索研究室提供的中文问句集,该问句集被分为7个大类,包括询问描述类(DES)、人物类(HUM)、地点(LOC)、数字(NUM)、实体(OBJ)、时间(TIME)和未知类(unknown),每个大类又包含一些不重复的小类,共77个小类。问句集共有6 266个问句(其中,4 966个作为训练样本;1 300个作为测试样本)。将测试样本随机分成2个部分,容量分别为700和600,容量为700的作为测试集T,容量为600的样本随机抽取200,400,600条问句作为增量集A,B,C。
6.2 评价标准
一般采用分类准确率对系统进行评价,定义如下:

6.3 实验结果
首先给出测试语料和增量前后训练语料各类别上的问句分布,如表1所示。

表1 测试语料和训练语料中的问句分布
为了验证本文设计的增量式贝叶斯学习方法在问句分类应用上的有效性及分类器增量学习后的性能,设计了3种不同的分类器模型,即传统朴素贝叶斯分类器、文献[12]中改进的贝叶斯分类器,以及增量式贝叶斯分类器。针对不同的增量集,设计的增量式贝叶斯分类器也不一样。在问句分类时选取疑问词、句法结构、疑问意向词和疑问意向词在知网的首项义原作为问句分类特征。不同分类器模型在大类和小类上的准确率如表2所示,在各类别上的准确率如表3所示。

表2 不同分类器模型的分类准确率 %

表3 不同分类器模型在各类别上的分类准确率 %
6.4 结果分析
由表2可以看出,改进贝叶斯分类器无论在大类还是小类上准确率都比朴素贝叶斯高。为了测试本文增量式的可行性,重点比较改进贝叶斯和增量式贝叶斯这几组实验,发现3种增量贝叶斯模型的准确率都比改进贝叶斯的准确率高,不同增量集对应的增量式贝叶斯分类器分类效果比较表明,增量集的问句数越多分类效果越好,说明本文提出的增量式贝叶斯方法是有效的。
观察表3中的数据发现:(1)HUM、LOC和TIME这3个类别使用改进贝叶斯分类方法时效果并不理想,其主要原因是因为训练集不充分导致初始分类器不准确。动态加入最优特征优化分类器后准确率提高尤其显著,增量集为C时分别提高了15.1,10.6,13.6个百分点。具体到小类发现,HUM_ORGANIZATION的正确率由27.8%提高到61.1%,LOC_COUNTRY的正确率由67.5%提高到90.0%,TIME_OTHER的正确率由72.7%提高到86.4%,这说明了增量学习方法对于训练不充分的类别优化效果更加有效,使得分类器从训练初期的不充分阶段逐步向充分阶段转移。(2)DES和NUM使用3种增量式贝叶斯分类器准确率提升幅度都比较小,这是因为经遗传算法筛选后加入的特征在这2个类别的训练集里本来就已经较完备,而且这些特征比较能反映问句的类别(如“简称”、“如何”、“多少”),所以用改进贝叶斯分类器分类时准确率就已经比较高。(3)OBJ类训练集规模比较大,但准确率比较低,这是由于包含疑问词“什么”的问句在训练集中在DES类别中出现的比例要比在OBJ中出现的比例大,所以很多包含“什么”的问句都被标记为DES类。
除准确率提高以外,增量式贝叶斯分类模型也大大优化了运行效率。分析知增量式贝叶斯模型主要时间消耗在初始参数的确定上,后面每一次对参数的调整都建立在上一个模型的基础上,进行分类时只要在已有的参数上计算,而改进贝叶斯模型对测试问句中的每个特征的概率计算都需要对训练集从头至尾统计词频,这必然会耗费大量时间。
7 结束语
本文提出将增量式贝叶斯思想用于问句分类的方法,结合遗传算法选取最优特征集优化分类器,强化了较完备数据对分类的积极影响而弱化了噪音数据的消极影响。实验结果表明,该方法在消除过多冗余特征、缩小增量规模的同时仍然有效地改善了分类器性能,并且在训练集不充分的情况下效果尤为突出,可见训练集的完备性对问句分类有较大影响。
在使用增量式完善训练集时也存在问题:用遗传算法提取最优特征时选取的是对分类系统最优而不是类别最优,会给某些类别带来干扰特征项;另外,选取最优特征只停留在词语表层,没有涉及语义。所以该增量学习方法还有待改进,下一步的研究重点是结合知网库对问句进行语义扩展,这样在选择适应度函数时特征子集的选择就延伸到语义层,而且语义扩展后得到的特征子集对类别贡献度也会有所提高。
[1] 郑实福,刘 挺,秦 兵,等.自动问答综述[J].中文信息学报,2002,16(6):46-52.
[2] 杨思春,高 超,秦 锋,等.融合基本特征和词袋绑定特征的问句特征模型[J].中文信息学报,2012,26 (5):46-52.
[3] 陈 文,晏 立,周 亮.一种具有增量学习能力的PU主动学习算法[J].计算机工程,2011,37(4): 214-215.
[4] Sarkar B K,Sana S S,Chaudhuri K.Selecting Informative Rules with Parallel Genetic Algorithm in Classification Problem[J].Applied Mathematics and Computation, 2011,218(7):3247-3264.
[5] 宫秀军,刘少辉,史忠植.一种增量贝叶斯分类模型[J].计算机学报,2002,25(6):645-650.
[6] 李 鑫,黄萱菁,吴立德.基于错误驱动算法组合分类器及其在问题分类中的应用[J].计算机研究与发展, 2008,45(3):535-541.
[7] 许 莉,王大玲,夏秀峰.基于句法和语义信息的问句特征提取方法[J].计算机工程,2010,36(21):65-66.
[8] 洪智勇,王天擎,刘灿涛.一种新的互信息特征子集评价函数[J].计算机工程与应用,2011,47(22): 130-132.
[9] Lee J H.Combining the Evidence of Different Relevance Feedback MethodsforInformation Retrieval[J]. Information Processing and Management,1998,34(6): 681-691.
[10] Tao Dacheng,Tang Xiaoou,Li Xuelong.Direct Kernel Biased Discriminant Analysis:A New Content-based Image Retrieval Relevance Feedback Algorithm[J]. IEEE Transactions on Multimedia,2006,8(4):716-727.
[11] 周 明,孙树栋.遗传算法原理及应用[M].北京:国防工业出版社,1999.
[12] 张 宇,刘 挺,文 勖.基于改进贝叶斯模型的问题分类[J].中文信息学报,2005,19(2):100-105.
编辑 顾逸斐
Chinese Question Classification Research Based on Incremental Bayes Model
WANG Xiao-lin,ZHEN Li-hua,YANG Si-chun,TAI Wei-peng,ZHENG Xiao
(School of Computer Science&Technology,Anhui University of Technology,Maanshan 243002,China)
Since the performance of the classifier generated by the fixed training set is not satisfactory and can hardly track the users'needs dynamically,in this paper,the incremental Bayes idea is introduced in question classification.In order to eliminate the feature redundancy in the training set,Genetic Algorithm(GA)is used to select the optimal features to amend the classifier.In the process of classifier learning,the parameters are modified dynamically while the training set is expanded.The interrogative word,syntax structure,question focus words,and their first sememes are chosen as classification features.To verify the effectiveness of the proposed method,in the experiment,questions of different size at random are extracted from the corpus to build the incremental sets.Then classify the questions from the same test set based on different incremental sets.Experimental results show that the incremental Bayes classifier achieves better result. The classification accuracy of coarse classes and fine classes achieves 90.2%and 76.3%respectively.At the same time, it significantly optimizes the efficiency to some degree.
question classification;question answering system;incremental Bayes;naive Bayes;modified Bayes; Genetic Algorithm(GA)
1000-3428(2014)09-0238-05
A
TP319
10.3969/j.issn.1000-3428.2014.09.048
国家自然科学基金资助项目(61003311);安徽高校省级自然科学基金资助项目(KJ2011A040)。
王小林(1964-),男,教授,主研方向:人工智能,中文信息处理;镇丽华,硕士研究生;杨思春,副教授、博士研究生;邰伟鹏,讲师、博士研究生;郑 啸,教授、博士。
2013-09-09
2013-11-01E-mail:wxl@ahut.edu.cn
