基于分段极值的时间序列数据查询显示方法
2014-06-06李重文邓腾彬马世龙
李重文,邓腾彬,马世龙
(1.湖南师范大学工程与设计学院,长沙410081;2.东莞电子科技大学电子信息工程研究院,广东东莞523808; 3.北京航空航天大学软件开发环境国家重点实验室,北京100191)
基于分段极值的时间序列数据查询显示方法
李重文1,邓腾彬2,马世龙3
(1.湖南师范大学工程与设计学院,长沙410081;2.东莞电子科技大学电子信息工程研究院,广东东莞523808; 3.北京航空航天大学软件开发环境国家重点实验室,北京100191)
时间序列数据在许多领域广泛存在,有海量和复杂的特点,直接查询出所有的原始数据并对其进行分析十分耗时,且对计算机的内存消耗极大。为此,提出一种基于分段极值的时间序列数据查询显示方法,对需要查询分析数据的时间范围进行分段,根据各个时间段数据的极值及总取点个数来确定该时间段的取点个数,通过数据库本身的查询机制实现均匀取点,并结合多线程机制实现各时间段数据的并行查询及曲线绘制。实验结果表明,与传统查询及可视化方法相比,该方法能够指定取点数量,并在取点数量确定的情况下,绘制曲线能较好地逼近原始曲线,且极大地缩短曲线的查询绘制时间,具有较好的工程实用性。
时间序列;数据库查询;时间序列数据库;曲线绘制;数据压缩;数据分析
1 概述
时间序列数据在医学、金融、传感器网络、移动对象、自动化测试[1]等领域广泛存在,并且在生物序列分析、金融数据分析、传感器网络监控等领域成功应用。
当前关于时间序列数据的研究主要集中在相似性搜索[2-3]、时间序列分割与模式发现[4-5]及时间序列的预测[6-7]等,并取得了大量的研究成果。时间序列可视化也是一个应用前景广阔的研究方向[8-11],国外研究较多,并开发出了相应的可视化工具,如 time-series on spirals[12],time searcher[13], vizTree[14],time-series bitmaps[15]等,但这些工具主要还是集中在对时间序列数据模式发现的可视化、模式展现形式的多样性等方面的研究。对于某些领域,如航天器测试中对数据分析的重点并非模式发现或者时间序列预测,而需要直接对原始数据进行查询分析,由测试人员来对数据的正确性进行判断,因此,目前已有的可视化工具都无法满足该需求。
当时间序列数据存储于时间序列数据库后,为便于分析,比较常用的方法是从数据库中检索数据,并将数据以曲线的形式展现出来,使得数据分析人员能够直观地对检索的数据趋势以及局部数据进行分析。但是由于数据的时间密度大,如在航天器测试应用中按照1 s 1条记录计算,一天的数据量就是86 400条,按照1周为数据分析周期,则总的数据量为604 800条。将如此多的数据一次全部检索出来并绘制出曲线是不大可行的:一方面将数据从数据库中检索出来需要耗费大量的时间,漫长的响应等待时间是用户难以接受的;另一方面巨大的数据量会消耗分析软件大量的内存空间,当数据量再变大,实现数据的全部绘制就不可行了。
传统的解决方案都是将大量的数据以分页的形式进行处理,即每次检索出固定数量的数据并绘制出曲线,当用户点击下一页时再将相同数量后一个时间段的数据检索出来进行绘制。这样做有如下不足:假设每页数据显示2 000条时,这些数据按照1 s 1条计算,仅涉及了约33 min的数据,对于1周的分析周期显得过于短暂,分析人员无法对1周数据的大致发展趋势进行判断,同时也无法快速定位异常数据所处的时间区间。
另一个解决思路是采用常见的曲线压缩算法如Douglas-Poiker法、线段过滤法、垂距限值法等对数据进行压缩,从而进行曲线绘制。这些算法的优点是都能取出较能体现曲线特征的特征点,从而使绘制出的特征点曲线能较好地逼近原始曲线。但是,将这些算法应用在这种极大数据量的环境中存在2个问题:
(1)这些算法都需要遍历所有的数据,并进行数据之间的运算才能取出特征点。如果按照前面所述的1 s 1条数据,从数据库中查询出一周的数据而不进行任何数据之间的运算都需要较长时间,再加上数据运算,绘制曲线需要的时间显然是不可接受的。
(2)这些算法虽然都能压缩数据量,但是压缩程度都依赖于某个阈值,如Douglas-Poiker法和垂距限值法都需要指定某个垂距作为数据过滤的阈值,线段过滤法需要指定线段长度作为数据过滤的阈值。对于不同的数据需要不同的阈值,分析人员往往无法直接提供出合适的阈值。
目前,针对这种大数据量数据的一次曲线显示查询还没有较好的解决方案。
本文提出基于分段极值的时间序列数据查询显示方法,该方法可以指定取点的总个数,并根据较少的数据点体现数据的变化趋势,结合多线程机制提高响应速度。
2 分段数据查询显示方法描述
本文方法的基本思路为:对整个需要查询分析的时间区间进行分段,每个分段按照一定的策略分别获取不同个数的数据点,以各个分段获取的数据点集合作为整个时间区间的趋势变化点集;另外,为加快整个曲线的查询绘制响应速度,每个分段时间区间分别开启单独线程来进行数据的查询分析及更新曲线视图。
2.1 基本定义
假设需要取点的总个数为pcount,该数据可由用户设定或程序根据用户显示器屏幕分辨率自动确定。整个时间区域分成n个时间段。
2.1.1 各时间段取点个数的确定
按照一般统计规律,对于任意2个跨度相同的时间段,极值相差较大的时间段能够容纳更多的数据变化信息,即隐藏着更多曲线变化,因此宜采集较多的数据点;而对于极值相差较小的时间段,说明该时间范围内数据变化平缓,则可选取少量数据点。因此,将较多的点取自变化较大的时间段,较少的点取自变化平缓的时间段,能够在总的取点个数一定的情况下较好地反映总的数据变化情况。
为了描述数据变化程度,对于第i个时间段值的变化情况,本文使用值的绝对距离di来衡量,即:

其中,maxi为第i个时间段内数据的最大值;mini为第i个时间段内数据的最小值。
根据式(1),所有分段的绝对距离之和为:

根据每一个时间段的绝对距离di在总的绝对距离之和sum所占的比例来确定第i个分段的取点个数,即:

对于式(3),pi的确定适合于di不等于0的情况,当di等于0时,说明该时间段值无变化,则取pi=2,因此综合2种情况,pi的取值为:

其中,i的取值范围为0<i≤n。pi在根据式(3)计算时,结果按照四舍五入取整数。
2.1.2 取点策略
取点策略包括如下部分:
(1)当di=0时,pi=2,说明第i时间段内的数据无变化,因此,选取第i个时间区间的首尾2个点即可代表该时间段的曲线特征。
(2)为加快数据查询及曲线绘制响应速度,避免Douglas-Poiker等方法须将所有数据都查询出来并进行计算及其耗时的缺陷,本文采用均匀取点的策略,即从所有数据点中按照点的序号等间隔地取点。均匀取点一方面能够根据总数据量和均匀间隔有效控制取点个数;另一方面均匀取点能够直接得到数据库的支持,主流大型数据库如ORACLE,DB2等通过SQL语句就能实现均匀取点,数据库查询出的点即目标点,能够极大地缩短查询取点耗时。
(3)对于每个时间段,最大值及最小值也作为目标点进行查询及曲线绘制。
2.1.3 分段个数的确定
令整个需要进行查询分析时间区域的数据总个数为total,在取点数量pcount确定的情况下,显然分段越多取出的数据点越能体现原始数据的变化趋势,因此可取:

但是由于n越大,开启的并行处理线程越多,也将消耗更多的系统资源,因此根据经验n的取值一般不超过50。
2.2 具体过程
曲线查询绘制子过程drawTendencyCurve如下:
输入 取点个数pcount,时间区间timeSE
输出 由取点集合绘制的曲线


在主过程中,如果用户要进一步查看某段时间区间的数据,则在已绘制的曲线显示视图上通过鼠标选定某个区间,将该区间的横坐标时间范围作为新的查询时间区间,然后再次调用上述子过程进行曲线查询绘制,使数据分析人员可进一步查看所选时间区域数据的细节,如果用户不需要进一步查看数据,则结束本次曲线绘制。
3 实验结果与分析
现有一个航天领域内测试数据管理的应用系统。该应用系统提供的主要功能包括对海量的航天器试验数据进行数据入库以及数据查询分析。该应用系统的数据库中主要数据表的字段分别为时间、[参数1]、[参数2]、[参数3]、……,其中时间作为主键,精确到ms,时间列在数据库中存储的数据类型为长整型数据。数据库系统采用ORACLE 9I数据库。该应用系统的数据查询分析子系统基于本文方法对测试数据进行查询以及曲线绘制,子系统采用 Java语言实现,曲线绘制使用的是开源JFREECHART工具包,运行于普通PC。实验环境如表1所示。

表1 实验环境
数据库中存储有一年的航天器测试数据。实验过程为按本文方法取3 000个点进行曲线绘制,然后取出该时间段所有数据点进行曲线绘制,比较两者的耗时及曲线形态。
本次实验查询的参数为A01,查询时间范围为2006年10月17日-10月27日共10天的数据,数据量为405 300条,曲线视图中横坐标表示时间,纵坐标表示参数编号为A01中的数值。
下文详细分析实验中数据的查询及曲线绘制过程:
(1)根据式(5)得出的n值均远大于50,故此处n取值为50,即分成50个时间段,每个时间段所含的数据量为pavg=405 300/50=8 106条。
(2)分别查出各段数据的起止时间点,SQL语句为:SELECT time FROM(SELECT time,ROWNUM from tb_name WHERE time BETWEEN 1161043100000 AND 1161935558000 AND(A01 IS NOT NULL)) WHERE MOD(ROWNUM-1,pavg)=0,其中,tb_name为对应表的名称;ROWNUM是ORACLE系统顺序分配为从查询返回的行的编号;1161043100000为实验的查询起始时间2006年10月17日07:58:20的长整数表示;1161935558000是查询结束时间2006年10月27日15:52:38的长整数表示。

(4)初始化曲线绘制视图,将所有已获取各时间段的最大值与最小值绘制于曲线显示视图中。本次实验中50个时间分段的最大值与最小值一共为100个数据点,采用连线的形式将100个点在曲线显示视图中显示出来,如图1所示。
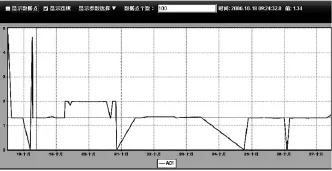
图1 最大最小值曲线绘制截图
(5)开启50个线程,每个线程负责处理一个时间段的曲线数据查询及视图更新。令50个时间分段中每个分段的起止时间分别为(t1,t2),(t3,t4),…,(ti,ti+1),…,(t50,t51),以及对应的时间段内要取点的个数为pi,则第i个线程构造的SQL查询语句为:SELECT time, A01 FROM(SELECT time,A01,ROWNUM FROM tb_ name WHERE time BETWEEN tiAND ti+1AND A01 IS NOT NULL)WHERE MOD(ROWNUM-1,tvi)=0,其中,tb_name为对应的表名称;参数tvi=pavg/pi;tvi表示需要均匀间隔取点的间隔数;ti,ti+1分别表示第i个时间段的起始和结束时间值。
(6)当50个线程都处理完成时,则曲线绘制完毕。用户可以查看所绘制的曲线,分析曲线整体的趋势,以及其是否存在异常,并将所绘制的曲线数据保存起来供后续查看分析。
本次实验曲线绘制完毕后在曲线显示视图中的显示如图 2所示,绘制的数据点个数一共为3 010个,由于pi的计算采用了四舍五入,且tvi的计算也是取整,因此总的取点个数只会近似于pcount。对比图3未使用本文方法将所有数据进行绘制的显示图,可以看出两者的曲线相当逼近,图2以较少的数据点很好地体现了图3的曲线特征,并且采用本文方法最终的耗时仅为5 s,远小于取出全部数据的572 s耗时,当采用Douglas-Poiker法或者垂距限值法时,因为还存在数据运算,显然时间会大于572 s。
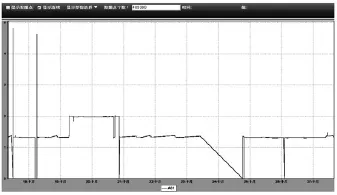
图3 全部数据点查询曲线绘制截图
通过实验可以看出,本文方法无论在时间、空间上都优于其他曲线压缩算法,并且具有较好的曲线特征提取效果,能够更好地应用于工程实践中。在航天器测试领域,大部分参数的变化都应该遵循某个变化规律或者变化的幅度处于某个指定的区间,数据分析人员通过绘制的曲线能很容易找到这些特征,并定位异常数据。本文方法对分析该航天器是否存在异常提供了便利,方便数据分析人员在短时间内查看长时间数据的曲线走势,根据该曲线判断是否存在异常,并且能够快速定位异常数据的位置,根据定位到的异常数据进一步分析该航天器的哪个部分出现问题。
4 结束语
时间序列数据由于其庞大的数据量,传统的数据查询及可视化方法在时空效率上都难以取得理想效果。本文结合航天器测试领域内的数据分析需求,提出一种基于分段极值的时间序列数据查询显示方法。通过对要查询分析的时间范围进行分段,在各分段内部采用均匀取点,由于数据库本身支持均匀取点,因此能够获得较快的取点速度,实验结果表明,该方法在时空效率及查询效果上具有较好的工程实用性。目前,本文方法已经成功应用于多个型号的航天器测试数据分析系统中。如何更为合理地确定各分段取点个数将是下一步将要解决的问题。
[1] 李重文,李先军,叶 钢,等.一种大数据量的曲线显示查询方法:中国,ZL 201010555587.4[P].2011-12-07.
[2] Yang Yin,Papadopoulos S,Papadias D,et al.Authenticated Indexing for Outsourced Spatial Databases[J]. VLDB Journal,18(3):631-648.
[3] Bueno R,Traina A J M,Traina J C.Genetic Alogorithms for Approximate Similarity Queries[J].Dataand Knowledge Engineering,2007,62(3):459-482.
[4] 覃 征,李爱国.时间序列数据的稳健最优分割[J].西安交通大学学报,2003,37(4):338-342.
[5] 肖 辉,胡运发.基于分段时间弯曲距离的时间序列挖掘[J].计算机研究与发展,2005,42(1):72-78.
[6] 薛海东,朱群雄.基于结构化类比的时间序列预测算法[J].计算机工程,2010,36(1):211-214.
[7] 刘志刚,杜 娟,许少华,等.基于过程神经元网络的时间序列预测方法[J].计算机工程,2012,38(5): 199-201.
[8] Yu Jin,Hunter J,Reiter E,et al.Recognising Visual Patterns to Communicate Gas Turbine Time-series Data [C]//Proc.of the 22nd SGAI International Conference on Knowledge Based Systems and Applied Artificial Intelligence.London,UK:Springer,2002:105-118.
[9] Hochheiser H,Shneiderman B.VisualQueries for Finding Patterns in Time Series Data[D].Baltimore, USA:University of Maryland,2002.
[10] Hochheiser H,Shneiderman B.Visual Specification of Queries for Finding Patterns in Time-series Data[D]. Baltimore,USA:University of Maryland,2001.
[11] Hochheiser H.Interactive Graphical Querying of Time Series and Linear Sequence Data Sets[D].Baltimore, USA:University of Maryland,2003.
[12] Weber M,Alexa M,Muller W.Visualizing Time-series on Spirals[C]//Proc.of IEEE Symposium on Information Visualization.San Diego,USA:IEEE Press, 2001:7-13.
[13] Hochheiser H,Shneiderman B.Dynamic Query Tools for Time Series Data Sets:Timebox Widgets for Interactive Exploration[J].Information Visualization,2004,3(1): 1-18.
[14] Lin J,Keogh E,Lonardi S.Visualizing and Discovering Non-trivial Patterns in Large Time Series Databases[J]. Information Visualization,2005,4(2):61-82.
[15] Kumar N,Lolla N,Keogh E.Time-series Bitmaps:A Practical Visualization Tool for Working with Large Time Series Databases[C]//Proc.of SSIAM'05. Newport Beach,USA:[s.n.],2005:531-535.
编辑 任吉慧
Method for Query and Display of Time-series Data Based on Extreme Value of Segmented Periods
LI Zhong-wen1,DENG Teng-bin2,MA Shi-long3
(1.College of Engineering&Design,Hunan Normal University,Changsha 410081,China;
2.Institute of Electronic and Information Engineering in Dongguan,University of Electronic Science and Technology of China, Dongguan 523808,China;3.State Key Laboratory of Software Development Environment,Beihang University,Beijing 100191,China)
Time-series is a kind of important data object and is ubiquitous in the world.Due to its very large quality and complexity,data query and analysis base on the source data do pay high costs on time and memory of computer.A method for querying and displaying time-series data based on segmented extreme value is proposed.It segments the range of time to be queried and analyzed into periods of time,and then determines the number of access points in a period of time according to extreme value of each period of time and the total number of access points,accessing the points uniformly through a database query mechanism itself and combined with multi-threading mechanism to achieve parallel query and curve drawing of each time period data.Experimental results show that compared with traditional methods,the number of access points is able to be specified,and the drawn curve has a good approximation of the original curve in the case that the number of access points are determined.It is able to greatly shorten the curve querying and drawing time,
with good engineering practicality.
time-series;database query;time-series database;curve drawing;data compression;data analysis
1000-3428(2014)09-0027-05
A
TP311.13
10.3969/j.issn.1000-3428.2014.09.006
湖南省自然科学基金资助项目(13JJ6029);湖南师范大学青年优秀人才培养计划基金资助项目(ET13108);东莞市高等院校科研机构科技计划基金资助项目(20121081001019)。
李重文(1981-),男,博士,主研方向:海量数据处理,自动化测试;邓腾彬,助理研究员;马世龙,教授。
2013-10-10
2013-12-19E-mail:lee_zw@163.com
