一种基于Hadoop的动态树增量更新方法
2014-06-02颜一鸣
颜一鸣,郭 鑫
一种基于Hadoop的动态树增量更新方法
颜一鸣,郭 鑫
(吉首大学软件服务外包学院,湖南 张家界 427000)
为适应真实环境中数据量大、流程复杂、计算密集的数据挖掘需求,提高传统树增量更新挖掘效率,改变已有算法的串行执行方式,提出一种基于Hadoop的动态树增量更新方法。介绍云计算、模型与执行流程等基本概念,针对现有Hadoop平台中任务调度的随机分配策略,设计一种动态云平台中的资源调度与分配算法,以期达到成本消耗的最小化,给出树增量更新挖掘算法以及2个并行算法(DeleteFreqTree和FindNewTree),完成树数据的增量挖掘工作。实验结果表明,该并行算法有效可行,具有高效性与良好的扩展率,能够对海量树数据进行更新挖掘。
数据挖掘;数据库;云计算;并发控制;频繁子树;增量更新
1 概述
树结构是现实世界中最基本的数据类型之一,很多应用环境都需要树结构,如数据库设计、XML数据分析、生物工程等。虽然针对树数据的处理技术与应用已发展很长时间,理论日趋完善,但随着互联网应用的普及与迅猛发展,许多企业机构都累积了大量不同结构形式的数据,其中大部分的数据都是以树结构表现出来的,如何对这些海量树数据进行高效管理,以及如何快速地更新与维护树数据库已经成为一个新的挑战。显然,传统的树数据挖掘算法与增量更新算法已无法满足数据日益增长的需求,可以将云计算[1]技术应用到相关算法中,以提高更新挖掘海量数据的效率。
云计算是先进计算机技术的产物,利用云计算来解决大规模树数据挖掘是一个具有发展潜力的方向。在云计算平台下进行海量数据处理主要包括MapReduce[2]和整体同步并行计算模型(BSP)[3]2种模型。谷歌的Pregel[4]与雅虎的Giraph[5]就是基于BSP模型的,但存在着消息通信效率瓶颈。MapReduce模型主要包括Hadoop与HOP[6]系统,本文利用MapReduce模型来处理海量树数据,主要包括输入输出文件、任务的分配、信息的改善、执行Reduce函数等过程。由于基于Hadoop平台的MapReduce算法工作流程简单可行,因此本文基于Hadoop平台设计一种动态树增量更新算法,以改善海量树数据的更新挖掘效率。
2 动态云平台
以往的云计算平台采用空闲的计算结点列表来保存当前可用的计算资源,Master结点在对任务进行分配时,会查阅该资源列表并将分割的子任务随机分配给当前闲置的计算结点,计算结点获得数据并进行相应的计算工作,最后将计算结点反馈给主结点。
在这一过程中,计算结点会定时给主结点发送信息以证明是否处于空闲状态,主结点收集空闲结点并进行随机调度。随机调度机制虽然可行,也很容易实现,但各个计算资源的实际情况不一,随机分配并不能保证计算资源的最佳利用,如云平台的整体反应时间最优、消耗成本最小、完成时间最少与计算性能最佳等。如何对计算资源进行合理调度才能达到最优化状态是本文需要考虑的问题,但要想达到所有情况最优很难实现,因此,对现有Hadoop平台的资源调度策略[7]进行改进,提出一种新的基于Hadoop的动态资源分配方法,该方法可以实现计算结点最小化资源消耗。
在设计动态云平台时,将综合考虑输入大数据文件类型、集群中计算结点数量、分配的子任务数量、调度和使用文件的时间成本、回收文件成本等要素,下面将集中论述动态云资源分配模型相关概念。
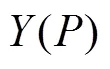
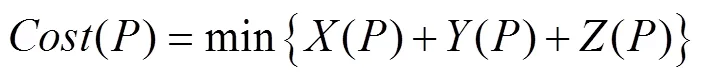
其中:

目标函数的约束条件为:
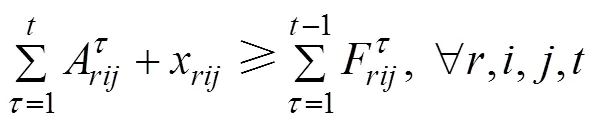
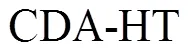
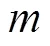
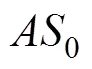
基于CDA-HT算法的动态云模型框架如图1所示。
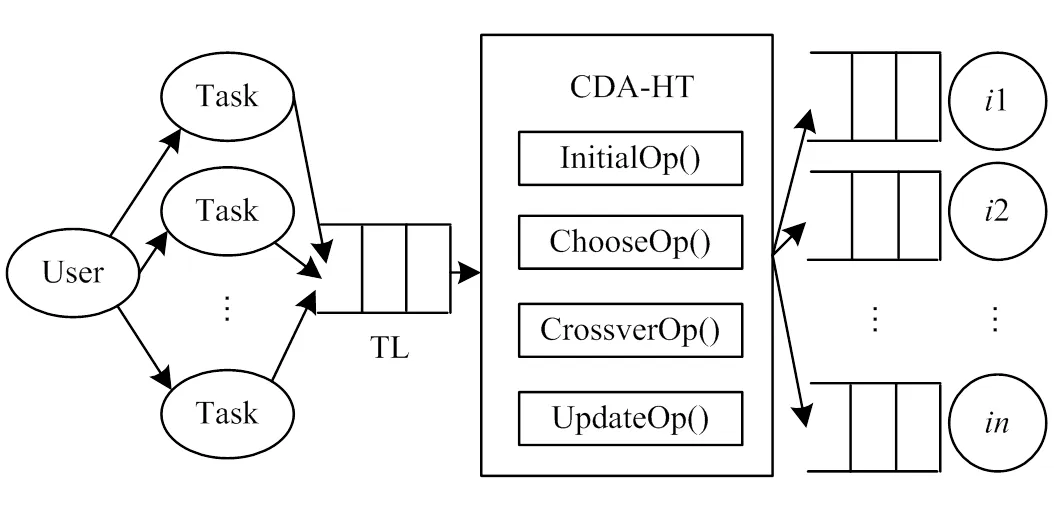
图1 动态云模型框架
3 基于Hadoop的树数据增量更新算法
传统的树数据挖掘算法与相关应用已发展成熟,树挖掘算法方面包括基于最右叶子结点扩展的有序树挖掘算法[8]与基于XML树结构特征的挖掘算法[9]等,树应用方面包括基于树的图像特征提取[10]与树层次聚类[11]等。本文考虑当树数据库与更新树集较大时,改善增量挖掘效率,提出一种基于Hadoop平台的动态树增量更新方法。
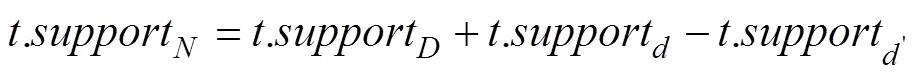
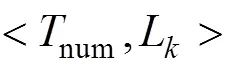

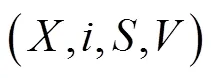
Map操作:根据上述策略生成新的子树集,分别用四元组表示,以子树结点数为键,四元组为值形成键值对,作为中间数据传递给Reduce操作。
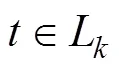
4 实验设计与分析



表1 更新树集的设置
设置不同的支持度阈值进行实验,实验结果如图2 所示。

图2 不同支持度下的运行结果

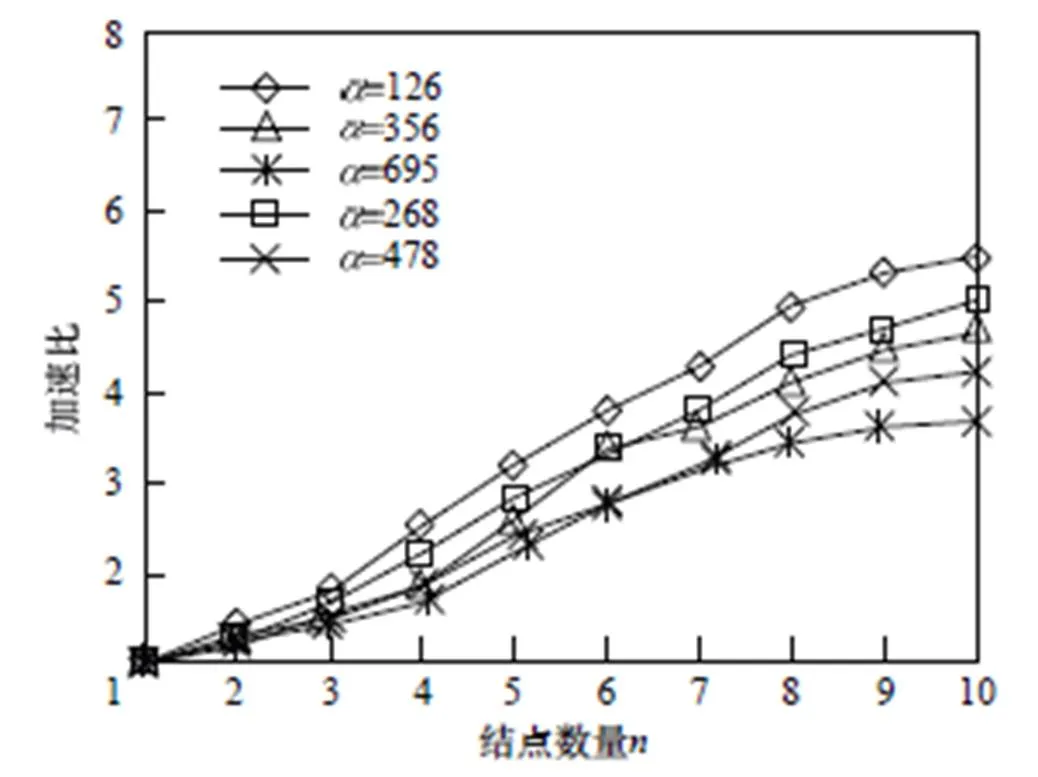
图3 加速比性能测试结果
从图3中可以看出,并行算法加速性能良好,在不同的支持度下加速性能不一样,但总体趋势一致,随着计算结点的增多,加速效果明显,但增长放缓,对于单一结点,其数据处理效率还是具有很大优势的。
第3组实验验证并行算法的扩展率,随机选取4个计算结点,采用5组数据集进行实验,数据集设置见表2。
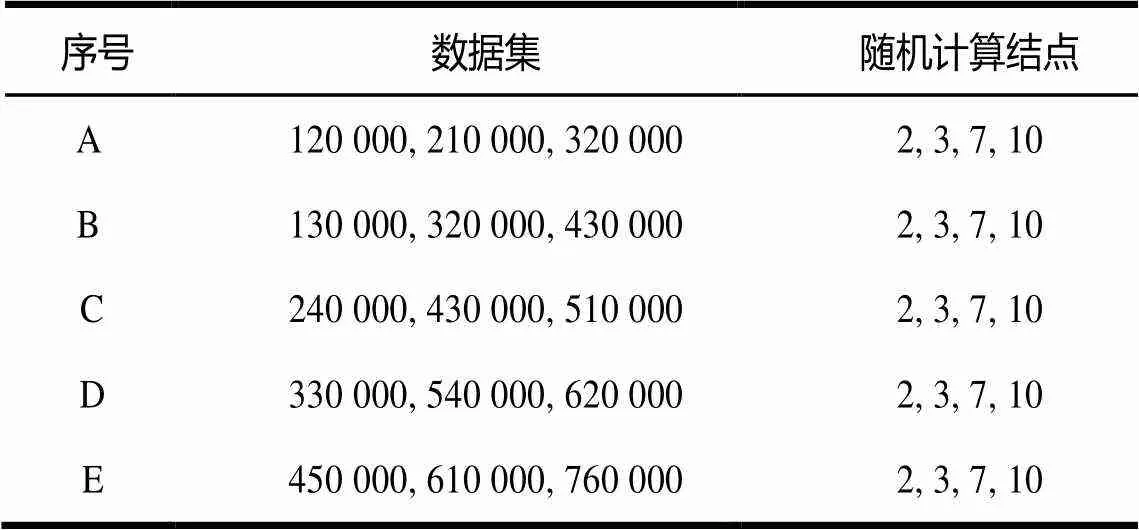
表2 参数设置
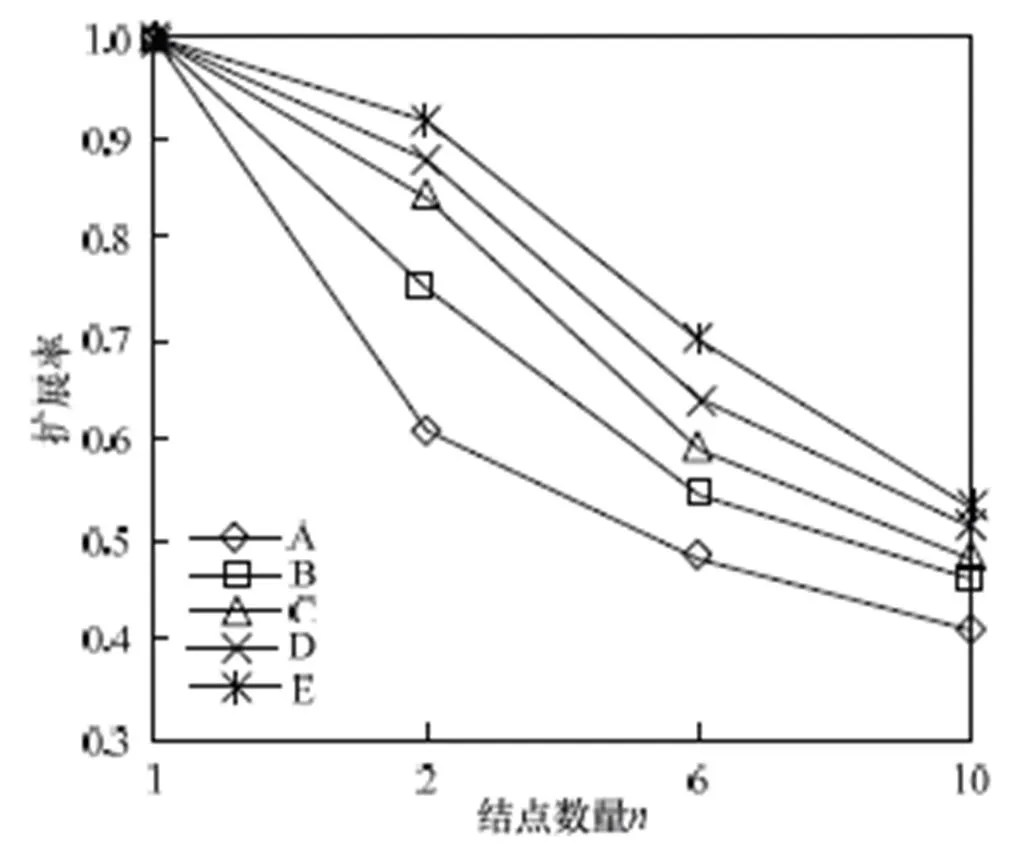
图4 扩展率测试结果
从图4中可以看出,当计算结点数增多时,算法的扩展率(百分比)是逐渐减小的,原因在于结点数越多,算法所需的通信代价也就越高,算法的执行时间也会随之增加。通过大量实验表明,本文提出的基于Hadoop的动态树增量更新算法具有可行性、高效性和扩展率。
5 结束语
本文根据云计算中并行分布式处理的特点,设计一种基于Hadoop的动态树增量更新挖掘算法。实验结果表明,本文算法具有可行性、高效性和扩展率,能够满足海量数据更新的需要。今后将继续改进该算法以解决实验过程中碰到的问题,同时还可以考虑将动态云计算平台应用到数据挖掘的其他方面,甚至扩展到图挖掘与社交网络等领域。
[1] 刘 鹏. 云计算[M]. 北京: 电子工业出版社, 2010.
[2] Jeffrey D, Sanjay G. MapReduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[3] Valiant L G. A Bridging Model for Parallel Computation[J]. Communications of the ACM, 1990, 33(3): 103-111.
[4] Grzegorz M, Austern M H, Bik A J C, et al. Pregel: A System for Large-scale Graph Processing[C]//Proc. of SIGMOD’10. Indianapolis, Indiana: [s. n.], 2010: 135-145.
[5] Ching A. Giraph: Large-scale Graph Processing Infrastruction on Hadoop[C]//Proc. of the Hadoop Summit. Santa Clara, USA: [s. n.], 2011.
[6] Condie T, Conway N, Alvaro P, et al. MapReduce Online[C]// Proc. of NSDI’10. San Jose, USA: [s. n.], 2010: 33-48.
[7] Lublin U, Feitelson D G. The Workload on Parallel Super- computers: Modeling the Characteristics of Rigid Jobs[J]. Journal of Parallel and Distributed Computing, 2003, 63(20): 1105-1122.
[8] Zaki M J. Efficiently Mining Frequent Trees in a Forest: Algorithms and Applications[J]. IEEE Transactions on Knowledge and Data Engineering: Special Issue on Mining Biological Data, 2005, 17(8): 1021-1035.
[9] 卓月明. 基于聚类技术的XML文件代表性结构获取[J]. 吉首大学学报: 自然科学版, 2011, 32(6): 55-58.
[10] 王志瑞, 闫彩良. 图像特征提取方法的综述[J]. 吉首大学学报: 自然科学版, 2011, 32(5): 43-47.
[11] 刘文军, 游兴中. 一种改进的凝聚层次聚类法[J]. 吉首大学学报: 自然科学版, 2011, 32(4): 11-14.
[12] 陈光鹏, 杨育彬, 高 阳, 等. 一种基于MapReduce的频繁闭项集挖掘算法[J]. 模式识别与人工智能, 2012, 25(2): 220-224.
编辑 任吉慧
A Dynamic Tree Incremental Updating Method Based on Hadoop
YAN Yi-ming, GUO Xin
(School of Software and Service Outsourcing, Jishou University, Zhangjiajie 427000, China)
In order to deal with problems in true environment caused by data mining tasks with larger amount of data, complex processing and intensive computing, improve the traditional tree incremental updating mining efficiency, and change the existing algorithm of serial implementation methods, this paper proposes a dynamic tree incremental updating method on the basis of Hadoop. It introduces concepts concerning cloud computing, the cloud model, operating process and so on. Then, according to the Hadoop platform task scheduling random distribution strategy, a new dynamic cloud platform resource allocation algorithm is put forward in order to minimize the consumption cost. It designs a new tree incremental updating algorithm on the basis of cloud platform, and two parallel algorithms (DeleteFreqTree, FindNewTree) are proposed. Large number of experiments show that the paralleled algorithm is feasible, highly efficient, expandable, and the algorithm can mine mass tree data effectively.
data mining; database; cloud computing; concurrency control; frequent subtree; incremental updating
1000-3428(2014)03-0067-04
A
TP311.12
湖南省工业支撑计划基金资助项目(2012GK2006);湖南省教育厅科学研究基金资助项目(12C0291)。
颜一鸣(1976-),男,讲师,主研方向:数据挖掘;郭 鑫,讲师、硕士。
2013-02-28
2013-04-02 E-mail:yymboy@126.com
10.3969/j.issn.1000-3428.2014.03.014
