基于不确定性数据的频繁闭项集挖掘算法
2014-06-02章淑云张守志
章淑云,张守志
基于不确定性数据的频繁闭项集挖掘算法
章淑云,张守志
(复旦大学计算机科学技术学院,上海 200433)
对于不确定性数据,传统判断项集是否频繁的方法并不能准确表达项集的频繁性,同样对于大型数据,频繁项集显得庞大和冗余。针对上述不足,在水平挖掘算法Apriori的基础上,提出一种基于不确定性数据的频繁闭项集挖掘算法UFCIM。利用置信度概率表达项集频繁的准确性,置信度越高,项集为频繁的准确性也越高,且由于频繁闭项集是频繁项集的一种无损压缩表示,因此利用压缩形式的频繁闭项集替代庞大的频繁项集。实验结果表明,该算法能够快速地挖掘出不确定性数据中的频繁闭项集,在减少项集冗余的同时保证项集的准确性和完整性。
不确定性数据;频繁闭项集;数据挖掘;水平挖掘;置信度概率
1 概述
现实应用中经常出现噪声和不完整的数据,比较常见的应用有传感网络[1]和隐私保护[2]等数据挖掘应用,又如医院对于病人的诊断数据也存在许多不确定性因素。因此,如何对这些不确定性数据进行分析和挖掘成为了数据挖掘中的一个重要研究领域。
近年来,有许多关于不确定性数据的频繁模式挖掘的研究,其中有U-Apriori算法[3]、UF-tree算法[4]、UD-FP-tree算法[5]、U-Eclat算法[6]等,但其均采用项集概率分布的期望值定义频繁项集,即将期望支持度大于等于最小支持度阈值的项集定义为频繁项集。但这种对支持度的估计方法并未表示出其所估计的准确度,因此本文采用文献[7]提出的概率频繁项集定义,定义了项集的支持度分布,并用大于等于最小支持度阈值的支持度概率总和定义项集的频繁概率。传统意义上频繁闭项集是对频繁项集的一种压缩无损表示,从文献[7]中的概率频繁项集出发,文献[8]对概率频繁闭项集作出了进一步阐述,定义了项集概率支持度的最大频繁度,并用概率支持度定义频繁闭项集。本文从概率频繁项集和概率频繁闭项集出发,利用可能性世界模型表示不确定性数据库,根据概率频繁闭项集的定义,提出一种在不确定性数据中进行频繁闭项集挖掘的算法UFCIM (Uncertain Frequent Closed Itemsets Mining)。
2 相关知识
对于不确定性数据以及可能性世界模型,不同的文献给出了类似的定义[9-11]。本文采用文献[7]中的概率矩阵表示不确定性数据库。项集={1,2,…,x},事务集合={1,2,…,t},其中对于每一项,都有一个非零概率(,t)∈[0,1]与之对应,表示该项出现在事务t中的概率。不确定性数据库可用一个×的矩阵表示,其中(,)表示项x在事务t中存在的概率。例如={1,2,3},={1,2,3},项在事务中出现的概率(∈t)用二元组(,(∈t))表示,见表1。
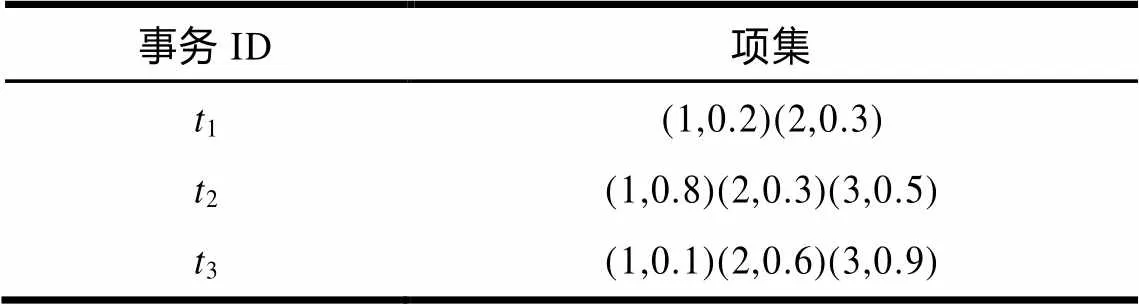
表1 不确定性数据库
概率(∈t)所对应概率矩阵为:

文献[7]中Bernecker证明项集的概率分布P()可以不经计算各个可能性世界存在的概率(w)所得,其中,为的子集;P()为的支持度为的概率。
定义1 假设P()为的支持度为的概率(简称支持度概率),则P()与可能性世界存在概率(w)无关的表示为:
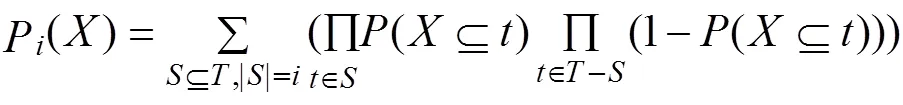
定义2P()为支持度为的概率,≥()为支持度至少为的概率:
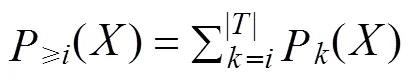
根据式(1),式(2)可转化为:
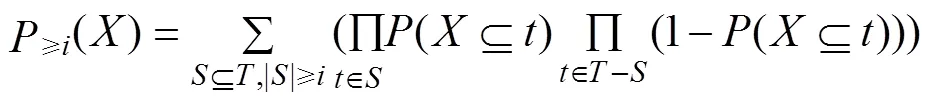
定义3 给定置信度阈值,最小支持度阈值,为概率频繁项集需要满足:
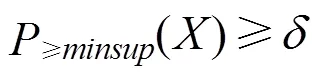
概率频繁项集的支持度大于等于最小支持度,且大于等于最小支持度的概率大于等于置信度。
定义4给定项集、不确定性事务数据库、置信度阈值,项集的概率支持度为:
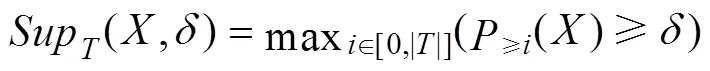
项集的概率支持度定义了满足支持度概率大于等于置信度的最大支持度。
定义5给定项集、不确定性事务数据库、置信度阈值、最小支持度,为频繁闭项集需满足2个 条件:
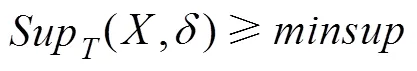
且不存在长度为||+1的的超集,使得下式成立:

式(6)中的条件保证项集为频繁项集,式(7)中的条件保证项集为闭项集。第2个条件为不存在的超集,()=(),但可证明满足式(7)中的条件即对所有的超集均成立,证明见文献[8]。
3 概率频繁闭项集UFCIM算法
3.1 概率支持度
由式(5)可看出,求解概率支持度需要计算项集支持度,满足≥()≥,由式(1)可看出,计算P()的复杂度为指数级。本文利用文献[12]中概率top-k查询的动态编程模式方法计算≥()。
定义6项集、支持度、事务中前个事务,项集在个事务中支持度大于等于的概率为:
(8)
图1表明动态计算模式算法能够在(||)时间复杂度下计算出项集支持度至少为的概率。其计算过程由下至上、由左至右。如图1所示,灰色区域为需要计算的概率值,图中每个方格表示概率值≥();详细计算过程可参考文献[8]。

图1 动态计算模式
将计算项集的支持度概率扩展到概率支持度中,即循环在支持度达到最小支持度(),且此时求得概率值大于等于置信度时并不终止,而是继续计算+1、+2的支持度概率,直至在该支持度下项集的支持度概率小于,返回当前支持度值-1。所得值为项集的概率支持度。概率支持度算法描述如下:
算法1概率支持度算法ProbSup
输入项集,置信度,最小支持度
输出项集的概率支持度
(1)ProbSup(Itemset X,float δ,int minsup):
(2)For j=0 to |T|
Foreach i in X
P[j]*=M[j][i]; //M为不确定数据库的概率矩阵,P为项集在事//务中出现的概率
(3)For i=0 to |T|
For j=i to |T|-minsup+i
if(i==0)
Matrix[i][j]=1;continue;//初始化矩阵的第1行
if(i==j)
Matrix[i][j-1]=0;//当i>j时,概率为0
Matrix[i][j]=matrix[i-1][j-1] * P[j] + matrix[i][j-1] * (1-P[j]);
End
if(matrix[i][j-1] <δ) //直至支持度概率小于置信度
Return i-1;
Return i-1;
以图1中概率矩阵对应的不确定性数据库为例,= {0,1,2},={0,1,2},以项集={0,1}为例,设=0.2,= 1;≥1,1(X)=1×[1][0]×[1][1]+0=0.8×0.3=0.24;继而计算出≥1,2()=0.285 6>;继续计算≥2,2()=0.014 4<,所以项集={0,1}的概率支持度为1。
3.2 UFCIM算法
上文介绍了概率支持度的计算方法,通过计算K-项集的概率支持度,找出频繁项集,即概率支持度大于等于最小支持度的项集;采用水平生成候选集的方法,生成K+1-项集并计算它们的概率支持度,找出K+1-频繁项集;将K-频繁项集与K+1-频繁闭项集一一比较,若有K+1-频繁闭项集的子集K-频繁项集与其支持度相等,将其舍去,最后输出K-频繁项集,其不存在K+1-频繁闭项集为其超集,且概率支持度相等。频繁闭项集的挖掘算法UFCIM描述如下:
算法2频繁闭项集挖掘算法UFCIM
输入,float,int//为初始项的集合,为置信//度阈值,为最小支持度
输出//频繁闭项集
Foreach Iiin I
Ii.MS = ProbSup(Ii,δ,minsup); //项集域包括概率支持度与项//集数组
if(Ii.MS ≥ minsup)
Lk.add(Ii);
End
Lk+1= AprioriGen_Order(Lk); //生成候选集
While(Lk+1.empty()== false)
Foreach X in Lk+1
X.MS = ProbSup(X,δ,minsup);
if(X.MS ≥ minsup)
FLk+1.add(X);
End
Foreach X in Lk
Flag = true;
Foreach Y in FLk+1
if(Y.contain(X) && Y.MS == X.MS)
Flag =false;
Break;
if(flag)
C.add(X);
End
End
Lk=FLk+1;
FLk+1.clear();
Lk+1= AprioriGen_Order(Lk);
End
Return C;
在上述算法中,I是初始项集合中的所有单项集的集合,首先计算各个单项集的概率支持度,将支持度存入项集的概率支持度域。将概率支持度大于等于最小支持度阈值的项集存入列表L,然后利用生成长度为2的候选集L+1,候选集生成方法与类似,但其复杂度远比低,因本文中项均用整数表示,算法扫描K-项集集合中的每2项(不重复),利用两顺序列表集合的并集操作生成候选项,遇到长度大于+1的项集及时退出,大大降低了时间复杂度。FL+1为当前K-频繁项集所生成的候选集K+1-频繁项集,对K-频繁项集一一检测,检查是否有K-频繁项集的超集为K+1-频繁项集且其支持度相等,从而输出频繁闭项集。
以图1对应的概率矩阵为例,={0,1,2},={0,1,2},=0.2,=1;利用3.1节中的计算概率支持度方法可计算出({0})=1,({1})=1,({2})=2,均大于等于最小支持度、生成长度为2的候选集{0,1},{0,2}, {1,2};计算得出({0,1})=1,({0,2})=1,({1,2})=1,均为频繁项集,与长度为1的频繁项集相比,可得只有项集{2}为频繁闭项集;再生成长度为3的候选集{0,1,2},计算得({0,1,2})=0不为频繁项集,因此所有2频繁项集均为频繁闭项集,最终频繁闭项集为{2},{0,1},{0,2},{1,2}。
4 实验结果与分析
本节对频繁闭项集算法UFCIM进行实验,并对实验结果进行分析。实验算法由C++语言编写,在VC6.0环境下编译运行,运行环境是Intel Core2 Duo 2.40 Hz CPU,2 GB内存,Windows7操作系统。
本文实验所用数据集来自文献[8],分别是mushroom、T10I4D100K、accidents、chess。所用数据集均可在http:// fimi.cs.helsinki.fi/data/中下载确定性数据库,使用Matlab R900b中的Beta分布函数,其中,参数分别为=5,=1,生成随机数,通常为0.8~1,对确定性数据库进行扫描,若该项存在于事务中,其概率值取,对于事务中不存在的项,其概率值取1-,实验证明这种概率分布更加接近现实中的不确定性数据库。图2分析了置信度为0.9时不同最小支持度/对运行时间的影响,图3分析了最小支持度=0.75×时不同置信度对运行时间的影响,图4分析了在/=0.75、置信度=0.9时数据集T10I4D100K中不同事务数对运行时间的影响。

图2 最小支持度与运行时间的关系
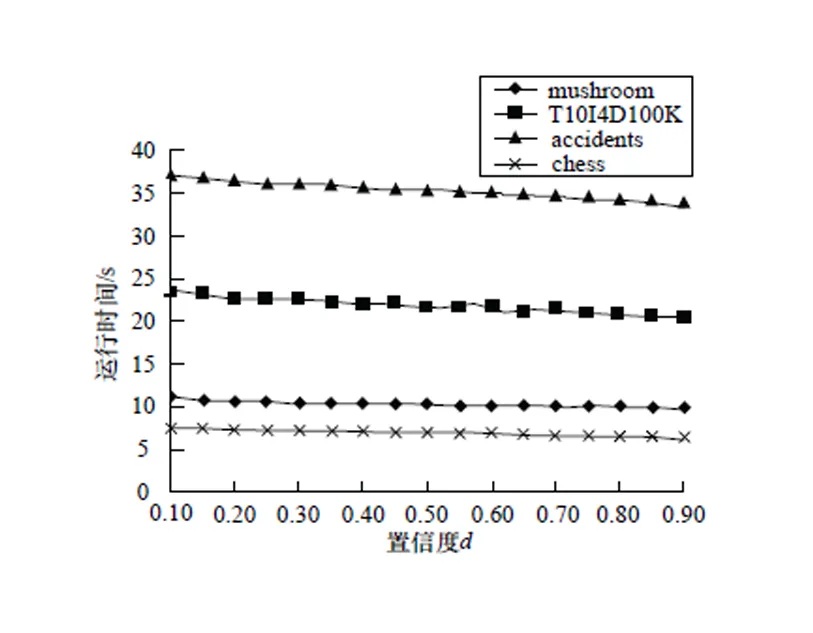
图3 置信度δ与运行时间的关系

图4 T10I4D100K中事务数与运行时间的关系
从图2中/对运行时间的影响可以看出,/与运行时间成指数关系。/比例值越低,意味着可生成更多频繁项集,从而生成更多候选集,生成候选集的时间与项集数成指数关系,所以比例值与运行时间呈指数关系。图3中显示了在/固定为0.75时,置信度与运行时间呈线性关系,因为支持度较高,生成的频繁项集在不同置信度下几乎没有差别,只是计算每个项集的支持度时循环执行的更多,线性增加了运行时间。图4中事务数与运行时间呈抛物线关系,与图3相似,增加的时间为计算概率支持度时,因而与运行时间呈抛物线关系。
5 结束语
本文扩展Apriori算法在不确定性数据挖掘中的应用,将其运用于不确定性数据中的频繁闭项集挖掘。但与一般不确定性数据频繁项集挖掘中所采用的数据表示和频繁项集定义不同,本文采用更精确的文献[7]中频繁项集的定义,进而定义频繁闭项集。本文算法UFCIM用于在不确定数据中挖掘频繁闭项集,通过实验分析了不同置信度、最小支持度、事务数对于运行时间的影响,表明算法UFCIM能有效地挖掘频繁闭项集。
[1] 戴晓华, 王 智, 蒋 鹏, 等. 无线传感器网络智能信息处理研究[J]. 传感技术学报; 2006, 9(1): 1-7.
[2] Evfimievski A, Srikant R, Agrawal R, et al. Privacy Preserving Mining of Association Rules[C]//Proc. of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton, Canada: [s. n.], 2002: 217-228.
[3] Chui C K, Kao B, Hung E. Mining Frequent Itemsets from Uncertain Data[C]//Proc. of the 11th Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin, Germany: Springer-Verlag, 2007: 47-58.
[4] Han Jiawei, Pei Jian, Yin Yiwen. Mining Frequent Patterns Without Candidate Generation[C]//Proc. of ACM SIGMOD International Conference on Management of Data. New York, USA: ACM Press, 2000: 1-12.
[5] 高 聪, 申德荣, 于 戈. 一种基于不确定数据的挖掘频繁集方法[J]. 计算机研究与发展, 2008, 45(z1): 71-76.
[6] Calders T, Carboni C, Goethals B. Efficient Pattern Mining of Uncertain Data with Sampling[C]//Proc. of the 14th Pacific- Asia Conference on Knowledge Discovery and Data Mining. Hyderabad, India: [s. n.], 2010: 480-487.
[7] Bernecker T, Kriegel H P, Renz M, et al. Probabilistic Fre- quent Itemset Mining in Uncertain Databases[C]//Proc. of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France: [s. n.], 2009: 119-128.
[8] Tang Peiyi, Peterson E A. Mining Probabilistic Frequent Closed Itemsets in Uncertain Databases[C]//Proc. of the 49th ACM Southeast Conference. Kennesaw, USA: [s. n.], 2011.
[9] Abiteboul S, Kanellakis P. On the Representation and Query- ing of Sets of Possible Worlds[C]//Proc. of ACM SIGMOD Conference on Management of Data. New York, USA: ACM Press, 1987: 34-48.
[10] Green T J, Tannen V. Models for Incomplete and Probabilistic Information[J]. Lecture Notes in Computer Science, 2006, 29(1): 17-24.
[11] Zhang Qin, Li Feifei, Yi Ke. Finding Frequent Items in Probabilistic Data[C]//Proc. of ACM SIGMOD International Conference on Management of Data. New York, USA: ACM Press, 2008: 819-832.
[12]Ke Yi, Li Feifei, Kollios G, et al. Efficient Processing of Top-K Queries in Uncertain Databases[C]//Proc. of the 24th Inter- national Conference on Data Engineering. Washington D. C., USA: IEEE Computer Society, 2009: 1406-1408.
编辑 任吉慧
Mining Algorithm of Frequent Closed Itemsets Based on Uncertain Data
ZHANG Shu-yun, ZHANG Shou-zhi
(School of Computer Science, Fudan University, Shanghai 200433, China)
For the uncertain data, traditional method of judging whether an itemset is frequent cannot express how close the estimate is, meanwhile frequent itemsets are large and redundant for large datasets. Regarding to the above two disadvantages, this paper proposes amining algorithm of frequent closed itemsets based on uncertain data called UFCIM to mine frequent closed itemsets from uncertain data according to frequent itemsets mining method from uncertain data, and it is based on level mining algorithm Apriori. It uses probability of confidence to express how close the estimate is, the larger that probability of confidence is, the itemsets are more likely to be frequent. Besides as frequent closed itemsets are compact and lossless representation of frequent itemsets, so it uses compacted frequent closed itemsets to take place of frequent itemsets which are of huge size. Experimental result shows the UFCIM algorithm can mine frequent closed itemsets effectively and quickly. It can reduce redundancy and meanwhile assure the accuracy and completeness of itemsets.
uncertain data; frequent closed itemsets; data mining; level mining; probability of confidence
1000-3428(2014)03-0051-04
A
TP311.12
章淑云(1989-),女,硕士研究生,主研方向:数据仓库,数据挖掘;张守志,副教授。
2012-12-10
2013-04-07 E-mail:10210240047@fudan.edu.cn
10.3969/j.issn.1000-3428.2014.03.010
