基于性能预测的推测多线程循环选择方法
2014-06-02赵银亮李玉祥冯博琴武万杰
刘 斌 赵银亮 韩 博 李玉祥 吉 烁 冯博琴 武万杰
基于性能预测的推测多线程循环选择方法
刘 斌 赵银亮*韩 博 李玉祥 吉 烁 冯博琴 武万杰
(西安交通大学计算机科学与技术系 西安 710049)
线程级推测(Thread-Level Speculation, TLS)是多核上一种加速串行程序的线程级自动并行化技术。循环具有规则的结构并在运行时占有大量的执行时间,因此循环是挖掘并行性的理想对象。然而,选择哪些循环并行才能提高程序的加速比是一个很难决定的问题。为了解决该问题,该文提出一种基于性能预测的循环选择方法。基于输入训练集获取程序预执行的剖析信息,同时结合各种推测因素,构建了循环结构的性能预测模型。预测结果定量评估了循环推测并行的加速比并决定该循环在运行时是否适合并行。实验结果表明,该文提出的方法能有效地预测循环并行时所蕴含的并行性,并依据预测结果准确地选择具有并行收益的循环推测并行,最终Olden基准测试集加速比性能平均提升了12.34%。
并行处理;线程级推测;循环选择;性能预测
1 引言
随着半导体按照摩尔定律的发展,处理器进入了多核时代,如何有效利用丰富的核资源成为当前研究的热点。当指令级并行在挖掘并行性方面遇到了瓶颈,线程级并行(Thread-Level Parallelism, TLP)逐渐成为更佳的选择,尤其适合于片上多处理器(Chip MultiProcessor, CMP)[1]。为了提升程序在CMP上的性能,大量非规则程序需要重构以便适合在多核上并行执行,从而提高程序的加速比性能。线程级推测(Thread-Level Speculation, TLS)作为线程级并行的一种重要方法,允许多个线程激进地并行执行以提高程序的加速比,较为典型的代表有Multiscalar[2], Hydra[3], POSH[4], Mitosis[5], DOMORE[6], SEED[7], DOE[8]和Prophet[9]。
循环具有规则的结构并且在程序执行时占有大量的时间,因此循环成为并行执行最理想的对象。目前,大量的研究关注循环并且从循环中提取多线程[10]。文献[11]结合数据和控制依赖提出一种误推测代价模型,并基于该模型对循环进行性能评估,然后对循环进行改造并选择合适的循环并行执行。与本文类似文献[11]也选择了具有收益的循环并行。与本文不同的是该方法仅考虑数据和控制依赖构建模型,而本文方法考虑了多种推测因素。文献[12]为Java语言提出一种动态循环选择框架。框架采用硬件运行系统提取依赖时间和推测状态等信息评估了循环的加速比性能。与本文相似的是对循环评估了循环的加速比并反向指导线程划分。不同之处在于该框架研究的是面向对象的Java程序,而本文研究的是非规则C语言程序,这两者程序的特征不同所引起的推测开销也就不同。文献[13]采用专家经验手工并行化了SPEC2000基准测试集。文献[13]的研究工作非常耗时,容易发生错误,而本文的研究工作是一种自动并行化的技术。
本文提出一种基于性能预测的循环选择方法。基于输入训练集多次预执行程序获取反映程序行为的剖析信息。综合考虑剖析信息和影响推测并行的各种因素,构建了循环推测并行时的性能预测模型,模型的预测结果决定了该循环是否进行推测并行。本文基于Prophet编译器实现了性能预测模型。使用Olden基准测试集进行了性能测试,并与传统方法进行了比较和分析。实验结果表明本文提出的预测模型能有效地预测循环中所蕴含的并行性,并准确地选择有收益的循环推测并行,最终Olden基准测试集加速比性能平均提升了12.34%。
2 执行模型
TLS将串行程序在多核上并行执行以提高程序的加速比,执行模型如图1所示,串行程序被一系列的线程激发点-准控制无关点(Spawning Point- Control Quasi-Independent Points, SP-CQIPs)指令对映射成多线程程序。同时按照串行语义顺序,在每一时刻只有一个线程提交数据到内存,该线程被称为确定线程,而其他线程为推测线程。每个推测线程由串行程序代码片段及预计算片段组成。预计算片段是由编译器根据切片技术生成的一小段代码,用来预测推测线程使用的live-ins(推测线程使用但并非由该线程定义的变量值)。如图1(a)所示,如果忽略SP-CQIPs指令对,推测多线程程序就转换成串行程序;如图1(b)所示,当程序执行到确定线程1中的SP时,如果有闲置核资源,将激发一个新推测线程2;当确定线程1执行到CQIP将验证直接后继线程2在预计算片段中使用的live-ins。若验证正确,则确定线程1提交执行结果,将核资源释放,该核可以执行其他的线程。然后将确定执行的权限传递给直接后继线程;若验证失败则会导致推测执行失败。当出现验证失败时,则撤销推测线程2,跳过预计算片段,串行执行此直接后继线程2,如图1(c)所示;当出现读后写(Read After Write, RAW)依赖违规时,如图1(d)所示,则在当前的状态下重新启动该线程。
3 性能预测模型
3.1 基本思想
在循环级并行中,现有的方法大多都采用静态、定性的方法进行性能评估。在本文中,结合程序的剖析信息和各种推测因素,提出一种定量预测并行性能的循环选择方法。首先,基于输入训练集获取程序在预执行时的剖析信息并以注释的形式添加到对应的SUIF中间文件(SUIF-IR)中。然后,综合剖析信息和推测因素,构建了一种性能预测模型。该模型力图更加精确地预测程序行为和定量地评估各种推测因素对加速比性能的影响,并利用预测结果评判推测执行性能的好坏程度,最终决定是否在程序运行时并行该循环。
3.2 剖析信息
程序剖析是通过收集程序过去运行时的信息,进而动态调整程序将来的执行。理论上讲,如果编译器能预测出精确的程序行为,它能产生出任何平台下并行性能最好的代码。然而实际上,编译器仅能获取部分精确的程序行为。为了提高程序行为的精确性,本文开发了Profiler剖析器,分析了程序集的输入特征,根据输入特征构造了基准程序的输入训练集。通过多次预执行程序捕获了程序运行时的剖析信息,为性能预测模型的构建提供了更为精确的程序行为。
Profiler的工作流程如图2所示,当一个程序指令被执行时,首先判断指令的类型,当指令为循环指令时,记录当前循环的迭代次数和动态指令数。那么循环的平均动态指令数为L= (L-1×(-1)+)/,其中L-1为上一次循环执行时的平均动态指令数。通过多次预执行程序,求其平均值可获取循环部分的剖析信息并以注释的形式标注在对应的SUIF-IR文件中。
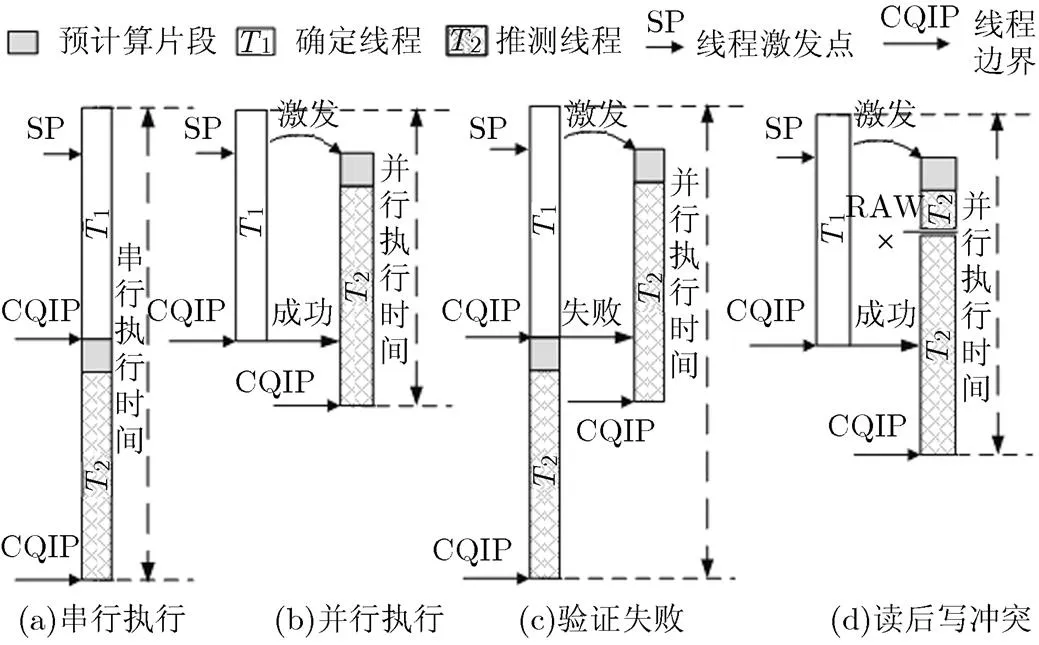
图1 推测多线程执行模型

图2 程序剖析器
3.3 推测并行影响因素
线程粒度、数据依赖、线程分发和激发距离是影响循环并行性能的关键影响因素。一般来说这些因素被综合考虑决定并行性能的好坏。
(1)线程粒度(thread size)是指一个线程的动态指令数。线程分发、线程启动与重启、线程冲突和线程间的通信会引起推测并行开销,所以线程粒度大小是影响推测性能的关键因素。线程粒度过小,推测执行中的各种开销将会抵消掉推测并行所带来的收益。线程粒度过大,线程间过多的控制和数据依赖将会导致线程冲突的概率增大,进而增加推测并行时的开销。
(2)数据依赖(data dependence)是指子线程中的指令引用了父线程中定义的变量。数据依赖距离通常用来刻画线程间依赖的程度。数据依赖距离是指线程推测并行时子线程执行时需要等待的指令数直到它所需要的数据被父线程产生。如果数据依赖距离过小子线程中需要的值还未由父线程产生,会引发额外的推测代价。
(3)线程分发(thread dispatch)是指当激发一个新的线程时,需要分发一个处理器单元执行该线程。线程分发需要复制父线程堆栈的参数和寄存器里的数值,这需要占用一定的开销。
(4)激发距离是指在父线程中定义的SP点到子线程开始CQIP点之间动态指令数。如果激发距离过长,子线程执行过程中使用的变量还未产生,将会导致数据推测失败。如果激发距离过小,推测执行所引起的各种开销将抵消掉推测并行所获得的收益。
3.4 性能预测

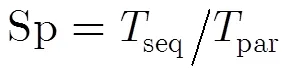
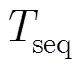



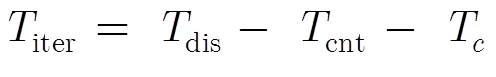
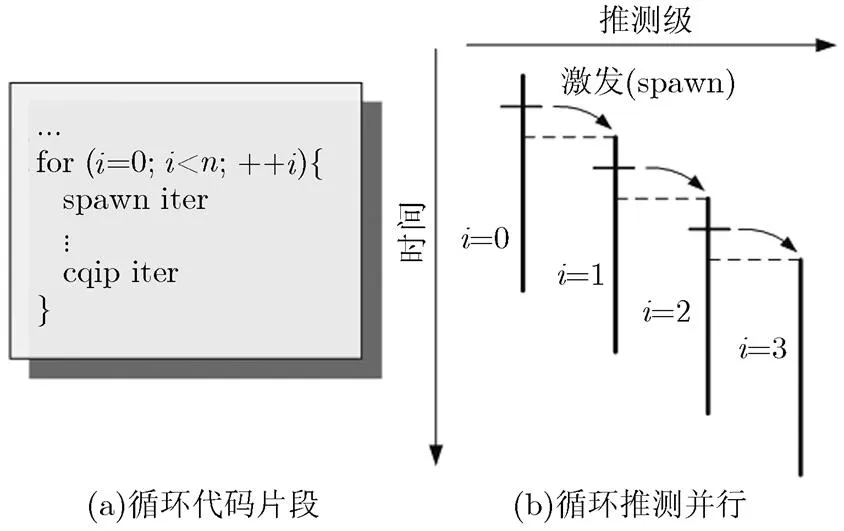
图3 循环激发示意图
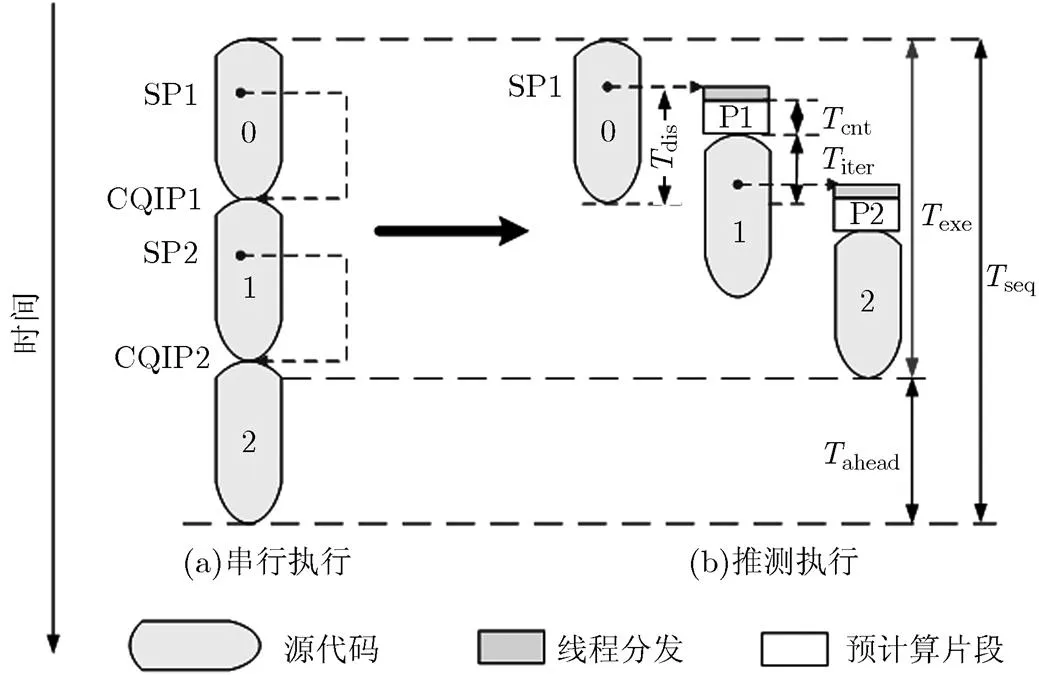
图4 推测执行的加速效果
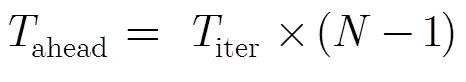
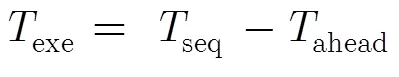


由式(2),式(6)和式(7)最终得到循环推测并行时预期加速比为
4 实验结果和性能分析
本文基于SUIF/MACHSUIF[14]开发了Prophet编译器[15],并在编译器中实现了性能预测的循环选择方法。同时在Prophet模拟器[9]中验证了方法的有效性,Prophet模拟器是基于Tomasulo[16]算法实现的超标量流水线4核处理器。最后选用了Olden 基准程序集[17]中的子集测试了本文提出的评估方法。
4.1 剖析信息统计
通过分析Olden程序集的输入特征,程序的输入参数个数不同但都为整型。根据均匀分布随机函数构造了程序的训练输入集,采用渐进式预执行来获取程序的剖析信息。随着程序预执行次数的增加,程序的剖析信息在程序某次执行之后趋于稳定。本文希望在稳定点之后停止预执行,最终每个程序的预执行次数如表1所示,剖析信息统计如图6(a)所示。从图6(a)可以看出程序预执行后所获取的剖析信息,其中横轴代表了循环的平均迭代次数,纵轴代表了循环平均迭代体大小。图6(b)为图6(a)左下角局域放大图,从中可以看出Olden中89.16%的循环具有中小规模。同时,7.23%的循环是比较大的循环体。从表1可以看出,每个程序预执行次数各不相同,程序mst的执行次数最多,高达1098次,而程序bh仅执行了106次。经过分析,主要原因是每个程序本身的特征不同,从而导致循环剖析信息达到稳定状态时所执行的次数也就不同。

表1 Olden基准测试集剖析信息统计
图6 Olden基准测试集循环剖析信息
理论上讲,预执行次数越多,所构建的预测模型也就越准确。然而,由于时间的限制,再多的预执行也无法覆盖所有的执行路径。这种情况说明剖析方法在实现过程中,剖析信息有可能不够完全精确。然而,随着预执行次数的不断增加,这些输入的剖析信息会变得更为精确,从而不断提高预测模型的精确程度。
4.2 加速比性能比较
图7给出了基于传统方法[18]和本文改进方法加速比性能的实验数据。实验结果显示,大多数Olden基准测试集的加速比性能都有一定程度的提升。特别是程序em3d, health和bh性能提升较为显著,而程序mst和tsp 的加速比性能未发生改变。为了定量分析,定义性能增长率为

图7 加速比性能比较
表2统计了Olden测试集基于传统的方法和改进的方法在Prophet模拟器中产生的动态信息及性能增长率。由表2中的最右列可以看出,与传统的方法相比,本文提出的方法使Olden基准测试集的增长率变化范围由0到107.61%,其平均增长率可达12.34%。实验数据显示,本文的改进方法能充分地挖掘程序中的并行性同时获得了更好的性能改善。此外,表2和表3分别统计了Prophet系统产生的动态线程统计信息。
程序em3d性能提升高达107.61%,原因在于程序em3d中循环蕴含的并行性较大,同时本文采用性能预测方法并行了8个具有并行收益的循环,而传统方法仅依靠启发式并行了4个外层循环(表2)。实验数据表明改进方法从程序em3d中激发出的线程数目是传统方法的2.41倍,同时改进方法保证了程序em3d激发成功率也有一定程度的提高,最终本文方法允许更多的推测线程参与并行从而提高了加速比性能。程序bh包含83个循环,是循环数最多的程序。传统方法仅并行了30个外层循环,本文方法选取具有并行收益的69个循环并行执行,并行的循环数量占循环总数的83.13%而传统方法仅占36.14%(表2)。改进方法虽然导致线程执行的成功率下降,但并行更多的循环使成功激发的线程数目却增加了,因此性能提升了3.16%。由表2中数据可以看出,程序health和power 执行行为与程序bh相似。本文方法为这两个程序分别选取了9个和13个具有并行收益的循环推测并行。虽然激发成功率都降低了(表2),但成功激发的线程数目增加了,其加速比性能各自提升了6.39%和0.93%。实验结果表明本文方法能激发更多的推测线程参与并行从而提高程序的加速比性能。
程序voronoi有18个循环体,但循环较小同时蕴含的并行有限。由表2可见,相比传统方法,虽然本文方法并行循环数增加了1个,但程序voronoi成功激发的线程数目与传统方法几乎相近,所以性能提升了,但提升的程度较为有限。程序mst和tsp加速比性能没有发生任何变化。对于程序mst,由表2可见,循环体数有12个,传统方法和本文的改进方法都选取了6个循环并行。虽然并行的循环数相同,但本文改进方法选择了具有并行收益的循环和传统方法所选择的最外层循环并不相同,最终导致成功激发的线程数目相差不大。同样,针对程序tsp,改进方法选取了5个循环并行化。由表2中可见,虽然激发的线程数目增加了,但是相应的线程激发的成功率却降低了,结果显示成功激发的线程数目和传统方法激发的线程数基本一样,由此可见,加速比性能不仅与线程数目相关而且还与每个线程对并行性能的贡献相关。最终由于本文方法所获取的收益与传统方法所获取的收益一致导致性能未发生变化。因此程序mst和tsp的加速比性能保持了原来的性能。

表2 Olden基准测试集动态信息统计
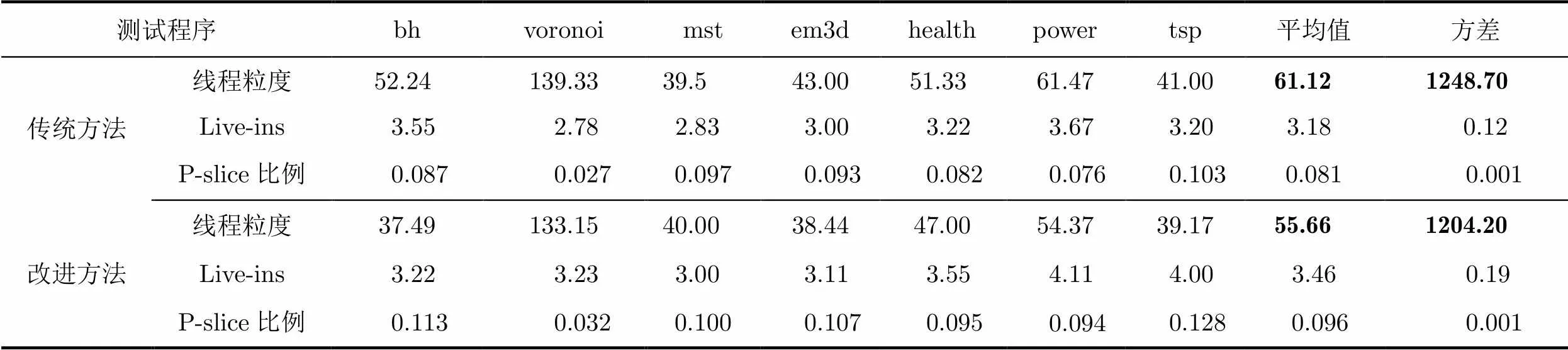
表3 Olden基准测试集线程信息统计
改进方法线程粒度平均值与方差均小于传统方法(表3),说明Olden基准测试集更适合细粒度并行。同时,改进方法产生的Live-ins变量比传统方法要多。实验结果表明本文方法有效的减少了推测并行时的开销,提升了有效工作时间比例,从而提高了程序的加速比性能。
5 结束语
该文提出和验证了一种基于性能预测的循环选择方法。该文主要创新在于:(1)基于程序的输入训练集获取了程序预执行的剖析信息,相比静态分析方法更加精确地预测了程序执行行为。(2)研究了影响线程级推测的关键因素。(3)提出一种性能预测模型。基于性能预测Olden基准测试集加速比性能平均提升了12.34%。实验表明,该文提出的性能预测方法能够有效地评估循环推测并行时所蕴含的并行性,并依据评估结果选择具有并行收益的循环推测并行从而提高程序的加速比性能。
[1] Yang L and Zhai A. Dynamically dispatching speculative threads to improve sequential execution[J]., 2012, 9(3): 13:1-13:31.
[2] Vijaykumar T N and Sohi G S. Task selection for a multiscalar processor[C]. Proceedings of the 31st Annual ACM/IEEE International Symposium on Microarchitecture, Dallas, 1998: 81-92.
[3] Hammond L, Hubbert B A, Siu M,The stanford hydra cmp[J]., 2000, 20(2): 71-84.
[4] Liu W, Tuck J, Ceze L,POSH: a TLS compiler that exploits program structure[C]. Proceedings of the 8th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, New York, 2006: 158-167.
[5] Madriles C, García-Quiñones C, Sánchez J,Mitosis: a speculative multithreaded processor based on precomputation slices[J]., 2008, 19(7): 914-925.
[6] Jialu H, Jablin T B, Beard S R,Automatically exploiting cross-invocation parallelism using runtime information[C]. Proceedings of the 2013 IEEE/ACM International Symposium on Code Generation and Optimization, Shenzhen, 2013: 1-11.
[7] Gao L, Li L, Xue J,SEED: a statically greedy and dynamically adaptive approach for speculative loop execution[J]., 2013, 62(5): 1004-1016.
[8] Sharafeddine M, Jothi K, and Akkary H. Disjoint out-of-order execution processor[J]., 2012, 9(3): 19:1-19:32.
[9] 宋少龙, 赵银亮, 冯博琴, 等. 支持推测多线程的扩展多核模拟器Prophet+[J]. 西安交通大学学报, 2010, 44(10): 13-17.
Song Shao-long, Zhao Yin-liang, Feng Bo-qin,Prophet+: an extended multicore simulator for speculative multithreading[J]., 2010, 44(10): 13-17.
[10] Wang S Y, Yew P C, and Zhai A. Code transformations for enhancing the performance of speculatively parallel threads[J]., 2012, 21(2): 1-23,
[11] Du Z H, Lim C C, Li X F,A cost-driven compilation framework for speculative parallelization of sequential programs[J]., 2004, 39(6): 71-81.
[12] Chen M and Olukotun K. TEST: a tracer for extracting speculative threads[C]. Proceedings of the 2003 International Symposium on Code Generation and Optimization, San Francisco, 2003: 301-312.
[13] Prabhu M K and Olukotun K. Exposing speculative thread parallelism in SPEC2000[C]. Proceedings of the 10th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Chicago, 2005: 142-152.
[14] Smith M D and Holloway G. An introduction to machine suif and its portable libraries for analysis and optimization[OL]. http://www.eecs.harvard.edu/hube/software/nci/overview. html, 2013.
[15] Chen Z, Zhao Y L, Pan X Y,.. An Overview of Prophet[M]. Berlin: German, Springer, 2009: 396-407.
[16] Hennessy J L and Patterson D A. Computer Architecture: A Quantitative Approach [M]. Amsterdam, Elsevier, 2012: 176-183.
[17] Carlisle M C, and Rogers A. Software caching and computation migration in olden[J]., 1996, 38(2): 248-255.
[18] Pan X Y, Zhao Y L, Chen Z,A thread partitioning method for speculative multithreading[C]. Proceedings of the 8th International Conference on Scalable Computing and Communications,Piscataway, 2009: 285-290.
刘 斌: 男,1981年生,博士生,研究方向为并行计算与机器学习.
赵银亮: 男,1960年生,教授,博士生导师,研究方向为程序语言与编译系统、大数据并行处理及挖掘.
韩 博: 男,1975年生,高级工程师,研究领域为软件编程方法学、信息管理学.
A Loop Selection Approach Based on Performance Prediction for Speculative Multithreading
Liu Bin Zhao Yin-liang Han Bo Li Yu-xiang Ji Shuo Feng Bo-qin Wu Wan-jie
(,’,’710049,)
Thread-Level Speculation (TLS) is a thread-level automatic parallelization technique to accelerate sequential programs on multi-core. Loops are usually regular structures and programs spent significant amounts of time executing them, thus loops are ideal candidates for exploiting the parallelism of programs. However, it is difficult to decide which set of loops should be parallelized to improve overall program performance. In order to solve the problem, this paper proposes a loop selection approach based on performance prediction. Basing on the input training set, the paper gathers profiling information during program pre-execution. Combining profiling information associated with the program and various speculative execution factors, the paper establishes a performance prediction model for loops. Then, based on the result of prediction, the paper can quantitatively estimate the speedup of loops and decide which loops should be parallelized on runtime. The experimental results show that the proposed approach effectively predicts the parallelism of loops when speculative execution and accurately selects beneficial loops for speculative parallelization according to the predicted results, finally Olden benchmarks reach 12.34% speedup performance improvement on average speedup.
Parallel processing; Thread-Level Speculation (TLS); Loop selection; Performance prediction
TP314
A
1009-5896(2014)11-2768-07
10.3724/SP.J.1146.2013.01879
赵银亮 zhaoy@mail.xjtu.edu.cn
2013-12-02收到,2014-03-21改回
国家自然科学基金(61173040),国家“863”计划项目(2012AA011003)和博士学科点专项科研基金(20130201110012)资助课题
