藏文组字部件的自动识别与字排序研究
2014-04-28才华
才华
(西藏大学藏文信息技术研究中心 西藏拉萨 850000)
藏文组字部件的自动识别与字排序研究
才华
(西藏大学藏文信息技术研究中心 西藏拉萨 850000)
藏文字有着独特的构字规则,组字部件的自动识别在藏文字、词、句层面的信息化处理有重要的应用。文章提出的藏文字部件自动识别方法理念为,现代藏文字按其第一个部件字符的不同分成5种结构类型,每一种类型又按其字长分为若干个子类,在每个子类中定义各字的部件识别算法,最后在藏文组字部件识别的基础上,给每个部件赋予序值,实现藏文字的有效排序。
藏文信息处理;构字部件;字符序值;字排序
引言
微软公司以叠置引擎和Open Type字库技术为基础,于2007年推出了基于藏文国际标准编码Unicode字符动态组合的藏文系统。该系统支持与藏文书写方式相一致的输入法,并能解决国内其他藏文系统普遍存在的缺字问题,[1]该系统成为藏文电子资源及藏文应用软件开发的主流平台,基于该系统的藏文字及其组字部件的自动识别,是藏文字、词层面信息化研究的一项基础工作。根据现代藏文文法,揭示并实现组字部件的自动识别对藏文字、词、句法层面的信息化有着重要的作用。
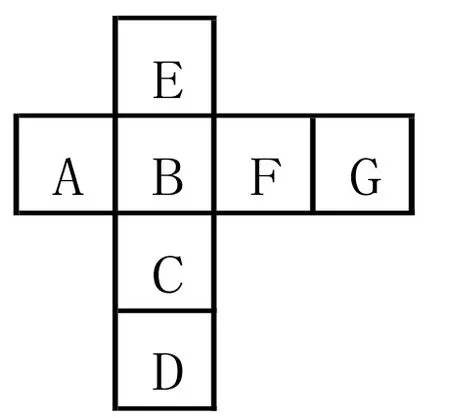
图 1 典型的藏文字结构
1 Unicode藏文字结构
藏语为单音节语种,属拼音文字。现代藏文有30个辅音字母,4个元音字母。图1为典型的藏文字结构图。
藏文字由一到七个不同数量的部件字符纵横叠加组合而构成,出现在不同位置上的部件字符有着确定的数量及字形。[2]图1中,A、B、C、D、F、G分别代表字部件中辅音字符出现的位置及与之对应的辅音字符集,依次叫做前加字符、上加字符、基本字符、下加字符、后加字符及再后加字符;E代表元音出现的位置,元音字符只能附着在某个基本字符或叠加字的上下部分,不能单独成字;英文字母的顺序代表了藏文字的拼读与书写顺序。
在Unicode或小字符集编码体系中,藏文字是以纵横动态组合叠加技术而生成的。如平面字繿軟繳纍的编码为0X0F56+0X0F66+0X0F92+0X0FB2+0X0F72+0X0F42+0X0F66,这完全符合藏文所固有的前加字符、上加字符、基本字符、下加字符、元音字符、后加字符、再后加字符这样的拼读与书写顺序。
2 藏文字字型结构统计
从字型结构来讲,现代藏文字的数量是非常有限的。据统计,现代藏文字所具有的字型结构共有45种[3]。表1中,把45种字型结构按照藏文字的部件数量(字长)又分为7个组。

表1 藏文字字型结构统计
2.1 藏文字型结构的分类
在拼读、书写或编码任意一个藏文字的时候,第一个组字部件只能是前加字符,上加字符或基本字符。即,藏文字中的元音字符、下加字符、后加字符及再后加字符等只能充当字的第二个或之后的结构部件。所以,除了上述的字长分类之外,还可以根据字的第一个组字部件(字符或编码)进一步细分现代藏文的字型结构。
在30个藏文辅音字母中,?等22个辅音字母既不能充当前加字,也不能当上加字。因此,如果发现当前字的第一个部件是上述字母时,就可以肯定此部件就是当前字的基本字符。据统计,发现该类字的字型结构仅有11种,最长字长为5个字符,如表2所示。根据这样的分类,发现藏文22个辅音字符在以第一个组字部件参与组字时,其字型结构只有11种,占现代藏文字型总数的24.4%。
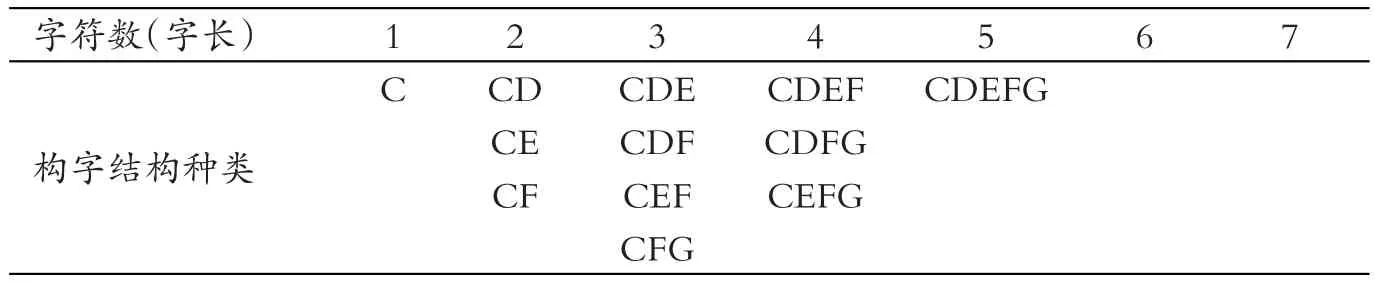
表2 第一个构字部件为基本字符的字型结构
2.1.2 第一个部件为繳的字型结构
字母繳可以以基本字符的身份,亦可以以前加字符的身份参与藏文字的组字结构中。但是,繳作为前加字符,所组成的字型中不会出现上下叠加的结构。如表3所示,有前加部件A的组字结构中,就不会出现上加部件B或下加部件D。此类字型占字型总数的35.6%。
表3 第一个部件为的字型结构

表3 第一个部件为的字型结构
字符数(字长)1 C 234567 CD CE CF ACE ACF CDE CDF CEF ACEF ACFG CDEF CDFG CEFG ACEFG CDEFG构字种类
2.1.3 第一个部件为繻་纀་纈的字型结构
跟繳一样,繻་纀་纈3个辅音字母出现在当前字的第一个构字部件位置上,可以看作字的基本字符或前加字符。但是,它们作为字的前加成分,所组成的字中不会出现带有上加部件的字型结构。如表4所示,此类组字结构中没有上加和下加部件B。此类结构占总字型结构的51.1%。
表4 第一个部件为的字型结构

表4 第一个部件为的字型结构
字符数(字长)1 C 234567 CD CE CF ACDEFG构字种类ACD ACE ACF CDE CDF CEF CFG ACDE ACDF ACEF ACFG CDEF CDFG CEFG ACDEF ACDFG ACEFG CDEFG
2.1.4 第一个部件为繿的字结构
因为第一个组字部件为字母繿的字结构涵盖了藏文的全部字型,所以这种类型的组字结构与表2相同。
2.2 Unicode组字部件的识别算法
Unicode藏文字的编码次序与藏文的拼读、书写顺序一致。因此,实现Unicode或小字符集藏文字的部件自动识别,要对识别的当前字进行“第一个组字部件的判断”和“字长计算”,根据字的“第一个组字部件”和“字长”,定位当前字可能的字型结构列表。最后根据该列表的具体识别算法可以筛选出唯一的字型结构。
表5 第一个部件字符为的字型结构
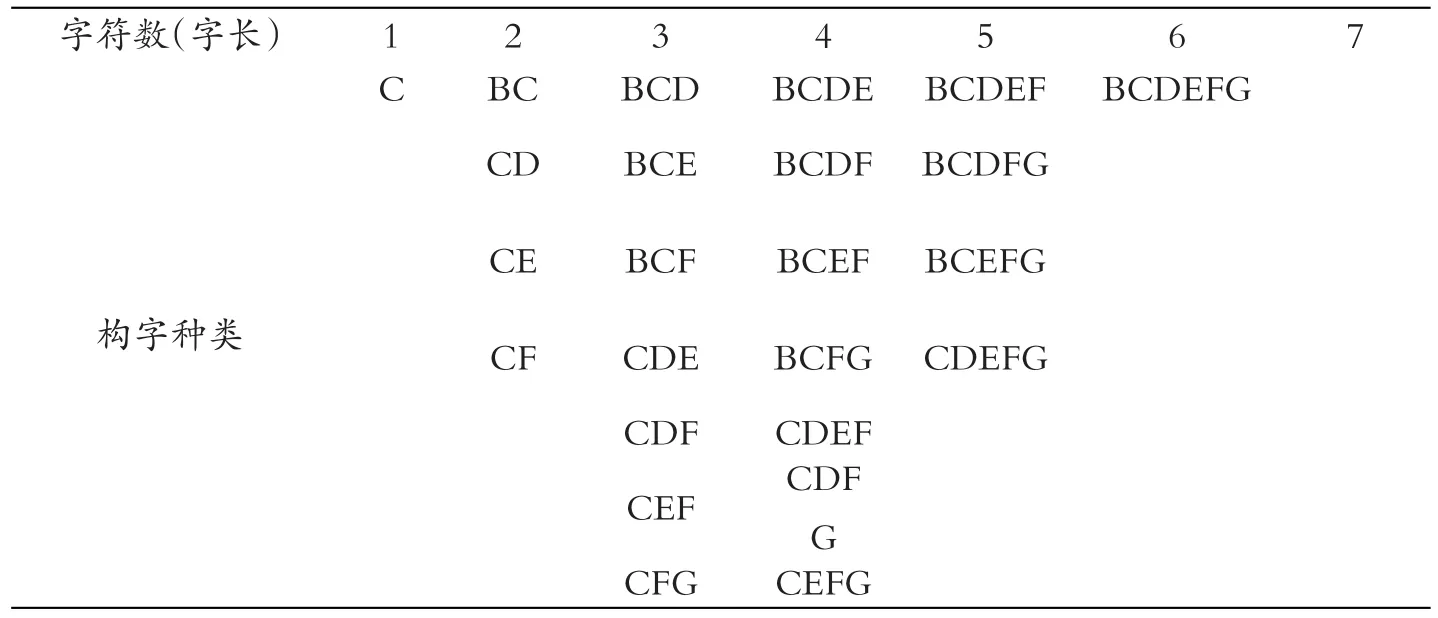
表5 第一个部件字符为的字型结构
字符数(字长)1 C 234567 BC CD CE CF BCD BCE BCF CDE CDF CEF CFG BCDE BCDF BCEF BCFG CDEF CDF G CEFG BCDEF BCDFG BCEFG CDEFG BCDEFG构字种类
①“贌繴”字的第一个字符部件是“繱”,字长为4个字节。因此,该字的字型结构就落在表3的第4列表中。
② 引用表3的第4列所对应的识别算法,就能得出其字型结构为:CDEF。
{if第二个字符为元音
字型结果:CEFG
else
if第三个字符为元音
输出字型结构:CDEF else输出的字型结构:CDFG }
3 现代藏文字的自动排序方法
由于藏文编码的不等长和其构字复杂性,藏文字的自动排序不像汉文和英文一样简单。传统藏文字词典都以30个字母顺序为主排序,但在同一基本字母下的内部排序上存在着明显的差异。1979年由青海民族出版社出版发行的《新编藏文字典》是传统藏文词典中的代表性出版物,使用量很大。在略去后加字和元音对字排序的影响下,《新编藏文字典》中字是以基字、下加叠字、前加字+基字、前加字+下加叠字、上加叠字、上下叠字、前加字+上加叠字、前加字+上下叠字的方式排序[4],其中带有前加字的字符分别出现在两个不相干的排序段上,整个排序没有明显的分界点。为此,文献[5]引入了字结构序的概念,并在前加字位增设一个结构辨识位来实现与字典相一致的自动排序。
本文对该字典所有基本字母的内部做了一种统一而合理的调整,提出一种形式简便,易查找的字排序方法。仅仅把带有前加字符的两段字集中在一起,即以基字、下加叠字、上加叠字、上下叠字、前加字+基字、前加字+下加叠字、前加字+上加叠字、前加字+上下叠字的模式对词典音节字重新编排。这样字序不仅形式简单,而且有序可循,所有音节字都以前加字符为界一分为二,容易被用户查找。以基本字母繱为例,就是把6至12之间的字原封不动地移到19之前,如表6所示。
表6 基本字母“”内部的排序调整

表6 基本字母“”内部的排序调整
调整后调整前1 2 3456789繱 轡 贁 贉贐繻繱繿贁 繿贕10 11 12 13 14 15 16 17 18繿贕繿贉繿贜 繿贜繿贐19 20 21 22 23繿罜繿罤繿罬罤罬繻繱19 20 21 22 23繿罜繿罤繿罬繻贁繻贉繿繱繳贕贜躛罜 罤 罬1 2 3456789繱 轡 贁 贉贐贕贜 躛 罜10 11 12 13 14 15 16 17 18繻贁繻贉繿繱繳繿贁繿贉繿贐
对现代藏文的每个基本字母内部排序都做上述统一的调整后,藏文字的排序模型就可以简化为5个构字部件按优先级线性排成的一组数序列:Sequence=XiYjZk,lLmMn。其中,Xi代表基本部首位上的字符值,Xi=i,i={1 ,2,3,…,30},分别是30个辅音字母的顺序代码;Yj代表前加部首位上的字符值,Yj=j,j={1 ,2,3,4,5} ,分别是5个前加字母的顺序代码;Lm代表元音位上的字符序值,Lm=m,m={1 ,2,3,4},分别是4个元音字母的顺序代码。Mn代表后加部首位上的字符序值(包括传统意义的后加字母、再后加字母及少量其他字),Mn=n,n={0 ,1,2,…16},分别是后加部首字母的顺序代码,如
表7所示。

表7 后加部件字符及其赋值
Zkl代表上下部首位上的字符组合序值,Zkl=kl,k=(0,1,2,3),分别是上加字母的顺序代码,而l=(0,1,2,…,7)是下加字母(包括下加字母、下加字母组合以及能充当下加字符的其他字母)的顺序代码,如表8所示。

表8 叠加部件字符及其赋值
k的每个元素原则上可以和l的各元素进行左结合,但符合藏文正字法的实际组合现象并不多[6]。
4 结论
综上所述,把所有的藏文音节字都可以看作5位空间的不同向量。通过字部件识别器,可以知道每个向量的分量。给字的每个分量赋予各自的序值后,就可以求出向量的大小。最后根据向量的大小(字序值)排序,就能自动完成字的排序问题(见表9)。
[1]江荻,龙从军.藏文字符研究[M].北京:社会科学文献出版社,2010:24-35.
[2]土弥三菩扎.西藏文法四种合编[M].北京:民族出版社,2005:17-25.
[3]高定国,龚育昌.现代藏文字全集的属性统计研究[J].中文信息学报,2005(1):71-75.
[4]新编藏文字典编写组.新编藏文字典[M].西宁:青海民族出版社,1989:2-38.
[5]江荻,康才.书面藏语排序的数学模型及算法[J].计算机学报,2004(4):524-529.
[6]才华,普布卓玛.试提一种新的藏文音节字排序模型[J].西藏科技,2012(1):69-71.
[7]艾金勇,于洪志,等.藏文字形结构计量统计分析[J].计算机应用,2009(7):2029-3031.
[8]于洪志.计算机藏文编码概况[J].西北民族学院学报(自然科学版),1999(3):15-19.

表9 藏文字的自动排序试验结果
[][]
Research on the Automatic Recognition and Sorting of Tibetan Word Components on the Unicode
Tshedpal
(Tibetan Information Technology Engineering Research Center,Tibet University,Lhasa 850000,Tibet)
Tibetan words have unique structure rules.The automatic recognition and sorting of word components has an important application in the information processing of various Tibetan word components such as character,word and sentence-level on the Unicode.In the present paper,according to the first component of Tibetan character,the Tibetan word structure can be divided into 5 categories.Each of word structure has been divided into several subcategories by the length of words.A recognition algorithm was defined for each word components in each subcategory.The ordinal value was given to each component of character based on the word component recognition to realizes sorting of Tibetan word efficiently.
Tibetan information processing;Tibetan word component;ordinal value of character;word sorting
TP391.1
A
1005-5738(2014)02-081-06
[责任编辑:索郎桑姆]
2014-08-27
2013年度西藏大学青年科研培育基金项目“Unicode藏文分词相关技术研究”阶段性成果,项目号:ZDPJZK201314
才华,男,藏族,青海尖扎人,西藏大学藏文信息研究中心博士研究生,西藏大学图书馆与现代教育技术中心讲师,主要研究方向为藏文信息处理。
