基于K均值聚类的高校图书馆勤工助学招聘
2014-04-18孙雅楠顾建新
●孙雅楠,顾建新
(东南大学 情报科学技术研究所,南京 211189)
1 现行高校图书馆勤工助学招聘存在问题
勤工助学工作作为高校图书馆人力资源的一部分正在日益规范化、制度化。员工的招聘与选拔,是人力资源管理的开端,所以做好图书馆勤工助学招聘工作是图书馆人力资源管理的重要部分。现行的高校图书馆勤工助学招聘工作,基本是由学生向图书馆递交申请书,图书馆调查学生家庭情况后,优先录取贫困学生,进行简单面试,根据其表现择优录取,录取的学生分配给缺人的部门。在这个过程中,存在两个问题:一方面,由于申请勤工助学的学生人数逐渐增加,面试过程中若没有科学的记录和比对系统支持,可能会由于横向比较失真,导致不公平现象的发生;另一方面,忽略了学生的个性与岗位的适应性,岗位分配经验化。传统的勤工助学招聘是基于每个学生的初始能力差别不大的假设上,对不同岗位的学生进行相应培训以适应岗位需求,但忽视了每个岗位对学生初始能力的个性需求。
为了解决以上问题,本文利用SPSS统计软件的聚类分析方法,对高校图书馆的招聘数据进行科学处理,方便各个岗位个性化的择优录取,对改进图书馆的招聘工作,促使勤工助学岗位的招聘和安排更加公
平公正、科学合理。
2 基于K均值聚类的勤工助学招聘
2.1 聚类方法和K均值聚类
聚类分析就是将研究对象按照多个方面的特征进行综合分类的一种统计方法。该方法通过将一个数据集划分为若干组或类,并使得同一个组内的数据对象具有较高的相似度,而不同组内的数据对象则是不相似的。[1]K均值聚类方法是由MacQueen提出的解决聚类分析问题的一种经典算法,该算法具有原理简单、速度快及能有效地处理大数据库等优点,现已广泛应用于数据挖掘和知识发现领域中。
2.2 K均值聚类应用于招聘工作的基本思路
K均值聚类方法应用于招聘工作,需要步骤如下。[2]
(1)对应聘学生集合X={x1,x2,…,xn},根据岗位能力需求等因素指派该集合中所有学生到k个类中来获得初始聚类中心cj(I),I=1,j=1,2,…,k。
(2)计算每个应聘学生xi到每个聚类中心的距离D(xi,cj(I)),其中I=1,2,…,n;j=1,2,…,k。如果满足D(xi,cj(I))=min{D(xi,cm(I))},m=1,2,…,k,则应聘学生xi∈Cj,表示该学生归属于第j类岗位。在该步骤中,距离的计算公式可采用欧氏距离,其定义如下:

其中:Xik表示第i个学生的第k个指标的观测值
Xjk表示第j个学生的第k个指标的观测值
dij表示第i个学生与第j个学生之间的欧氏距离
依次求出任何两个点的距离系数dij(i,j=1,2,…,n)以后,则可形成一个距离矩阵:
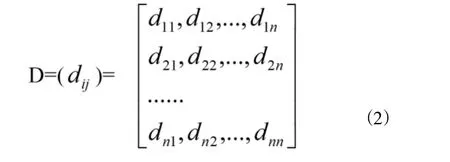
若dij越小,那么第i与j两个样品之间的性质就越接近。性质接近的样品就可以或为一类。
(3)根据新的应聘学生划分情况,计算k个新的聚类中心 ,其中nj是类别Cj中应聘学生的个数,x'是划分到Cj中的数据元素。
(4)判断Cj(I+1)是否等于Cj(I)或者误差平方和(SSE)是否变化,若不相等或者SSE变化,则I=I+1,返回到步骤(2);若果相等或者SSE不变化,则完成了应聘学生的分类。
3 实例分析——以东南大学图书馆勤工助学招聘为例
3.1 招聘流程设计
东南大学李文正图书馆勤工助学招聘岗位有4个部门,分别是:采编部、流通阅览部、信息咨询部及系统与数字化建设部。现拟向本科一、二、三年级贫困生招聘16名勤工助学学生,根据实际招聘数据比例,分配到各个岗位分别为:(1)信息咨询部4人;(2)系统与数字化建设部5人;(3)流通阅览部5人;(4)文献采编部2人。
具体的招聘办法和程序如下。
(1)各年级推选。本科一、二、三年级根据学生的家庭情况和平时表现,共推选30人。
(2)笔试筛选。以《东南大学图书馆使用指南》中的基本内容作为考试范围。根据考试分数的高低按1:1.25的比例,选择20名学生进入第二阶段的考试。
(3)面试评分。采访图书馆各部门勤工助学管理负责人得到对学生助理四个维度的要求,分别为时间匹配度、计算机水平、应变能力、身体素质。选择各部门老师组成招聘小组,根据招聘岗位对人员素质的要求,对进入面试考核阶段的学生从上述四个维度进行考查,给出评分。
(4)综合考虑笔试、面试成绩,设计个性化方案,将合适人选分配到各个部门。[3]
3.2 利用SPSS统计软件的K-Means Cluster方法对应聘学生进行聚类分析
为了简化计算过程,提高聚类分析结果的准确性,采用SPSS 16.0软件来取代繁杂的手工迭代。将20名学生的成绩输入SPSS进行聚类分析。首先,人工给出聚类分析计算的初始聚类中心。根据采访各部门的实际情况,利用德尔菲法得出4个岗位中各个维度的权重,如表1所示,其中每一列代表拟将划分的4个岗位类别,每一行分配各个维度的权重,该表显示在算法开始时的初始聚类中心。
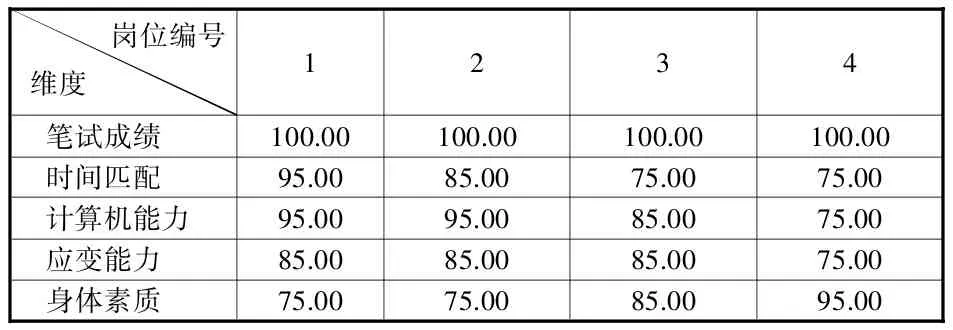
表1 初始聚类中心

表2 迭代历史记录
3.3 聚类结果分析及录取分配方案
表2显示的是迭代历史记录。即,聚类的迭代计算过程。从中可以看出,在经过4次迭代后,聚类中心就不再发生变化,即误差平方和的值在第4次计算后与上一次迭代计算结果的差值全部变为0,聚类计算到这里已经完成。[4]
表3显示聚类分析的结果。其中的“聚类划分”一列,表明每个应聘学生应属的岗位类别,最后一列是每个应聘学生xi到其所属类中心的距离D(xi,cj(I))。
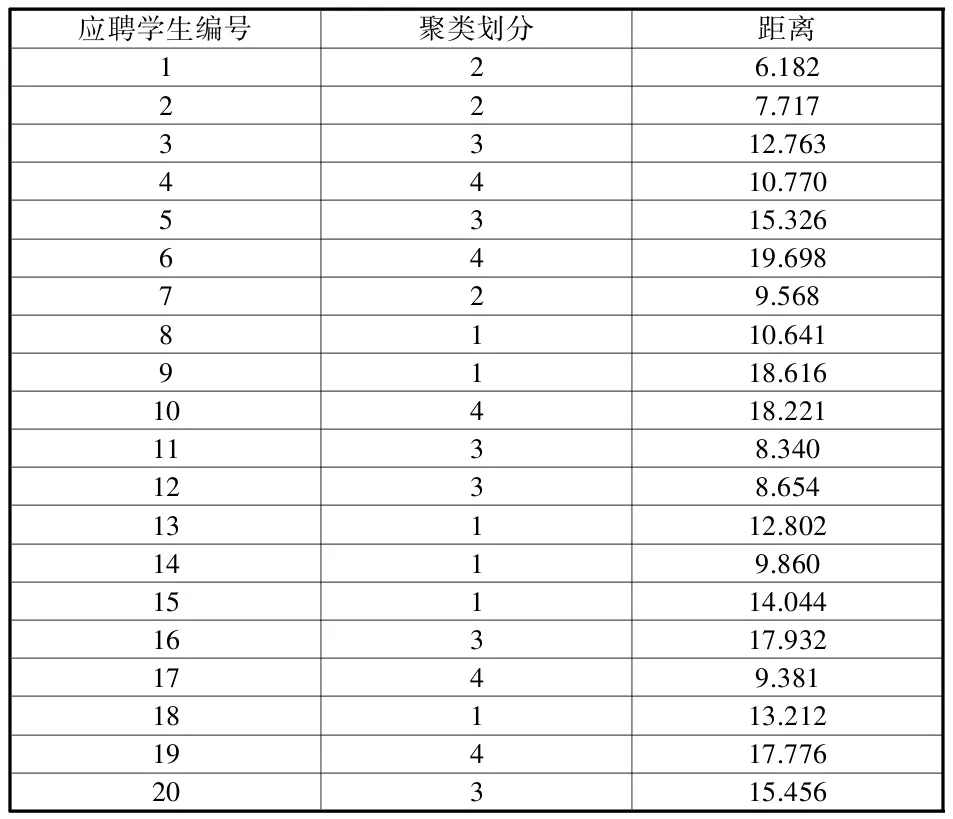
表3 聚类结果
对表3的聚类结果进行分析,在各岗位类别中根据各样本到类中心点的距离依次从近到远录取;如果样本到类中心点距离相同,则可参照笔试成绩,得到如表4中的岗位分配结果。
4 总结
本文将图书馆的招聘工作与统计学知识相结合,希望找到一个科学便捷的方法进行勤工助学的招聘方法。这次尝试虽然以数据分析为主,但为招聘工作提供了一个思路,为图书馆招聘公正合理提供了一个统计学理论支持。此外本文利用SPSS软件的K均值聚类方法对应聘学生进行聚类分析有其便利性,但分析不够全面,在实际招聘中可以尝试更多的方法,考虑到更全面的因素。

表4 岗位分配结果
[1]邓海燕.聚类分析与判别分析的区别[J].武汉学刊,2006(1):29-31.
[2]宁凯.基于K均值聚类的编组站分类方法研究[J].铁路运营技术,2011(7):41-46.
[3]沈炎.SPSS在高校图书馆勤工助学招聘中的应用[J].大学图书情报学刊,2008(6):33-35.
[4]顾荣炎.SPSS 12.0 For Windows实用教程与操作技巧[D].上海:上海科学技术文献出版社,2005,9.
