结合词语分布信息的TFIDF关键词抽取方法研究
2014-04-02,
,
(1.河南工业大学 信息科学与工程学院,郑州 450001;2.数字出版技术国家重点实验室,北京 100871)
关键词抽取旨在从文本中选择少量的、最能代表文本语义内容的词或短语,而这些关键词构成了文本的一种浓缩表示,可以看作是文本的一个高度概括的摘要。正因为如此,关键词抽取在信息检索与文本挖掘(如文本摘要、文本分类、文本聚类和自动问答等)中有着非常广泛的应用。
目前关键词抽取方法主要分为有监督方法和无监督方法2种。有监督方法需要借助人工标注的大规模语料获取关键词抽取模型,而无监督方法不要求有人工标注的语料,只利用待处理文本中词语的统计信息确定文本关键词。无监督方法因为不需要标注语料,所以具有更高的实用价值。文献[1]对5种无监督关键词抽取算法(TFIDF、TextRank、SingleRank、ExpandRank、KeyCluster)在4个语料上做了全面测试,发现基于TFIDF的方法简单且总体性能最优[1];基于TFIDF的抽取算法,考虑了词频以及词语的常用程度等信息,但却忽略了词语在文本中的分布信息,如词语分布规律、词语出现的位置等。在直觉上,这些词语分布信息对于确定代表文本内容的关键词应当很有帮助。例如,如果两个词语A和B在文本中的分布分别为 “-A——A——A——A-”、“——————BBBB——————”(“-”代表其他词汇),那么词语A作为关键词的可能性应当大于B。另外,出现在标题和篇首的词语成为关键词的可能性相对要大得多。本文试图结合词语的分布信息,进一步提高基于TFIDF的关键词抽取方法的性能。
1 相关工作
与关键词自动抽取紧密相关的是自动标引技术,它试图用一组能描述文本内容的词或短语标注文本。自动标引可以分为抽词标引和赋词标引两种[2]。赋词标引是从预先编制的规范词表中选取能够表达文本主题内容的词或短语,这些词或短语未必在文本中出现。而抽词标引则使用文本中出现的词语来标注文本的语义内容。相比而言,抽词标引灵活,更适合计算机自动处理,也是目前大多数自动标引研究者使用的方法。抽词标引即为本文所说的关键词抽取。
在20世纪70年代,有学者将机器学习算法引入关键词自动抽取领域,其中常见的有最大熵模型、决策树、SVM[3]、贝叶斯和bagging等算法。这些基于有监督的方法,其主要思路是将关键词抽取视为一个分类任务,对已经标注好的数据进行训练,获得分类模型;通过分类模型,判断给定的词是否为文档的关键词,最终实现对文档关键词抽取。比较典型的有Turney实现的GenEx系统(利用决策树和遗传算法实现)和Witten实现的Kea系统(利用朴素贝叶斯算法实现)。这些模型的特点是在取得较好效果的同时,需要标注好具有一定规模的语料,而且,不同领域的抽取效果是无法估计的[4]。
基于无监督的关键词抽取方法也受到了重视,主要包括基于语言模型的分析方法、基于统计的方法等,其中以基于统计的方法较为常见,它主要利用了N-gram、词频、TFIDF、词的同现、Pat-tree等信息[4-5]。基于图的算法[6-7]、基于聚类的算法[8]以及基于话题模型的算法等无监督方法的优点在于不需要标注语料作训练,适用面较广。
2 基于TFIDF的关键词抽取算法
首先,借助TFIDF公式计算文本中所有词语对文本语义内容的代表程度;然后,直接取最重要的若干词语作为关键词,然而这只是一种最简单的情况。实际上,关键词常常是由多个词语组成的短语。因此,在计算得到单个词语的TFIDF值之后,先利用一些启发式规则(如窗口大小、短语边界、词性组合等)确定候选的关键词或关键词短语,然后利用词语的TFIDF值计算这些候选词或短语作为关键词的可能性大小,最终取可能性最大的若干候选词或短语作为关键词。在计算候选短语作为关键词的可能性时,通常由其所含词语的TFIDF值加和得到。
上述基于TFIDF的关键词抽取算法中,词语的TFIDF值是最主要的依赖因素。
TFIDF是信息检索领域用于计算文本特征值的重要技术,用于表示一个特征项(可以是一个词、一个短语等)对于一个文档语义内容的代表能力。TFIDF的主要思想是:如果某个特征项(词或短语)在一篇文档中出现的频率高并且不常用,那么该特征项就具有很好的文档代表能力。其中,特征项的常用程度是由文档频率决定的:在文档中出现越多,就越常用。
传统的TFIDF计算可由TF(w,d)×IDF(w)求得,TF(w,d)即TF,代表项w(词或短语)在文档d中出现的次数;IDF(w)即IDF,可通过DF(w)求出。
(1)
其中:Nall代表语料中文档的总数;DF(w)代表包含词语w的文档数量。
3 结合词语分布信息的算法
通过引入词语分布信息,本文将传统的TFIDF计算公式修改为
(TF*(1-STDdist)+RFPos)*IDF
(2)
其中:TF和IDF的计算方法与传统的TFIDF方法一致;RFPos描述了词语在文本中首次出现的相对位置;STDdist描述了词语在文本中分布的均衡程度,值越小分布越均匀。RFPos以及STDdist的计算公式如下:
(3)
(4)
其中:RD(i,i+1)为词语第i次出现与第i+1次出现之间的相对距离,值为间隔中的词语数与文本长度的比值。当计算i=TF(最后一次的RD(i,i+1)值)时,假设文本头尾相连,计算最后一次出现与第一次出现之间的相对距离;参数α的取值范围在0到1之间。
改进的TFIDF算法将RFPos以及STDdist引入TFIDF值的计算中,其中对于不同的语料,参数α的相对最优取值可以由实验获得。
4 实验及结果分析
为了验证改进算法的有效性,本文对选自不同领域的3个语料进行了测试。关键词抽取一般通过将自动抽取的关键词与人工标注的关键词相比较进行评价,使用的评价指标主要是准确率与召回率等。
4.1 实验语料
为方便对比,本文参照文献[1],选用3个语料进行测试,分别为Inspec、DUC2001、NUS语料。3个语料中的文档数量、文档平均长度以及格式不同,具体统计信息如表1所示。
Inspec语料[6,9-10]:作为关键词抽取领域流行语料之一的Inspec语料,包含了来自2 000篇学术文章的摘要。它包含3种后缀名的文件:后缀名为abstr的文件内容是论文的标题和摘要;后缀名为contr和uncontr的文件内容分别是人工标注的关键词短语和由Hulth实验标注的关键词短语。本文采用该语料测试集合中的500篇文档作为实验语料。从表1可以看出,该语料中文档平均长度是3个语料中最短的。
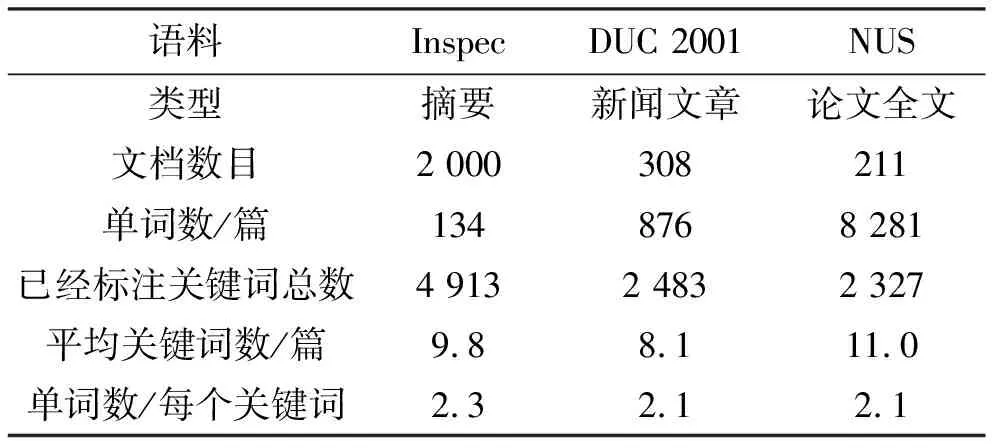
表1 3个语料的统计信息
DUC2001语料[4]:含有308篇新闻,采用SGML格式,标识了每篇新闻报道的标题、时间及正文信息。本文选用全部的308篇文档,仅对新闻的正文部分进行处理,采用由万小军整理标注的关键词集合[6]。
NUS语料[10]:该语料包括211篇科技论文全文,每篇文档有PDF、HTML、文本及XML 4种格式,且已经由作者或其他人标注。需要注意的是,该语料中每个文档可能有多人进行标注,保存在不同的文件中。该语料的主要特点:每篇文档平均包含8 291个词,是3个语料中最长的。在实验中,本文选用全部的211篇文档,考虑到不同标注者侧重点的不同且方便与文献[1]进行对比,按照文献[1]中的处理方式,将每篇文档由不同人标注的关键词短语统计排序后的集合,作为该文档的关键词短语人工标注结果。因此,该语料中每篇文档的平均关键词数是最多的。
从表1可以看出,3个语料人工标注的关键词平均包含的词语数都超过了2。
4.2 实验设置
对3个语料中的文档进行预处理,利用斯坦福大学的词性标注工具POS Tagger进行词性标注[11]。将这些经过词性标注的文档作为输入,计算出k个关键词短语,作为抽取结果。
(1)关键词提取的前期阶段采用文献[7]中的方法,选用形容词、名词作为候选单词;利用N-gram算法,筛选并得到包含候选词的最长n元词集合。
(2)公式(4)中参数α的设定依据:从给定的语料中任意抽出一篇文档进行测试,设定α的取值从0变化到1,步长为0.1,取抽取结果最优时的α值作为处理其他文档时的参数值。
(3)候选词或短语作为关键词的度量值由其所含词语的TFIDF值加和得到。
(4)对于每篇文档的候选关键词短语,按照上面计算的度量值进行排序,选取前k个作为抽取结果。
(5)评测时,将抽取得到的关键词与人工标注的结果进行对比,采用标准的准确率P、召回率R和F1测度值(F1-measure)作为评价指标。其中F1为准确率P与召回率R的调和平均值,计算公式如下:
(5)
(6)
(7)
4.3 实验分析
图1、图2和图3分别给出了改进的TFIDF(TFIDF-POS)和传统的TFIDF算法(TFIDF)在Inspec、DUC2001和NUS 3个语料上的F1测度值的变化情况。在TFIDF算法的基础上引入词语的位置及分布信息,使得关键词抽取的准确率有所提高。Inspec语料的每篇文档长度比DUC2001和NUS语料的短得多,曲线变化不够明显。但从统计显著量(0.42)来看,准确率提高的效果是显著的。从图2和图3可以发现,随着文档长度的增加,词语的位置信息及分布信息的有效性变得更为明显。TFIDF算法对于200以上单词数的文章效果较好,这与文献[12]的观点一致。

图1 在Inspec语料上F1测度值的变化
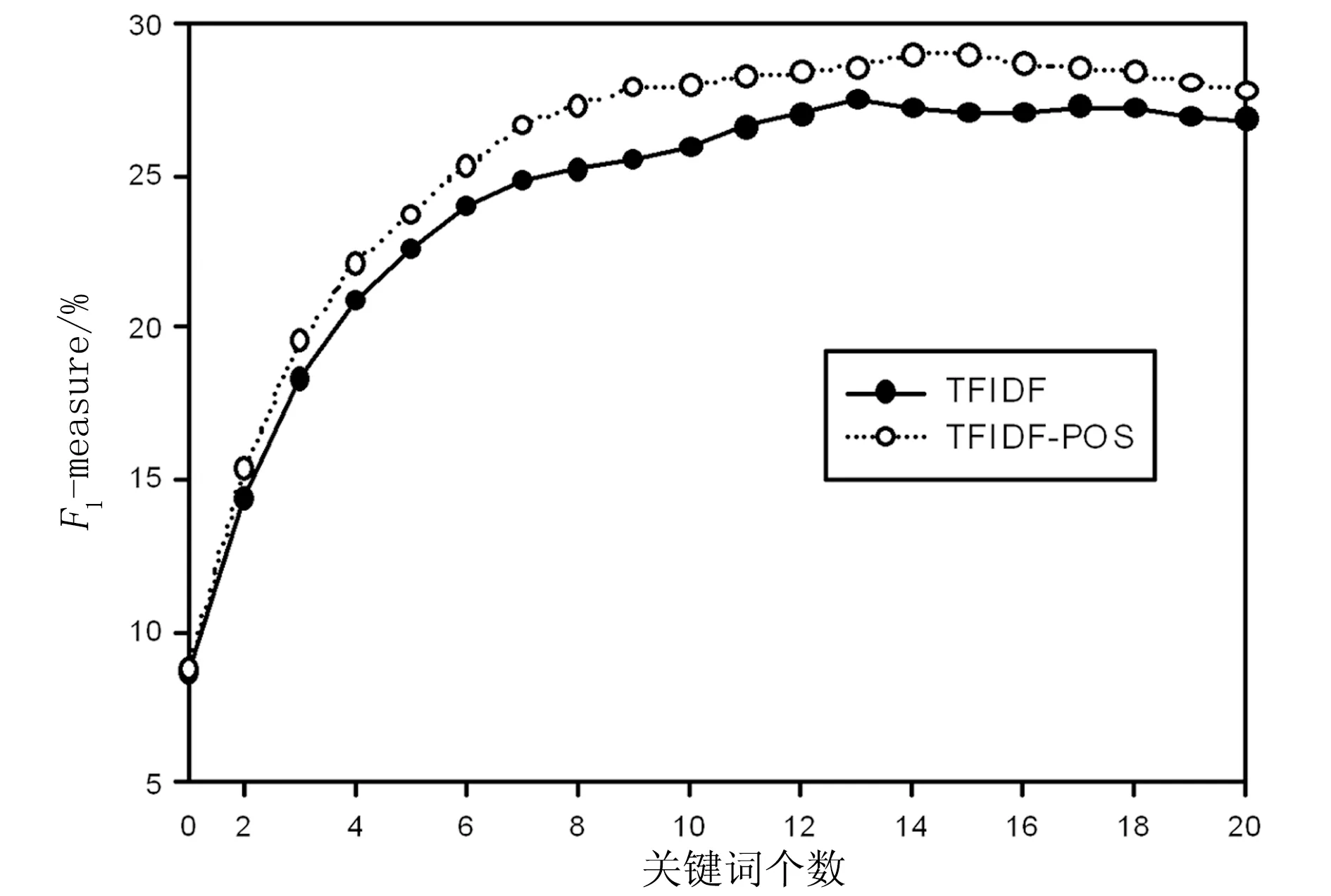
图2 在DUC2001语料上F1测度值的变化
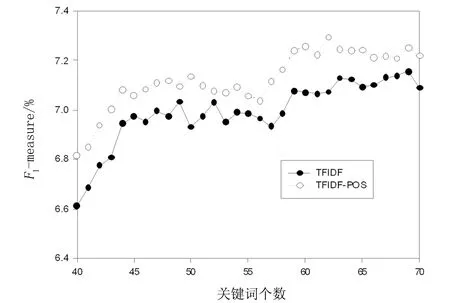
图3 在NUS语料上F1测度值的变化
为了更好地分析不同语料受首次出现的位置信息和分布均衡度信息两者影响的差异,本文在公式(2)的基础上进行修改:若仅考虑分布均衡度信息,将RFPos置为0(情况一);若仅考虑首次出现的位置信息,将STDdist设置为0(情况二);传统的TFIDF算法为情况三。限于篇幅,本文仅对Inspec和DUC2001两个语料进行测试,测试结果如图4和图5所示。
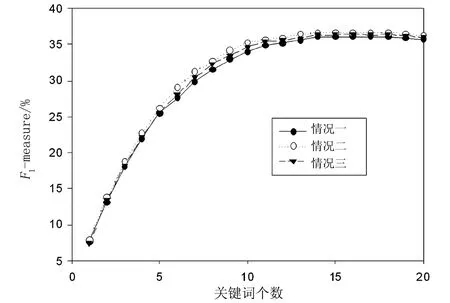
图4 对Inspec语料的测试结果
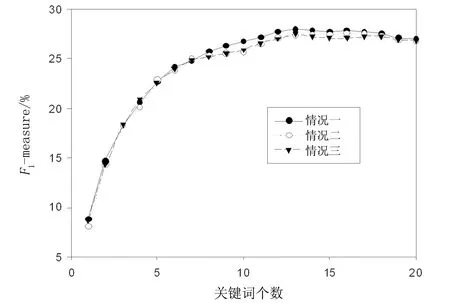
图5 对DUC2001语料的测试结果
从实验得到的数据来看,对于类似于Inspec文档长度较短的语料而言,仅考虑首次出现的位置得到的抽取准确率比仅考虑分布均衡度及传统的TFIDF的效果好,而对于类似于DUC2001中文档长度较长的语料正好相反。因此,在抽取关键词时要充分考虑语料的特点。
实验还研究了参数α的设定对关键词抽取性能的影响。表2列出了TFIDF算法与改进的TFIDF算法在3个语料上的最佳参数设置。表中参数k为设定的每篇文档要抽取的关键词数目;参数α的取值体现了词语首次出现的位置和词语在文中出现位置的均衡度的关系。其值越小则词语首次出现的位置信息越重要;值越大则词语在文中出现位置的均衡度越重要;F代表F1测度值。
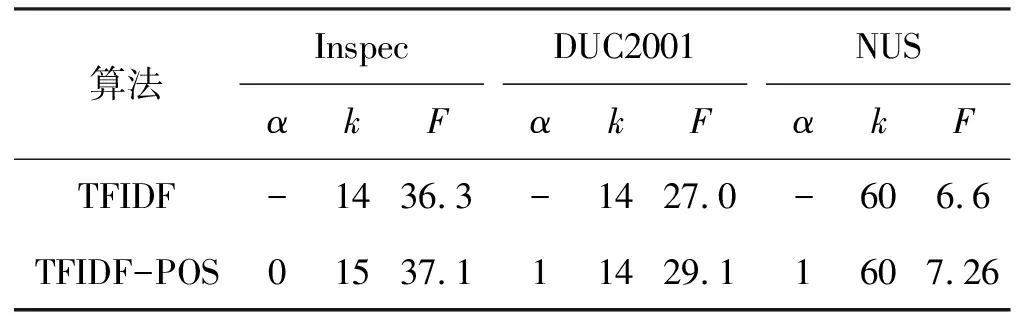
表2 两个算法的最佳参数设置
5 结 语
本文在经典的、基于TFIDF的关键词抽取算法基础上,考虑了词语在文档中分布的均衡程度以及首次出现的相对位置等信息,构建了一种改进的关键词抽取算法,并对3个语料进行了实验。实验结果表明,改进方法是有效的。
下一步将进一步考虑文本数据的特点,利用位置及顺序等信息,改进关键词抽取的性能。同时也计划尝试利用机器学习算法,充分利用多种信息特征,来提高关键词抽取的准确率。
参考文献:
[1] Kazi Saidul Hasan, Vincent N.Conundrums in Unsupervised Keyphrase Extraction: Making Sense of The-art[C]//Rroceedings of the 23rd International Conference on Computational Linguistics, Beijing, 2010: 365-373.
[2] Kathrin Eichler, Günter Neumann.DFKI KeyWE: Ranking Keyphrases Extracted from Scientific Articles[C]//Proceedings of The 5th International Workshop on Semantic Evaluation,Uppsala, Sweden, 2010: 150-153.
[3] Zhang K, Xu H, Tang J, et al.Keyword Extraction Using Support Vector Machine[C]//Proceedings of the Seventh International Conference on Web-Age Information Management, HongKong, 2006: 85-96.
[4] Kim S N, Medelyan O, Kan M Y, et al.Evaluating N-gram Based Evaluation Metrics for Automatic Keyphrase Extraction [C]//Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, 2010: 572-580.
[5] Niraj Kumar, Kannan Srinathan.Automatic Keyphrase Extraction from Scientific Documents Using N-gram Filtration Technique[C]//Proceedings of the Eighth ACM Symposium on Document Engineering, New York, 2001:199-208.
[6] Rada Mihalcea, Paul Tarau.TextRank: Bringing Order into Texts [C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing,Barcelona, 2004:120-128.
[7] WAN Xiaojun, XIAO Jianguo.Single Document Keyphrase Extraction Using Neighborhood Knowledge[C]//Proceedings of the 23rd AAAI Conference on Artificial Intelligence, Chicago, 2008: 855-860.
[8] LIU Zhiyuan, LI Peng, ZHANG Yabin, et al.Clustering to Find Exemplar Terms for Keyphrase Extraction[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 2009: 257-266.
[9] Anette Hulth.Improved Automatic Keyword Extraction Given More Linguistic Knowledge[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, 2003: 216-223.
[10] LIU Feifan, Deana Pennell, LIU Fei, et al.Unsupervised Approaches for Automatic Keyword Extraction Using Meeting Transcripts[C]//Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, New York, 2009: 620-628.
[11] Thuy Dung Nguyen, Min-Yen Kan.Keyphrase Extraction in Scientific Publications[C]//Proceedings of the International Conference on Asian Digital Libraries, Hanoi, 2007:317-326.
[12] Kristina Toutanova, Christopher D Manning.Enriching the Knowledge Sources Used in a Maximum Entropy Part-of-speech Tagger[C]//Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, Hong Kong, 2000:63-70.
