基于Intel Xeon Phi的激光等离子体粒子模拟研究*
2014-03-23姚文科杜云飞杨灿群
姚文科,杜云飞,吴 强,杨灿群
(1.国防科学技术大学并行与分布处理国家重点实验室,湖南长沙410073;2.国防科学技术大学计算机学院,湖南长沙410073)
1 引言
激光等离子体粒子模拟通常用于描述强激光与等离子体相互作用的非线性过程,从而预测、设计、解释实验结果[1,2]。它对于解释激光等离子体多种耦合过程的物理图像细节,发现新的物理现象具有重要的意义[1~4]。在实际应用中,模拟迭代的时间步通常可达数千万步,模拟的粒子数目超过数百万个[5,6],为了在有效的时间内获得模拟结果,模拟对计算性能有着极高的要求。因此,使用高性能计算领域的最新成果加速激光等离子体粒子模拟具有重要的现实意义。
近年来,异构系统已经成为高性能计算领域的一种主流系统[2,7]。通过集成通用CPU和加速器单元如GPU等,异构系统在功耗和性能方面占有优势。针对GPU等加速单元与CPU体系结构差异大、编程模型不兼容的问题[7],Intel发布了支持X86指令架构的Intel Xeon Phi协处理器[8]。Intel Xeon Phi一方面可以兼容原CPU上的程序库、开发工具以及应用程序,另一方面对于特定类型的计算任务,可以提供极高的计算性能,如Intel Xeon PhiTMCoprocessor 5110P单卡双精度浮点性能可达1.01 Tflops[2]。在2013年5月Top 500排名中,采用了CPU-Intel Xeon Phi异构结构的TH-2超级计算机排名榜首。可以预见,基于CPU-Intel Xeon Phi的异构系统将在未来高性能计算领域中发挥重要的作用。
基于这一背景,本文研究了三维等离子体粒子模拟程序LARED-P到Intel Xeon Phi的移植。首先采用Native模式对LARED-P程序中热点计算任务进行优化研究,通过采用SIMD扩展指令进行手工向量化以及数据预取、循环展开的优化,使该计算任务获得了4.61倍的加速。随后采用Offload模式将程序移植到CPU-Intel Xeon Phi异构系统上,并通过使用异步数据传输和双缓冲技术提升了程序性能。
本文结构如下:第2节介绍了Intel Xeon Phi的结构特点和LARED-P算法,回顾了相关工作;第3节描述了Native模式下LARED-P在Intel Xeon Phi上的SIMD优化;第4节展现了Offload模式下粒子运动方程的优化过程;第5节给出了性能测评结果;第6节对全文进行了简要总结。
2 背景介绍
本节主要对Intel Xeon Phi加速器的结构和LARED-P程序结构进行简单介绍;同时,对其他学者的类似研究工作进行总结。
2.1 Intel Xeon Phi的结构
Intel在2012年11月发布了Intel Xeon PhiTM协处理器,它基于Intel MIC(Many Integrated Core)架构。每片Intel Xeon Phi可以提供62个x86兼容的计算核心[8],每个核包含一个支持512位SIMD的向量处理单元(VPU)。通过使用VPU,每个核可同时处理8路双精度或16路单精度浮点运算[8],目前,Intel通过提供Intel向量化库、Intel Intrinsic函数等方式使用VPU。Intel Xeon Phi的每个核拥有32 KB的L1数据Cache和32 KB的L1指令Cache。此外,每个核还可以使用512 KB的L2 Cache。不同核的L2 Cache通过双向内存控制器相连。
Intel提供了多种模式来使用Intel Xeon Phi,例如Native模式、Offload模式等。
Native模式将Intel Xeon Phi作为一个独立的处理节点,其上运行有微Linux操作系统,内存空间作为全部的存储空间。
Offload模式则将Intel Xeon Phi作为CPU的加速单元。CPU作为主控端,将计算密集部分传送到Intel Xeon Phi上进行计算,然后再将计算结果返回给CPU。
2.2 LARED-P简介
LARED-P程序是北京应用物理与数学研究所采用粒子云网格法[3,4]实现的三维等离子体粒子模拟程序。它适应于二维和三维Cartesian坐标系,本文主要针对三维模拟进行研究。它采用均匀矩形结构网格离散整个模拟空间,等离子体采用粒子云近似。
LARED-P程序流程如图1所示,其中主要的三个任务为求解电磁场Maxwell方程、静电势Poisson方程和粒子运动方程。在计算过程中,LARED-P以有限差分方法离散Maxwell方程,然后采用蛙跳格式离散粒子运动方程,最后采用粒子云网格方法(PIC)耦合粒子和电磁场。这三个方程中粒子运动方程占据了计算时间的31.8%,粒子云方程占34.7%,粒子重排过程占27%。
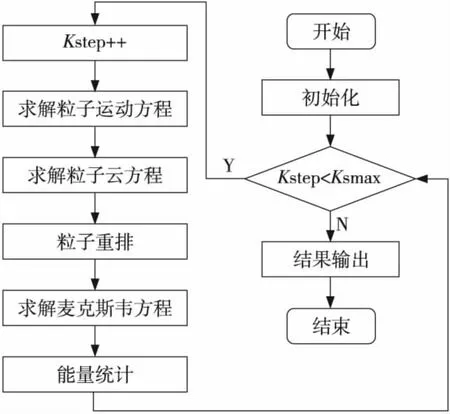
Figure 1 Flow chart of LARED-P图1 LARED-P程序流程图
2.3 相关工作
莫则尧等人[4]在所开发的串行LARED-P程序的基础上引进网格与粒子的关系链表,重排粒子位置,消除了性能迁移,提高了单机性能。而后又开发了基于MPI环境的三维粒子模拟程序LARED-P,并采取三维分割、合理安排通信结构,设置虚网格等手段进行优化。
刘来国等人[6]完成了基于GPU的LARED-P加速技术的研究与实现。加速后的LARED-P程序在NVIDIA Tesla S1070的单个GPU上获得了相当于主频2.4 GHz的Intel(R)Core(TM)2 Quad CPU Q6600单核的6倍加速比。
石志才等人[9]则针对LARED-P中粒子运动方程在GPU上的实现提出八色分解方案,消除并行访问的读写依赖,扩大了并行度,在NVIDIA Tesla M2090上获得了相对于Intel Xeon X5670 CPU单核的20.08倍的加速比。
3 Native模式下基于SIMD的优化
本节介绍在Native模式下针对LARED-P所做的优化工作。该算法的实现部分见文献[9]。运动方程的运行时间占整个算法运行时间的31.8%,在移植过程中为了提高其数据级并行,对它进行了向量化。在使用编译器选项-O3-mmic与-O3-novec-mmic对比中,发现两者运行时间没明显区别;加编译指导#pragma vector命令后也没太大提升。所以,我们选择了手工向量化。
3.1 基于SIMD扩展指令的手工向量化
通过调用Intel提供的Intrinsic接口函数对粒子运动方程的求解进行手工向量化,该过程主要包括数据打包、向量计算以及数据解包等过程。以更新粒子位置为例,如图2所示。其中,x、y、z三个数组分别存放粒子的x坐标、y坐标以及z坐标,vxj、vyj、vzj三个数组则存放粒子新速度的三个分量。
这样经过SIMD向量化,程序局部性增强,性能得到可观的提升。
在更新粒子新速度时,涉及许多乘、加操作,为了提高效率可以使用乘加指令:_mm512_fmadd_pd(_mm512d,_mm512d,_mm512d)。乘加指令的使用带来了可观的性能提升。
3.2 预取优化
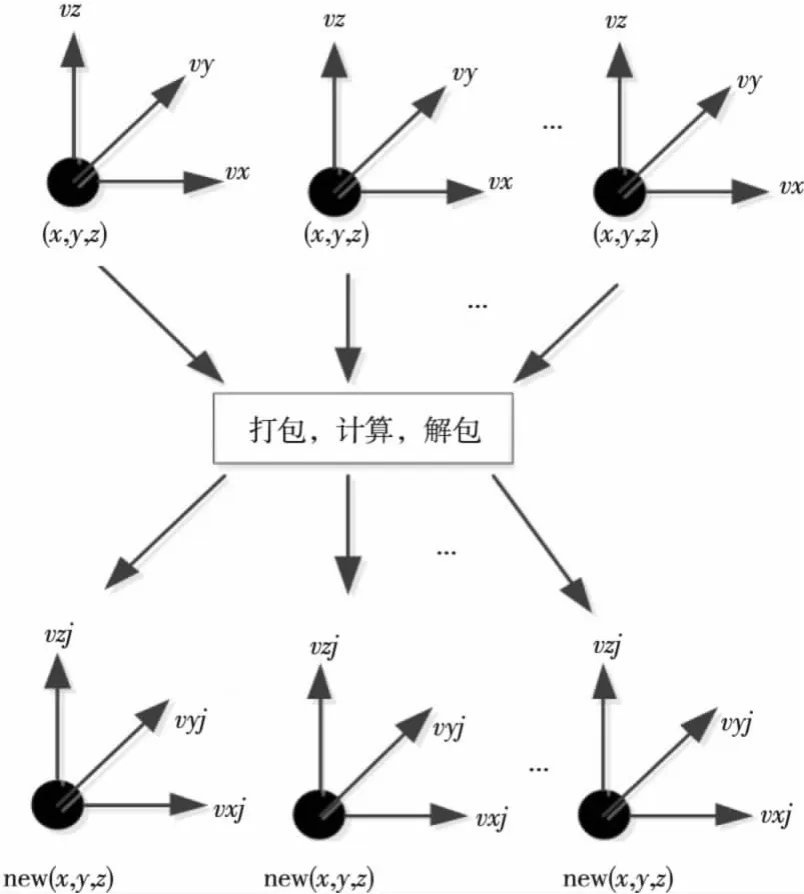
Figure 2 Sketch map of vectorization图2 向量化示意图
512位宽度的向量处理给访存带来了巨大挑战,为了降低访问延迟,本文采用了预取指令mm_prefetch(),减少Cache失效。
每次迭代访问八个网格,这种访问模式可预测性给预取带来了便利。本文测试了几组不同预取距离的运行结果,如图3所示。从图3可以看出预取距离为一个迭代时性能最好。
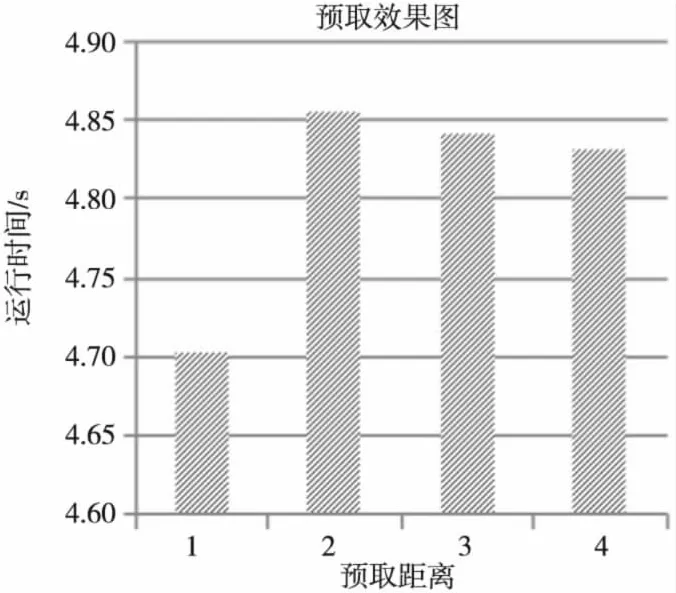
Figure 3 Result of prefetch图3 预取效果图
4 基于Offload模式的程序移植
随后我们利用offload模式将LARED-P移植到CPU-Intel Xeon Phi异构系统上。我们将热点计算任务—运动方程的求解使用Intel Xeon Phi进行加速,程序的其余部分仍然在CPU上完成。在移植的过程中发现,CPU和Intel Xeon Phi之间的数据传输是程序性能瓶颈,占总时间60%。因此,如何降低传输开销成为了本节工作的重点。我们主要采用了两种优化方法:异步数据传输和双缓冲。
4.1 异步数据传输
当使用Offload模式时,CPU在将数据传给Intel Xeon Phi之后,由于数据依赖的原因,需要等待其计算完毕并将结果传送回CPU以后,CPU才能继续执行。为了减少CPU的空转时间,我们采用了异步数据传输的方式对其进行优化。
首先采用一种CPU提前计算的方式减少CPU的空转时间。当需要调用Intel Xeon Phi进行粒子运动方程加速时,CPU以异步方式将数据传输到Intel Xeon Phi上,并提前进行与粒子运动方程计算结果无关的任务的处理,如图4所示。然而,由于大部分的计算任务都与运动方程相关,因此这种方式取得的效果并不明显。
随后采用了一种提前传输的方式来减少数据拷贝时CPU的等待时间。当粒子运动方程相关的数据已经准备完毕时,CPU立刻以异步的方式将数据传给Intel Xeon Phi后,继续以正常流程进行任务处理,这样增加了CPU和Intel Xeon Phi并行执行的时间,从而隐藏了部分数据传输时间。

Figure 4 Sketch map of asynchronous mode图4 异步传输示意图
4.2 双缓冲
为了进一步减少数据传输开销,我们采用了双缓冲技术,在CPU端开辟两个发送缓冲区和两个接收缓冲区。所需数据分组传输,相比之前MIC端需要接收全部数据之后才开始计算,在使用了双缓冲之后,带来的明显好处是:以流水线方式执行传输和计算,可以将绝大部分数据传输时间隐藏,如图5所示。

Figure 5 Sketch map of double buffer图5 双缓冲示意图
5 性能评测
本节对LARED-P算法进行性能测试,测试平台的具体配置如表1所示。我们采用的编译器为Intel C++Compiler 13.0,MPI版本为3.0。

Table 1 Configuration of the test platform表1 测试平台的配置
首先测试了手动向量化和数据预取取得的性能提升。测试网格数为64*128*128,平均每个网格包含10个粒子。图6为没有向量化、只有向量化和向量化加预取三种情况下程序的运行时间,从图6中可以看出,向量化加速效果不错,加速比可达到4.61,而预取的加速效果没有向量化明显,但是仍有19.7%的性能提升。因为MIC卡内存有限,无法再扩大规模,而当线程数接近64时,运行时间占整个程序时间的比例已经非常小了,所以只测试到了64线程。CPU上运行16线程时总时间为1.058 s,而MIC上64线程运行时间为0.717 s,所以在MIC上每个核运行一个线程的情况下,相对单块CPU有1.48倍的加速。
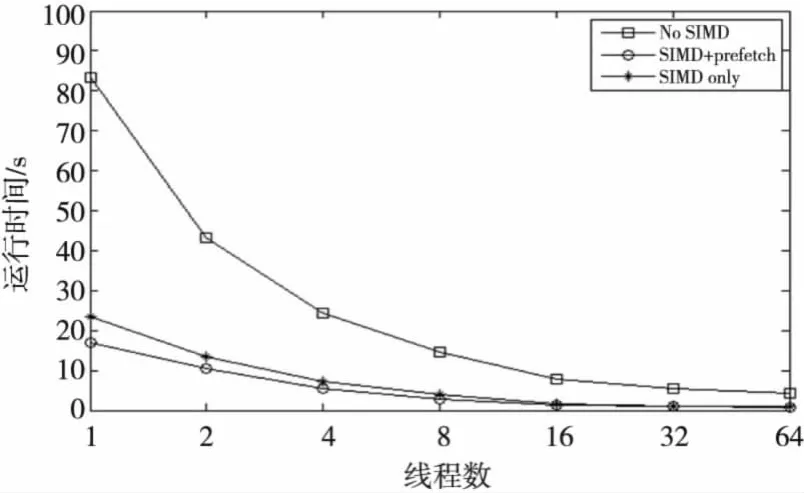
Figure 6 Result in native mode图6 Native模式下实验结果
接着测试了Offload模式下的异步输入和双缓冲的效果,如图7所示。从图7中可以看出,异步输入和双缓冲都对运动方程产生了一定的性能提升,相比于传统Offload分别有9.8%和21.8%的性能提升。
6 结束语
本文基于Intel Xeon Phi协处理器实现了LARED-P程序的移植。在移植的过程中,本文综合运用了Native和Offload两种编程模式:首先运用Native模式对LARED-P程序中热点计算任务进行优化研究,通过采用SIMD扩展指令使该计算任务获得了4.61倍的加速;然后运用Offload模式将程序移植到CPU-Intel Xeon Phi异构系统上,并通过使用异步数据传输和双缓冲技术分别获得9.8%和21.8%的性能提升。

Figure 7 Result in Offload mode图7 Offload模式下实验结果
[1] Zhu Shao-ping,Zhang Wei-yan.Overview of computer simulation on laser fusion in China[J].Journal of the Korean Physical Society,2006,49:33-38.
[2] Chang Tie-qiang.Laser-plasma interaction and laser fusion[M].Changsha:Hunan Science and Technology Press,1998.(in Chinese)
[3] Ma Yan-yun,Chang Wen-wei,Yin Yan,et al.An object-oriented 3D parallel simulation program PLASIM3D[J].Chinese Journal of Computation Physics,2004,21(3):305-311.(in Chinese)
[4] Mo Ze-yao,Xu Lin-bao,Zhang Bao-lin,et al.Parallel computing and performance analysis for 2D plasma simulation with particle clouds in cells method[J].Chinese Journal of Computation Physics,1999,16(5)496-504.(in Chinese)
[5] Cao Xiao-lin,Zheng Chun-yang,Zhang Ai-qing,et al.Program development of 3D plasma simulation oriented thousands of processors[J].Chinese Journal of Progress in Natural Science,2009,1(5):544-550.(in Chinese)
[6] Liu Lai-guo,Xu Wei-xia,Yang Can-qun,et al.Accelerating LARED-P algorithm based on GPU[J].Computer Engineering &Science,2009,31(A01):59-63.(in Chinese)
[7] Stantchev G,Dorland W,Gumerov N.Fast parallel particleto-grid interpolation for plasma PIC simulations on the GPU[J].Journal of Parallel and Distributed Computing,2008,68(10):1339-1349.
[8] Intel®Xeon PhiTMCoprocessor System Software Developers Guide[R].SKU#328207-001EN,2012.
[9] Yang Can-qun,Wu Qiang,Hu Hui-li,et al.Fast weighting method for plasma PIC simulation on the GPU-accelerated heterogeneous systems[J].Journal of Central South University,2013,20(6):1527-1535.
[10] MPI-2:Extensions to the message-passing interface[EB/OL].[2012-05-16].http://micro.ustc.edu.cn/Linux/MPI/mpi-20.pdf.
[11] Schulz K W,Ulerich R,Malaya N,et al.Early experiences porting scientific applications to the many integrated core(MIC)platform[C]∥Proc of the 2012 Highly Parallel Computing Symposium,2012:1.
附中文参考文献:
[2] 常铁强.激光等离子体相互作用与激光聚变[M].长沙:湖南科学技术出版社,1998.
[3] 马燕云,常文蔚,银燕,等.三维面向对象的并行粒子模拟程序PLASIM3D[J].计算物理,2004,21(3):305-311.
[4] 莫则尧,许林宝,张宝琳,等.二维等离子体模拟粒子云网格方法的并行计算与性能分析[J].计算物理,1999,16(5):496-504.
[5] 曹小林,郑春阳,张爱清,等.面向数千处理器的三维等离子体粒子模拟程序研制[J].自然科学进展,2009,19(5):544-550.
[6] 刘来国,徐炜遐,杨灿群,等.基于GPU的LARED-P算法加速[J].计算机工程与科学,2009,31(A01):59-63.
