滑动窗口内动态数据流聚类算法研究
2014-03-23许颖梅
许颖梅
(商丘师范学院 计算机与信息技术学院, 河南 商丘 476000)
0 引 言
随着通信业的大力发展,一种被称之为数据流的数据应运而生。数据流具有数据连续、实时到达、数据量大、无限制并且无法预知的特点[1]。而数据流聚类算法作为数据流挖掘的工具,具有很好的研究和应用前景,也是目前应用研究的热点。聚类就是按一定特征将一个对象的集合分成若干个类。聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程,这些对象与同一簇中的对象彼此相似,与其他簇中的对象相异。
数据流聚类正在蓬勃发展,现在数据流聚类算法的研究已经成为一个非常活跃的研究课题,基于K-means(K-平均值)、K-medoids(K-中心点)和其他一些的聚类分析工具已经被应用到许多领域。Guha等人[2]提出了LOCALSEARCH算法,在有限的空间内对数据流分门别类,使用一个不断迭代的过程对不断到来的流数据采取K-means聚类;Callaghan等人[3]在LOCALSEARCH算法的基础上又提出了Stream算法,STREAM算法采用分级聚类的技术,对K-Means算法进行改进,得到较好的性能,但这种算法是基于静态数据流而言的,不能及时反映数据流动态变化的情况;Aggarwal等人[4]在2003年提出了CLUStream算法,该算法提出一个通用的数据流聚类框架,它适应范围很广,为后来的研究作出了杰出的贡献,它有效地将数据流的聚类分成在线微聚类和离线宏聚类两个阶段;针对高维数据流和任意形状分布的数据聚类问题,2006年周晓云等[5]又提出基于Hoeffding界的高维数据流的子空间聚类发现及维护算法SHStream,它通过迭代逐步得到满足聚类精度要求的聚类结果。2007年,杨春宇等人[6]考虑到数据流的连续属性和标称属性提出了一种适用于处理混合属性数据流的聚类算法——HCluStream,为混合属性构建新的信息汇总方式及距离度量。2009年,吴枫等人[7]在数据流聚类形状问题上又提出了一种滑动窗口内进化数据流任意形状聚类算法SWASCStream。
这些算法在一定程度上都较之前有了改进,但都各有优劣,本文就算法的可行性、效率和内存使用情况进行研究,提出一种基于滑动窗口的优化数据分析算法。该算法的特点是:(1)提出一种新的内存存储结构滑动窗口树,它只需单遍访问数据流,不但能及时更新数据流上的模式信息,还能够周期性地对滑动窗口树进行修剪;(2)滑动窗口大小可以动态改变,根据支持度的不同,适当调整窗口大小,解决有限内存存储无限数据的可能。
1 预备知识
1.1 相关概念
定义1 数据流DS={T1,T2,…,Ti,…}为一个不断变化着的无限大小的数据序列,其中Ti为第i个产生的事务。在数据流中每个事务都有唯一的事务标识tid,在数据集中每个事务中的数据元素集合都是数据集A={a1,a2,…,am}的一个子集。

定义3 动态滑动窗口,给定最小支持度阈值δ和误差因子ε。假设|W|表示滑动窗口W的宽度,即W中包含的事务数。fw(A)表示模式A在滑动窗口中的支持度计数。对于模式A,如果有fw(A)≥δ|W|,则称A为滑动窗口W中的微簇;如果有fw(A)≥ε|W|,则称A为滑动窗口W中的临界微簇;如果有fw(A)<ε|W|,则称A为滑动窗口W中的过期微簇。
1.2 时间滑动窗口模型
结合数据流的特点,笔者在提高算法的可行性、效率和节约内存的情况下,采用动态滑动窗口模型,见图1。窗口大小会随着流速的改变而改变,同时考虑到窗口的频繁变化会影响算法的执行效率,定义了时间界定阈值。对不断到来多维数据流进入滑动窗口可以这样定义{Xi,tm,tn},Xi为在tm时刻到来的样本数据,tm为进到滑动窗口的时间点,tn为从滑动窗口流出的时间点。随着流入的速度不同,滑动窗口大小W可以随之改变,定义一个时间界定阈值σ,从而灵活地确定滑动窗口的大小。

图1 时间滑动窗口模型
1.3 滑动窗口树
SWStream算法采用滑动窗口树SW.tree的结构来存储潜在的微簇,一个SW.tree由事务头表、根结点和前缀子树构成。事务头表就是由当前滑动窗口中的所有临界微簇按照元组的支持度降序排序而成。事务头表的每个表目由事务名name和结点链头指针组成,其中结点链头指针指向树中具有相同事务名的第一个结点。前缀子树中的每一个结点由以下几个域构成[8]:①事务名name;②事务标识tid;③指向孩子结点的linktable;④指向父结点的point;⑤指向SW.tree中具有相同事务名的下一个结点的指针;⑥数值域(f,f1,f2,…,fi,…,fn),fi表示第i个元组中构成的各个模式的计数信息。
1.4 时间衰减机制
在数据流聚类过程中,有数据源源不断地流入,也应该有些过期的数据淘汰,这就要采用一定的衰减机制对过期元组进行衰减。本文中采用时间衰减模型,在这种模型中,数据流中每一个项集都有一个权重。权重随时间改变,新到来的项集对该项集的频度影响大于原来的项集。在时刻t,每个元组的衰减因子的大小满足:2-λt<ε(λ>0),λ值越大,过去数据的重要性就会降低。
数据流总的权重:
其中tc表示当前时间,v表示数据流的流速。
2 算 法
2.1 算法思想
本文紧紧围绕动态数据流分析这一核心问题,依据CLUStream双层聚类框架思想,将挖掘过程分为在线和离线两个阶段:在线阶段不断接收到来的数据流摘要信息,利用K-means算法从初始样本集中挖掘出一定数量的微簇更新到滑动窗口树分枝上,其产生的结果作为挖掘的中间结果维护起来。过一定的时间段将这些中间结果保存到外存中作为离线过程的初始数据。离线过程由用户调用,针对用户的查询得到最终的聚类结果。通过在线和离线两个阶段不同算法的处理以解决动态数据的快速处理。
2.2 在线层算法
算法SWStream采用了滑动窗口模型对流数据进行处理,存储结构使用滑动窗口树存储最近到来的模式信息,同时对节点信息增量更新,根据时间衰减机制对过期信息进行裁剪,从而减少了内存开销。
算法1 SW.tree的生成和维护。
该算法生成和维护一个用于存储滑动窗口中所有潜在的微簇的SW.tree结构。该算法在第一个元组进入滑动窗口后生成一个SW.tree,并在以后每个新元组进入滑动窗口后更新该SW.tree,过程分三步:一是根据更新的f.list对SW.tree进行重构;二是以ε为最小支持度阈值,调用传统的聚类算法对临界微簇进行聚类;三是将这些模式插入到SW.tree中。
SW.tree的生成和维护算法如下:
Input:newDS,进人滑动窗口之前的SW.tree(初始状态SW.tree为空),事务集排序表f.list,误差因子ε,滑动窗口W中包含的基本元组数n;
Output:new SW.tree
(1)构造滑动窗口树(SW.tree,f.list,n);
(2)以ε为最小支持度阈值,用传统的聚类算法如K-means对新窗口中的临界微簇进行聚类;
(3)将新的临界微簇插入到SW.tree中。
算法2 动态滑动窗口数据流在线聚类算法SWStream。
描述如下:
Input:数据流DS,窗口大小W,SW.tree;
Output:通过动态窗口生成的微聚类CF。
Begin
(1)建立微聚类输出表fo.list;
(2)逆序取SW.tree中项目头表中的元素ei,得到SW.tree中以ei为叶结点的分枝;
for each selected itemei。
(3){沿结点链查找各个以ei为叶结点的分枝,for each取到的分枝;
(4){将由根结点到叶结点ei的路径构成所有项目模式及各个子模式插入到fo.list中,各个插入模式的f值等于ei.f;若插入模式已存在于fo.list中,则fo.list中该模式的f值加上ei.f;}
(5)将叶结点ei从SW.tree中删除;}
(6)处理完所有元组,删除SW.tree;
(7)将fo.list按f值降序排序。
(8)输出所有在fo.list中f值大于δ|W|的模式。
End
2.3 离线层算法
离线层通常分析某时间段的聚类情况,针对用户的查询以在线聚类阶段形成的微聚类为基础进行离线聚类,利用衰减因子对微聚类进行动态维护,及时更新和衰减,得到相应时间段内的宏聚类。
算法实现如下:
input:时刻t1和t2,时间界定阈值ε。
output:t1到t2之间的聚类结果。
Begin
(1)ift1和t2是两个合法的时间点;
(2)将t1时刻的概要信息聚类得到的微簇作为中心微簇,并赋予类标号;
(3){while在内存中存储的每一个微聚类特征CF;

(5)endw;
(6)采用K-means算法对内存中的微聚类特征进行聚类,生成k个聚类;
(7)}
End
3 实验分析
本实验是在配置为Intel PentiumIV 3.0 GHz、内存1 GB的PC机上实现的,操作系统是Windows XP。所有程序采用Visual C++开发环境实现,并与基于界标窗口模型的CluStream算法进行性能比较。
实验中所使用的数据是网络入侵检测数据集KDDCUP99与IBM合成数据发生器产生的数据集T1516D1000K。KDDCUP99数据集共包含283 490条数据记录,每条数据记录共有41维固定特征属性,对其中22个连续型,9个离散型共31个属性进行分析。数据集T1516D1000K共包含305 732条数据记录,每条记录包含50维属性,其中,数值属性44维,分类属性6维[9]。
首先比较了在相同最小支持度阈值下两算法对1000K个事务的平均处理时间,取最小支持度阈值ε=0.5%,图2给出了SWStream算法与CluStream算法随事务到达的平均处理时间对比。从实验分析,SWStream算法时间效率明显高于CluStream算法。
接下来对内存使用情况进行比较。依然选取两个数据集产生的1000K个事务,图3是处理KDDCUP99和T1516D1000K数据集的实验比对结果。
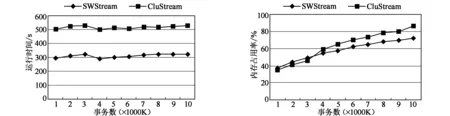
图2 相同事务数的平均处理时间比较 图3 内存使用情况比较
结果显示,随着数据流量的增多,SWStream的内存节省率高于CluStream。说明有效的衰减机制能够明显地节约内存开销。
4 结 论
在当前网络和数据库飞速发展的大环境下,数据流处理中的聚类分析要求也越来越多。CluStream算法给研究人员提供了在线和离线处理数据的框架,是数据流聚类方法中常用的一种,但当数据规模很大时,它不能有效地解决有限内存存储无限数据的可能。基于此,本文提出了改进算法SWStream,它是一种基于滑动窗口的流数据聚类算法,采用滑动窗口树作为概要数据结构,采用时间衰减策略有效地对过期微簇进行删除,节约了存储空间,提高了处理效率。实验表明,本文提出的基于滑动窗口的对动态数据流的处理算法,在准确度和运行效率上都有所提高。
[参考文献]
[1] 金澈清,钱卫宁,周傲英.流数据分析与管理综述[J].软件学报,2004,15(8):1172-1181.
[2] GUHA S,MISHRA N,MOTWANI R,et al.Clustering data streams[C]//41stAnnual Symposium on Foundations of Computer Science.Los Alamitos:IEEE Computer Society Press,2000:359-366.
[3] O’CALLAGHAN L,MISHRA N,MEYERSON A,et al.Streaming data algorithms for high-quality clustering[C]//18th Int’l Conf.Data Engineering. Los Alamitos,CA:IEEE Computer Society Press,2002:685-704.
[4] AGGARWAL C C,HAN Jia-wei,WANG Jian-yong,et al.A framework for clustering evolving data streams[C]//Proeedings of the 29th International Conference on Very Large Data Bases.Berlin Germany,2003:81-92.
[5] 周晓云,孙志挥,张柏礼,等.高维数据流子空间聚类发现及维护算法[J].计算机研究与发展,2006,43(5):834-840.
[6] 杨春宇,周杰.一种混合属性数据流聚类算法[J].计算机学报,2007,30(8):1364-1371.
[7] 吴枫,仲妍,金鑫,等.滑动窗口内进化数据流任意形状聚类算法[J].小型微型计算机系统,2009,30(5):887-890.
[8] 孙焕浪,赵法信,鲍玉斌,等.CD-Stream——一种基于空间划分的流数据密度聚类算法[J].计算机研究与发展,2004,41(S):289-294.
[9] AGGARWAL C C,HAN Jia-wei,WANG Jian-yong,et al.A framework for projected clustering of high dimensional data streams[C]//Proceedings of the 30th International Conference on Very Large Data Bases.Toronto,Canada,2004:852-863.
[10] 张忠平,王浩,薛伟,等.动态滑动窗口的数据流聚类方法[J]计算机工程与应用,2011(7):135-138.
[11] 李子文,邢长征.滑动窗口内基于密度网格的数据流聚类算法[J].计算机应用,2010(4):1093-1095.
[12] 林国平,陈磊松.一种网格和分形维数的数据流聚类算法[J].郑州大学学报:理学版,2009,41(2):24-28.
