基于异方差PLDA的外观流形建模视频人脸识别
2014-03-14孙伟强
孙伟强
(辽宁广播电视大学,辽宁沈阳110034)
由于视频图像有许多优点,视频人脸识别已经得到了广泛的应用,例如安防监控系统、手持设备和多媒体数据库等[1-2]。使用视频有益于提高识别率,视频包含的信息多于图像,分类的精确性、确定性和可靠性都会提高,这些信息也会用于观察条件不佳情况下的补偿,而图像人脸识别只允许在较低干扰系统下实现[3-4]。
至今,学者们已经提出了许多视频人脸识别方法,例如,文献[5]将图像集表示成一个线性子空间,使用子空间之间的正则角度计算它们之间的距离,称为交互子空间方法(MSM)。文献[6]对集占有的区域使用凸近似,如凸包或仿射包,通过寻找最近距离来衡量包间相似性,对应于合成最接近的粒子对。文献[7]通过使用距离计算样本系数稀疏性的规范化约束改进了上述算法,很多情况下,这些全集表示都是有效的,然而,它们不是以人脸外观流形的非线性(局部拓扑结构)建模的,稀疏约束能改善性能的事实表明整体的近似会导致过高的估计[8]。为了对流形的局部结构建模,图像集主要表示成分段局部线性模型,从图像集的聚类可以学习到这些表示,文献[9]和文献[10]从聚类构建线性子空间作为局部模型,为了评估两个图像集之间的相似性,计算了局部模型之间的成对距离,并通过融合策略对它们进行合并;另一种方法是融合过程之前在探针集中计算每幅图像的点到模型距离。提到的这些方法都是以非判别方式构建局部模型的,经常需要与最优分类的贝叶斯先验进行协调。文献[11-13]提出通过人脸外观流形的判别学习[11]、线性投影矩阵[12]及流形嵌入的非线性映射[13]学习构建局部模型的邻居图像,从而更好地分离不同人的局部模型,增加同一个人的局部模型紧凑性。尽管这些方法都取得了不错的识别效果,然而,在这些现存的方法中,大部分都是在非判别方式下执行的,在每个图像集上进行训练,不直接学习集之间的差别,往往不能很好地学习局部模型特定协方差。
基于上述分析,为了更好地识别视频中的人脸,提出了一种基于异方差概率LDA的外观流形建模算法,通过构建分段局部线性模型,以高斯分布的集合建模,使用异方差概率线性判别分析(PLDA)学习,实验结果验证了所提算法的有效性及可靠性。
1 概率线性判别分析
概率线性判别分析或者PLDA是一个通用的模型,用于描述如何观察从潜在空间生成的人脸图像,分配适当的参数来对模型进行训练,以便它可以支持精确的预测和合理的不确定性估计。令M个视频中M个不同人X1,X2,…,XM作为训练数据,每个视频是D×1维矢量图像(或者是派生特征向量)的集合,如果用xij表示第i个人的第j幅图像,PLDA的数据生成过程可表示如下

假设每个观察数据点xij是从潜在空间hi和wij生成的点,称hi的空间为类间空间,wij的空间为类内空间,正如下标所示,来自同一个人的观察共享相同的h值,但有自己的w值,因此,h项也称为潜在身份变量(LIV),对于每个人来说,它是独一无二的。向量hi和wij应该小于xij,且遵循附加的观察平均μ和剩余噪声εij,分别由线性变换F和G映射到观察空间。注意,x,h,w和ε是有多元高斯分布的随机变量,条件概率可描述为
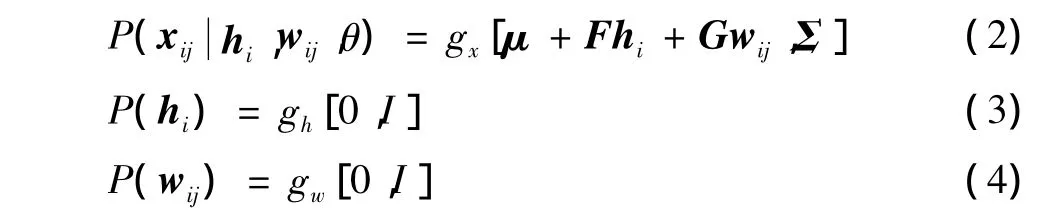
式中:θ=(μ,F,G,Σ)是建模参数;Σ是剩余噪声ε的对角协方差矩阵。
使用这个模型有两个阶段:训练(离线)阶段和识别(在线)阶段。训练阶段,该算法试图优化似然函数
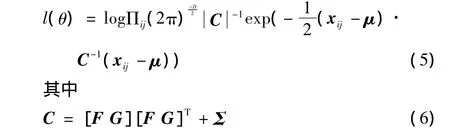
识别阶段,使用训练模型去推断探针数据的身份,如果在模型比较过程中使用统一的先验知识,探测图像xp和图库图像xm之间的匹配得分可定义如下

式中:P(xm,xp)和P(xm)是生成的数据点的似然值,对于P(xm,xp),要外加假设这两个点是从相同的LIV生成的,为了评估P(xm,xp)和P(xm),生成方程改写为
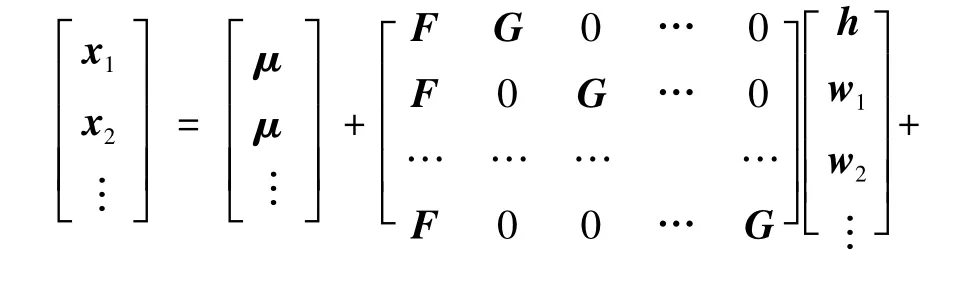

然后计算gx'[μ',AAT+Σ'],其中,Σ'是ε'的对角协方差矩阵。式(8)和式(9)有通用的形式,可以用来获取P(xm,xp)和P(xm),因此,也可以推广到图像集(Xm和Xp)似然评估的情况。
2 方法提出
为了更好地识别视频中的人脸,提出了基于异方差概率现行判别分析的流刑学习方法,提出的方法包含两个部分:利用图库中所有视频的人脸进行外观流形建模;利用匹配探测和图库视频进行身份认证。为了完成这两个任务,采用了异方差PLDA模型。
2.1 异方差概率线性判别分析
异方差PLDA能使人脸样本减少“预测的”高斯分布,从而可以得到更好地近似非线性流形。尽管能逐个对类内协方差建模,它们都保持在单个类间协方差的顶端。
通过对每个人/类的类内协方差分开建模的方式将标准PLDA扩展成了异方差PLDA,在这个新模型下,式(1)的数据生成过程变为

式中:G不是唯一的,以类标签i为索引,这个模型的参数可记作 θ=(μ,F,G1,2,…,M,Σ),似然函数为

为了训练异方差模型,执行如下算法:
2)重复下述过程直至融合:
E-step:为每幅训练图像 xij计算 E(zijxij)和,给出当前的θ。
M-step:使用 E-step 获得的值计算新的 F,G1,2,…,M和Σ。
以上步骤,N是训练图像和z=[hTwT]T的数目。项xij表示第i个人的所有训练图像,E-step类似于标准PLDA中的 E-step,为每幅图像计算2个预期值E(zijxij)和E(zijzTijxij),指定某个人所有图像的预期值是同时计算的,由那些图像的第一次列出的通用等式实现,如式(8)。这次如果考虑的是第i个人,则用Gi取代式(8)中的G,然后用得到的式子计算
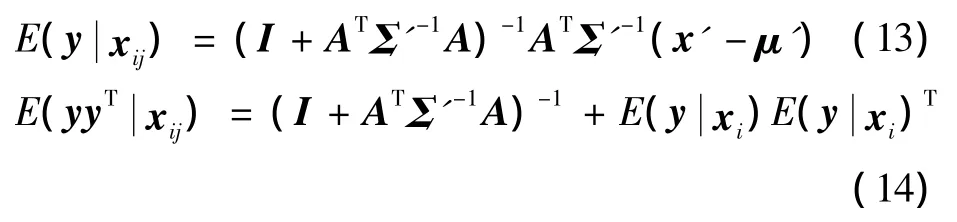
式中:y,x',μ',A 和 Σ'是式(9)中的项,E(zijxij)和E(zijzTijxij)分别从E(yxij)和E(yyTxij)中提取出来。
异方差PLDA的M-step从式(11)中推导出来,更具体的就是试图最大化以下函数

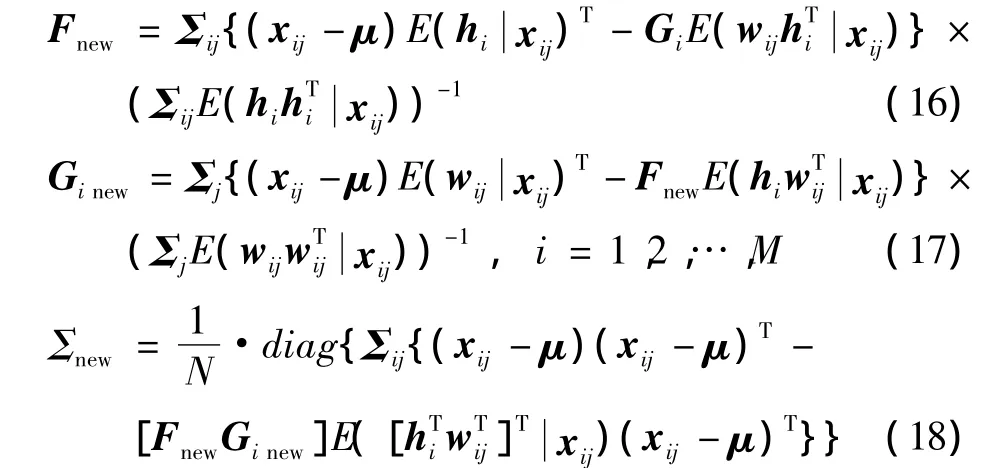
2.2 人脸外观流形建模
图库中每个视频都包含一个人的各种人脸外观,使用分段局部线性模型对这些外观建模,首先通过聚集视频帧找到每个视频的局部结构,然后,使用异方差PLDA模型学习聚类结果,获得表征分布的参数。
为了聚集视频帧,任何聚类算法都可使用,因此,提出了一种基于PLDA的增量式合并聚类方法,该方法首先使用图库X1,X2,…,XM中所有视频训练标准PLDA模型θ=(μ,F,G,Σ),然后,视频 Xi的聚类过程可描述如下:
1)创建第一个聚类Xi1,包含视频的第一帧和集合Ki,即在Xi的聚类数目为1。
2)对每个剩余帧xij:
(1)在已经存在的聚类中寻找一个与xij相似度最高的聚类:


(2)如果得分低于预定义阈值δ:Ki增加1;为xij创建一个新的聚类XiKi,否则,包含xij到Xik';执行聚类迭代合并,即当时,Ki减1;合并2个与Xil'相似度最高的聚类,即l',m'=
3)对于每个聚类,如果它的成员少于确定值η,合并这个聚类到最相似的且成员多于η的聚类。
上述过程聚类之间的相似性计算如下
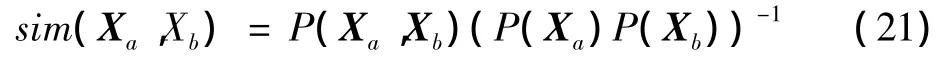
式中:P(Xa,Xb),P(Xa)和P(Xb)使用如式(7)所示的预训练的标准PLDA模型计算得到,整个实验,设置阈值δ为0,η为4。注意,整个过程结束时,视频可能会有不同数目的聚类。
如前文所述,形成的聚类将作为局部线性模型的样本,异方差PLDA,聚类被建模成高斯分布,在训练的异方差模型中每个聚类将关联于其中一个G,训练算法本身会搜寻最优类间协方差(特征为F)和类内协方差(特征为G)。在训练过程中,所有聚类都是针对不同人的,例如,聚类 X11,X12,…,X1K1,X21,…,XMKM是 X1,X2,…,XK的重新索引,其中K=ΣiKi。训练结束后,学习的G要重新索引,以便GiK与XiK相关联。
2.3 概率融合匹配
为了识别探针视频,匹配每一帧到图库的所有聚类并融合匹配得分,已知探针视频Xp有R帧xp1,xp2,…,xpR,帧xpr与聚类Xik之间的匹配分数计算如下

另外,P(Xik,xpr)和P(Xik)计算方法相同,但是式(8)中的G由训练的异方差模型的Gi取代,xpr和整个视频Xi的匹配分数由下述最大化规则获得


最后探针视频Xp和图库视频Xi之间的匹配分数计算如下选定argmaxxiS(Xi,Xp)为匹配身份,它具有最大的融合匹配得分。
2.4 算法整个过程
所提算法的整个过程如图1所示。

图1 所提算法的整个过程
训练阶段:
1)通过聚集视频帧找到每个视频的局部结构;
2)对视频帧进行聚类;
3)使用异方差PLDA模型学习聚类结果,获得表征分布的参数。
识别阶段:
1)匹配每一帧到图库的所有聚类;
2)并融合匹配得分;
3)根据最大融合匹配得分原则完成视频人脸的识别。
3 实验
实验使用MATLAB7.0在个人计算机上实现,计算机配置为:Windows XP操作系统、迅驰酷睿2处理器、2.53 GHz主频、4 Gbyte RAM。在公开的数据库CMU Mo-Bo[14]和 Honda/UCSD[15]上对提出的方法作了评估,也将所提方法与其他文献中提出的方法作了比较。
3.1 MoBo数据集上的实验
实验在MoBo数据集的正面视图子集上执行,该子集包含在跑步机上行走的25个人的99个视频序列,每个人有4个序列对应于4个行走模型:慢、快、倾斜和抱球(缺少了一个人的持物序列),视频中包含姿势和表情的变化,对这些视频使用Viola-Jones探测器检测人脸,并将图像裁剪为40×40灰度大小,然后提取每幅图像的局部二进制模式(LBP)直方图特征集,划分图像为25个8×8像素的方块,在每个方块上计算以圆(8,1)为邻域的统一LBP直方图,产生的所有直方图连起来产生最终1 476×1的特征向量。
共执行了12次实验,得到识别率的平均值和标准差,最初,在原始基于行走模式分组上执行了4倍交叉验证,选取其中一个组作为训练集/图库,剩下的作为测试集,在每个视频打乱分组前重复两次交叉验证,每次实验中,使用标准PLDA聚类训练集中的图像,使用异方差PLDA学习,然后与测试集比对。
令F中包含24个基础向量,每个G中也包含24个基础向量。对文献中提到的其他3种较为先进的视频人脸识别方法进行了测试比较,包括 MSM[5]、SANP[7]和标准PLDA[12]。其中,SANP因其识别率高而被认为是最先进的算法;对于MSM来说,需要选择特征向量的数目,以便能保留98%的总特征值;对于SANP,标准参数值使用文献[7]中建议的值,图2表明了12次实验中各个算法取得的识别率,各算法的识别率从低到高排列,平均识别结果如表1所示。

图2 各方法在CMU MoBo数据集上的识别率

表1 各方法在CMU MoBo数据集上的平均识别率及其标准差
从图2和表1可以看出,所提算法明显优于其他几个方法,获得的平均分类率最高;其次为SANP方法,分类率仅略低于所提算法;另外两个方法MSM和标准PLDA性能明显欠佳。所提算法的标准差也是最低的,表明它比其他方法更稳定,优于标准PLDA的事实表明,为每个人分别构建类内协方差模型确实非常有效、益于识别。
3.2 Honda/UCSD数据集上的实验
Honda/UCSD数据集包含20个人的有姿势和表情变化的59个视频序列,使用Viola-Jones检测器检测每帧图像,并将人脸图像裁剪为20×20灰度大小,然后使用直方图均衡化每幅图像,通过矢量化图像原始像素来提取特征向量。
使用文献[9]中指定的标准训练/测试配置在这个数据集上执行实验,即20个序列用作训练集/图库,剩余的39个序列作为测试集,为了得到更详细的结果,对每个视频都执行了多次实验,并且限制了用于训练模型和识别视频的最大帧数目,使用与CMU MoBo数据集相同的参数值执行实验,视频帧数分别设置为50、100及全长,表2列出了4种方法相对于不同最大帧数目的识别率。
从表2可以看出,使用全长视频识别的情况下,所提算法及SANP得到的性能最佳,识别率可达100%;标准PLDA性能略差;MSM性能远低于其他三种方法。当最大帧数目减小到100时,所提算法优于SANP,标准PLDA排第三,在这种情况下,所提算法仍能获得几乎完美的识别率。
当视频长度限制为50帧时,SANP能获得最佳性能,所提出的方法降为第三,甚至不及标准PLDA,这表明在训练集不是很充足的情况下,异方差PLDA不能可靠地估计指定人的类内协方差,标准PLDA这种均匀模型可能会获得更好的估计,或者,某个人的整个数据可能被更好地全局建模,然而这类情况不是本文首先要考虑的情况。

表2 各方法在Honda/UCSD数据集上的分类率
3.3 性能比较及分析
为了更好地体现所提算法的优越性,将其复杂度与标准PLDA、MSM、SANP算法进行了对比,分别比较了训练时间复杂度、测试时间复杂度及空间复杂度,具体比较结果如表3所示,其中,m和n分别表示图像矩阵的行数和列数,L,M和N分别表示投影向量数、测试样本数和训练样本数。

表3 各算法的复杂度比较
从表3可以看出,与标准PLDA算法相比,所提算法的各个复杂度均相当;与MSM算法相比,所提算法的训练阶段时间复杂度稍微高了点,但是测试阶段的时间复杂度比MSM算法低了一半;与SANP算法相比,所提算法的训练阶段、测试阶段时间复杂度及总体空间复杂度均低了很多。在大大提高识别率的同时,所提异方差概率LDA流形学习算法仍然能够保持与其他相关算法相当甚至更优的复杂度,由此可见其优越性。
4 总结
针对现有的视频人脸识别方法不能很好地学习局部模型特定协方差的问题,为了更好地识别视频中的人脸,提出了基于异方差概率线性判别分析的外观流形建模算法,以高斯分布集合作为人脸外观流形模型,采用了异方差概率线性判别分析(PLDA)来判别性地学习流形。在训练期间,对从视频中采集的人脸图像进行聚类,同时学习所有人的聚类。为了识别一个新颖的视频,视频要与训练模型按帧匹配,然后融合得到各个类的得分。在两个基准数据库上进行了实验,将提出的方法与其他几种视频人脸识别算法进行了比较,虽然匹配策略很简单,但提出的方法能获得较高的识别率,表现出的性能也很稳定,并且具有较低的时间复杂度和空间复杂度,标准和异方差PLDA之间的比较也证实了局部模型特定协方差建模的有效性。
未来会将本文算法应用到其他的视频人脸数据集上,进行大量的实验,在提高识别率的同时,进一步降低算法的计算复杂度,从而更好地运用于实时人脸识别系统。
[1]严严,章毓晋.基于视频的人脸识别研究进展[J].计算机学报,2009,32(5):878-886.
[2]张亮亮.基于对称子空间分析的人脸识别方法研究[D].济南:山东大学,2011.
[3]王晓侃,毛峡.基于非线性流形学习的人脸面部运动估计[J].电子与信息学报,2011,33(10):2531-2535.
[4]张鑫.基于SIFT算法的ATM视频人脸识别系统研究[D].哈尔滨:哈尔滨工程大学,2012.
[5]刘亚楠,吴飞,庄越挺.基于多模态子空间相关性传递的视频语义挖掘[J].计算机研究与发展,2009,46(1):1-8.
[6]CEVIKALP H,TRIGGS B.Face recognition based on image sets[C]//Proc.2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2010:2567-2573.
[7]HU Y,MIAN A S,OWENS R.Sparse approximated nearest points for image set classification[C]//Proc.2011 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2011:121-128.
[8]刘向阳.多流形数据建模及其应用[D].上海:上海交通大学,2011.
[9]张懿,刘国海,魏海峰,等.基于二次仿射传播聚类的非线性系统多模型 LSSVM 建模[J].控制与决策,2012,27(7):1117-1120.
[10]陈定三.基于聚类的多模型建模及其在软测量中的应用[D].无锡:江南大学,2011.
[11]范小九,彭强,夏旭.一种改进的AAM人脸特征点快速定位方法[J].电子与信息学报,2009,31(6):1354-1358.
[12]李乐,章毓晋.基于线性投影结构的非负矩阵分解[J].自动化学报,2010,36(1):23-39.
[13]何强,蔡洪,韩壮志,等.基于非线性流形学习的ISAR目标识别研究[J].电子学报,2010,38(3):585-590.
[14] 鲁珂,丁正明,赵继东,等. 一种基于相关反馈的视频人脸算法[J].西安电子科技大学学报: 自然科学版, 2012, 39(3) : 154-160.
[15] 代毅,肖国强,宋刚. 隐马尔可夫后处理模型在视频人脸识别中的应用[J]. 计算机应用, 2010(4) : 960-963.
