基于字的分布表征的汉语基本块识别
2014-02-28李国臣党帅兵王瑞波李济洪
李国臣,党帅兵,王瑞波,李济洪
(1.太原工业学院 计算机工程系,山西 太原 030008;2. 山西大学 计算机与信息技术学院,山西 太原 030006;3. 山西大学 计算中心,山西 太原 030006;)
1 引言
汉语句法分析体系,目前主要有两种: 第一种是直接在分词、词性标注的基础上构建汉语句子的完全句法分析树,另外一种是将汉语句子分割成不同层面的语块的浅层句法分析。后者的典型代表是周强等提出的语块分析体系[1]。该体系中提出了汉语基本块、多词块和功能块3种块。周强构建了相应语料,并设置了汉语基本块等自动识别任务,开发了自动分析工具。周强构建的第一个基于规则的汉语基本块分析器[2],在其测试集上F值达到89.47%。不过,该基本块分析器十分依赖于汉语句子的分词和词性标注性能。后来,宇航等[3]使用条件随机场模型构建了一个汉语基本块标注模型,模型的F值达到89.54%。在周强组织的汉语基本块分析评测CIPS-Pars-Eval-2009中,基本块自动识别的最好结果为F值[4]93.20%(封闭测试)和90.53%(开放测试)。
需要注意的是,上述评测任务中,绝大多数是通过使用最大熵、条件随机场等模型对汉语句子中的每个词语进行标注,直接将词语、词性等原子特征及组合特征加入到学习算法中进行训练,并最终将预测得到的标记合并成汉语基本块的识别结果。这种做法存在两个问题: 第一,这些基本块识别模型的性能非常依赖于测试集中分词的正确性和一致性。设想如果测试集中使用的分词规范和训练集不一致时,基本块自动识别的性能会有很大的下降。第二,这些基本块识别模型主要使用词、词性等示性特征,机器学习算法很难学习、泛化相同或相近句法结构而使用不同词语表达的样例。
第一个问题的一种解决思路是避免使用词语作为标注单位,而直接使用汉字作为标注单位。这样可以避免由于分词错误或者不一致而导致的基本块标注的性能明显下降。目前,已经有很多的研究工作在探究直接从汉字出发来识别句法块,构建汉语句法分析树[5]。本文采用这种方法,直接将汉语基本块看作是以汉字为标注单位的任务,并使用条件随机场、最大熵和深层神经网络等机器模型来进行标注。
第二个问题中,我们可以使用几种方法来将词语之间的句法、语义关联信息加入到机器学习算法中。其中,一种方法是,直接使用知网、同义词词林等人工构建的语义资源,以这些资源构建特征加入到机器学习算法中,来提高模型识别的性能[6]。另外一种方法是,使用潜在语义分析,PLSA[7]以及LDA[8]等算法在使用大规模生语料库训练出各个词语的实值向量表示,并将这些表示作为特征加入到机器学习算法中,来改进模型识别的精度。在本文提出的方法中,我们直接使用两种经典的神经网络模型(C&W[9]和word2vec[10-12])在大规模语料上进行无监督的训练,得到汉字的分布表征,并将这种表征加入到基于字的汉语基本块识别模型中,来验证该分布表征信息对模型性能的影响。
使用神经网络来获取字以及词的分布表征信息已经得到了研究者的广泛关注。其中,最著名的是Bengio等人[13]提出的语言模型。该工作中,将英文句子中词语的n-gram串通过一个实值矩阵映射成一个固定维度的实值向量,然后将其作为输入,使用神经网络模型构建了一个概率语言模型。在大规模语料上进行训练中,不断地对实值矩阵中的各个元素进行更新学习,最终形成了每个词语的分布表征。在Collobert和Weston等人[9]的工作中,通过替换n-gram词串的当前词来构造出一些伪例,然后将真实的n-gram串和构造的伪例作为训练样本,使用hinge损失函数来无监督地训练整个神经网络模型,获得了英文词语的分布表征。后来的很多研究工作将这种方法获得的分布表征称为C&W分布表征。另外一个著名的工作是Mikolov等人提出的[10]。该工作中提出的CBOW方法和Skip-gram算法具有训练速度快、分布表征性质良好等特点。这些工作中有很多的例子表明,使用大规模无监督的语料进行训练后,词语的分布表征可以较好地体现原词语的句法、语义信息的相似性。本文主要使用了汉语字的C&W[9]分布表征和word2vec[10-12]分布表征(使用CBOW方法获得)。
字和词的分布表征也被很多研究者使用到自然语言处理的各种任务之中,例如,英文的情感分析、词性标注、命名体识别、语义角色标注以及汉语的分词[14]、基本块识别[15]等任务中。Collobert和Weston等人的研究工作[9]将英文中的词性标注、名命体识别和语义角色标注等多个任务直接放入到一个神经网络模型中,使用分布表征矩阵来将英文词映射到实值向量上,并使用梯度下降算法进行训练,得到了一个接近于目前最好性能的自然语言理解模型。Turian在文献[16]中提出一种适用于自然语言理解任务的半监督学习框架,即: 将无监督训练得到的词语的分布表征作为特征加入到有监督的机器学习算法中,来改进各种自然语言理解模型的性能。来斯惟等人使用字的分布表征和神经网络算法来构建汉语分词模型[14]。他们的实验结果表明,该方法在汉语分词任务上有很大的潜力。侯潇琪等人[15]将词的分布表征加入到基本块识别模型中,在正确分词基础上BIO的标记精度达到85.90%的。不过,该工作使用词作为标注单位,实用中标注结果明显依赖于分词性能的好坏。
本文直接将字作为标注单位来构建基本块识别模型。在仅仅使用以字构建的特征下,本文对比了条件随机场、最大熵和深层神经网络等标注模型,并对比了字的随机向量表示、C&W表示和word2vec表示三种分布表征。实验结果表明,在[-3,3]窗口下,将字的word2vec分布表征融入到五层神经网络下,汉语基本块的识别性能最好,可以达到77.12%的F值。本文的主要目的是基于汉语基本块识别任务,探讨汉语词语的表示学习以及深层神经网络语言模型的有效性。
本文章节安排如下: 第2节介绍了本文的整个基本块识别模型框架,并详细给出了本文使用的深层神经网络的具体配置以及标注算法所使用的标记集合;第3节描述了本文所用的实验数据、实验设置和评价指标;第4节总结了实验结果,并进行了深入的分析;最后对本文工作做了总结,并给出下一步的研究方向。
2 基于字的汉语基本块识别模型描述
本文将基本块识别转化成汉字的序列标注任务,然后借助于多种统计机器学习算法对该序列标注问题进行建模。
2.1 问题描述
汉语基本块识别任务是对给定的一个汉语句子,标注每个基本块的位置,确定基本块中所包含的具体词语。由于一个句子中的汉语基本块不存在重叠、嵌套和交叉问题。因此,我们可以很容易地将其转化成一个序列分割问题,数学描述如下:
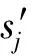
上述的序列分割问题,通常要引入一个标记集合来将一个分割的识别问题转化到分割中所包含字的标注问题,即: 给分割中包含的每一个字赋予一个标记来标识该字在分割中的位置。常用的标记集合有IOB1, IOB2, IOE1,IOE2, IOBES等,具体的转化方法请参见文献[17]。本文中采用了IOBES标记集合。其中用“S”标记单字基本块,对于包含多个字的基本块,块中的第一个字用“B”标记,最后一个字用“E”标记,中间的字用“I”标记,对于块外的字统一用“O”标记。具体的对应关系如下例所示。
原始句子: 医和药是密切相关的。
基本块信息: [ 医 ] 和 [ 药 ] [ 是 ] [ 密切相关 ] 的 。
标记信息: 医/S 和/O 药/S 是/S 密/B 切/I 相/I 关/E 的/O 。/O
通过转化,基本块识别问题可以转化成一个序列标注问题: 给定汉语句子序列X=(x1x2…xn),正确识别出一个句子的基本块信息标记序列Y=y1y2…yn,其中,yi属于{I,O,B,E,S}。即找到:
(1)
s.t.Y*是一个合理的序列,可以还原出基本块信息。
2.2 深层神经网络模型
解决式(1)所描述的问题,条件随机场模型[18]是一种较好的算法。不过,本文仅在一部分对比实验中使用了条件随机场模型。本文主要关注最大熵模型和深层神经网络模型。这两种模型均把式(1)描述的原始问题转化成如下的问题:
s.t.Y*是一个合理的序列,可以还原出基本块信息。
实际上,只有当标记序列Y中任意两个yi和yj(i不等于j)之间相互独立时,式(1)才可以转化成式(2)和式(3)。在本文中,为了简单处理,我们假设这种独立性成立。最大熵算法的基本思想和模型形式在文献[19]中已经给出了很好的描述。这里,我们仅给出本文使用的深层神经网络模型的结构及一些参数设置。
本文所使用的深层神经网络为5层结构(算上原始输入层),如图1所示。其中,原始输入是w个字在字表中对应的索引值,然后通过在分布表征矩阵中查找出这w个字中每个字所对应的n维的实值向量,并依字序首尾相接成的w·n维的实值向量v。在第1隐层直接使用tanh函数对向量v进行非线性变换形成h1,该层中的每个节点h1j都与表示层中的每个节点vi相连。进而,在第2隐层中,将h1使用tanh变换得到h2。同样,h1和h2之间的节点也是完全相连的。最后,在输出层,使用softmax函数对h2层的节点值进行概率归一化得出P(yi=t|X),t属于{B,I,O,E,S}。最终,使用输出层的5个节点中最大概率值对应的标记作为第i词的最终标记。
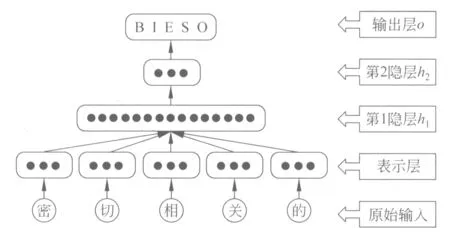
图1 深层神经网络模型图
2.3 字的分布表征
一般来说,在使用机器学习算法解决式(1)和式(3)中描述的问题时,并没有将整个句子X中的所有信息引入来预测每个字的标记信息。在预测第i个字的标记时,通常只是将该字周围的一些字的信息作为特征加入到机器学习算法中,即,使用开窗口的方式来进行特征选取。本文也采用了这种做法。
区别于直接使用字、词作为特征,本文使用了字的分布表征作为特征信息。不同于字的0-1向量表
示,字的分布表征是将字表示成为一个定长的实值向量。该实值向量是通过某个表示学习模型来获得的。具体请参考本文第一部分给出的相关文献。
需要注意的是,假设常用字有5 000个,并且特征窗口设置为[-2,2],如果直接使用字的0-1向量表示作为特征,那么机器学习算法就必须处理25 000维的特征向量。如果再考虑上字、词特征之间的组合特征等,那么特征向量的维度会成倍地往上增长。这很容易引起维数灾难问题。并且,在这样的特征矩阵里,存在着严重的稀疏问题。字的分布表征一般为低维(比如100维)的实值向量,那么上面的问题就可以转化为一个在500维特征上的一个学习问题。值得说明的是,字的分布表征中能学习到字之间的句法、语义的某些关联性,这为自然语言处理许多任务带来新思路、新方法。下面的几节中,给出汉语基本块识别任务实验。
3 实验设置
本文实验主要关心使用字的分布表征来进行基本块的识别实验。在所有实验中,基本块的识别问题被转化成字层面的序列标注问题。本文主要使用了IOBES标注集合。实验中尝试了多种机器学习算法,并对它们进行了比较。
3.1 实验语料
实验语料使用了CIPS-ParsEval-2009中发布的汉语基本块分析语料。语料库总规模为765 820字, 训练文件数为171个, 包含14 249条句子, 共计618 231字。测试文件数为 43个, 包含3 751条句子 ,共计147 589字。语料中,基本块的块长(块中所含字数)统计如表1所示。

表1 基本块语料块长度统计
从表1中可以看出,块长小于等于5的块占到近95%,而长度不大于7的块占所有块的99%。因此,在实验中,本文分别使用[-2,2]和[-3,3]窗口内的字的分布表征作为特征,来对当前字进行标注。
3.2 要对比的标注模型
本文使用了3种标注模型: 最大熵、条件随机场和深层神经网络。其中,条件随机场模型在序列分割和标注任务中得到了广泛的应用[18]。本文使用了张乐博士开发的MaxEnt最大熵工具包[20]。在将字的分布表征作为特征值代入到最大熵工具时,做了平移处理(加上某个常量)让所有的值都转变为正数。实验中,高斯惩罚参数设为1.0。本文使用的深层神经网络模型是在pylearn2工具包[21]上开发得到的。本文主要构建了一个五层神经网络模型,该模型的结构在3.2节中给出。其中,第一个隐层的单元个数为300,第二个隐层的单元个数为100。另外,本文进行对照实验使用条件随机场模型的crfpp工具包[22]。
3.3 字的分布表征学习算法
本文使用C&W算法[9]和 word2vec工具包[10-12]的CBOW算法来获得字的分布表征。其中,我们设置每一个字使用100维的实值向量来表示。两种工具包的训练语料均使用的是山西大学500万分词语料。学习分布表征前,我们对语料库进行了简单的预处理,把所有的英文字母统一用“WORD”表示,所有的数字用“NUMBER”表示。在进行基本块识别前,我们将每一个字的分布表征单位化成一个长度为1的向量。
在C&W算法中,本文仅将隐层设置为一层,学习率设置为0.000 000 01,迭代时使用的是句子中字的5元组作为原始输入。模型使用BGD(Batch Gradient Descent)优化算法,其中,每一个minibatch设置为1 000。由于该表示学习算法可以无限地迭代下去,本文仅选择迭代到5 500万minibatch后生成的字的分布表征。
在word2vec工具包中,本文使用的是CBOW算法,并且使用层次化的softmax层作为输出层,在训练时设置窗口大小为5。
为了观察C&W方法和word2vec方法的训练效果,本文仿照文献[14],选取了“一”、“李”、“江”和“急”4个字,并给出了它们的最相似字。这里,我们先将字的分布表征向量进行单位化,然后使用夹角余弦计算相似度。具体结果见表2。
从表2中可以看出,C&W和word2vec两种方法学习到的字的分布表征还是有所差别的。从直觉来看,C&W方法对“李”的聚类结果要比word2vec方法的要好。而对于“一”、“江”和“急”,两种方法的聚类结果尽管不尽相同,但是,并没有明显的好坏之分。
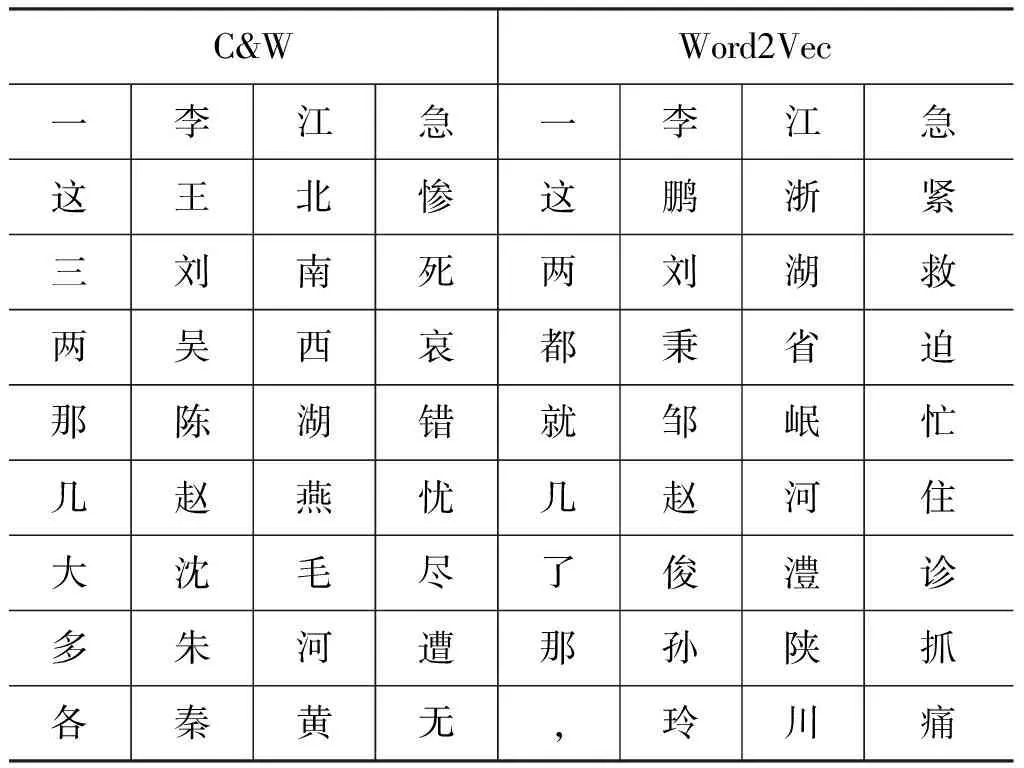
表2 不同字表示学习方法得到的“一”“李”“江”“急”的最相似字
3.4 评价指标
本文从字层面和块的层面来评价基本块识别模型的性能。其中,在字层面,本文使用了标记准确率,它指的是所有标签中标记正确的标记数与总的标记数的比值。在块层面,本文使用了块识别的准确率、召回率和F值。它们的定义如下:
4 实验结果和分析
本节中,我们首先分析了不使用字的分布表征,只使用字作为特征的各种基本块识别模型性能,然后又分析了使用字的分布表征的各模型性能,最后对基于词的神经网络模型与基于字的神经网络模型做了对比分析。
4.1 不使用字的分布表征的结果
我们直接将字作为特征代入到基本块识别模型中。表3和表4分别给出了两种学习算法使用字特征时的基本块识别性能。

表3 MaxEnt算法+字特征
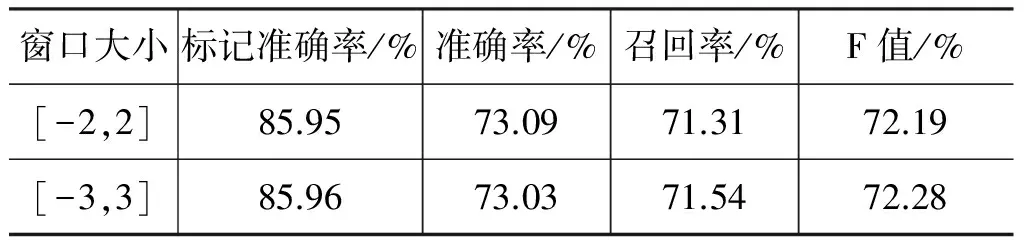
表4 Crfpp算法+字特征
对比表3和表4可以发现,两者的实验结果都较目前较好的一些基本块分析模型的性能[4]要差很多。这主要是因为上述实验中并没有考虑词性特征和词、词性的组合和搭配特征,而这些特征的加入可以明显改善基本块识别的性能。之所以不加入这些特征,主要是本文旨在探讨字的分布表征对基本块识别的影响。
表5中给出了将词作为标注单位,将[-2,2]窗口内的词特征加入到条件随机场模型中,进行基本块识别的结果。为了对比字特征与词特征对于基本块识别性能的影响,我们在实验中也未使用词性特征,以及多元的组合搭配特征。
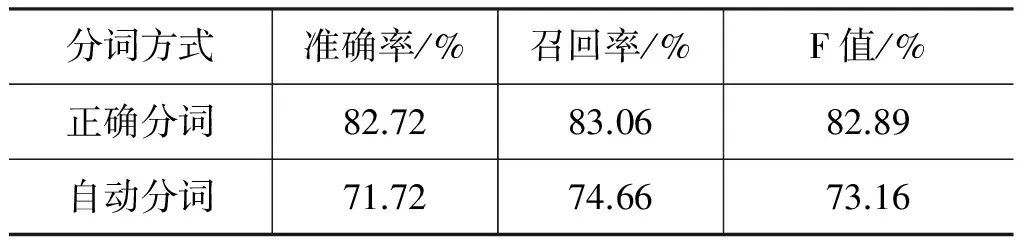
表5 词为标注单位+Crfpp+[-2,2]窗口
从表5中可以看出,如果分词信息正确,基本词层面的块识别F值可以达到82.18%。但是,当使用山西大学分词软件FC2000对测试集的句子自动分词后,基本块识别的F值仅可以达到73.16%,明显低于分词信息正确时的实验结果。这说明以词语为标注单位的基本块识别模型在实际使用中,对于分词系统的性能有着很大的依赖性。这也是本文希望研究以字为标注单位的基本块识别模型的重要原因之一。
4.2 使用字的分布表征的结果
这一小节,我们将字的分布表征分别加入到最大熵模型,CRF模型和深层神经网络模型后的实验结果。
4.2.1 最大熵+字的分布表征
为了对比验证,我们将如下3种字的分布表征加入到最大熵模型中。3种分布表征中,除了包含上文提到的C&W字表示和word2vec字表示,本文还加入了完全随机的字表示。随机字表示是针对每一个字随机生成了一个100维的实值向量。向量中的每一个元素从[-0.01,0.01]的均匀分布中抽取,然后,对该向量进行单位化。
表6给出了将字的3种分布表征加入到最大熵算法中的基本块识别结果。

表6 MaxEnt算法+字的分布表征
对比表6中的3种分布表征的实验结果,可以发现,虽然C&W表示特征和word2vec表示特征的识别结果较完全随机的表示特征有着明显的上升(F值上升近10%~15%),但识别结果也很不理想(F值仅在50%左右)。探究其原因,从分类算法的角度来看,主要因为最大熵分类器并不考虑整个序列的全局优化,仅是针对每个字的标记的单点优化;从特征的表示来看,C&W和word2vec的分布表征尽管克服了原有的0-1表示特征的数据稀疏问题,但是,两种分布表征是使用无监督的方式训练得到的,而没有针对具体任务进行优化,因此,它们并没有很好地表达出基本块识别所需要的句法语义信息。
对比表6中的两种窗口下的实验结果,可以发现,窗口的扩大并没有带来识别结果的明显提升,甚至在随机分布表征和word2vec分布表征的两种情况下,窗口的扩大还带来了块F值的些许下降。
4.2.2 CRF+字的分布表征
为了与基于字特征的CRF模型作对比,我们把上述3种分布表征作为特征直接应用到CRF模型中。表7是得到的详细结果。
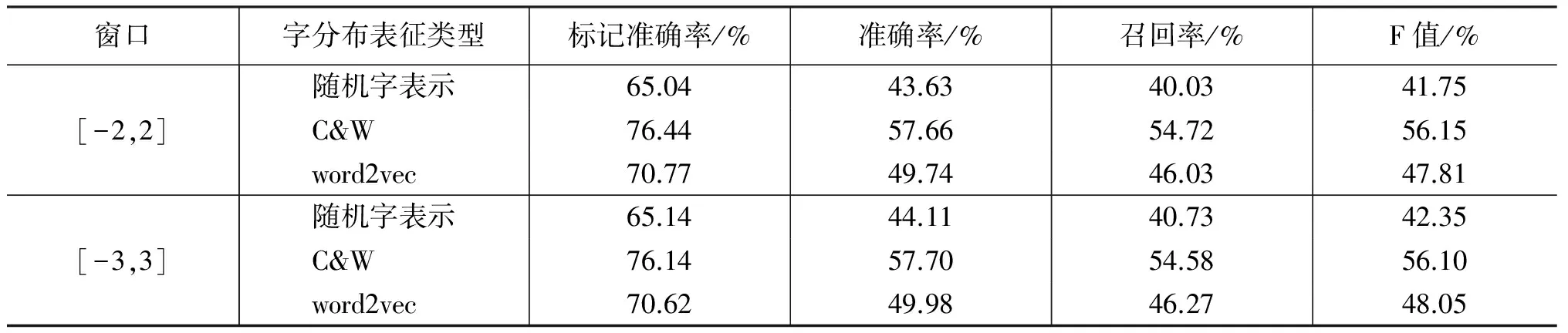
表7 CRF算法+字的分布表征
对比表7和表4,可以发现,使用字的分布表征时,其最好结果也明显低于仅使用字特征的CRF模型。
4.2.3 深层神经网络+字的分布表征
这一小节,我们给出了使用深层神经网络来进行基本块识别的实验结果。表8中详细总结了在两种窗口下3种分布表征的条件下,基本块识别的详细结果。
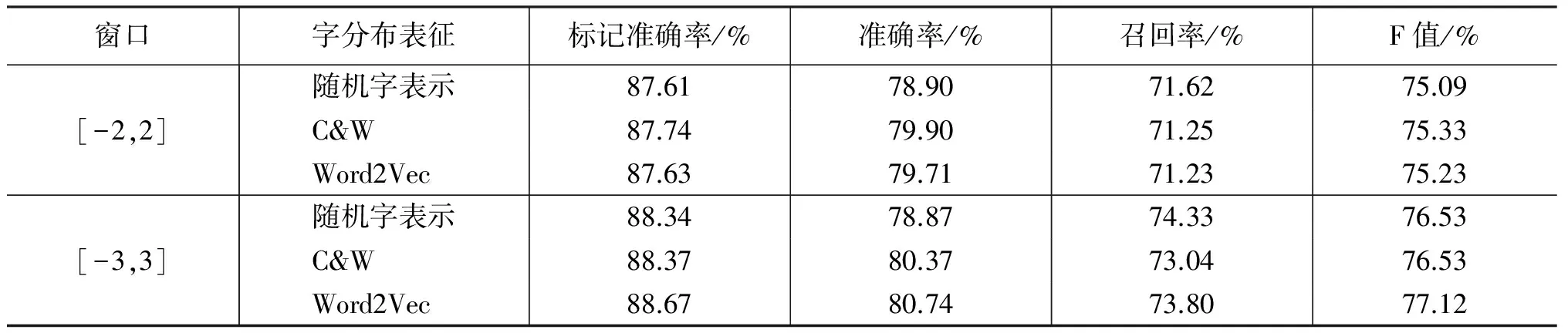
表8 深层神经网络+字的分布表征
分别对比表8和表6、表7,可以看出,5层的神经网络模型的实验结果明显好于最大熵模型和CRF模型。这一方面得益于深层神经网络模型使用多个非线性隐层来对原始的分布表征进行变换,形成更为有用的特征。另一方面体现出深层神经网络在进行基本块的学习过程中,对原有分布表征进行调整,形成了对基本块识别任务更为有利的分布表征。
对比表8中3种分布表征的影响,可以看出,尽管基于C&W分布表征和word2vec分布表征所得到的基本块识别结果都比使用完全随机的分布表征要好一些,但是3种分布表征的实验结果之间的差异不大,word2vec分布表征的结果略高一些。也就是说,3种表示作为深层神经网络的初始输入,对最后的基本块识别影响不大。这也说明,神经网络模型在迭代计算的过程,对字的分布表征进行不断地学习、修正,弱化了对初始值的依赖,形成了基本块识别任务需要的字的分布表征。
在表8中,不同窗口的实验结果表明,扩大特征窗口可以带来识别结果的明显上升。而且在[-3,3]窗口内,使用word2vec分布表征可以达到本文最高的识别F值,即77.12%。这明显好于表4中给出的条件随机场情况下使用字特征得到的实验结果(F值为72.28%)。需要强调的是,和最大熵模型一样,本文使用的深层神经网络模型是仅针对每个字的单点标记似然进行最大化,而不是优化整个序列上的似然函数。因此,使用深层神经网络的识别结果能高出条件随机场识别结果近5%的F值也是相当可观的。
另外,本文使用word2vec分布表征,分别用4层、6层神经网络也做了实验,其结果均低于5层神经网络模型,但差异不大(表9)。这说明,在汉语基本块识别任务中选择5层神经网络是合适的。从语言层面来分析,可以将h1隐层理解为关于词的特征表示,h2隐层可以理解为关于基本块的特征表示。字的分布表征是经过词的特征表示再到基本块的特征表示,或略掉词的特征表示层(h1隐层)直接到基本块的特征表示层(h2隐层),即用4层神经网络,是不可取的。同样,多于5层时模型结构难以从语言层面合理解释,相应的标注结果也有所下降。
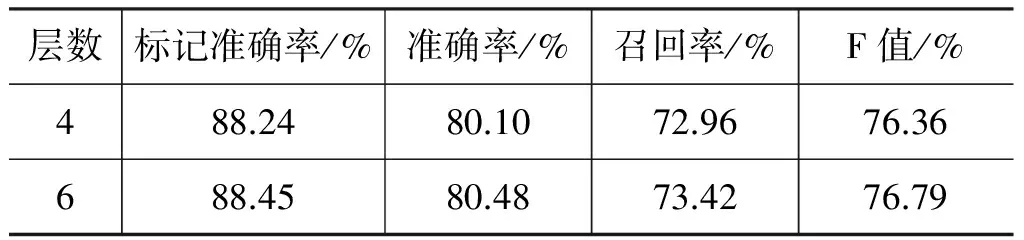
表9 使用word2vec的4层和6层神经网络的结果
4.3 基于词的深层神经网络模型结果
表10给出了基于词的神经网络模型结果,为了与基于字的神经网络模型作对比,测试集分别使用了原人工标注的正确分词语料和经过山西大学分词软件FC2000重新分词后的语料。
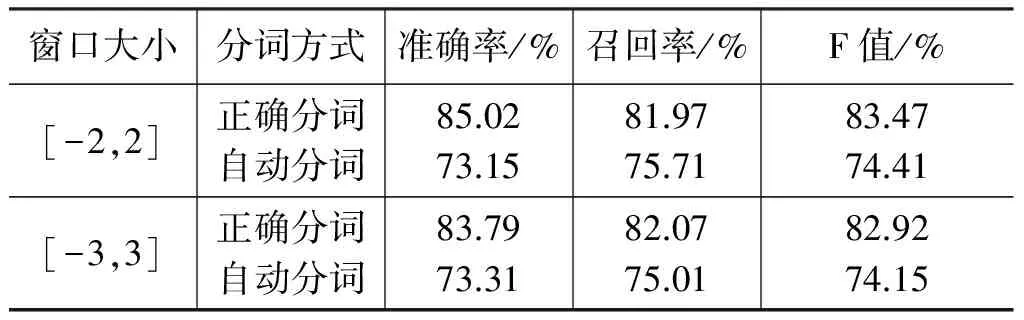
表10 基于词的神经网络模型
对比表10和表5可以看出,本文所用到的神经网络模型性能要优于CRF模型,这也与上一小节得到的结论一致。比较表10和表8可以看出当测试集使用自动分词语料时,其结果要低于基于字的神经网络模型,这也在神经网络模型上验证了4.1小节由表5得到的结论。
5 总结与展望
本文研究和对比了使用字的分布表征来进行基本块识别的若干种方法。在这些方法中,本文主要使用了最大熵、条件随机场和深层神经网络3种模型,并且使用了字的C&W分布表征、word2vec分布表征、随机的字分布表征,在[-2,2]和[-3,3]两种特征窗口情形下,我们对多个基本块识别模型进行了对比。实验结果表明,使用在[-3,3]窗口下,将字的word2vec分布表征融入到5层神经网络模型下,可以得到汉语基本块的一个较好的识别性能(F值达到了77.12%)。这个结果要明显好于直接将[-3,3]窗口内的字特征加入到条件随机场模型所得到的识别模型(F值为72.28%)。
实际上,本文的所有实验中并未能融入词性信息、字的组合搭配信息等更为丰富的特征信息。我们相信如果将这些信息进一步加入到本文的模型中,基本块的识别性能还会有大幅度的提高。但如何获得词性的分布表征以及相邻字的组合串的分布表征是需要我们进一步研究的。
[1] 周强,任海波,孙茂松. 分阶段构建汉语树库[C].
Proceedings of The Second China-Japan Natural Language Processing Joint Research Promotion Conference, 2002: 189-197.
[2] 周强. 基于规则的汉语基本块自动分析器[C].第七届中文信息处理国际会议论文集(ICCC-2007).2007: 137-142.
[3] 宇航,周强. 汉语基本块标注系统的内部关系分析[J]. 清华大学学报,2009, 49(10): 136-140.
[4] 李超,孙健,关毅,徐兴军,侯磊,李生. 基于最大熵模型的汉语基本块分析技术研究[R]. CIPS-ParsEval -2009.
[5] 赵海,揭春雨,宋彦. 基于字依存树的中文词法-句法一体化分析[C].全国第十届计算语言学学术会议(C- NCCL-2009), 2009: 82-88.
[6] 齐璇,王挺,陈火旺. 义类自动标注方法的研究[J]. 中文信息学报,2001,15(3): 9-15.
[7] 吴志媛,钱雪忠 .基于PLSI的标签聚类研究[J]. 计算机应用研究,2013,30(5): 1316-1319.
[8] David M. Blei. Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003(3): 993-1022.
[9] Ronan Collobert, Jason Weston, Léon Bottou, et al. Natural Language Processing (Almost) from Scratch[J]. Journal of Machine Learning Research (JMLR), 2011(12): 2493-2537.
[10] Tomas Mikolov, Kai Chen, Greg Corrado, et al. Efficient Estimation of Word Representations in Vector Space [R]. arXiv preprint arXiv,2013.
[11] Tomas Mikolov, Ilya Sutskever, Kai Chen, et al. Distributed representations of words and phrases and their compositionality[R]. arXiv preprint arXiv,2013.
[12] Tomas Mikolov,Wen-tau Yih, and Geoffrey Zweig.Linguistic Regularities in Continuous Space Word Repre- sentations[C]//Proceedings of NAACL HLT, 2013.
[13] Yoshua Bengio, Rejean Ducharme, Pascal Vincent, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research (JMLR),2003(3): 1137-1155.
[14] 来斯惟,徐立恒,陈玉博,刘康,赵军. 基于表示学习的中文分词算法探索[J]. 中文信息学报,2013,27(5): 8-14.
[15] 侯潇琪,王瑞波,李济洪. 基于词的分布式实值表示的汉语基本块识别[J]. 中北大学学报(自然科学版).2013,34(5): 582-585.
[16] Turian Joseph, Lev Ratinov, and Yoshua Bengio. Word representations: a simple and general method for sem- i-supervised learning[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL).2010.
[17] Taku Kudo, Yuji Matsumoto. Chunking with support vector machine[C]//Proceedings of the second meeti- ng of North American chapter of association for computational linguistics(NAACL), 2001: 192-199.
[18] John Lafferty, Andrew Mccallum, FernandoPereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of International Conferenceon Machine Learning (ICML 01). Williamstown, MA, USA, 2001: 282-289.
[19] Berger Adam, Stephen Della, Pietra Adam, Vincent Della Pietra. A maximum entropy approach to natural language processing [J]. Computational Linguistics, 1996, 22(1): 39-71.
[20] 张乐. 最大熵工具包MaxEnt(2004版)[CP/OL].2004.http://homepages. inf.ed.ac.uk/s0450736/maxent_ toolkit .html.
[21] Ian J. Goodfellow, David Warde-Farley, Pascal Lamblin, Vincent Dumoulin, Mehdi Mirza, Razvan Pascanu, James Bergstra, Frédéric Bastien, Yoshua Bengio. Pylearn2: a machine learning research library[J]. arXi-v preprint arXiv: 1308.4214.
[22] TakuKudo, CRF++toolkit[CP], 2005. http://crfpp.sourceforge.net/.
