语法和语义相结合的中文对话系统问题理解研究
2014-02-28黄沛杰吴秀鹏吴桂盛郭庆文陈楠挺陈楚萍
黄沛杰,黄 强,吴秀鹏,吴桂盛,郭庆文,陈楠挺,陈楚萍
(华南农业大学 信息学院,广东 广州 510642)
1 引言
问题理解是口语对话系统中的一个关键步骤,它的目标是让计算机自动分析和理解人们用自然语言提出的问题,确定问题的语义组织方法、查询策略和应答的方式。只有在准确理解用户问题的情况下,系统才能较好地回答问题。然而由于中文的弱语法性,以及口语的特点,中文口语问句的表达多样性给问题理解带来了很大的挑战。
国内外已有的对话(聊天)机器人,如国外的ELIZA[1]、PARRY[2]和ALICE[3],国内的清华大学图书馆“小图”[4],机器人小I[5],以及腾讯小Q等,这些系统可以与用户进行基于自然语言句子的交互,并已被广泛应用到机器助理,比如反恐支持平台[6]、计算机辅助英语学习[7]和健康咨询[8]等。然而,这些聊天机器人只能正确回应极少数的问题,它们几乎都是基于完全精确匹配或者很弱的模糊匹配的模版来搜索回答[9]。由于缺乏足够的智力基础[10],并没有真正“理解”用户的问题。
基于自然语言理解技术的对话系统研究方面,从90年代初期DARPA发起的航线信息查询系统(Airline Travel Information System,ATIS)项目开始,一般采用填槽法(Slot filling)或者叫填表法(Form filling)来实现语义理解。这些系统的语义表示是每个子任务(比如订票、 查询)采用一个框(Frame),每个框有一些针对具体子任务预定义的槽(Slot),这类系统中的问题理解就在于从用户输入句子中为一个给定的框中的每个槽 (比如目的地、出发日期) 提取填充的信息。一些系统采用了数据驱动的统计方法,如AT&T的CHRONUS[11]和BBN的隐理解模型[12],另一些则采用基于知识的方法如MIT的TINA[13]、CMU的Phoenix[14]和SRI的Gemini[15]。之后的研究推广到了更为复杂的限定领域,包括导航系统[16]、导游系统[17-18]和信息查询系统[19-21]等许多领域。研究者们还通过有限状态自动机的对话管理来引导槽信息的填充[22],以及采用了自动的语义槽信息填充技术[23]。上述的已有研究都促进了问题理解研究领域的发展,然而他们主要着重在语义理解方面,试图根据语义知识找到问题的目标,仍然缺乏对中文口语对话系统中问句表达多样性较为完整的解决方案,在较为复杂的限定领域,仍然不能很好地帮助系统像人一样去回答。
要使得系统能像人一样去回答,关键是要让系统能像人一样去理解用户提出的问题。图灵在1950年撰写的论文 “Computing Machinery and Intelligence” 中提出两个重要的思想[24]: 一个是智能的测试,即著名的“图灵测试”;另一个是“创造和教育儿童机器” (具有儿童般能力的机器)。前一个思想受到广泛的关注,而后一个则某种程度上被忽视了。这启发我们研究儿童认知和语言能力。通过观察发现,对于3岁儿童而言,可以理解许多不同结构的句子,能够根据不同结构的问题做出不同反应,证明其信息提取和应答方式是完善的,只遗留对某些具体内容的不理解而出现偶尔回答不了的问题。但可以确定的是,即使因为领域语义知识的欠缺而给不出正确回答,多数情况下儿童也是理解对方是在问什么样的问题。因此,我们认为问句理解能力的基础在于句型结构(语法),掌握了句型结构之后,再通过学习,具备各种各样的领域知识(语义),就可以进行某一知识领域的对话。
问题的焦点变成了: 如何得到这个基础,也即是需要掌握的句型结构。对此,当代语言学的两大流派——“形式主义语言学”和“认知功能语言学”的观点存在根本分歧。以乔姆斯基为代表的形式主义者认为,语法是一个天生的、自足的系统,在使用中代入语义内容。简单来说,就是进化为人类提供了一个特殊的功能强大的语言装置[25-26]。认知功能派的学者则认为,语法和语义是密不可分的,语法是词语内容的结构化,语义在很大程度上决定语法,他们认为儿童是根据语义的关系习得语法。然而,不论是哪种观点,就儿童如何具备一种特定的语言理解能力的问题而言,都还没有完全研究透彻。
本文另辟途径,回避了乔氏假说中的初始语言装置是否存在的问题,同时也跳过了认知功能派学者试图采用语义去习得语法的困难。我们在对话系统中预置一个乔姆斯基假说的具体语言(中文)语法装置,人工制造一个初始的语法库,进而采用基于语法的句子结构理解和基于语义的信息提取相结合的方法实现问题理解。本文的方法被应用到我们开发的中文手机导购对话系统。测试结果表明,该方法能有效地完成对话流程中的用户问题理解。
本文后续章节如下: 第2节简要介绍本文提出的问题理解方法的整体框架。第3节介绍本文的人工编制知识库。第4节给出了基于语法的句型模式识别,以及语义方面的提取和组织。第5节给出了应用运行例子及测试结果。最后,第6节总结本文的工作并做简要的展望。
2 系统框架
问题理解的整体框架如图1所示。
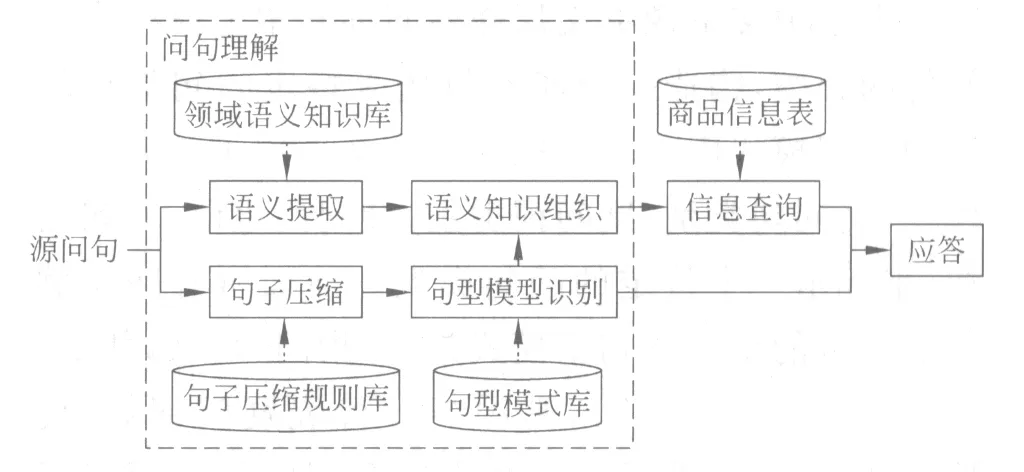
图1 问题理解整体框架
从语法的视角,我们首先设计了手工编制(Hand-crafted)的语法知识库,包括句子压缩规则库和句型模式库。然后通过句子压缩模块对复杂句子进行简化,只留下其结构。进而进行句型模式识别,每个句型模式可唯一确定问题的语义组织方法、查询策略和应答方式。
从语义的视角,根据领域语义知识库,从源句子中提取相应的语义信息,进而根据识别到的句型模式所对应的知识组织方法进行语义知识组织,完成对问句的理解。
3 人工编制的知识库
语法知识库是独立于领域和应用方向的语言学规则组件,在转移应用目标时候,基本可以保持不变;领域语义知识库是在语言学之上针对领域和应用的信息抽取,在扩展到其它应用时,需要重新编写。
3.1 语法知识库
句子是无限的,而结构是有限的,多样化的句子表达可以被有限的经过良好设计的句型模式覆盖到。下面的问句具有同样的核心句子结构。
• 有什么手机?
• 有哪款手机?
• 有什么2 000块左右的手机?
• 有什么2 000块以下的大屏幕的手机?
• 有哪些触屏手机?
• 有什么输入方式?
通过句子压缩,多样化的用户输入可以被消除,统一归类到一个简单的句子结构“有+什么/哪款/哪些…+手机/输入方式…”,或者进一步符号化为“VP+~+NP”。 这需要两个语法知识库的支持,句型模式库以及支持句子压缩的句子压缩规则库。
(1) 句型模式库
由于中文不像英文那样疑问词基本上就代表了问句的分类,构造一个能有效代表特定问句类型的问句类型模式库是一个挑战。本文采用了4元句型模式{疑问句类别,疑问词类别,疑问词短语,问句结构}来标示一个特定的问句类型。前面所有问句例子所对应的统一的句型模式是{特指问,什么,什么/哪*,VP+~+NP},其中“~”代表疑问词短语。值得注意的是,采用4.1.2小节介绍的句型模式识别算法,一些口语化省略的问句,比如“有什么2 000块左右的?”也可以识别为上述句型模式。这体现了本文设计方案的健壮性,使用有限的句型模式就能取得良好的应用效果 (我们目前的手机导购对话系统只用了30个句型模式,覆盖特指问、正反问、是非问和选择问等四类疑问句类别)。
(2) 句子压缩规则库
句子压缩规则用于实现源句子到目标句子的转换,是对几百个问题例子的分析后得到。目前的应用系统采用相对保守的句子压缩策略(压缩不完全会影响后续句型模式识别的得分,但可以避免一些由于错误压缩导致的匹配失败),共有16条规则,可以覆盖到一些常用的汉语句子压缩情况。我们采用基于语法树形式的句子压缩算法,句子压缩规则 (NP (DNP, NP1))->NP(NP1)表示由一个DNP和一个NP组成的NP可以缩掉其中的DNP。
3.2 领域语义知识库
对话系统中的领域语义信息包括基本语义知识和评价性语义知识。当前系统的手机销售领域的基本语义知识共有77个属性,这些属性是参考主流电子商务网站上的手机信息选定的,表1是当前系统中的基本语义知识片段。
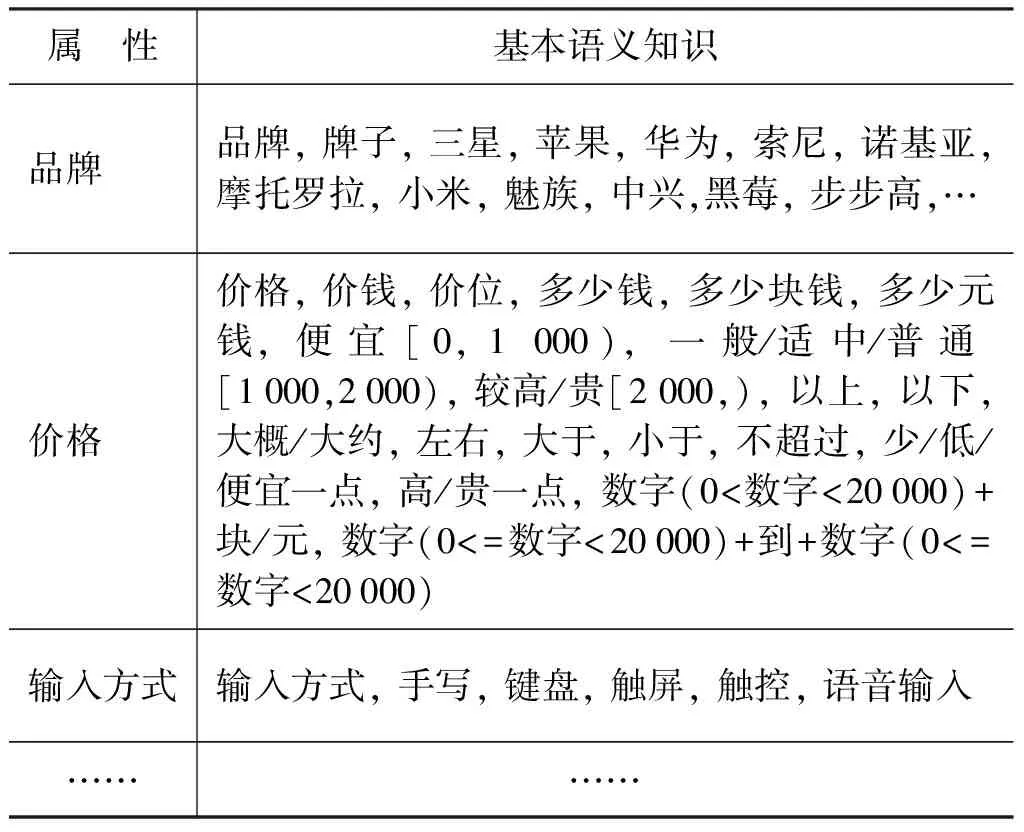
表1 基本语义知识片段
基本语义知识覆盖多种不同的知识,以价格属性为例,包括:
(1) 概念性知识: “价格”,“价钱”,“价位”,“多少钱”,“多少块钱”,“多少元钱”;
(2) 定性知识: “便宜[0,1 000)”,“一般/适中/普通[1 000,2 000)”,“较高/贵[2 000,)”;
(3) 定量知识: 又可以进一步细分为两种:
• 概数知识: “以上/大于”,“以下/小于”,“左右/大概”,“不超过”,“少/低/便宜一点”,“高/贵一点”;
• 确数知识: “数字(0<=数字<20 000)+块/元”,“数字(0<=数字<20 000)+到+数字(0<=数字<20 000)”。
评价性语义知识则是参考主流电子商务网站用户反馈信息以及调研一些手机实体店的销售过程制定,当前系统中共有11个属性,表2是评价性语义知识片段。

表2 评价性语义知识片段
4 语法和语义相结合的问题理解
4.1 基于语法的句型模式识别
4.1.1 句子压缩
句子压缩被应用于消除用户输入中的多样性修饰成分。给定一个输入句子x=x1,x2,…,xn,句子
压缩通过去除其中的一些词得到目标句子y[27]。本文句子压缩的目标是保留句子的重要结构信息。本文使用斯坦福大学的句法分析器(Stanford Parser)[28]构建语法树,进而借鉴近年来应用于机器翻译和文档摘要中的一些处理技术进行基于句子语法结构的句子压缩[29-30]。图2给出了算法伪代码。算法中,当前匹配节点对是指在两棵树中,当前尝试用规则匹配改写的节点对。规则为三元组,(源树模板st,改写后的树vt,对称节点组~),其中~代表st,vt的儿子中,句子成份一致的节点对[(cs1, ct1), (cs2, ct2), (cs3, None)…]。

图2 句子压缩算法
4.1.2 句型模式识别
句型模式识别的算法流程如图3所示。

图3 句型模式识别算法
由于Stanford Parser 在中文词性标注上不够准确,在上述算法的第1步,我们采用了中科院的汉语词法分析系统ICTCLAS[31]对缩句后句子进行重标注。在句型模式的4元结构{疑问句类别,疑问词类别,疑问词短语,问句结构}中,由于疑问词类别不起识别作用,在进行句型模式识别时,压缩后的疑问句和句型模式库中的句型模式从疑问句类别、疑问词短语和问句结构3方面计算综合相似度。
问句结构相似度计算的算法,是基于编辑距离算法[32]的扩展。主要特点是,给每种操作赋予不同的权值得分,以算出最后的最高得分。算法流程如图4所示。

图4 问句结构相似度计算算法
1.a)—1.d)行针对不同的词性标注α,会有不同的得分权重,例如,对于语气词、副词、标点符号等词性标注的得分权重就会稍低,对于名词、动词和疑问词的权重就会稍高;在2和3行,最高的分数基于编辑距离算法计算得到;3—4行是为了让得分变成百分制。
4.2 语义知识组织
4.2.1 语义信息提取
语义信息提取是语义知识理解的第一步,我们采用如图5所示的语义信息提取流程[33]。
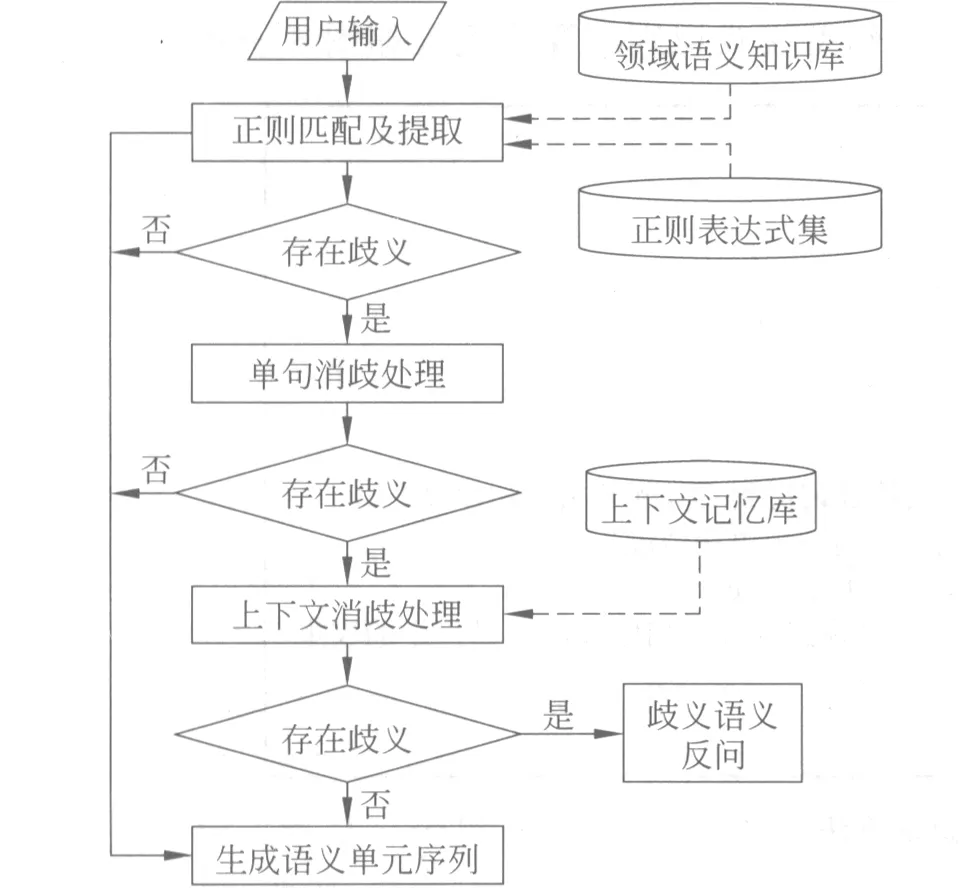
图5 语义信息提取流程
系统对用户的输入进行正则表达式匹配和提取,接着判断所提取的信息是否存在歧义,如果存在,则进行消歧,包括单句消歧和上下文消歧,若最终仍存在歧义,则可进行反问,否则生成语义单元序列。比如源句子“有什么2 000块以下的大屏幕的手机?”,通过单句消歧,借助“块”、“屏幕”等信息,排除了“上市日期”和“RAM容量”等属性的干扰,提取到的信息是 “价格: 2 000块,以下;主屏尺寸: 屏幕,大”。
4.2.2 语义知识组织
提取到的语义信息进一步根据识别到的句型模式所对应的知识组织方式进行组织。不同的句型模式可以具有不同的组织方式。下面两个例子分别是特指问和选择问:
• 源句子1: 有什么2 000块以下的大屏幕的手机?
语义知识组织: “价格: 2 000块,以下”与“主屏尺寸: 屏幕,大”。
• 源句子2: 这款手机是直板的还是翻盖的?
语义知识组织: “外观设计: 直板”或“外观设计: 翻盖”。
通常具有相同疑问句类别的句型模式具有相同的语义知识组织方式。
5 应用测试
为了验证本文提出的问题理解方法的效果,我们实现了一个中文手机导购系统原型,如图6所示。手机导购属于信息咨询类中较为复杂的网上商品销售咨询限定领域。对话记录作为背景保留在页面上,方便用户查阅对话的上下文。

图6 系统界面
5.1 应用例子
图7是一个开发人员测试的应用例子。第(8)、(10)和(12)行的用户输入是疑问句。可以看到本文的方法能理解不同类型的用户问句,帮助对话系统完成导购流程。

图7 中文手机导购系统的一个运行例子
5.2 测试及分析
我们在实现的中文手机导购对话系统中进行了外部测试。测试人员是6名学生志愿者,每位测试者测试3段,共18段对话。这些测试人员只知道系统的功能是手机导购,对系统的实现细节并不知情,这样可确保测试的真实性和自然性。测试结果如表3所示。
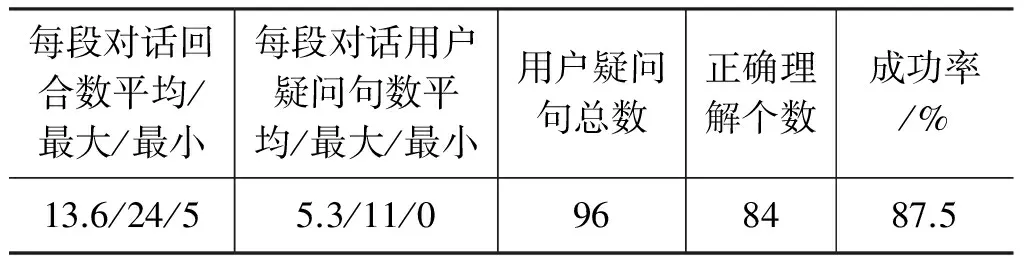
表3 测试结果
18段对话的平均回合数为13.6,每段对话用户疑问句平均次数为5.3,表明了导购流程中用户主动发问的比例还是比较高。从最大和最小的疑问句数分别是11和0也可以看出测试者的差异性很大,有的主动发问很多,有的倾向于依赖系统的引导。在总共96个用户疑问句中,正确理解(语义提取和句型模式识别都正确)的个数占87.5%,包括许多带有冗余修饰和口语化省略情况的问句(部分省略过于严重的问句,如“内存呢?”,通过上下文理解补充缺失句子成分解决),表明本文方法能有效地完成中文口语对话流程中用户问题理解。
经过对结果的逐个分析发现,96个问句分属12个不同的句型模式。有18个句型模式在测试中没有出现。选择问和正反问出现频率很低。问句在12个出现的句型中的分布也很不均匀,出现最多的3个句型占了总数的一半以上,分别是特指问的“NP+~” 句子结构(如“像素多高?”)和 “VP+~+NP” 句子结构(如“有什么颜色可以选?”),以及是非问的“VP+NP+~” 句子结构(如“是安卓吗?”)这也体现了导购类信息咨询对话的特点。
未能被正确理解的12个问句的错误分类如表4所示。

表4 错误分类
从表4可以看到,目前的理解错误有一半是因为领域语义知识库或者疑问词列表还不够完善导致。除此之外有25%属于分词或标注错误引起,由于是依赖外部工具完成,这部分错误未来相对较难降低。由于疑问词或其他句子成分移位的问题较难解决,未来计划通过基于规则的同步树替换算法,并在规则使用时采用基于统计的辅助判断尝试解决这个问题。
具体的错误分析如下:
(1) 用户输入预处理错误: 用户输入“这款多贵?”,在预处理模块,“多贵”没有转成“多少钱”,结果造成语义提取失败。
(2) 分词或词性标注错误: 用户输入“是什么操作系统?”,由于分词模块没有分出专有名词“操作系统”,导致“操作”被句子压缩模块缩掉,变成“是什么系统?”,而后的词性标注错把“系统”标注为“ADJP”,导致句型模式识别错误。另外两个用户输入“它装的什么系统?”和“有没有塞班操作系统的?”也是同样的词性标注问题导致理解错误。
(3) 疑问词识别错误: 用户输入“最便宜的手机是哪一部?”则由于特指问疑问词“哪一部”没有被加到疑问词短语列表里,未能被识别到。
(4) 领域语义知识欠缺: 用户输入“还有别的吗?”、“还有呢?”、“没有对吗?”、“没有htc吗?”由于目前领域语义知识库还没有考虑 “其他”、“别的”、 “还有”、“没有”之类的词作为有效语义处理,因此没能正确理解用户问句。在未来工作中,计划加入这类语义,再结合语义提取中的上下文消歧就可以确定用户问的是别的什么或者没有什么。另外一例由于语义提取问题导致理解错误的是用户输入“耐摔吗?”这类评价性语义需要在测试中逐渐完善。
(5) 疑问词或其他句子成分移位: 用户输入“苹果手机有什么好推荐的吗?”,由于出现疑问词移位的情况,未能匹配上目标句子结构“VP+~+NP”。如果是“有什么苹果手机好推荐的吗?”,则经过预处理去除“好推荐的”,以及经过句子压缩去掉“苹果”之后,就可以识别为特指问类型中的句子结构“VP+~+NP”。用户输入“小米手机,有吗?”同样是因为出现句子成分VP(“有”)移位情况,未能识别为是非问类型中的句子结构“VP+NP+~”(如“有小米手机吗?”)。
6 结束语
本文针对中文口语问句的表达多样性给对话系统问题理解造成的困难,提出了一种语法和语义相结合的口语对话系统问题理解方法,并在我们开发的中文手机导购系统上测试,取得了较好的测试效果。本文提出的方案中的人工编制语法知识库,虽然在构建时客观上需要专家的指导,本文测试表明,目前有限的句子压缩规则(16条)和问句类型模式(30个),已经能够较好地完成手机导购领域的问题理解,后续在进一步测试时可以方便地扩充完善。并且由于独立于领域,在转移到同为导购类的其他应用目标的时候,语法知识库可预期基本保持不变(还有待在开发新应用时检验)。另一方面,由于采用了“在语法结构之上获取语义知识”设计理念,某一特定业务的专业领域语义知识,可以被相对独立地设计和加载到对话系统,使得本文的研究具备良好的业务(专业领域)可扩展性,可以很方便地扩展应用到一个新的业务领域的问题理解。未来工作是研究如何处理汉语句子的移位表达;以及通过更大范围的测试,进一步完善语法知识库和领域语义知识库;并探索一定的智能学习机制,如采用基于事例的推理(CBR)方法,研究特定限定领域对话系统在预置的语法知识库和领域语义知识库的基础上,如何在持续开展的测试和应用中实现自适应的修改和扩充。
[1] Weizenbaum J. ELIZA-A computer program for the study of natural language communication between man and machine[J]. Communications of the ACM, 1966, 9(1): 36-45.
[2] Colby K M, Weber S, Hilf F D. Artificial paranoia[J]. Artificial Intelligence, 1971, 2(1): 1-25.
[3] Wallace R S. The Anatomy of A.L.I.C.E. [EB/OL], A.L.I.C.E. Artificial Intelligence Foundation Inc., 2004.
[4] 清华大学图书馆智能机器人小图[EB/OL]. http://166.111.120.164: 8081/programd/
[5] 小I机器人[EB/OL]. http://www.xiaoi.com/index.html
[6] Schumaker R P, Chen H. Leveraging question answer technology to address terrorism inquiry[J]. Decision Support Systems, 2007, 43(4): 1419-1430.
[7] Jia J Y. CSIEC: A computer assisted English learning chatbot based on textual knowledge and reasoning[J]. Knowledge-Based Systems, 2009, 22 (4): 249-255.
[8] Crutzen R, Peters G Y, Portugal S D, et al. An artificially intelligent chat agent that answers adolescents’ questions related to sex, drugs, and alcohol: An exploratory study[J]. Journal of Adolescent Health, 2011, 48(5): 514-519.
[9] Huang J Z, Zhou M, Yang D. Extracting chatbot knowledge from online discussion forums[C]//Proceedings of the 20thInternational Joint Conference on Artificial Intelligence (IJCAI 2007), Hyderabad, India, January 2007: 423-428.
[10] Russell R S. Language Use, Personality and True Conversational Interfaces[R]. Project Report, AI and CS, University of Edinburgh, Edinburgh, 2002.
[11] Pieraccini R, Tzoukermann E, Gorelov Z, et al. A speech understanding system based on statistical representation of semantics[C]//Proceedings Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 1992), San Francisco, CA.
[12] Miller S, Bobrow R, Ingria R, et al. Hidden understanding models of natural language[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL 1994), Las Cruces, NM.
[13] Seneff S. TINA: a natural language system for spoken language applications[J]. Computational Linguistics, 1992, 18 (1): 61-86.
[14] Ward W, Issar S. Recent improvements in the CMU spoken language understanding system[C]//Proceedings of the ARPA Human Language Technology Conference (HLT 1994) Workshop. 1994:213-216.
[15] Dowding J, Gawron J M, Appelt D, et al. Gemini: a natural language system for spoken language understanding[C]//Proceedings of the ARPA Workshop on Human Language Technology, Princeton, NJ,1993.
[16] 黄寅飞, 郑方, 燕鹏举, 等. 校园导航系统EasyNav的设计与实现[J].中文信息学报, 2001, 15(4): 35-40.
[17] 何伟, 李红莲, 袁保宗, 等. 基于对话回合衰减的cache语言模型在线自适应研究[J].中文信息学报, 2003, 17(5): 41-47.
[18] Pappu A, Rudnicky A. The Structure and Generality of Spoken Route Instructions[C]//Proceedings of the 13thSIGdial Workshop on Discourse and Dialogue, 2012: 99-107.
[19] Zue V, Seneff S, Glass J, et al. JUPITER: a telephone-based conversational interface for weather information[J]. IEEE Transactions on Speech and Audio Processing, 2000, 8(1): 85-96.
[20] 刘蓓, 杜利民, 于水源. 面向任务口语对话系统中期待模型的实现算法[J].电子与信息学报, 2004, 26(11): 1721-1727.
[21] 张琳, 高峰, 郭荣, 等. 汉语股票实时行情查询对话系统[J]. 计算机应用, 2004, 24(7): 61-63.
[22] 黄民烈, 朱小燕. 对话管理中基于槽特征有限状态自动机的方法研究[J]. 计算机学报, 2004, 27 (08): 1092-1101.
[23] Chen Y N, Wang W Y, and Rudnicky A I. Unsupervised Induction and Filling of Semantic Slots for Spoken Dialogue Systems using Frame-Semantic Parsing[C]//Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2013.
[24] Turing A M. Computing Machinery and Intelligence[M]. Washington: Publishing House of Electronics Industry, 1950: 5-23.
[25] Chomsky N. The Minimalist Program. Cambridge[M], Mass: MIT Press, 1995.
[26] Chomsky N. Three factors in language design[J]. Linguistic Inquiry, 2005, 36(1): 1-22.
[27] Knight K, Marcu D. Summarization beyond sentence extraction: a probabilistic approach to sentence compression[J]. Artificial Intelligence, 2002, 139 (1): 91-107.
[28] Levy R, Manning C D. Is it harder to parse Chinese, or the Chinese Treebank? [C]//Proceedings of the 41th Annual Meeting of the Association for Computational Linguistics (ACL 2003), 2003: 439-446.
[29] Cohn T, Lapata M. Sentence compression as tree transduction[J]. Journal of Artificial Intelligence Research, 2009, 34(1): 637-674.
[30] Cohn T, Lapata M. An Abstractive Approach to Sentence Compression[J]. ACM Transactions on Intelligent Systems and Technology, 2013, 4(3): 1-35.
[31] Zhang H P, Yu H K, Xiong D Y, et al. HHMM-based Chinese lexical analyzer ICTCLAS[C]//Proceedings of the Second SIGHAN Workshop Affiliated with the 41 Annual Meeting of the Association for Computational Linguistics (ACL 2003), 2003, 184-187.
[32] Ristad E S, Yianilos P N. Learning string-edit distance[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(5): 522-532.
[33] 林仙茂, 黄沛杰, 杨德, 等. 中文手机导购对话系统中的语义信息提取[J]. 现代计算机, 2014, (04): 52-55.
