藏语自动分词中的几个关键问题的研究
2014-02-28完么扎西尼玛扎西
完么扎西,尼玛扎西
(1. 青海师范大学民族师范学院,青海 海南 813000;2. 西藏大学现代教育技术中心,西藏 拉萨 850000)
1 引言
近几年来,众多专家和学者不但对藏语自动分词算法进行了大量的研究,而且取得了显著的成果。文献[1]在提出用格助词分块思想的同时,提出了未登录词的识别方法,紧缩词的识别和处理方法,其中紧缩词的识别和处理方法是基于语法结构的识别和处理方法;文献[2]不仅在文献[1]的基础上进一步提出了用八个格助词分块的思想,而且首次提出了紧缩词的识别和处理方法,即“还原法”;文献[3]提出了人名音译未登录词的识别和处理方法;文献[4]提出了切分与格框架、标注一体化的藏语三级切分体系;文献[5]在文献[2]和[3]的基础上进一步提出了格助词分块和临界词识别方法,同时也提出了歧义检测和消歧的方法;文献[6]提出了藏文数字组合的方法。
以上文献中提到的方法对藏语自动分词的准确率和切分速度有了很大的提高,但同时也存在一些不足。针对这些不足,本文以传统藏文文法[7-8]和现代藏文文法[9-11]为理论依据,采用最大正向匹配算法和Viterbi算法,构建了基于规则和统计相结合的藏语自动分词及词性标注一体化的系统,重点做到了以下几个方面: 一、按照藏文添接法和词的前后词性关系进行组合的方法处理未登录词;二、构建特殊词表,用词的前后词性关系,提出了“排除-还原”的方法识别紧缩词,且提高紧缩词识别的准确率;三、根据“词性规则法”消除歧义;四、用规则和统计相结合的方法,提高词性标注的准确率。下面将对未登录词、紧缩词和歧义等问题的处理方法做具体分析。
2 藏语自动分词及词性标注一体化过程

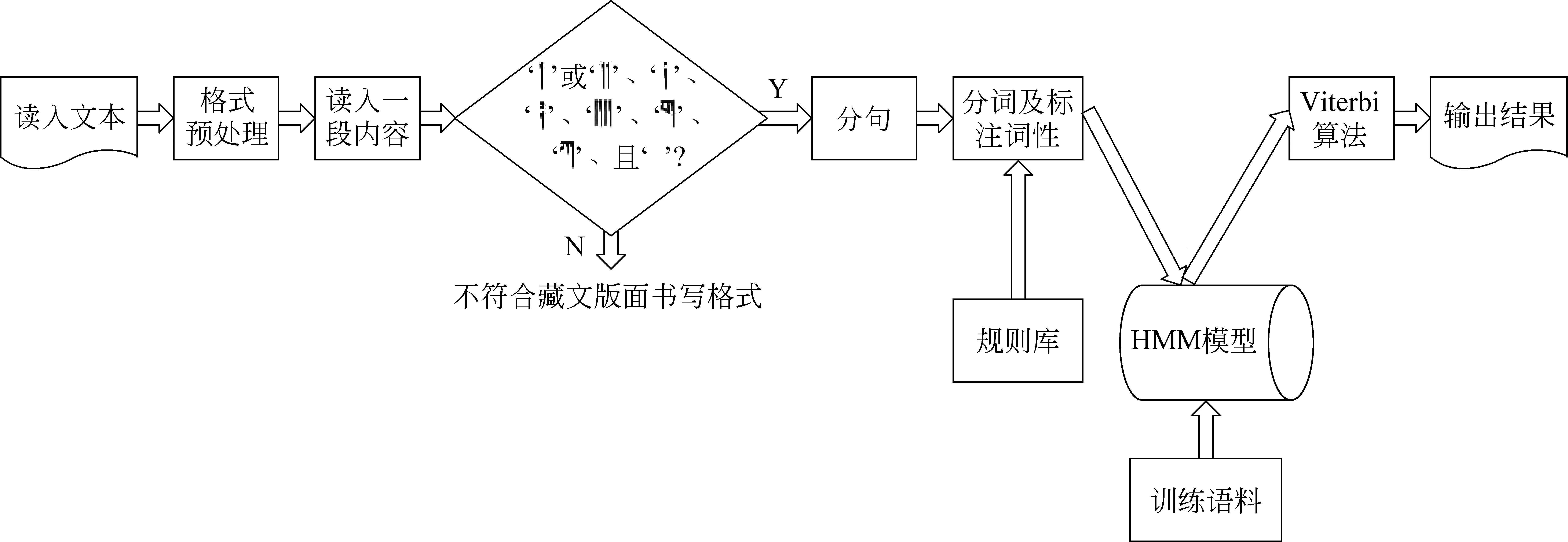
图1 藏语自动分词及词性标注一体化流程图
2.1 未登录词的处理方法
未登录词是指分词词典中不存在,但符合构成藏文音节规则的单音节词或多音节词,和以及不一定符合构成藏文音节规则的音译词。
(1) 符合藏文音节构成规则的词
藏语言中存在大量的具有一定构词规则的词。这些词的总构词方法分为音的构词法()和意的构词法()两种,其中音的构词法又分为同性原则()、同音原则()和方便原则()三种,其中:

• 同音原则是指不论字性一致与否,后接成分的基字与前一音节的后加字是同一个字,或者后接成分的基字与前一音节的基字是同一个字,或者发音完全相同的进行组合。
• 方便原则是指按约定俗成的习惯添接法添接的。
(2) 音译词

(3) 数词
藏语言中数词分为基数词、序数词、总数词、倍数词、分数词和概数词等,其中:
(6)加强政策宣讲和业务培训。财政专项的最终执行者是项目负责人,由于专业的关系,很多项目负责人对专项资金及财务的相关政策和规定都不是很了解,高校相关职能部门应通过各种渠道,加强专项资金管理办法和财务报销规范的宣传培训,提高项目负责人的执行意识,认识到按照预算进度完成项目支出的重要性和必要性。

读入句子(不一定是完整的句子);
if(S为未登录词){
if(S在音译词表中){
if(S的下一个词在音译词表中){
continue;
}else 进行切分;



} else if(S的前一个词是动词){

}else if(S的前一个词是基数词){


} else { 不组合。}
}else 处理其他;
2.2 紧缩词的识别方法
(1) 紧缩词的概念
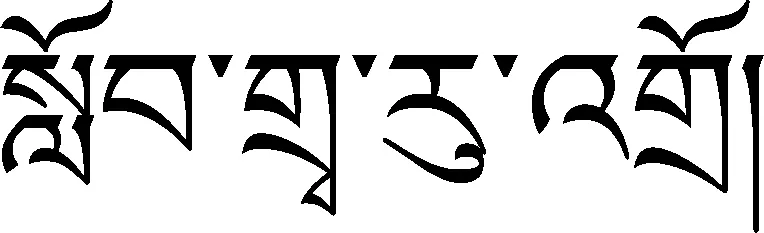
(2) 缩写词的种类

(3) 紧缩词的识别
识别以上三种情况中的紧缩词时,“还原法”基本上能正确地识别,但是紧缩词的前面部分为登录词而且需要添加、有再后加字的音节为未登录词的情况、上述第三种情况中的紧缩词和为末尾的音译词等进行识别时,会出现错误的结果,例如,①“”和②“”这两句为例, 因为①中紧缩词的前部分(近处或旁边)是登录词,②中的(gao)是音译词,所以“还原法”切分的结果为①“”和②“”,显然这两个结果都是错的。如果的添加法“”(意思是后加字只能添加在单字(是指三十个字母)后面。)应用到程序设计中,完全可以避免①的错误,因为中的是单字,所以必须要添加,然后再进行切分。以为末尾的音译词,的前面部分可能是未登录词,也可能是登录词,在很难识别是否为紧缩词时,可以根据音译词表和词的前后词性关系,识别是否为紧缩词,除此之外未能找到一个合理的识别方法。因此有待于研究。
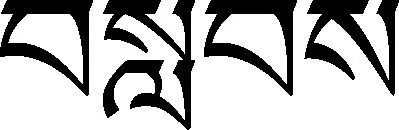

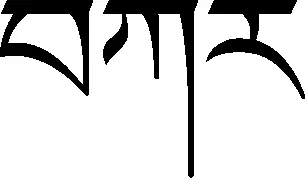
读入句子(不一定是完整的句子);
若S为未登录词;则
切分S;
}
if(S′在词典中) 切分S′;
else S′是未登录词;
}
else{
切分S-1;
}
}
若S为未登录词;
else if(S在构建词表中){
if(S的下一个词是自主动词或不自主动词或判断词或名词){
if(S′在词典中) 切分S′;
else S′是未登录词
}else{
切分S-1;
}
}else 切分S;
}else{
if(S′在词典中) 切分S′;
else 切分S-1;
}else{
切分S-1;
}
}
2.3 歧义的处理方法
歧义是自然语言中普遍存在的,藏语言中也不例外。它不仅是藏语自动分词的难点,而且成为影响藏语自动分词准确率的因素之一。目前对这个问题的研究除了文献[5]和[12]外很少,与汉语歧义问题的研究相比很落后。歧义的定义和检测歧义的方法与汉语完全相同,这里不再重述。
藏语歧义同样分为两类,即交集型歧义和组合型歧义。
(1) 交集型歧义

(2)组合型歧义

上述理论知识应用到程序设计中,通过大量实验搜集了以下几种属于交集型歧义的字段,并提出了“词性规则法”,其方法是: 首先采用文献[5]的方法检测具有歧义的字段,其次通过该字段中各词的词性来判断该字段属于哪一类,最后用如下六个规则消除歧义。






3 实验数据及结果分析
3.1 实验数据
本文以文学类、诗歌类、医学类和新闻类等大小1M的语料上进行测试。统计文中的未登录词、紧缩词和交集型歧义等出现的次数并通过准确率计算公式(准确率=(正确识别的总次数/测试文本中出现的总次数)*100%)计算未登录词、紧缩词和交集型歧义等的识别准确率,其实验结果如图二所示。
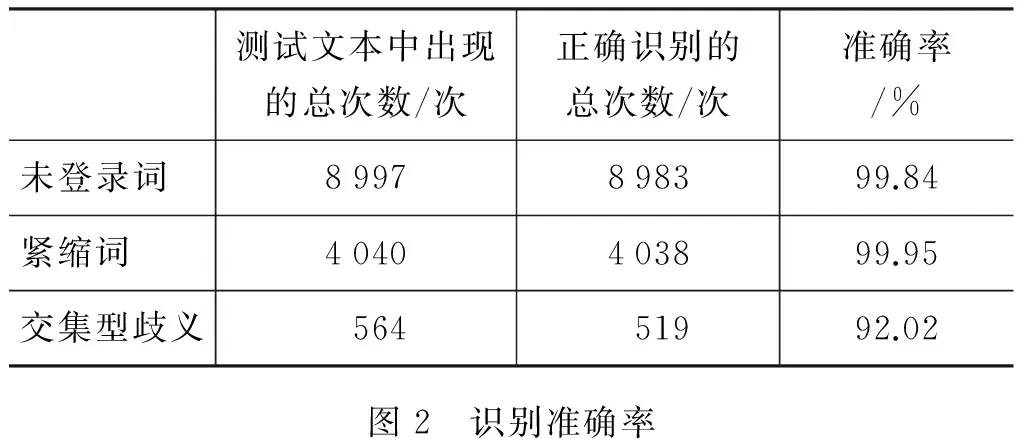
测试文本中出现的总次数/次正确识别的总次数/次准确率/%未登录词8997898399.84紧缩词4040403899.95交集型歧义56451992.02图2 识别准确率
3.1 实验结果分析

4 结束语

通过实验也发现“重组法”和“词性规则法”只能识别部分未登录词和交集型歧义。因此,下一步的工作重点将解决如何提高无法用构词规则进行组合的未登录词的识别率和如何改进消除交集型歧义的方法。
[1] 陈玉忠,李保利,俞士汶. 藏文自动分词系统的设计与实现[J].中文信息学报, 2003,17(03):15-20.
[2] 才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报, 2009,23(01):35-37.
[3] 才智杰,才让卓玛.藏文自动分词系统的设计[J]. 计算机工程与科学,2011,33(5): 151-154.
[4] 祁坤钰.信息处理用藏文自动分词研究[J].西北民族大学学报(哲学社会科学版), 2006,26(04):92-97.
[5] 刘汇丹,诺明花,赵维纳,等. SegT: 一个实用的藏文分词系统[J]. 中文信息学报, 2012, 26(1):97-103.
[6] Huidan Liu, Weina Zhao, Minghua Nuo, et al. Tibetan Number Identification Based on Classification of Number Components in Tibetan Word Segmentation[C]//Proceedings of the 23rd International Conference on Computational Linguistics (Posters Volume) (Coling 2010),2010:719-724.
[7] 噶玛司都.司都文法详解[M].西宁: 青海民族出版社,2003.
[8] 色多五世罗桑崔臣嘉措.藏文文法根本颂色多氏大疏[M].兰州: 甘肃人名出版社,1981.
[9] 吉太加. 现代藏文语法通论[M].兰州: 甘肃民族出版社,2000.
[10] 马进武. 藏语语法四种结构明晰[M].北京: 民族出版社,2008.
[11] 格桑央京等.实用藏文文法教程[M].成都: 四川民族出版社,2004.
[12] Yuan Sun, Xiaodong Yan, Xiaobing Zhao, et al. A resolution of overlapping ambiguity in Tibetan word segmentation[C]//Proceedings of the 3rd International Conference on Computer Science and Information Technology, 2010: 222-225.
