基于多策略的藏语语义角色标注研究
2014-02-27龙从军康才畯
龙从军,康才畯,李 琳,江 荻
(1. 中国社科院民族所,北京 100081;2. 青海师范大学 计算机学院,青海 西宁 810004;3. 中国科学院软件研究所,北京 100190)
1 引言
自动语义角色标注(Semantic Role Labeling,缩写为SRL)是自然语言处理的重要任务,对提高语言信息处理系统的性能具有重要的意义。语义角色标注的过程可以表述为: 设立一套标签体系(角色分类体系),部分地标注句子的成分结构(能承载语义角色),使计算机自动的获得一定的“理解”能力。
最早研究SRL的是Gildea和Jurafsky,他们开发了一套SRL系统,经对不同的两套语料测试,实验结果准确率分别约为82%和65%[1]。在CoNLL2004会议中,他们提交的论文强调对句法组块进行分类,在训练语料相同的情况下,比较了词到词与短语到短语的标注结果,测试结果为准确率72.43%、召回率66.77%和F值为69.49[2]。CoNLL2007会议设立一个Session讨论SRL[3]。CoNLL2008又把SRL作为主要的评测任务,并以依存句法分析为基础,考察SRL和句法分析结果[4]。我国学者也较早地参与SRL研究,在2005的CoNLL会议的评测会上,刘挺等采用了最大熵模型进行英语SRL研究,以句法成分为标注单元,并加入了规则后处理模块,标注的结果为: 准确率79.65%,召回率71.34%和F值75.27[5]。汉语语义角色标注研究也取得了一系列的成果[6-8],尤其是丁伟伟等人尝试了基于语义组块的汉语语义角色标注研究,获得了不错的效果[9]。
藏语目前没有公开可用的句法树库资源,难以采用句法成分和依存句法的语义角色标注研究。但是藏语具有比较丰富的句法标记,这些标记可以把一个藏语句子天然地切分成一定数目的块(语义组块),文献[10-13]从不同的角度对藏语的组块进行了讨论,但是未讨论组块与语义角色之间的对应关系。本文尝试采用统计和规则相结合的多策略的方法进行基于语义块的语义角色标注研究。规则的获得主要通过手工编制初始规则集,利用错误驱动学习的方法获得扩充规则集,然后利用这些规则对基于条件随机场模型的语义角色标注结果进行校正。
2 藏语的语义角色分类
2.1 藏语的标记
语义组块的分类需要关注两个问题: 块的边界和块的类型,藏语中的标记兼顾了块边界识别与块的类型识别两大功能,下面以例句1来说明。

khos ngavi rlangs vkhor gsar bar bstod pa byed kyin yod.
他对我的新汽车夸赞。

2.2 藏语语义角色分类原则和体系
SRL具有语言工程研究特点,语义角色的分类将应用到语料标注中去,实践性强。如果分类过细,对语言研究来说当然是件好事,但在实际语料标注中,会遇到很多困难。如果分类过粗,也许达不到研究的目的。因此一个大致合适的语义角色分类体系是十分必要的。袁毓林专门对语义角色分类的精细等级进行了探讨,现有的语义角色分类可以粗略的分为微观、中观和宏观三个等级。微观分类包括基于特定动词和基于特定领域的语义角色。中观层级的分类包括各种语义格的分类,它是基于动词类而不是具体的动词。宏观层级的分类包括原型施事(Proto-Agent)与原型受事(Proto-Patient)[14]。藏语的语义角色分类需要关注格及助词的标记特征以及动词的类型特征,因此分类的结果与中观层级的分类相近。同时本文作者还拟定了如下的3个分类原则:
(1) 参照性原则。所谓参照性就是充分借鉴现有英、汉语中语义角色分类体系的成功经验[15-20],结合藏语语言实际特点,加工改造。
(2) 注重标记特征原则。一种语言中的句法标记特征越多,计算机对这种语言的句法理解就更容易把握。藏语与汉语相比,以格标记为核心的句法标记十分丰富, 是语义角色分类 的 重 要 依 据。表1列 示了句法标记与可能的语义角色的对应关系。

表1 句法标记与语义角色对应关系
(3) 角色配对原则。句法标记并不能与语义角色构成一一对应关系,仍然存在部分无标记的语义组块。针对这种情况,本文作者在对语义角色分类时充分考虑了无标记与有标记的语义角色块在一个句子中的配对关系,例如,施事与受事,领事与属事,系事与类事,使役与受役之间存在配对关系;特殊句型与语义角色的关系,例如,领事、属事与领有句有关,系事与类事与判断句有关,使役与受役与使动句有关等。
综合以上的各种因素,本文作者最终为藏语设计了22个语义角色类型,具体如表2所示。
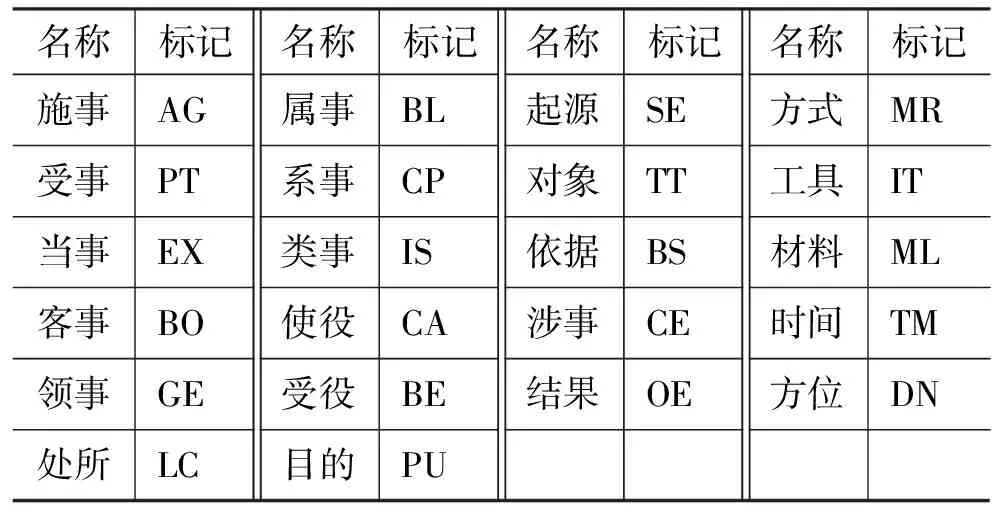
表2 藏语语义角色分类体系
3 语义角色标注规则构建
与统计方法相比,规则方法在自然语言处理中并无明显优势,这对于资源丰富、数据获取便利的大语种来说更是如此。但是对于资源少、句法标记较丰富的藏语来说,在现阶段,也不失为一种有益的尝试。为此,本文采用手工编制初始规则集和利用基于转换的错误驱动学习算法(Transformation-Based Error-driven Learning, TBL)对规则库进行泛化,从而获得扩充规则集。
3.1 初始规则集
初始规则包括语义块边界规则和语义角色与格标记及助词的对应规则。规则的获得主要由人工总结归纳。语义块边界规则由左边界、右边界、双边界和左右边界例外四个部分组成。其中左右边界例外是一个调节规则,就是对左右及双边界标注结果进行纠错。四个部分规则共有271个,右边界特征114个,双边界特征119个,左边界特征15个(包括全部动词和否定副词等特征词),左右边界例外特征35个。语义角色与格标记及助词的对应规则63个。
3.2 扩充规则集
在初始规则集的基础上,本文作者采用TBL算法自动从语料中学习并建立扩充规则集。TBL算法利用学习器从语料中自动获取转换规则集,因此建立一个高效的学习器是TBL算法的关键。学习所需资源主要包括以下三方面: (1)正确标注语义角色的语料; (2)经初始标注的语义角色语料; (3)转换规则模板集合。通过比较资源(1)和资源(2)之间的标注差异,得到扩充规则集。
4 统计模型及特征选择
4.1 条件随机场模型
条件随机场(Conditional Random Fields,CRFs)是一种判别式概率模型,多用于标注或者分析序列材料。在基于统计的标注方法中,条件随机场模型具有很好的效果,其模型思想主要来源于最大熵模型,但又不存在最大熵模型的数据稀疏问题;同时也无需对数据进行不必要的独立性假设,在这个方面也优于隐马尔科夫模型(Hidden Markov Model,HMM)。CRFs通常采用如图1的一阶链式结构。
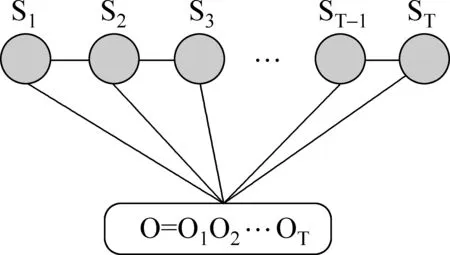
图1 CRFs链式图
4.2 标签设计
语义角色标注的标签设计十分关键,在训练语料不丰富的前提下,标签的数量会直接影响标注的效果。本文的语义角色标注所使用的语料经人工标注,标注语料能够提供词性信息、语义组块边界信息和语义角色标记信息。如果把这些信息结合起来考虑,设计一套联合标签,在一定程度上,可能会提高标注效果。边界标记使用了BIE标记法,单词成块或者块外标点为S,块开始用B,块结尾用E, 块中间用I。
语义角色以角色类型作为标签。联合标签还包括词形和词性,具体情况如表3所示。

表3 语义角色标注联合标签
4.3 特征选择
条件随机场算法中,数据的很多重要信息是通过特征函数给出的。CRF工具以特征模板的方式,给出这些特征函数的定义,使选取特征和定义特征函数非常方便。本文所使用的特征包括词形信息、词性信息、语义组块音节长度信息、谓语动词类型信息以及谓语动词与语义组块之间的距离信息。这些信息的具体描述如下:
音节长度: 是指一个语义组块的音节数量,语义组块的平均音节数量可以作为语义组块边界识别的参考。

谓语动词类型: 是指谓语动词的语义类型,本项研究按照动词必有论元的数量对动词分类,分为一元动词、二元动词和三元动词。动词语义类型可以影响动词携带语义角色的数量。
谓语动词与语义块的距离: 是指谓语动词与承载语义角色块之间间隔的音节数,一般来说受事语义角色与谓语动词近,施事语义角色离动词远,这些特征可能有效地辅助推断语义角色。
5 实验及结果分析
5.1 工具与语料
本文使用由日本松本实验室的Taku Kudo博士开发的CRF++软件包[21]。首先构建一个Baseline系统,该系统只选择词形及词性作为特征,其识别结果作为后续实验比较的基准。在后续实验中增加新特征,通过与Baseline结果的比较,确定添加的特征对语义块的识别是否有效。添加的特征分别是语义块音节长度、谓语动词类型和谓语动词与语义块的距离三个特征。选取约5 000个手工标注语义组块边界和语义角色类型的句子作为训练语料,用同类型的500个句子作为测试语料来检验算法的性能。
5.2 实验结果评价及结果分析
本文采用语言信息处理通用评价指标来检验语义组块标注结果的效率,这些指标是准确率(P)、召回率(R)和F值,计算公式如式(1)~(3)所示。
实验结果表明,利用词形和词性的baseline模板的语义角色标注准确率、召回率和F值分别为68.88%、63.10%和64.85%。当分别加入语义组块音节特征、谓语动词类型特征和语义块与谓语动词的距离特征后,获得的标注效果都有明显的提升,其中加入语义组块音节特征效果最为明显,准确率、召回率和F值分别提高到78.60%、71.34%和74.80%。第二个具有明显作用的特征是谓语动词与语义角色块的距离特征,谓语动词类型特征同样也能提高标注效果,具体情况如图2所示。

图2 加入不同特征测试指标的变化情况
基于统计的方法在边界识别与语义角色标注中出现的错误类型可以概括为如下几种:
(1) 边界识别错误。如例句2:
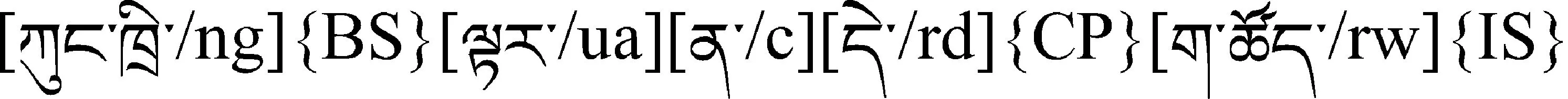
这个句子的边界识别结果为:

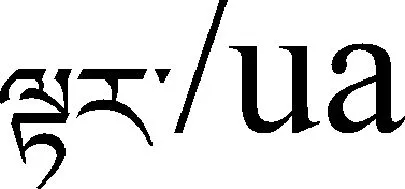

这个句子的边界识别结果为:


(2) 边界识别正确,语义角色标注错误。语义角色标注的错误表现有: 语义角色未标注,语义角色标注的位置错误和语义角色选择错误。如例句4、5。


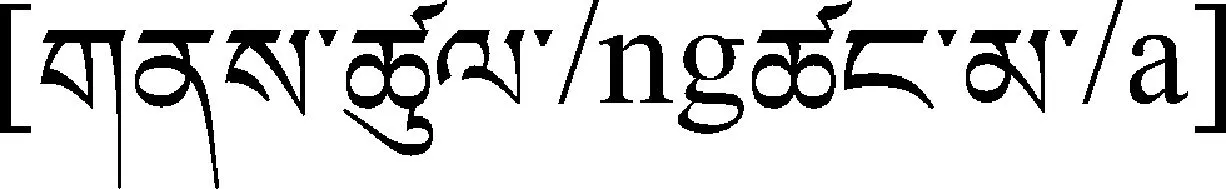



5.3 实验结果改进
利用已经建立的边界规则库和语义角色标注规则来优化统计标注的结果,在训练语料规模有限的情况下可能会产生一定的效果。因此我们利用手工编制初始规则集和利用TBL方法获得的扩充规则集对统计结果进行校正。在进行第二次实验时,本文选择了统计标注最好结果作为规则校正的对象。图3表示baseline统计方法标注、加入语义组块音节数统计方法标注以及统计和规则相结合的标注三种实验结果的对比。
从图3可以看到,利用规则方法对统计结果进行校正,与单纯依靠统计方法相比,实验结果有大幅度的提升,准确率、召回率和F值分别达到了82.78%、85.71%和83.91%,可见规则方法的调节效果还是比较明显的。
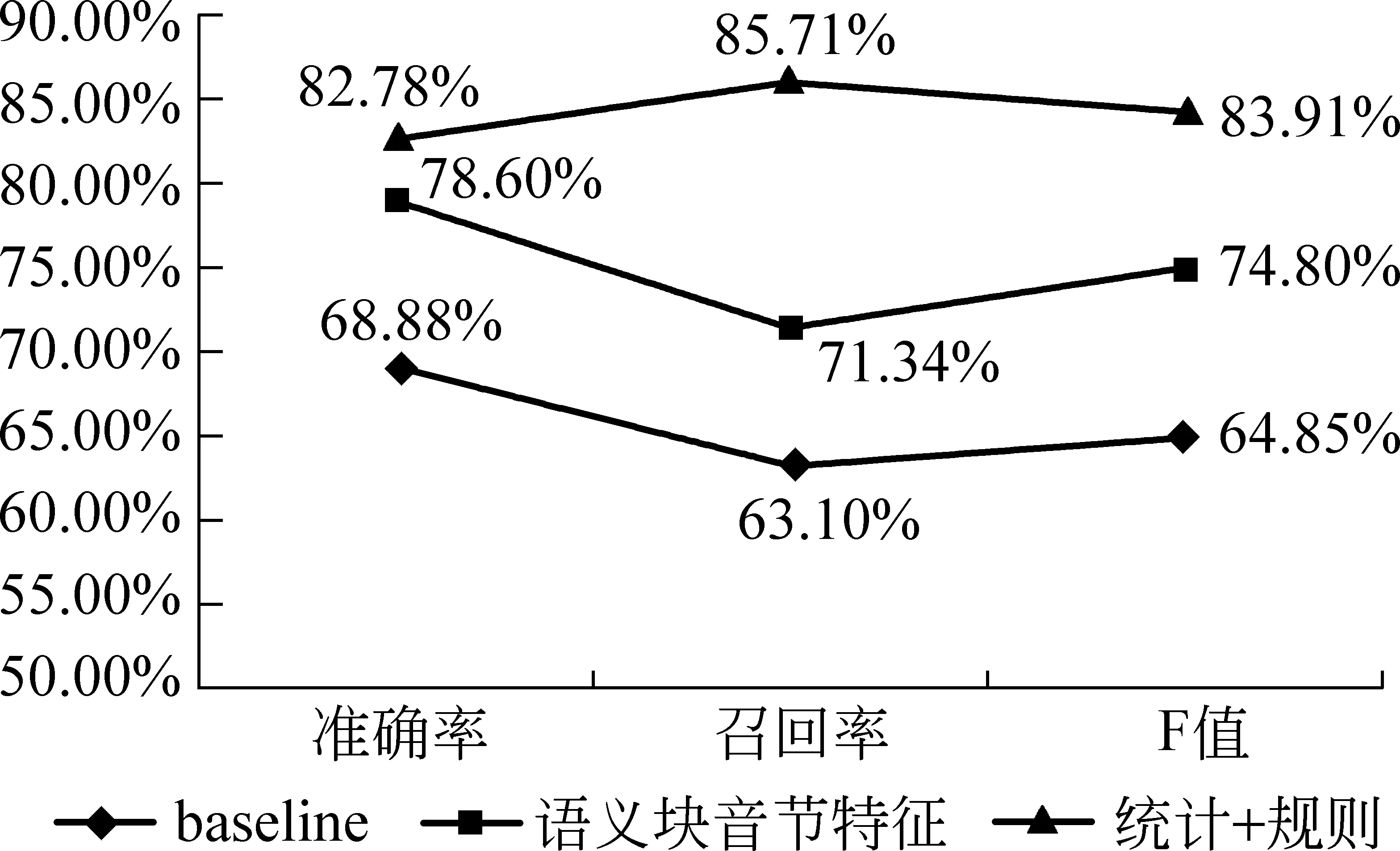
图3 三种方法标注结果对比图
6 结束
语义角色标注研究属于浅层句法分析的主要内容之一,在当前完全句法分析存在诸多困难的情况下,开展浅层句法分析可以有效地提高机器分析与理解自然语言的能力。语义角色标注研究的成果在机器翻译、自动问答、信息抽取等诸多领域都可以得到广泛使用。本文探讨了藏语语义角色标注研究,通过利用统计和规则相融合的策略,提升了语义角色标注的效果,实验结果准确率达到了82.78%。但是本项研究中,对嵌套语义组块和长距离语义组块的标注效果并不理想,这类错误拉低了标注的准确率。在后续研究中,除了扩充大规模的训练语料和精细化规则集之外,还需要对嵌套语义组块和长距离语义组块进行专门的纠错处理。
[1] Daniel Gildea, Daniel Jurafsky. Automatic Labeling of Semantic Roles, Computational Linguistics[J], 2002,28(3): 245-288.
[2] Kadri Hacioglu, Sameer Pradhan, Wayne Ward, et al. Semantic Role Labeling by Tagging Syntactic Chunks[C]//Proceedings of ConNLL-2004.
[3] http://www.cs.jhu.edu/EMNLP-CoNLL-2007/.
[4] http://www.clips.ua.ac.be/conll2008/.
[5] Ting Liu, Wanxiang Che, Sheng Li, et al.Semantic Role Lableing System using Maximum Entropy Classifer[C]//Proceedings of ConNLL-2005.
[6] Yu Jiangde, Fan Xiaozhong,Pang Wenbo, et al. Semantic Role Labeling Based on Conditional Random Fields, Journal of Southeast University[J]. 2007,23(3): 361-364.
[7] 王步康,王红玲等. 基于依存句法分析的中文语义角色标注[J],中文信息学报,2010,24(1): 25-47.
[8] 刘挺,车万翔等. 基于最大熵分类器的语义角色标注[J], 软件学报,2007,18(3): 565-573.
[9] 丁伟伟,常宝宝. 基于语义组块分析的汉语语义角色标注[J],中文信息学报,2009,23(5): 53-74.
[10] 江荻. 现代藏语的句法组块与形式标记[A].语言计算与基于内容的文本处理,孙茂松,陈群秀主编.北京:清华大学出版社.2003: 160-166.
[11] 江荻. 面向机器处理的现代藏语句法规则和词类,组块标注集[A], 江荻,孔江平主编, 中国民族语言工程研究新进展, 北京: 社会科学文献出版社,2005: 13-106.
[12] 李琳,龙从军,江荻. 藏语句法功能组块的边界识别[J]. 中文信息学报, 2013,27(6): 165-168.
[13] 龙从军,江荻.现代藏语带助动词谓语组块的识别方法[A].第2届青年计算语言学会议论文[C].2004.
[14] 袁毓林. 语义角色的精细等级及其在信息处理中的应用[J],中文信息学报,2007,2(4): 10-20.
[15] 周强,詹卫东,任海波. 构建大规模的汉语语块库[A],清华大学出版社. 自然语言理解与机器翻译,2001: 102-107.
[16] 周强,孙茂松. 汉语句子的组块分析体系[J],计算机学报,1999, 22(11): 1158-1165.
[17] 杨敏,常宝宝. 基于北京大学中文网库的语义角色分类[J],中文信息学报,2011,25(2): 3-8.
[18] http://www.keenage.com/.
[19] 鲁川. 汉语语法的意合网络[M],商务印书馆,2001: 111.
[20] 林杏光. 词汇语义和计算语言学[M],语文出版社,1999: 184.
[21] http://CRFspp.googlecode.com/svn/trunk/doc/index.html.
