基于错误驱动学习策略的藏语句法功能组块边界识别
2014-02-27王天航史树敏龙从军黄河燕
王天航,史树敏,2,龙从军,黄河燕,2,李 琳
(1. 北京理工大学 计算机学院,北京 100081;2. 北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081;3. 中国社会科学院民族学与人类学研究所,北京 100081)
1 引言
句法分析是自然语言处理领域的关键技术之一,在机器翻译、自动问答、信息抽取等诸多领域有着广泛应用。但是由于自然语言所具有的复杂性和不确定性,目前,完全句法分析器在性能与效率上还无法达到令人满意的效果。而采用“分而治之”的方法进行浅层的句法分析可以降低完全句法分析的难度。因此,组块分析逐渐成为目前的研究热点。
句法功能组块分析是组块分析的一个重要组成部分。它的研究目的是正确标注出构成句子的句法功能组块,自上而下地进行句子拆分获取句子中的基本信息单元,以显示句子在小句层面上的基本结构及骨架,为进一步的事件骨架树分析提供最小的功能组块描述序列。藏语词法研究的深入,藏语语料库的建设、藏语分词工具的开发和藏语组块理论的提出都为进行藏语功能组块分析的研究奠定了基础。目前,已经初步具备了开展藏语功能组块分析研究的条件。
本文在项目组前期研究成果的基础上,首先采用CRFs模型,利用改进的特征模板对组块边界进行初步识别;进而分别采用基于错误驱动的规则学习方法和基于错误驱动的统计学习方法对初次识别结果进行校正,从而得出最终的识别结果。通过对实验结果错误分析,本文进一步提出了基于错误驱动的规则与统计相结合的学习方法,进一步提高了功能组块边界的识别效果。
2 相关工作
英语、汉语在组块上的研究成果较多[1-10],这些成果为藏语功能组块的研究提供了较好的借鉴。
国内藏语组块理论及识别也已经开展。依据藏语的句法形式标记、词类以及其句法分布特点,文献[11]定义了7类句法组块。文献[12]对7类分类体系进行了扩充,提出了10类藏语句法组块。文献[13]对谓语组块的组成成分进行了深入研究,确定了9类体貌—示证标记范畴及形式标记。文献[14]针对现代藏语名词短语开展了研究,根据名词组块的三类句法形式标记构造识别规则集,预测名词组块边界。文献[15]提出了识别部分谓语组块的语法规则和算法,详细分析了藏语助动词的语法功能。这些研究的主要技术路线都是基于藏语句法规则进行的,目前采用统计方法对藏语组块进行识别的研究还较少。而随着藏语语言信息化程度的提高,近期也有学者从工程应用角度尝试用统计的方法对藏语组块进行识别。文献[16]是从汉语组块出发,通过对译译文寻找藏语组块的边界。但是该研究没有充分考虑藏语自身特点,特别是格标记属性特征的作用。文献[17]界定了5种句法功能组块,并首次将CRFs模型运用到藏语功能组块边界的识别,但选取的特征模板相对简单。
3 藏语功能组块
3.1 藏语功能组块描述性定义
本文所使用的功能组块定义遵循前期研究中采用的描述性定义,即主语块、谓语块、宾语块、状语块、补语块以及为了处理方便而增设的句法标记块[17]。
3.2 藏语功能组块标注集
本文采用BIE标记集来标记功能组块,把句法功能组块边界识别问题转化为一个序列标注问题。其中,功能组块起始位置标记为B,内部位置标记为I,结束位置标记为E,功能组块之外的标点统一标记为B。



图1 藏语功能组块边界识别标注实例
4 边界识别统计模型
4.1 前期工作
在前期工作中我们采用前后各两个词及当前词的词形和词性以及前一个词和当前词的转移概率特征作为特征,利用CRFs尝试了藏语功能组块边界识别,实验结果F值达到83.56%。为了进一步确定更优的特征,本文通过基于信息增益的特征选择实验,发现前后词的词形以及当前词的词音节数所蕴含的信息对藏语功能组块的边界识别有帮助,并且通过进一步的实验,将以上的单一特征进行组合,提出了改进的边界识别特征模板。
4.2 改进的CRFs特征模板
好的模板有助于对功能组块边界识别。通常来讲,丰富的上下文特征对于边界的识别率提高有着积极的作用,但过量的特征反而可能会降低训练的效果,并且会使训练和测试过程开销大大增加。考虑到这些因素,本文定义了原子模板,如表1所示。

表1 原子特征模板
其中,POSTag表示词性标注,ChunkTag表示组块标记,Word表示词形,Rhythm表示词音节数,实验窗口取5,上表中+/-表示当前词后/前的词对应的特征。当特征函数取特定值时,则该模板被实例化,如图2所示。

图2 原子模板特征选择示例

对表1的单一特征进行复合,通过实验选择,得到对边界识别有益的复合特征模板,如表2所示。

表2 复合特征模板

续表
5 基于错误驱动的组块边界识别策略
错误驱动是一种通过对错误标记的上下文特征进行学习,从而将错误标记校正为正确标记的学习算法,这种算法在词性标注和句法分析中都取得了不错的效果。本文分别利用规则的错误驱动技术与统计的错误驱动技术对功能组块边界进行识别校正。
5.1 基于转换规则的错误驱动学习
TBL算法是Brill于1992年提出的一个有效的学习算法[19],它的核心任务是构建用于校正的转换规则集。利用TBL自动获取转换规则集的算法如下:
算法1基于转换规则的错误驱动学习算法
Input: TC (训练语料) RT(规则转换模板集合)。
Initialize: RS=∅,Score=∅,EF,TM(RS为规则集合(有序),Score为对应的规则评价得分,EF为评价函数,TM为初始标注器)。
Step1:利用TM对TC进行初始标注,得到初始标注结果Result;
Step2:从RT中取出一条未选规则模板rti带入Result,通过错误学习得到转换规则集合TRS,并将rti标记为已选;
Step3:从TRS中取出一条规则ri对TC中满足规则触发条件的标记进行转换,利用评价函数对ri打分得到评分si,将si加入Score;
Step4:重复Step2,Step3直到RT中所有规则模板均已选,取出对应评分最高的ri加入到RS,利用ri对TC进行标注得到新的标注结果Result,将RT中所有规则模板重新初始化, Score清空;
Step5:重复Step2,Step3直到所有ri对应评分均为负。
Output: RS。
转换规则模板可以利用的属性信息包括: 词形信息(Word),词性信息(POS),功能组块标注信息(ChunkTag)。通过以上3类信息的组合使用,本文构造了模板转换条件,如表3所示。

表3 TBL规则转换模板
实验采用的评价函数如式(1)所示。
其中,F为转换规则的评价函数,XRr为应用规则r后正确的标记数,XEr为应用规则r后错误的标记数。通过上述过程,就可以得到用来校正的转换规则集。
5.2 基于CRFs的错误驱动学习
与传统的规则方法和基于转换的错误驱动方法不同,基于CRFs的错误驱动技术由统计模型来自动驱动纠错。它是将第一阶段CRFs本身识别的结果作为一般特征加入下一阶段的CRFs特征模板中,并融入第一阶段所应用的特征进行二次识别。CRFs错误驱动学习可以利用的属性信息包括当前词第一阶段的组块标记结果(Tag)与原模板特征集(POS,Word,ChunkTag)。根据以上属性信息的组合使用,本文构造了特征模板,如表4所示。
表4 CRFs错误驱动学习特征模板


表5 基于CRFs错误驱动技术的特征选择
将以上的特征带入表4对应的模板,就可以得到用来进行CRFs错误驱动的模板实例。
6 实验
6.1 实验数据及评价参数
实验使用Taku Kudo开发的开源CRFs++*http://CRFspp.googlecode.com/svn/trunk/doc/index.html进行模型训练。选择fnTBL*http://nlp.cs.jhu.edu/~rflorian/fntbl/index.html作为转换规则错误驱动工具。实验语料共包含18 073个词,将其随机分为三部分: 第一部(7 498个词)用来进行初次的CRFs训练;第二部分(8 043个词)用来错误驱动学习;第三部(2 532个词)作为最终的测试数据,用来测试训练效果。实验采用的评价标准如式(2)~(4)所示。
6.2 实验过程与结果分析
6.2.1 错误驱动学习方法独立实验
对训练数据进行预处理后运用4.2所提出的特征模板对训练语料进行训练,得到初步训练模型,分别利用两种错误驱动学习方法对初步识别结果进行二次训练,得到最终的模型,并在测试数据中运用上述两种训练模型进行测试得出最终的功能组块识别结果,如图3所示。

图3 规则与统计错误驱动学习方法独立实验结果
图中Baseline表示CRFs初次识别结果,TBL表示在初次识别后运用TBL错误驱动后的识别结果,准确率、召回率与F值分别达到84.54%、90.18%与87.27%,较初次识别F值提高了1.65%。CRFs表示在初次识别后运用CRFs进行错误驱动的识别结果,准确率、召回率与F值分别达到93.11%、94.86%与93.98%,较初次识别F值提高了8.36%。

6.2.2 错误驱动学习方法融合实验
通过对上面CRFs错误驱动的实验结果分析,本文进一步提出设想,能否运用规则的方法进一步对识别结果校正,从而弥补CRFs模型对长距离功能组块边界识别效果较低的缺陷。于是将第二部分训练语料分为两部分T1,T2,在都经过CRFs初步训练之后,将T1用来进行CRFs错误驱动学习,并将训练结果应用于T2之上,最终再在T2上利用TBL对其进一步训练,从而将统计与规则错误驱动学习机制相结合,识别结果如图4所示。

图4 规则与统计错误驱动学习方法融合实验结果
图中CRFs_1st表示CRFs初次识别结果,CRFs_2nd表示经过初步识别后利用CRFs进行错误驱动学习的识别结果,TBL表示在前两步的基础上利用TBL进行错误驱动学习的最终结果,准确率、召回率与F值分别达到94.1%、94.76%与94.43%,与前次实验结果相比,F值提升了0.45%,实验结果表明,通过两种错误驱动学习方法的结合,能够提升对功能组块边界特别是长距离功能组块边界的识别效果,尤其是在实验所用训练语料中长距离的句法功能组块不多且语料的总体量有限的情况下。
6.3 实验结果分析
通过上述实验可见,利用本文所提出的方法能够有效地对功能组块边界进行识别,但仍然存在一些典型的边界识别错误,本文将其归纳如下。
(1) 常用副词位置不固定导致识别错误。藏语中一些副词位置不固定,既可以放在修饰词前也可以放在修饰词后,遇到这种情况,往往会出现错误。

珠穆朗玛是非常高的山。

(2) 名词化标记导致识别错误。藏语中非谓动词后常常紧跟名词化标记,使整个非谓动词短语充当某种成分,遇到这种情况,往往会出现识别错误。
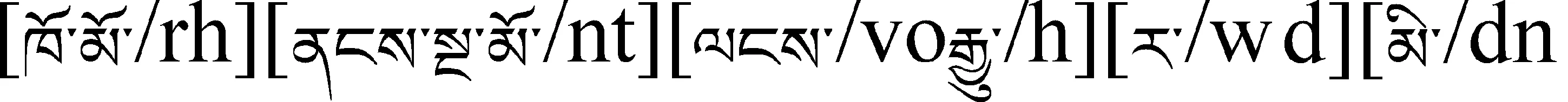
她不喜欢早起。
(3) 疑问语气词处于句中导致识别错误。通常情况下,疑问语气词会出现在句子的末尾,但有时由于出现嵌套句,疑问语气词出现在嵌套小句的末尾从而被嵌入句中,遇到这种情况,往往会出现识别错误。

我问: “早上好吗?”,但她不回答。
7 结束语
功能组块代表了句子的各个功能性成分,使待分析句子的结构得以简化,在进行句法分析时大大降低了分析的难度,也大大避免了直接在分词的基础上进行句法分析时由于词的数量较多引起的歧义,从而导致分析结构的准确率低等缺点。本文首先基于前期工作中藏语句法功能组块的描述体系,提出了一种错误驱动学习策略与条件随机场相结合的藏语功能组块边界识别方法,通过实验分析,进一步将两种错误驱动学习方法融合,最终实验结果准确率、召回率与F值分别达到94.1%、94.76%与94.43%。在下一步的工作中,我们准备在边界识别的基础上,进一步对功能组块的类型进行识别。
[1] Abney, Steven P.Parsing by Chunks[M]. Springer Netherlands, 1992.
[2] Ramshaw, Lance, Mitchell Marcus. Text Chunking using Transformation-Based Learning[C] Proceedings of the ACL Third Workshop on Very Large Corpora, 1995: 82-94.
[3] Tjong Kim Sang E F, Buchholz S. Introduction to the CoNLL-2000 Shared Task: Chunking[C]//Proceedings of the 2nd Workshop on Learning Language in Logic and the 4th Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2000(7): 127-132.
[4] Pierce D, Cardie C. Limitations of co-training for Natural Language Learning from Large Datasets.[C]//Proceeding of the 2001 Conference on Empirical Meth-ods in Natural Language Processing, Cornel University, Ithaca NY, 2001:1-9.
[5] 李衍,朱靖波,姚天顺.基于SVM的中文语块分析[J]. 中文信息学报,2004,18(2): 1-7.
[6] 李素建,刘群,杨志峰.基于最大熵模型的组块分析[J].计算机报,2003:1722-1727.
[7] Tan Y M, Yao T S, Chen Q, et al. Applying Conditional Random Fields to Chinese Shallow Parsing. Proceedings of CICLing2-2005. Mexico City, Mexico, 2005: 167-176.
[8] 周强,赵颖泽.汉语功能块自动分析[J].中文信息学报,2007,21(5):18-24.
[9] 陈亿,周强, 宇航.分层次的汉语功能块描述库构建分析[J].中文信息学报,2008,22(3): 24-31.
[10] 黄德根,于静.分布式策略与CRFs相结合识别汉语组块[J].中文信息学报,2009,23(1): 16—22.
[11] 江荻.现代藏语的句法组块与形式标记[A].语言计算与基于内容的文本处理,孙茂松,陈群秀主编.北京:清华大学出版社.2003:160-166.
[12] 江荻.面向机器处理的现代藏语句法规则和词类、组块标注集[A]. 江荻、孔江平主编, 中国民族语言工程研究新进展, 北京: 社会科学文献出版社, 2005: 13-106.
[13] 江荻.藏语拉萨话的体貌、示证及自我中心范畴[J].语言科学.2005(1):70-88.
[14] 黄行,孙宏开,江荻等.现代藏语名词组块的类型及形式标记特征[A].孙茂松,陈群秀(主编):自然语言理解与人规模内容计算[C].清华大学出版社.2005: 615-618.
[15] 龙从军,江荻.现代藏语带助动词谓语组块的识别方法[A].第2届青年计算语言学会议论文[C].2004.
[16] 诺明花, 刘汇丹, 马龙龙等. 基于中心语块扩展的汉藏基本名词短语对的识别[J]. 中文信息学报, 2013, 27(4): 63-69.
[17] 李琳, 龙从军, 江荻. 藏语句法功能组块的边界识别[J]. 中文信息学报, 2013, 27(6): 165-168.
[18] John D L,Andrew M,Fernando CN.Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[A].2001,282-289.
[19] Brill E. Transformation-based Error-driven Parsing[C]//Proceedings of the Third International Workshop on Parsing Technologies, Tilburg, The Netherlands. 1993.

王天航(1989—),硕士研究生,主要研究领域为自然语言处理、机器翻译。E-mail:hbcdwth@126.com

史树敏(1978—),通讯作者,博士,讲师,硕士生导师,主要研究领域为自然语言处理、机器翻译、语义计算。E-mail: bjssm@bit.edu.cn

龙从军(1978—),博士,助理研究员,主要研究领域为藏语语法、藏语信息处理。E-mail: longcj@cass.org.cn
