多种语义特征在突发事件新闻中的共指消解研究
2014-02-27杨尔弘
庞 宁 ,杨尔弘
(1. 太原科技大学 应用科学学院, 山西 太原 030024; 2. 北京语言大学 国家语言资源监测与研究中心平面媒体语言分中心,北京 100083)
突发事件是媒体关注的焦点。每一个突发事件产生后,都有大量的相关报道同时涌现出来。突发事件的应对是一个系统工程,其中一个重要环节就是信息的收集、整理、加工和发布。及时、客观、准确地收集信息,快速、高效地提取有用信息,为分析形势、制定策略提供翔实可靠的参考数据,已经成为提高突发事件应对能力的一个重要方面,也是衡量突发事件应对能力的一个重要指标。
1 引言
共指消解的研究目的是在一篇文本中,找到指示同一实体的名词、代词、名词短语,并形成若干个指代链。共指消解的研究课题越来越受到广泛关注[1],研究策略主要是在大规模语料库的支持下开展的,近年来利用语义特征进行共指消解成为研究热点,例如,国外Ng[2]研究小组在前人的研究基础上,提出一种自动获取语义类的方法,引入ACE的语义分类标准,将名词的语义类特征代入指代消解模型中,在ACE测试语料上的实验结果表明,F值提高2个百分点。Yang[3]在预先定义的语义模式的基础上,提出一种自动发现和评估模式的方法,并从语义模式中挖掘出语义相关信息,再将获得的信息应用于指代消解,通过试验证明语义相关信息是消解的一个重要因素,实验表明模式信息有助于指代消解。国内苏州大学的王海东,孔芳等[4]通过实验发现将语义角色特征和指代链特征以及代词细化特征的结合,能够显著提高系统的性能, 特别是对代词的消解有很好的效果。
1.1 突发事件语料的特点及标注方法
突发事件语料与普通文本语料相比,具有以下几个特点。
1) 命名实体的突显性。在突发事件的语料中,围绕事件本身的相关的人物、组织结构、发生地点、发生时间等命名实体集中地突显出来,例如,马德里爆炸案中,“西班牙 ns”、“ 阿斯纳尔 nh”、“ 巴斯克民族分裂组织 ni”、“ 上午7时45分 nt”,命名实体在词语中的比例高达38.24%,由于突发事件是同事件的多文本,这些命名实体出现在文本中的重复率很高,所以准确识别和标注命名实体是良好地消解共指现象的基础。
2) 未登录词的集中性。由于突发事件新闻报道通常是集中描述某一突发事件的发生和发展,大量与事件特征相关的描述性词语频繁出现,而这些词语通常在分词中均为未登录词,例如,在马德里爆炸案中,“国际社会”、“恐怖袭击事件”、“连环爆炸事件制造者”等,这些词语往往涵盖了事件的重要信息,由于反复出现的几率很大,所以常被指代,因此这部分未登录词的标注对共指消解是很关键的。
3) 标注语料的事件性,将事件信息作为标注的语言单位,突发事件报道以新闻六要素为关注点,所以,本文标注语料时,将事件的这些要素,包括事件发生的时间、地点、人物、内容、起因、结果等等作为事件信息重点标注出来,突发事件中事件的数量约为句子数量的2.3倍(突发事件信息的标注研究),说明一个句子中不是单一的一个事件,而是多事件,因此标注语料是以事件为单元。
本文所用语料均来自新华网,中新网,东方网,人民日报网等新闻网站。在标注语料时,参考 HTML 超文本标记语言格式方法,采用多组标签对有利于计算机自动识别和人工处理。例如,分别表示实体编号,实体字数长度,实体的类型;表示实体的中心词。
1.2 突发事件语料中的共指现象
在突发事件新闻报道中,存在很多的共指现象,通过对同事件多文本的突发事件报道的分析,我们观察到如下共指特点[5]。
1) 人称代词的指代现象
a. 指示语指称的是一个人名实体,且指示语的候选先行语唯一,虽然有的距离跨越非常大,但是在先行语与指示语之间再没有其他人名实体出现;
b. 指示语指称一个名词短语,这类指代消解需要先进行名词的短语捆绑,表示复数概念的还需要并合连词两侧的同类名词短语;
c. 指示语指称组织/人名的概率较大,由于突发事件新闻报道的突发性、集中性,大量文本的指代相对集中某些特定类别的实体,例如,在“马德里爆炸案”事件中,指示“组织”的指示语占32.9%,指代“人名”的占 45.4%。
2) 指示代词的指称现象
超声辅助酸碱改性活性炭纤维对DBT脱硫性能的研究……………………………………………………………(1):7
指示代词指称的是一个事件或命名实体,这类指代占到了共指现象的62.07%。
2 共指消解原型系统
针对突发事件新闻的共指消解任务,我们利用最大熵模型搭建了一个原型系统。所采取的解决策略是: 首先对语料库进行预处理,包括句子边界识别、分词、词性标注、命名实体识别、名词短语识别、名词短语中心词获取等。从训练集中获取到用于共指消解的正例和反例,再用GIS算法对最大熵模型进行训练,利用训练好的模型计算各待消解对的共指概率并用归并策略得到共指链[6]。针对汉语自身特点以及消解任务的需求将特征分为4大类,共8个特征[6]。4大类特征分别是词汇特征、语法特征、语义特征、距离特征、每种特征的具体特征分类以及该特征值的取值方法见表1。

表1 特征选取说明表
3 语义特征
3.1 用于自然语言处理的语义信息
目前,可用于自然语言处理研究中的语义信息基本可以归纳为3类,语义类别,语义角色,语义相似度[7]。语义类别通常是指词本身所属的类别,通常这类信息可以用于初步过滤非指代的现象,而语义角色是指各种名词短语对应于句中动词所承担的句法成分,语义相似度表示两个名词短语可以替换的程度,相似度越大的名词短语就有可能相互指代。但是,能够用于代词消解,尤其是中性代词,例如,它、它们、其、等这类代词的消解仅用上述语义信息是不能完全消解的,因此我们尝试在消解系统中加入了上下文特征等其他特征,帮助提高消解效率。
3.2 多语义特征在系统中的使用
本系统的语义特征共分为3大类,分别为基于词典的语义类别特征、基于句法的语义角色特征和基于维基百科的语义特征。
1) 基于词典的语义特征
在原型系统中,我们采用了直接在HowNet上判断各待消解项的语义类别的方法,对多义词没有进行排异,同时由于方法过于简单带来较大噪音,因此,为了提高各待消解项的语义类别的识别,我们将语义类别细化,并采用了基于机器学习与基于字典相结合的方法。首先是对语料中命名实体的语义类别的获取,本文命名实体的类别是基于HMM的命名实体识别,根据 MUC会议的定义,命名实体有人名(person)、地名(location)、机构名(organization)、日期(date)、时间(time)、百分数(percentage)、货币(monetary value)这7类。本文中命名实体的语义类别就是指这个实体的类别。其次,对于命名实体识别程序没有识别出来的名词短语,我们获得它的中心词,然后在HowNet中查找其语义类别信息。表2是本文关于语义类别信息抽取的8种特征。

表2 语义类别特征
2) 语义角色特征
语义角色标注是浅层语义分析的应用之一。语义角色是句子中的名词短语在相应动词驱动下所承担的句法成分。核心的语义角色为Arg0—5六种,Arg0通常表示动作的施事,Arg1通常表示动作的影响等。其余的语义角色为附加语义角色。依据中心理论,在一个句子中,主语最可能被指代,其次是宾语,最后是其他的一些名词短语。如果先行语是句子的中心,比如作为主语或宾语,那么它很可能被指代。将语义角色和代词特征结合,可以识别并排除一些不需要消解的固定搭配中的代词。具体语义角色特征见表3。
目前维基百科被广泛应用在自然语言处理的各个领域中,维基百科页面之间具有非常密集的站内链接和便于机器访问的结构化信息,利用其解释页面间超级链接之间的关系,可挖掘出语料中的更为深刻的语义关系。维基百科中一个解释页面对应一个主题概念,解释页面有简洁的标题,通常对应目标概念的标准名称,解释页面开头的几个段落,特别是第一个句子是对主题关键词概念的定义和基本描述。

表3 语义角色特征
后续段落分别围绕主题从各个角度展开具体阐述。
(1) 语义相关性特征。本文利用解释页面中的链接文字相互引用关系抽取语义相关词,假设,若A的基本解释或相关内容中利用超级链接引用了关键词B,而B页面也包含了指向A的超级链接,那么A和B就可以被认为是具有语义依赖关系的相关词。根据超级链接所处的位置,A与B的语义依赖关系也不同,故设计的特征也不同,如从与主题语义相关性的角度考虑,位于页面第一部分的基本描述段落最重要也最紧密,故设计了I/J_BASIC_CONTAINS特征,I/J_PARTIALBASIC_CONTAINS特征反映的语义相关性则次之,因为考察项可以出现的位置范围从基本描述段落扩大至整个页面,而假设一对候选共指对(i,j),具体特征如表4所示。
(2) 重定向特征。维基百科通过重定向页面技术将同一概念的不同表达方式(简称、别名和非正规名称等)链接到其主题概念的解释页面。具体方法是,在解释页面中寻找到“重定向自”标记,后面就是该实体的另一表述文字。另外在解释页面文档的首段文本中有许多黑体标注的词,这些词同样也是同一实体的其他表达形式。突发事件新闻报道中存在大量专有名词无法被常规规则识别,其别名或简称更没有专门的词典或数据库可以借鉴, 极大地影响了基于突发事件共指消解的效率,因此,借助维基百科的重定向技术可以很好地解决上述问题。

表4 语义相关性特征
I/J _redirection: 如果i(或 j)是维基百科的某个词条,而j(或i)是i(或 j)的重定向页面上的词条,则返回1 ,否则返回0。
(3) 上下文特征。由于代词本身缺乏明显语义,故本文特别设计了I_CONTEXT、J_CONTEXT两个特征,分别计算出I、J的背景知识与上下文[8]之间的相似度,本文采用了一种基于维基百科的文本距离法来计算背景知识和上下文的相似度,首先分别定位词对(ca,cb)到相关的维基百科的解释页面,抽取各自的解释文本的基本段落(pa,pb),在解释文本中统计共同出现的词串。如果找到n个词串分别包含mn个词,则词对(ca,cb)的相似度如式(1)所示。
(1)
具体特征见表5。

表5 上下文特征
4 系统测试和结果分析
4.1 实验语料和评测指标
本实验共标注了25万字突发事件新闻语料用于训练和测试,其中选取了5万字语料用于测试,本文采用MUC对指代消解结果技术评估的三个指标,召回率 R(Recall)、准确率 P(Precision)和 F 值。其中: 召回率 R 是指代消解结果中正确消解的对象数目占消解系统应消解对象总数的百分比,它反映的是指代消解系统的完备性;准确率 P 是指代消解结果中正确消解的对象数目占实际消解的对象数目的百分比,它反映的是指代消解系统的准确程度。比较两个不同系统的性能时,一般使用 F 值,F 值是召回率和准确率的调和平均数,定义如式(2)所示。
4.2 实验结果及分析
本文在原型系统和多种语义特征下的测试结果对比详见表6。
语义类别特征是在原型系统的语义一致性的基础上,增加了专用名词类的判定,例如,人名、组织名、地名和事件,这些实体恰恰是突发事件中经常出现的。因此召回率增加了1.12%,准确率增加了2.44%。
在原型系统的基础上单纯加入语义角色特征,各指标均有所下降,F值下降了1.31%。原因是语义角色特征有强化句子中心的作用,而代词往往是作为句子的中心,所以单纯加入角色信息会有一定的干扰作用。因此将语义角色与代词特征相结合,能突显代词的语法角色,有助于提高系统性能。
原型系统加入语义相关性特征,之前没有被正确识别的待消解项由于在维基百科页面上同现而被正确识别,但同时也带来了的噪声。因此召回率升高的同时,准确率也会降低。
在维基百科网页中,重定向页面不包含具体的解释内容,仅通过重定向链接指向与当前页面标题指向同一概念但包含解释内容的主页面,因此,重定向特征有助于互为别称,简称等待消解项的识别,该特征对系统的各指标都有所改善,F值提高了0.22%。

表6 原型系统和改进系统的测试结果
代词是所有待消解项中最缺乏语义信息的一类词,而上下文特征正是针对词前后内容提出的,不需要考虑词本身,因此该特征会提高系统的精确率。
另外,本文对维基百科的各语义特征对原型系统的影响分别做了测试,测试结果见表7。
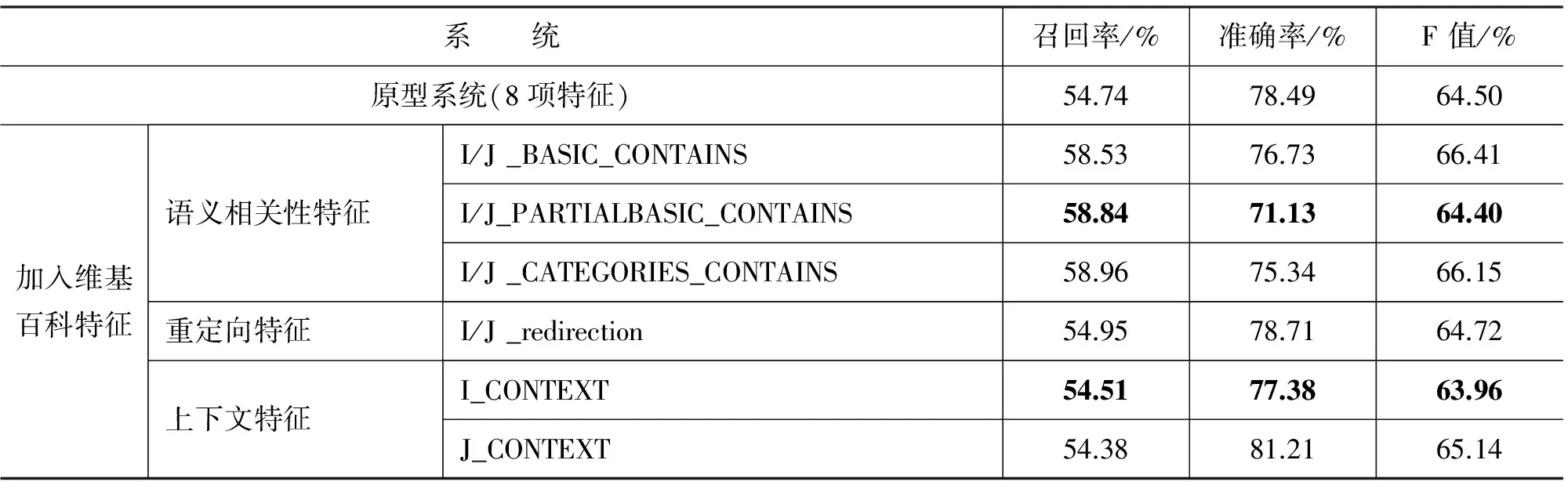
表7 各维基百科语义特征对原型系统的影响测试结果表
分析表7中的结果,发现语义相关性中的I/J_PARTIALBASIC_CONTAINS特征F值降低了0.1%,分析原因,我们认为该特征是在整个网页中寻找语义相关词,会带来大量噪音,因此虽然召回率提高,但准确率下降了7.36%。
而上下文特征中的I_CONTEXT。该特征取先行词I周围的词与指代词J在维基百科中计算相似度。分析语料发现指代词J极有可能是代词,缺少对应的维基百科的背景知识页面,同时一般在句首的先行词无法提取该词的上文,所以相应的计算结果不理想。
从上述实验结果分析,各语义信息特征对消解效果均有贡献,其中维基百科特征中I/J _BASIC_CONTAINS特征的贡献最大,而同样在代词细化下的语义角色特征也使消解性能得以改善,但是也有各别特征对系统起到了负作用,例如,单纯语义角色、I_CONTEXT、I/J_PARTIALBASIC_CONTAINS特征。这说明对维基百科的背景知识的结构信息还有待进一步研究,例如,重定向和消歧页面是维基百科语义挖掘需要重点关注的资源。实验表明,挖掘维基百科的深层语义信息将是共指消解研究的一个有意义的研究方向。
[1] 张牧宇. 基于中心语匹配的共指消解[J].中文信息学报,2011,25(3):3-8.
[2] Vincent Ng.Shallow Semantics For Coreference Resolution[A].IJCAI,2007: 1689-1694.
[3] Xiaofeng Yang,Jian Su. Coreference Resolution Using Semantic Relatedness Information from Automatically Discovered Patterns[C]//Proceedings of ACL, 2007:528-535.
[4] 王海东,胡乃全,孔芳,等.指代消解中语义角色特征的研究[J].中文信息学报,2009,23(1):23-29.
[5] 杨尔弘.突发事件信息提取研究[D]. 北京语言大学博士学位论文, 2005.
[6] 庞宁,杨尔弘.基于最大熵模型的共指消解研究[J].中文信息学报,2008,22(2):24-27.
[7] 李艳翠.语义信息在指代消解中的应用研究[D],苏州大学硕士学位论文,2008.
[8] 郎君,等.集成多种背景语义知识的共指消解[J],中文信息学报,2009,23(3):3-9.
