基于吸收马尔可夫链的子话题发现方法
2014-02-27魏明川朱俊杰程学旗
魏明川,朱俊杰,张 瑾,张 凯,程学旗,任 彦
(1. 中国科学院计算技术研究所,北京 100190;2. 中国科学院研究生院,北京 100190;3. 国家计算机网络应急技术处理协调中心,北京 100190)
1 引言
随着互联网信息的爆炸性增长,如何在海量信息里更快速、准确地提取有用信息日益成为一大挑战。由于传统信息检索技术在有效获取有用信息方面作用有限,因而对如何有效地提炼各种文本信息知识提出了难题。话题检测与跟踪(Topic Detection and Tracking ,TDT)着力研究如何对网络文本进行高效组织和检索。但某些话题对象存在持续时间长、涵盖事件多的特点,如果直接用TDT中的定义事件组织专题,会导致事件个数随着专题规模扩大而爆炸增长;同时,TDT无法发现话题中事件的关系,很难检测话题中事件生成、衍化直至消亡的过程。针对以上问题,很多研究都提出建立子话题层的解决方法,在话题层和新闻事件层生成子话题层,使之成为衔接话题和事件之间的桥梁,从而构建出适合大规模数据自动分析的完备组织模式。传统子话题划分方法一般都是基于词元的向量空间模型或基于此模型的一些改进方法,所得结果在重要性和多样性上存在欠缺。
针对上述问题,本文提出一种基于二元关键词组的子话题划分模型,并且利用吸收马尔可夫链算法对生成的子话题进行有效吸收提取,从而得到兼备重要性和多样性的子话题结果。本文结构如下: 第2节介绍相关工作;第3节介绍本文提出的子话题发现模型;第4节描述实验数据、评测标准、最终实验结果及其分析;第5节为总结和下一步工作展望。
2 相关工作
作为话题表示模型的基本单元,关键词是表示话题内容和区分话题类型的主要元素,因此TDT的一个研究热点是研究如何从大量文本中提取出能独立代表一个话题的关键词。
基于关键词的话题研究方面,Makkonen[1]提出根据话题的4个要素,将词语分成时间类、地点类、实体类、动作类,从而将一个话题表示为一个语义向量{时间、地点、人物、事件}。在此思路下Hua-Jun Zeng[2]提出将词语在文章的属性具体表示为包括tf-idf、词语长度、内部聚合相似度等概念,通过将词语属性进行线性组合,计算词语在文章中的权重,排序生成关键词,但是对以上特征的具体选取并没有较好的解决方案。王巍[3]只利用tf-idf特征值,将词语位置分为标题和正文,修正不同位置的关键词tf-idf值并进行线性组合,通过标题长度和正文长度比进行动态调整,从而降低词频噪音。
子话题是话题(或子话题)内一组相关事件或活动的集合。目前子话题的研究大都是基于话题内的子话题划分,该方面研究并没有太多新颖有效的模型或解决方案,主要思路还是延续基于关键词的方案。
基于话题内子话题的发现研究方面,袁继鹏[4]提出计算每个关键词的新颖度,并以此作为子话题分界的依据之一,其新颖度用分布密度来表征,从而得到子话题的分界点,并最终以此分界点作为子话题衍化时间点。另外,李军等人[5]提出基于话题模型的子话题划分方法,方法用隐含语义空间表示文档,采用层次聚类进行子话题划分。
以上方法都是基于1个关键词的一元模式,但实际生活中很多事件很难用一个关键词准确描述,因此以上方案都存在子话题划分准确度不高,结果不够理想的情况。本文提出了二元模式的子话题划分方案,但该方案由于特定关键词的权重唯一性,权重高的关键词相互之间会生成冗余子话题,从而导致生成结果多样性效果较差。
针对子话题多样性质量优化问题,张瑾等人[6]提出基于图的子话题划分的多文档文摘算法,算法中借助吸收马尔可夫链来更新句子的贡献度,并借助其收敛性实现文摘算法的稳定性。但该算法的衰减过快,不能具体适应本文的子话题模型。
针对此问题,本文提出一种针对子话题的吸收马尔可夫链算法(absorbing Markov chain subtopic, AMCSubtopic)来提升子话题多样性质量。
3 基于吸收马尔可夫链的子话题发现方法
3.1 二元关键词子话题表示模型
目前各大门户网站及主要搜索引擎公司都提供热点关键词新闻服务(百度新闻首页的热词新闻模块)。将围绕某一事件或与该事件密切相关的若干事件的新闻报道共同组织在一起全方位,多角度跟踪报道新闻事件。基于关键词的话题演化分析通过计算话题文档集合中词语的权重,选出权重靠前的若干词语作为话题描述信息,以此将话题文档进行分类从而形成子话题。对于新闻事件而言,其六要素特性(人物、时间、地点、起因、经过、结果)往往要求描述每个事件至少涵盖两个到多个关键词。但关键词具有词义独立性,因此过多关键词来描述子话题反而会导致子话题的聚焦性失衡;而且实际系统的运行效率会随着子话题的关键词规模的增多而增大。因此模型在词元个数选择上存在较大商榷性。

表1 关键词子话题模型对比结果
如表1的初步实验对比发现,一元关键词描述信息过于粗略,而多元关键词存在信息冗余。综合复杂度和有效性两个方面,本文提出基于二元关键词的子话题模型,该模型不但能够避免单关键词表征意思失衡,同时也降低了系统时间复杂度。模型核心特征在于二元关键词组合的tf-idf值,计算方式如下:
话题T共有n篇文档语料D{d1,d2,…,dn},每篇文档语料都含有若干关键词,所有的关键词集合为W{w1,w2,…,wm},每个关键词在语料D中都有其特定的tf-idf值,将tf-idf分开为集合TF{tf1,tf2,…,tfm}和IDF{idf1,idf2,…idfm},对于任意一个关键词Wi满足式(1)。
其中tfik表示关键词Wi在文档Dk中的词频值。对于模型而言,其关键词组WiWj的联合初始联合TF-IDF计算公式如式(2)所示。

(2)
对每篇语料分别算出每个子话题对应两个关键词的tf-idf值,并取其最小值,这样做有两个目的:
1) 能保证两个关键词作为一个联合整体被纳入考虑;
2) 能保证两个关键词组和对应文档语料有合适的相关度。
通过式(2)计算出来的联合初始tf-idf值并不能作为真正的评判结果指标进行子话题划分,否则会引入高频关键词两两生成高频子话题簇,导致生成结果多样性质量不好。例如,“食品安全”话题下的一批文档,按照以上联合初始tf-idf值计算出来的前7个热点子话题结果如下:
{1“产品 市场”;2“安全 市场”;3“市场 年中”;4“安全 生产”;5“企业 市场”;6“企业 安全”;7“产品 安全”}。
以上结果虽然跟话题有较大关联性,但结果实际主要由关键词组{“产品”;“市场”;“安全”;“生产”}组合生成。结果的覆盖冗余性过高, 多样性不足。为了解决以上问题,我们引入了以下的AMCSubtopic算法。
3.2 基于吸收马尔可夫链算法的子话题检测模型
张瑾等人[6]提出用吸收马尔可夫链来改进文摘质量, Zhu xiaojin等人[7]提出用吸收马尔可夫链来提升结果多样性。为了更好地评价二元关键词组模型,本文借鉴以上工作,提出基于子话题先验的关键词组策略模型SubtopicRank,对指定话题t的多文档语料而言,令F=[f1,f2,…,fl]T表示关键词组重要性得分向量,面向子话题的先验分布R=[r1,r2,…,rl]T,则SubtopicRank策略可以表示为式(3)。
f(t+1)=λr+ (1-λ) ·M·f(t)
(3)
其中M是转移概念矩阵,λ是置信度参数,本文模型λ为0,即不考虑先验知识。为了同时考虑子话题的重要性、新颖性和多样性,我们引入吸收马尔可夫链。将已入选的关键词组中两个关键词对应的状态都设定为吸收状态。基于此引入吸收模型,其模型转移矩阵见式(4)和式(5)。
其中N为n*n的矩阵,为
β为衰减系数。因此SubtopicRank策略公式即式(3)转化为式(6)。
对于式(2)而言,算法AMCSubtopic目的是利用其吸收特性,对联合初始tf-idf值进行重排序。因此根据式(6),我们可以得到如下计算联合tf-idf值的公式:
3.3 模型算法及实现过程
在引入AMCSubtopic算法后,子话题模型得以很好解决子话题新颖性、重要性和多样性的问题,而本文具体实现方案即针对二元关键词组联合tf-idf值进行重排序,并设定阈值,取出排名靠前的K个二元关键词组作为子话题生成结果。
模型流程如下:

2) 得到二元关键词组初始权重: 按式(2)计算得到每个关键词组的初始权重值、排序;
3) 得到最终子话题: 将关键词组按序放入待吸收队列中,每次取出队列中最大权重条目作为吸收子话题,然后根据AMCSubtopic算法更新队列中剩余条目权重值,重新排序,重复以上过程直至队列为空。
具体算法实现过程如下:
输入:n篇t话题下的文档语料,每篇文档限定的关键词数x,衰减模型中衰减系数β,最终子话题个数s。
输出:s个子话题
fori←0ton
do
Wi=DivideDocIntoWord(Di)
MergeWord(&G,Wi)
done
SortWordByTf(&G)
fori←0tog-1
forj←0tog-1
do
Make2Keywords(&F,gj,gj+1)
done
done
SortWordByTf(&F)
len=0
whilelen!=s
do
Slen=PopFromBegin(&F)
UpdateByMarkov(&F,β)
len++
done
4 实验结果及分析
4.1 实验数据集及实验指标
为了评测子话题发现模型生成结果质量,本文共设计3种指标进行评测。子话题中联合关键词组的tf值可作为该子话题和对应文档的相关度。两个关键词如果在一篇文献中同时出现过,表示该子话题和该篇文档相关联。基于此本文设计了子话题覆盖度cr、子话题独立度dr两个关于子话题及文档相关度的评测指标。

子话题覆盖度(cr)为所有子话题关联文档的并集和原始文档集的相似度,cr越大,说明子话题关联文档并集和原始文档集余越接近。cr为1表示子话题关联文档并集和原始文档集重合;而dr表示任一子话题和其他所有子话题关联文档集的差异情况,dr越大,说明子话题之间关联的文档交集越小,说明子话题之间多样性越强,如果dr为1,表示子话题之间完全独立。
为更形象体现子话题之间独立性,我们设计了第三个评价指标: 关键词的独立度wr。已知每个子话题stk有两个关键词sTWk={stwk1,stwk2},对于独立性不高子话题集而言,各个子话题之间重复关键词较多,因此wr是一个描述子话题集关键词之间的重复情况的指标。公式如下:
wr越高,说明子话题之间关键词重复度越低,对应子话题独立性越高,反之亦然。
本文使用某在线系统,人工配置9个新闻话题进行数据采集,得到文档数量和相应话题名称如表2所示。
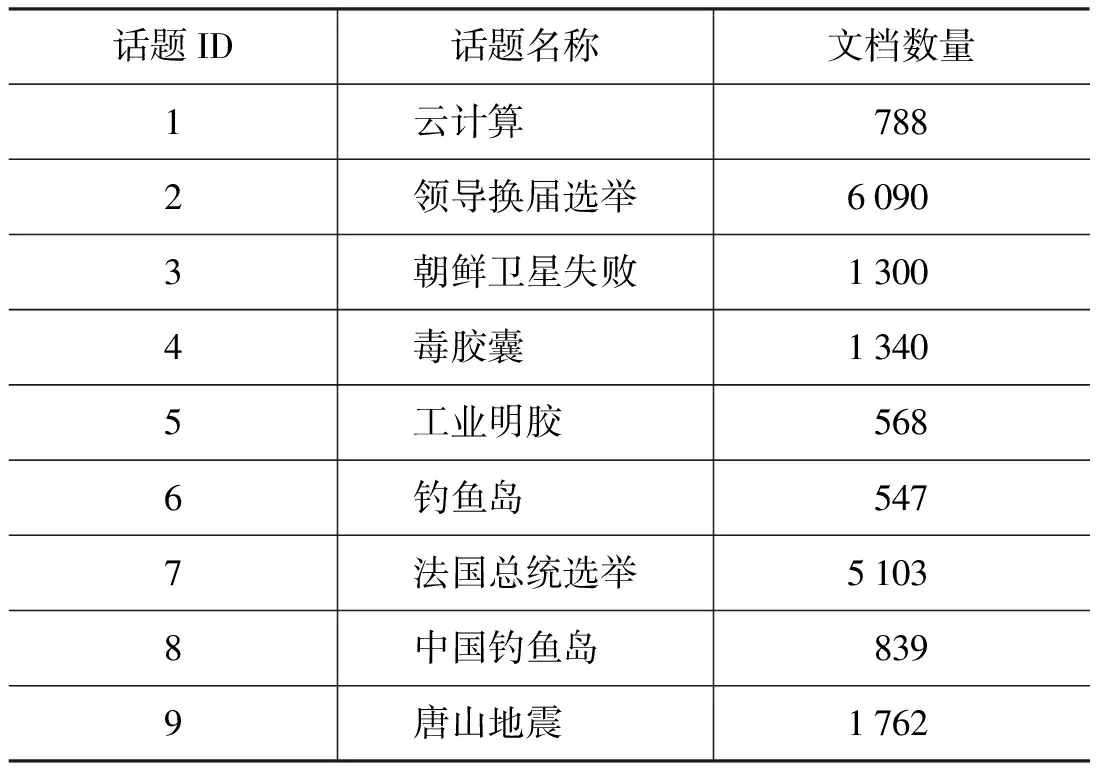
表2 待检测话题
系统采集源都是来自中国境内的各个新闻网站,因此数据源可靠且准确。为了更好评价相似话题的子话题结果,我们选用了话题4和话题5、话题2和话题7两组相似度较高的话题集用于评测。
4.2 实验结果
4.2.1 对比测试
根据以上9个话题数据集,本文使用测试模型1为原始二元关键词子话题模型,模型2为引入AMCSubtopic的子话题模型,测试中分别取每个话题集的前20个子话题结果进行测试。实验基于子话题覆盖率,多样性和独立度生成的实验结果分别如图1、图2和图3所示。

图1 子话题覆盖率结果图

图2 子话题多样性结果图

图3 子话题关键词独立度结果图
图1中显示模型2在9组话题测试结果中其子话题的覆盖率都高于模型1,说明模型2中子话题结果并集对原始语料的覆盖度有所提升, 从而更好全面体现出话题内容概要。
图2中模型2在子话题多样性上性能较模型1有了大幅度提升,多样性平均提升了约10%,从而说明了AMCSubtopic对子话题冗余信息处理非常优秀。
结合图1、图2结果可以看出,基于AMCSubtopic的子话题发现模型不仅提升了子话题结果并集的覆盖度,还减少了子话题之间彼此的信息冗余,尤其在信息冗余处理上,效果非常明显。
图3是验证子话题多样性更直观的结果图。而图3中模型2的子话题关键词组基本没有重复,而模型1的子话题组关键词重复情况比较严重,从而说明模型2的多样性的确优于模型1,也印证了本文引入AMCSubtopic的想法初衷。
4.2.2 人工评价
为了更好的评测结果,我们从AMCSubtopic模型生成的子话题结果截取前10个进行人工标注测试。我们邀请了20个不同工作领域的用户进行测试,用户按重要度递减标注出每个话题前5个子话题作为热点Top5结果。对比人工标注的Top5和模型自动生成的Top5结果,根据排名给出权重值得出标注结果和自动结果的匹配度,从而评价模型性能。
AMCSubtopic模型生成的9组话题top5子话题和对应的人工标注匹配结果如表3所示。
从表3可以看出,AMCSubtopic模型自动生成的子话题结果基本和用户信息需求基本完全吻合,9组结果中有5组结果能够完全吻合,最低的也能达到80.00%,说明本文实现的子话题切分模型已经能够有效的生成符合用户需求的子话题结果,从而达到子话题检测目的。
但人工标注的匹配结果还不能完全达到100%,说明子话题结果质量还有优化空间。分析结果时发现,以实体作为一个关键词的子话题结果往往更能够符合用户要求,因此本文下一步工作方向将结合实体,实现更高质量的子话题发现模型。另外,通过表3可以看出,话题4、5和话题2、7之间生成的top5子话题结果比较接近,而该两组话题本身之间存在较大相似性,从而说明通过子话题之间关系可以反推出对应话题间关系。因此,本文的另一个工作方向就是基于子话题关系分析话题间关系。
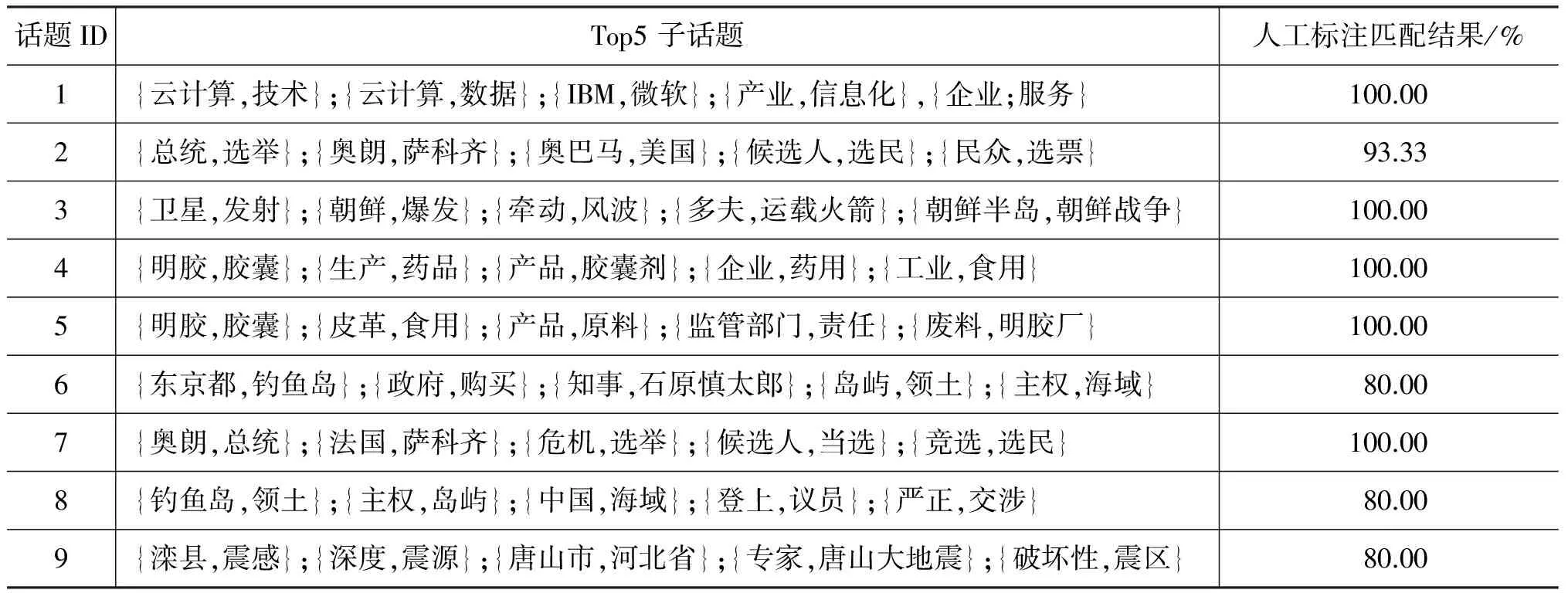
表3 Top5子话题统计结果表
5 总结与下一步工作
由于传统话题检测方法对于选择事件粒度比较困难,因此对于一些小粒度事件的发现及追踪有较大难度,本文提出的基于二元关键词子话题划分模型能够有效解决该方面的问题,并且在模型中引入了吸收马尔可夫链算法,从而能够有效实现子话题的代表性和多样性。通过人工标注测试,生成了和用户标注较为吻合的子话题结果,从而验证了模型的可实用性。但文本仅仅引入关键词组的tf-idf属性,在分析具体系统运行结果中我们发现某些实体关键词对子话题的划分也起到一定正相关的影响。因此本文下一步的研究点将纳入考虑实体关键词对子话题划分的影响。另外,我们将继续拓展子话题关系模型的研究,研究子话题之间衍化和话题之间基于子话题的关联分析等。
[1] Makkonen J,Ahonen-MykaHand SalmenkiviM Applying semantic classes in event detection and tracking[C]//Proceedings of International Conference on Natural Language Processing(ICON) Mumbai, India,2002: 175-183.
[2] Hua-Jun Zeng,Qi-Cai He, Zheng chen, et al. Learning to Cluster Web Search Results[C]//Proceedings of SIGIR’04, July, Sheffield, South Yorkshire, UK,2004:25-29.
[3] 王巍. 基于关键词和时间点的网络话题演化分析.[D]. 复旦大学中国优秀硕士学位论文. 2009.
[4] 袁继鹏. 网络舆情话题演化及话题重要度分析[D],中国科学院计算技术研究所硕士学位论文, 2012.
[5] 李军,李娟子. 新闻专题内子话题划分. 清华大学计算机科学与技术系[C]//Proceedings of the Fourth National Conference of Information Retrieval and Content Security,2008,Vol.1.
[6] 张瑾. 面向Web话题的多文档文摘关键技术研究[D]. 中国科学院计算技术研究所博士学位论文,2009.
[7] Zhu Xiaojin,Goldberg A B,Van Gael J,et al. Improving diversity in ranking using absorbing random walks[C]//Proceedings of Human Language Technologies:the Annual Conference of the North American Chapter of the Association for Computational Linguistics.Rochester:NAACL,2007:97-104.
[8] 洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):72-57.
[9] 骆卫华,于满泉,许洪波,等.基于多策略优化的分治多层聚类算法的话题发现研究[J]. 中文信息学报,2006,20(1):29-36.
[10] 张瑾,许洪波. 基于动态内容的文摘方法研究[C]. 第三届全国信息检索与内容安全学术会议论文集(NCIRCS 2007),苏州, 2007.
[11] 张瑾,王小磊,许洪波. 自动文摘评价方法综述[J]. 中文信息学报, 2008,22(3):81-88.
[12] 王灿辉.Web环境下的新闻专题构建和话题挖掘研究[D],清华大学博士学位论文, 2008.
[13] 文利娟.Web社区中话题的发现与排序[D],武汉理工大学硕士学位论文, 2009.
[14] 贾自艳,何清,张海俊,等. 一种基于动态进化模型的时间检测和追踪算法[J],计算机研究与发展, 2004,41(7):1273-1280.
