石佛寺流域洪水分类预报研究
2014-02-24范雪芬
范雪芬
(辽宁省石佛寺水库管理局,辽宁 沈阳 110166)
1 流域介绍
石佛寺水库位于辽河干流的中下游,是辽河干流唯一的控制性水利工程,辽宁省内流域面积16 161万km2,水库总库容1.85亿m3。石佛寺水库通过与辽河干流左侧三大支流上的南城子、清河、柴河、榛子岭4座水库联合调控,将石佛寺水库以下辽河干流的防洪标准从30年一遇提高到100年一遇[1]。
根据石佛寺流域特点和水利工程分布情况,将石佛寺流域划分为4个子区间,即松树子区间、开原子区间、铁岭子区间和石佛寺子区间[2,3]。石佛寺水库洪水预报方案中,产汇流预报采用大伙房模型[4],洪水演算采用错时段法。
2 分类洪水预报模型
2.1 模型建立
采用模糊聚类ISODATA迭代模型对洪水进行聚类,在文献[5]中详细介绍了ISODATA模型的推导过程,将历史洪水划分为大洪水、中等洪水和小洪水3类,以洪峰和洪量作为模糊聚类的特征指标,指标权重向量W=(0.5,0.5)。由于无法提前获取洪峰和洪量两个指标,使得基于洪峰和洪量指标的模糊聚类方法应用受到了极大限制。使用模糊推理的方法,来提前判断洪水所属类型,以便快速准确的选取相应模型参数。
基于综合信息的模糊推理模式是建立在以成因分析、统计分析、经验相关等方法的基础上,利用历史信息归纳生成推理模式语句,再根据面临时刻信息与历史信息相匹配,得到相应的结果作为结论。模糊推理要求具有代表性好,且足够多的历史信息作为输入因子用来生成规则。
根据多规则、多输入、单输出的模型求解思路,多重模糊推理形式为:
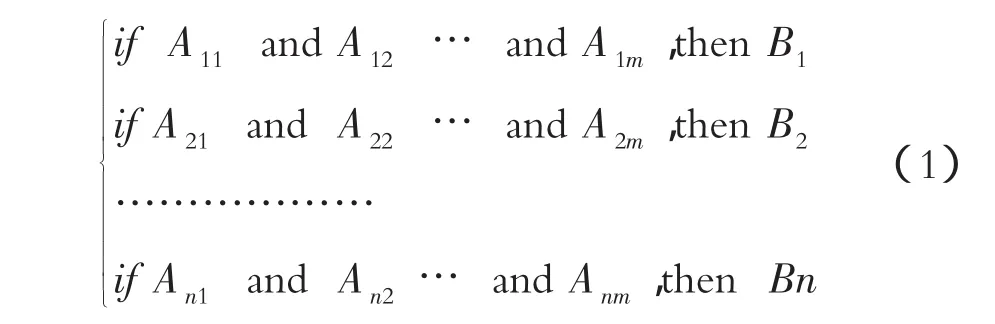
式中:A为推理因子;B为推理结果;m为推理因子个数;n为规则个数。
洪水类型识别模糊推理模型,分为离线阶段和在线阶段两部分,洪水分类预报流程如图1所示。离线阶段是根据历史资料生成推理规则和将历史洪水进行聚类,在线阶段是利用面临时刻信息进行模糊推理,判断实时洪水类型。
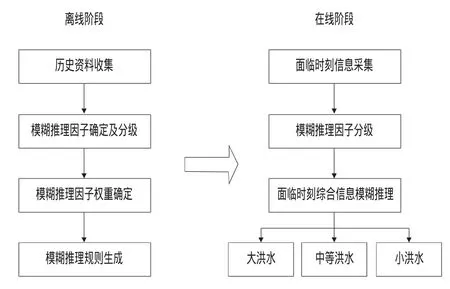
图1 基于模糊推理的洪水分类预报模型流程图
2.2 模型求解
由于松树子单元水文资料好,人类活动少,且下垫面条件稳定,适合进行模糊推理研究。对松树子单元1954-2010年,47场历史洪水作为研究资料进行分析,选择前期土壤含水量(WM0)、降雨强度(i)、起始流量(Q0)、累计降雨量(P),4个因子作为模型的输入条件。
具体的计算过程是,将四个因子分级,如表1所示。将历史洪水的特征指标转化为相应的级别作为样本,而获取实时洪水的特征指标后,将特征指标转化为相应的级别,与样本洪水中各因子的级别相比较,认为级别最相近的为同一类洪水,采用同一组预报模型参数。
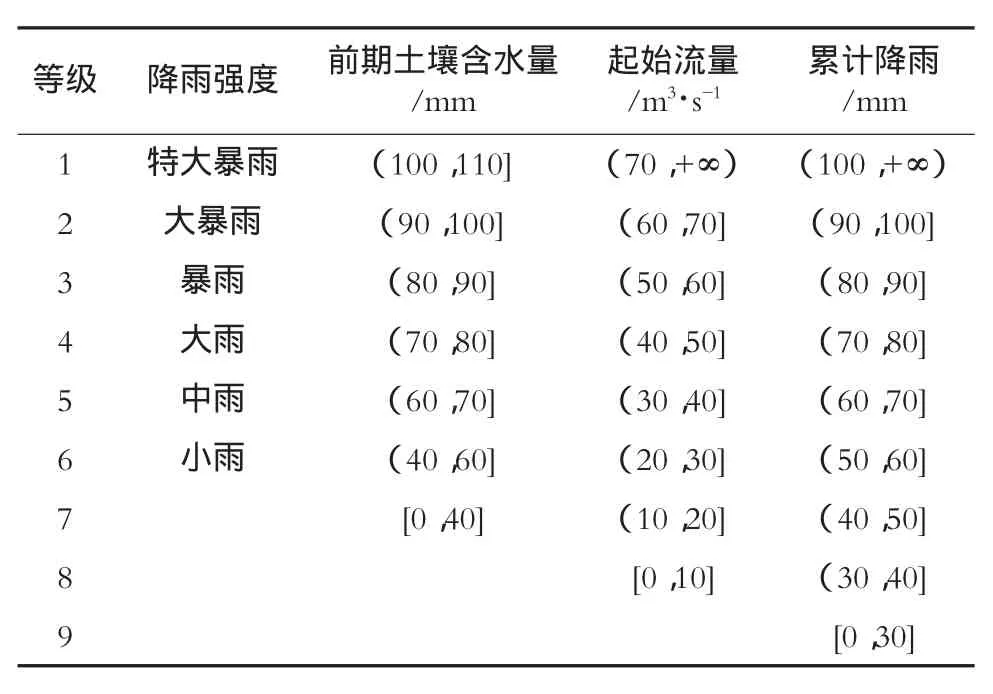
表1 模糊推理因子分级
将历史洪水划分为率定期和检验期,将率定期和检验期的分类预报结果和不分类预报结果列入表2和表3中。经过对比分析可以看出,分类预报方案较原方案相比,模拟精度和合格率都有所提高,预报误差减小[6]。用模糊聚类方法能够根据特征指标准确的将历史场次洪水进行聚类,并根据聚类结果对模型参数进行分类优选,将不同类型的参数应用于洪水预报中,模拟精度得到了明显的提高。

表2 松树子单元率定期洪水预报结果比较

表3 松树子单元检验期洪水预报结果比较
3 结论
为了提高石佛寺流域洪水预报精度,建立了基于综合信息的模糊推理模式洪水分类预报模型,并以松树子单元为例进行研究。采用洪量和洪峰作为指标,应用模糊聚类ISODATA模型将历史场次洪水进行聚类,进行不同类型洪水的模型参数优选。由于实时洪水预报中无法提前获取洪峰、洪量指标,故选择前期土壤含水量、降雨强度、起始流量、累计降雨量等,4个因子作为模糊推理的输入条件,判断该场洪水所属的洪水类型。实际结果表明,洪峰和洪量指标与前期土壤含水量、降雨强度、起始流量和累计降雨量等,4个因子存在良好的相关关系,并且分类洪水预报可以有效提高洪水预报精度。
[1]梁文章,柴晓利,曹炜伦.石佛寺水库2010720暴雨洪水分析[J].东北水利水电,2011,624(3)∶49-50.
[2]王猛,彭勇,梁国华.大伙房模型在石佛寺流域洪水预报方案中的应用[J].南水北调与水利科技,2012,10(2)∶15-19.
[3]王猛.石佛寺水库洪水预报及其实时修正方法研究[D].大连理工大学,2012.
[4]大连理工大学,国家防汛抗旱总指挥部办公室.水库防洪预报方法与应用[M].北京∶中国水利水电出版社.
[5]陈守煜.工程模糊集理论与应用[M].北京∶国防工业出版社,1998.
[6]中华人民共和国水利部.水文情报预报规范(SL-2000)[S].北京,2000.
