一种具有主次标签的多标签文本分类方法
2014-02-24北京理工大学计算机学院北京100081
李 晓(北京理工大学计算机学院,北京,100081)
一种具有主次标签的多标签文本分类方法
李 晓
(北京理工大学计算机学院,北京,100081)
在自然语言文本分类处理领域中,各种主流的多标签分类方法都只能使文本具有多个标签类别,但并不能识别哪个标签对使用者来说最重要,哪些标签次重要。本文以文本信息为研究对象,通过对几种主流多标签分类算法原理的研究分析,提出了能识别主、次标签的多标签文本分类方法-具有主次标签的多标签分类方法(Multi-Labels Text Classifier with Primary and Secondary Labels:MLTCPSL)。
文本分类;主、次标签;MLTCPSL
0 引言
多标签文本分类问题的研究对海量文本信息迅速分流,协助信息用户检索并准确定位所需信息,解决信息杂乱等问题都有着十分重要的意义,但现有的多标签分类方法虽然把信息分到了多个类别中,却无法识别那个标签对用户来说是最重要的,那些是次重要的。例如:一篇关于中国和美国篮球赛的文章,可以分到中国和美国两个类别里,如果这篇文章重点谈的是中国队的训练和备战,那它的主类别就是中国,次类别是美国,如果用户查询中国这个关键词就可以显示这篇文章,如果用户查询美国这个关键词就可以把这篇文章放到检索结果靠后的位置,因为它只是次要谈到了美国。所以,研究能识别主、次标签的多标签分类方法,对提高用户使用效率有着十分重要的意义。
1 识别主、次标签分类方法的问题分析
本文所研究的对文本按不同类别进行分类,是根据文本内容涉及的国家或地域名称对文本添加地理标签的过程,之所以选择地理标签是因为地理标签界限比较明确,数据收集和整理比较方便。当然也可以选择其它标签进行分类,只要类别清楚,已知类别数据量充足即可。根据文本内容添加地理标签这一步骤实际上是以既定的地理标签为类别判断标准,研究文本与已知类别标签之间的多重归属关系,也就是说,其实质是一个多类多标签分类问题。但是与常见的多类多标签分类问题相比,它还具有以下特点:
(1)每个文本添加的多个标签有主次之分,且数量有别。主标签有且只有一个,次标签可有可无、数量不限。而在常规多类多标签分类问题中,标签之间并无区别。
(2)添加主次标签时使用的评价标准不一致。为更好地对文本进行处理,通常必须选定一个文本主类别,也就是说,添加主标签要准确;同时,该文本涉及信息面可能较广,所以还要保证文本处理的全面性,也就是说,添加次标签要全,尽量不要遗漏。因此,在区分主次标签时,不能象常规多类多标签分类问题采用查准率和查全率均衡的评价方法,而是需在区分主标签时以查准率为主,区分次标签时以查全率为主。
必须面对训练文本中类别不均衡问题。由于标签数目很多,不同类别的样本数量可能存在量级上的差距,导致经训练构建的分类器无法准确反映各类别文本的分布情况,导致分类器容易被大类淹没而忽略小类。即使对主标签分类时,可以对训练文本集合进行调整,达到对主标签平衡的状态,但是也无法达到对每个次标签都平衡的状态。
文献研究结果表明,现有文本分类算法主要解决单标签文本分类问题,而多标签文本分类问题一般采用多分类器集成学习方法,通过将多标签文本分类问题转化为多个相互独立的单标签文本分类问题,然后综合各个单标签文本分类问题求解结果,形成最终的多标签分类结果。这种方式,往往没有考虑标签之间的主次关系,不能解决有主次区分的多标签文本分类问题。为此,本文借鉴多分类器集成学习方法,针对主次标签相对独立的特点,将在不同类别信息区分过程中具有主次标签的多标签分类问题,分解为以主标签为目标的多类单标签分类和以次标签为目标的多类多标签分类两个问题。
2 具有主次标签的多标签分类方法
文献研究结果表明,针对文本分类问题提出的文本表示模型和分类算法种类繁多、各有特点,与文本分类的性能息息相关。但是,单个文本表示模型或分类算法往往在解决某类特定的问题时表现出相对更佳的性能,而在解决其他问题上的表现则差强人意。因此,直接采用已有的分类算法或者全新设计一个分类方案,以期解决具有主次标签的多标签分类问题,是不现实的。为此,针对主、次标签相对独立的特点,将在不同类别信息区分过程中具有主次标签的多标签分类问题,分解为以主标签为目标的多类单标签分类和以次标签为目标的多类多标签分类两个问题,从而提出了具有主次标签的多标签文本分类方法(Multi-Labels Text Classifier with Primary and Secondary Labels:MLTCPSL)。
2.1 主标签分类方法
对主标签分类器的选择,实质上是以精度为指标,选择能够在实际数据环境中表现最优的分类器。
本文首先选择Naïve Bayesian(朴素贝叶斯)、LR(逻辑斯特回归)、SVM(支持向量机)和Sparse Bayesian(稀疏贝叶斯)等具有代表性的分类器进行分类精度实验,实验结果如表1 所示。
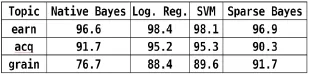
表1 各种分类器在Reuters-21578上的实验结果
从表中可以看出LR和SVM性能相当,都比Naïve Bayesian、Sparse Bayesian好。
用户的数据环境是一个典型的类别数据分布不平衡环境,不同的类别间数据量差异较大。本文进一步对比LR和SVM对不平衡类别分布的健壮性,研究发现SVM对实例分布的健壮性要好于LR。
因此,本文确定线性SVM作为MLTCPSL主标签分类器的训练算法。
2.2 次标签分类方法
MLTCPSL中的次标签分类器设计问题,实质上是一个以macro-F1作为性能指标的标准多标签分类问题。
本文选择问题转换法的二值法来解决多标签分类问题:为每个标签训练一个两分类器(正类为该标签,反类为非该标签),这样如果有n个标签,就构造n个分类器;分类时,如果相应的分类器输出为正值就把分类器对应的标签输出。
每个标签是一个两分类问题,由于要考虑的标签很多(十几个),这就使得对应于每一个分类器,正类数据由该标签对应的数据构成,而反类数据则是由其它所有不属于这个标签的数据构成,正反类数据之间严重不平衡。解决不平衡类别的方法很多,调整决策门限是比较简单和有效的一种方法。
本文选择了Pcut、Scut和Rcut等三种决策门限选取方法进行了研究,确定Scut在校验集合上为每个标签分别选择各自的决策门限。
在校验集上优化决策门限需要确定优化准则,本文选择F1作为评估指标。F1有macro-和micro-两种计算方法,其中稀少类的性能对macro-F1有较大影响,通过优化macro-F1可以使各类的性能相差不大,分类时就不会出现有些类性能很好,有些类性能很差的现象;另外有文献指出,即使目标是优化macro-F1,也能保证得到较小的micro-F1,反之则不一定,因此本文选择macro-F1作为准则。
2.3 MLTCPSL方法
表2 以3个文档3个标签为例说明了本文构造的分类器,对主标签使用一个多类别的分类器。在MLTCPSL中是单标签多类别的SVM分类器。实际上最基本的SVM是两分类器,该多分类器实际是使用one-against-rest策略从两分类器得到。、、是针对3个标签采用二值方法分别建立的三个两分类器,用macro-F1最大化作为训练指标。
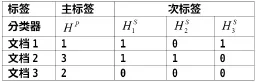
表2 具有主次标签的多标签文本分类算法(MLTCPSL)示例
算法3-1给出了本文提出的MLTCPSL算法流程,分别处理主标签和次标签,训练出一个多类别的主标签分类器和n个次标签分类器。主标签分类器的训练以精度最大化为指标,而多个次标签分类器以macro-F1为优化目标,选择在校验集合上使macro-F1最大的门限作为决策门限。

3 结论
本文提出了能识别主、次标签的多标签文本分类算法(MLTCPSL),解决了在多标签分类方法中识别主要标签和次要标签的问题。
作者简介
[1] D.D.Lewis.Naive Bayes at forty:the independence assumption in information retrieval[C].The 10th European Conference on Machine Leaming, Heidelberg,Germany,1998.
[2] N.Kamal,L.John,M.Andrew.Using maximum entropy for text classification [C].Proceedings of the IJCAI-99,Workshop on Information Filtering,Stokholm, Sweden,1999.
[3] Y.Yang.An evaluation of statistical approaches to text categorization[J].Joumal of Information Retrieval,1999,l(1/2):69-90.
[4] T.Joachims.Text categorization with support vector machine:learning with many relevant features[C]. Proeeedings of the 10th European Conference on Machine Leaming,1998:137-142.
李晓,男,民族:汉,出生年月日:1982年2月4日,籍贯(省市):湖北随州,最后学历:硕士研究生,毕业院校:北京理工大学,专业:计算机科学与技术,职称(职务):在读研究生

表3.2 基于三个函数的链路预测算法准确性比较
4 结论
利用WCN,WAA,WRA三个预测算法,通过三个节点活跃度函数分别在三个算法中的验证分析,结果表明,在考虑节点活跃度这一属性时,链路预测的准确度都有明显的提高,这说明将节点活跃度融合到算法中是必要可行的。
参考文献
[1] 刘宏鲲,吕琳媛,周涛.利用链路预测推断网络演化机制.中国科学, 2011, 41(7):816-823.
[2] Yu H,Braun P,Yildirim M A,et al.High-quality binary protein interaction map of the yeast interactome network.Science,2008,322(5898):104-110.
[3] Stumpfm P H,Thornet T,Silva E de,et al.Estimating the size of the human interactome.Proc Natl Sci Acad USA,2008,105(19):6959-6964.
黄勇(198-),男,工程师,研究方向为信息安全,光纤网络等。
A major label multi label text categorization method
Li Xiao
(School of Computer Technology ,Beijing Institute of Technology,Beijing,100081)
This paper take the text as the object of study,through the research of several mainstream multi label classification algorithm analysis, put forward to the identification of the main,secondary label multi label text classification methods with primary and secondary label multi label classification method (Multi-Labels Text Classifier with Primary and Secondary Labels:MLTCPSL).
text classification;principal;time tag;MLTCPSL
王烨(1981-,女(满族),博士研究生,研究方向为赛博空间,社交网络,云计算等;
朱正祥(1974-),男,博士后,研究方向为主要研究领域为数据挖掘、系统科学等;
刘增良(1958-),男,博士生导师,博士,研究方向为信息安全,网络战,人工智能等;
宋文超(1981-),男,中级测评师,研究方向为信息安全、等级保护、云计算等;
