基于REMOS 的远距离语音识别模型补偿方法
2014-02-23李劲松孙明伟
杨 勇,李劲松,孙明伟
(重庆邮电大学计算机科学与技术研究所,重庆 400065)
0 引言
封闭环境中的远距离语音识别[1],测试语音容易受到混响效果的影响。混响会导致语音幅值变化、相位延时和共振峰偏移。此外,混响还会产生其他新的谱峰,拖尾的混响声部分还会造成音节的相互掩蔽。通常现有语音识别系统都是在无混响或弱混响环境中采用(准)纯净语音训练得到识别模型所需的参数[2]。在一个真实的封闭环境中使用该识别模型时,由于训练环境和测试环境发生失配,导致语音训练集与测试集不匹配,从而系统识别率会发生急剧下降。
为了消除混响的影响,一般来说可以从信号域、特征域和模型域3个方面来进行处理[2]。比如语音增强、麦克风阵列属于信号域方法,特征规整属于特征域方法,模型补偿属于模型域方法。信号域方法可以获得较好的语音处理效果,但其原理复杂、传声器体积庞大且昂贵[3];特征规整方法应用在语音的前端处理,处理效果不如信号域理想,且过于复杂的处理算法影响系统的实时性[4];训练带有混响的语音数据[5],以及线性和非线性的模型补偿[6],是最近几年来的一些模型补偿新方法,但往往这些方法都没有考虑到环境因素,即缺乏环境适应性。
混响建模(reverberation modeling for speech recognition,REMOS)[7]是 Armin Sehr等提出的一种在模型域解混响的新方法,该方法实质是在模型域模拟混响信号的产生特点,根据实际语音分帧长度,求出房间冲击响应(room impulse response,RIR)[7]的帧数目,建立混响模型(reverberation model,RM),利用混响模型参数在模型域对每一帧清晰语音特征向量补偿相同帧数目的混响补偿值。Armin Sehr完成了在mel频域[7]、对数域补偿以及相应的性能分析,实验证明REMOS能有效地提高语音识别的混响鲁棒性[7]。之后又在REMOS基础上提出按帧补偿的隐马尔可夫模型 (hidden Markov model,HMM)自适应方法(REMOS-based frame-wise model adaptation,REMOS-FMA)[8],该方法将 REMOS 理论应用到HMM自适应方法中,使得REMOS有了实际应用价值。但该方法在模型域补偿阶段对HMM参数进行的混响补偿是一种固定补偿。在实际语音识别应用中,声源位置是未知的,且同一房间中不同区域的局部RM差异很大,若在不同区域仍然使用同一个RM,将会导致补偿不精确。此外,若声源位置发生变动,但在模型域的混响补偿没有做相应的变化,也会造成补偿变得不精确,从而导致识别率不能得到有效提高。
针对这一问题,本文应用最大后验概率思想,结合RIR序列的特征,提出一种位置划分的模型自适应方法(location divided model adaptation,LDMA)。位置的划分实际是一种对RIR优化集的聚类过程,该方法首先建立与RIR序列相绑定的混响模型,求出RIR序列的优化集,通过 K-means聚类算法[9]对RIR优化集进行聚类,从而达到对绑定混响模型的聚类。对所属相同类的混响模型进行合并处理,再把合并后的混响模型载入Viterbi算法[10]中,对清晰语音的HMM模型进行按帧的补偿。最后采用后验概率方法挑选最佳补偿,使得模型域的混响补偿能最接近精确补偿。
1 混响模型概念
如果忽略加性干扰,麦克风在混响环境中接受的信号x(n)可以描述为清晰语音信号与房间冲激响应h(n)在时域的卷积

(2)式中:smel,hmel和 xmel分别为清晰语音、RIR、混响语音的mel域fft数值向量;k为语音帧标识;⊙表示是元素对应项相乘;m为混响帧标识,代表了一定的帧延时;M为混响帧数目。RIR序列可由声学测量仪器得到,也可用经典镜像方法(image method)[11]计算得到。M可以通过(3)式计算得到,L为RIR序列长度,W为语音加窗长度,d为语音帧两两重叠长度。

混响模型反映了在特定房间、已知麦克风位置以及声源位置下产生的RIR集的统计概率特性。RM是一个l×m的二维矩阵,每一行代表一个mel信道l,每一列代表一个确定的帧延时,每一个矩阵元素是RIR序列的mel域特征的独立同分布高斯随机过程。简单的说,不同的矩阵元素之间具有统计独立性[7]。

2 基于混响模型的模型域补偿方法
前文已经探讨了混响问题对语音时频域的影响,以及混响模型的基本概念。REMOS-FMA是一种利用混响模型在模型域进行补偿的方法。它利用事先建立好的RM,在Viterbi解码时期,对HMM模型参数进行补偿,并且考虑前面语音帧对当前语音特征造成的延时影响。该方法实质是在模型域模拟混响语音的形成特点,在当前要识别的语音模型参数上叠加混响帧的特征参数,来达到减小训练集与测试集之间差异的目的。但该方法仍然存在一定的弊端:①该方法存在补偿不够精确的问题,用RM中提供的均值向量与清晰语音的HMM参数做点乘运算,但RM是RIR集在mel频域向量转换到mel特征域向量得到的,由频域转换到特征域需要经过滤波处理,如果再以特征域与清晰语音的HMM参数做点乘运算,将会使补偿不够精确;②该方法在补偿时没有针对性,缺乏自适应性,处在同一房间的不同位置,RIR序列有很大的差异,FMA在利用RM进行补偿时,并没有考虑到这种差异性,而是用多个特定位置求得的RM进行特定补偿。如果声源位置发生变化,或测试语音位置不在训练RM时的几个特定位置上,但仍然使用同一个RM参数去补偿清晰HMM参数时,这样补偿显然是不合适的。
针对这2个问题,本文提出了一种新的基于位置划分的模型自适应方法。对第1个问题,本文引入了辅助矩阵来改进混响模型;对第2个问题,本文提出了基于K-means的位置划分以及最大后验概率的思想来解决该问题。
3 基于位置划分的模型自适应方法
3.1 引入辅助矩阵修正混响模型
在固定位置进行模型域补偿。所谓固定位置,即混响语音x(n)由s(n)和h(n)在时域卷积直接得到,而h(n)在由镜像方法计算时,需要提供确定的位置参数。语音特征提取过程中,由频域转换到特征域一般来说有多种方法,例如文献[11]中提到了对每个mel滤波器内的频域值进行求和运算,剑桥大学的开源语音识别引擎HTK[12]的实现方式则是先对每个mel滤波器内相邻的2个频域值求欧式距离,再对所有欧式距离值进行求和运算。相比之下,HTK的这种计算方式具有更好的鲁棒性[12]。最后在每个语音帧中求得l个(假设取l个mel滤波器组)mel频率特征。由频域转换到mel特征域以后,混响补偿可表示为

(4)式中:Smel,Hmel和 X'mel分别为清晰语音、RIR、混响语音的mel域特征向量;X'mel为Xmel的估计值;l为mel信道标识。文献[7]中证明采用Monte-Carlo方法计算得到的Hmel比直接通过RIR序列计算mel域特征向量更精确,Monte-Carlo方法如(5)式所示

语音从频域转变到特征域,将RIR的mel域特征向量与清晰语音的mel域特征向量分开计算,会与真实的混响语音的mel域特征向量Xmel存在误差。所以我们引入辅助矩阵

(6)式中:a(l)为l×l的辅助矩阵,如(7)式所示,可通过求广义逆方法确定该矩阵
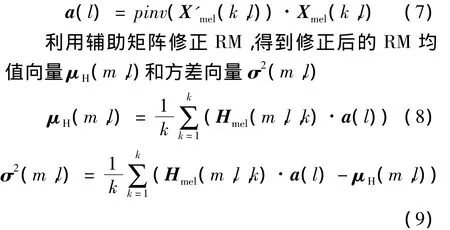
3.2 位置划分
上文讨论了如何在固定位置获辅助矩阵来修正RM的问题,也指出了FMA方法在补偿端不具有位置自适应的问题。若想要达到位置自适应的目的,可以通过在不同位置获得的RM对HMM模型进行有区别的补偿,通过最大后验概率的思想选取最佳的补偿。但如果在一个房间训练了上千个随机位置所对应的RM,则在每次补偿都需要进行上千次试探性补偿,这对语音识别的实时性来讲是无法接受的。由于相邻位置的RIR序列有着极为相似的特征[7],所以如果能对位置进行适当的划分,利用一类位置的RM代替固定位置的RM,并在补偿精度与时间复杂度之间做出权衡,对识别效率来讲是有益的。
由于RM矩阵很难找出明显聚类特征,对基于位置的RM矩阵进行聚类是困难的,考虑到每一个RM矩阵都是在一个特定位置计算得到,而不同位置有对应的RIR序列。所以若将特定位置的RIR序列与对应的RM矩阵绑定,求出RIR优化集,再对RIR优化集的特征进行聚类,即可得到基于位置的RM矩阵的聚类结果,聚类步骤如图1所示。

图1 K-means聚类流程图Fig.1 K-means clustering flow chart
首先对同一房间、固定麦克风位置,利用镜像法生成RIR集,用3.1中的方法计算得到对应位置的修正后的RM,聚类前首先对N个RIR进行分帧处理,求出优化序列,帧大小与HTK中语音特征提取帧大小一致,假设为M点每帧,处理过程如下。

RIROS(RIR optimized sequences)为 RIR优化序列,i为RIR优化序列的维数,j为帧标识,M可由(3)式计算获得,最后得到的RIR优化序列实际是RIR序列的分帧加权特征。由于每一个RIR序列都绑定有一个RM矩阵,当多个RIR优化集通过K-means聚为一类时,对应的均值补偿矩阵与方差补偿矩阵也需要做合并处理。假设将相同环境和相同麦克风位置条件下得到的RIR优化集聚为c个类,它的物理意义就是将位置划分成了c个部分。将每个部分中的RM进行合并,合并过程如式(10)和式(11)所示,cT为第i类中RIR优化序列的数目,下标i为类标识(1≤i≤n)。可得第i个RM类的补偿均值向量与方差向量

3.3 Viterbi算法嵌入
将这c个类的RM均值向量、与方差向量代入Viterbi解码网络中,具体方法如下。
由清晰语音训练得到的HMM输出概率均值向量位于MFCC(Mel frequency cepstrum coefficient)倒谱域中,需要转换到mel频域才能进行模型域的补偿。MFCC域与mel域的相互转换计算式为

通过Viterbi算法在当前状态读出每一个模型的输出均值向量与方差向量,用3.2中实施聚类修正后的RM参数做出按帧的补偿,从直达语音帧和混响语音帧两方面模拟输入语音的混响形成,具体方法如下。
1 )首先需要计算直达语音的模型补偿,直达语音即在空间中未经过任何反射直接从声源传入麦克风的语音帧。对于直达语音的倒谱特征向量来说,均值向量等同于清晰语音的均值向量加上RM第0列的均值向量

(13)式中:k为帧标识;r为类标识。同样,方差向量等同于清晰语音的方差向量加上RM第0列的方差向量
2 )然后是混响语音帧的补偿,需要在当前帧的清晰语音的均值向量上叠加前面M个帧的混响均值向量。由于方差向量对于混响语音帧的影响很小,且较难估算,因此,忽略混响帧的方差补偿。
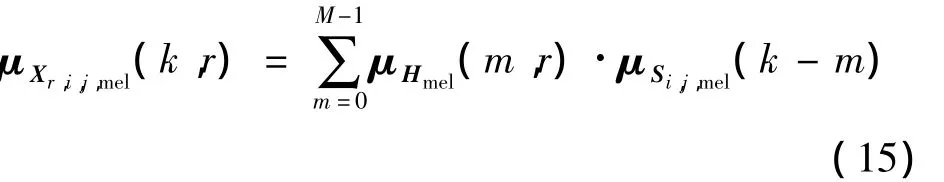
3 )补偿后的当前帧均值向量为直达语音帧均值向量加上混响语音帧的均值向量
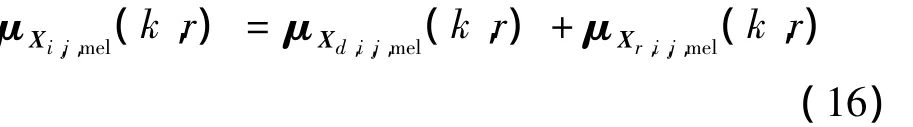
由于忽略了混响语音帧的方差向量值,所以补偿后的当前帧方差向量约等于直达帧的方差向量值。

(18)式中,bij为状态的输出概率。利用最大后验概率的思想,从r个补偿结果中选择出最佳补偿结果

(19)式中,aij为HMM的状态转移概率。
4 实验分析
本节通过对RIR优化集聚类结果进行分析,并与几种传统的基于HMM的语音识别模型域补偿方法进行比较,从多个方面证明了LDMA在语音识别中处理带混响的语音数据是有效的。实验环境:2.3 GHz双核CPU,2 GByte内存,操作系统为 windows xp sp3,HTK版本号为3.4.1,编程工具为vs2010和matlab R2010a。实验中采用an4语料库作为实验语料来源。an4语料库是卡内基梅隆大学(Carnegie Mellon University,CMU)录制的无任何杂音的清晰语音库,由an4_clstk训练库和an4test_clstk测试库组成。其中an4_clstk训练库由74个不同人录制的949个语音文件,an4test_clstk测试库由10个不同人录制的130个语音文件,训练库和测试库由完全不同的人录制。利用VS2010对HTK识别引擎源代码进行修改,重新编译生成动态链接库,识别时加载保存的RM文件,实现LDMA方法。
4.1 RIR优化集的聚类实验
聚类实验的设置,其目的是验证和测试对RIR优化集聚类,从而实现对封闭环境不同区域进行有区别补偿的可行性。在实验过程中,首先定义房间几何尺寸、声源位置以及随机的麦克风坐标参数。通过镜像算法产生5 000组模拟的RIR序列,然后通过优化RIR集得到RIR优化集,最后利用K-means聚类聚类算法对RIR优化集进行聚类,得到聚类结果。
图2是在长宽高分别为10 m,8 m,3 m的房间进行10个聚类的示意图。每一幅图中都包含5 000个随机点,每一点代表一个由随机位置产生的RIR序列计算得来的RIR优化向量。

图2 利用K-means将RIR优化集聚为10类效果图Fig.2 Implement K-means algorithm on RIR optimized sets in 10 classes
图2展示了对RIR优化集实施K-means聚类后,将房间的声学空间分为多个类的情况。图2中的3幅图分别为3组不同麦克风坐标情况下的聚类图,从左至右麦克风的三维坐标依次为(6 m,6 m,1.6 m),(5m,4m,1.6m)和(0m,0m,1.6m)。图2中虚线为类间的分割线,不同的声学空间呈现出不同的聚类形状,聚类效果明显。说明对处于每一个局部声学空间中的语音进行有针对性的模型补偿是可行的。
4.2 不同模型域补偿方法的对比实验
本节把LDMA与几种主流的模型域去混响方法进行了对比。其中,混响HMM方法是指将清晰语音模型用混响语音模型来代替,即语音训练集加入了混响效果;HMM-MLLR[13]是一种典型的非线性模型补偿方法,该方法从非清晰语音中得到的一些经验数据,通过一组线性回归变换函数,对清晰语音高斯分量的均值和方差进行变换,使其更好地拟合非清晰语音。所有实验过程都采用相同的训练方法,最终的HMM均为状态数为5的三音素模型,输出概率模型为单高斯概率密度函数。为更好地验证本方法在固定位置声源与随机位置声源2种情况下,采用局部混响模型比采用全局混响模型进行补偿的精度更高,设置了固定位置声源与随机位置声源的对比试验。在2组试验中,R1,R2,R3分别为作者所在研究所的实验室、会议室和办公室,3个房间的大小依次为 R1(10 m,8 m,3 m),R2(5 m,6 m,m)以及R3(3 m,3 m,3 m),且3个房间中LDMA 的聚类数n都统一为20。
在固位置位置声源的对比试验中,设置麦克风三维坐标为6m,6 m和1.5 m,声源坐标为4 m,5 m和1.5 m,在此位置上对清晰语音加入相应混响,实验结果如表1所示。

表1 在不同房间使用固定位置混响语音的实验结果Tab.1 Experimental results through implementing same locate reverberantion on test speech in different rooms
从表1中可以看到,“Clear”表示清晰的测试语音,可以看到清晰语音有较高的识别率,在对R1,R2和R3中的固定位置的混响语音进行测试时,由于混响程度随着房间空间的增大而增大,测试语音与清晰语音模型之间的差异性也就越大,所以在较大房间R1中识别率最低,而在小房间R3的识别率最高。此外,混响HMM由于环境未发生改变,即声源位置固定,所以能获得较为理想的识别效果。MLLR由于只考虑了环境的模拟问题,未考虑混响带来的语音帧叠加问题,因此MLLR对解决混响问题效果一般,更多的是用于解决说话人自适应。FMA与LDMA都是采用清晰语音训练得到的HMM模型,但FMA方法用全局的混响模型参数对清晰语音HMM模型进行补偿,性能低于利用局部混响模型参数进行补偿的LDMA。
在随机位置声源的实验中,麦克风三维坐标统一为6 m,6 m和1.5 m,其中混响语音A在距麦克风5~6 m的随机位置对清晰语音加混响得到,由于不同位置的混响特征序列是不同的,因此由随机位置得到的混响语音的混响程度是不同的,混响语音B和C采用同样的方法分别在距麦克风3~4 m和1~2 m录制得到,以测试在不同区域内采用随机位置声源的各方法的性能优劣。实验结果如表2所示。

表2 在不同房间使用随机位置混响语音的实验结果Tab.2 Experimental results through implementing random locate reverberantion on test speech in different rooms
从表2中可以看到,混响HMM在不同环境以及不同程度的混响语音中性能较为稳定,但混响HMM的实现方法表明了它是一种不灵活的方法,该方法在训练时采用混响语音进行训练,即训练集与测试集都需要在混响程度上保持一致性。这意味着在测试时如果改变了声源位置或者更换了房间,训练集与测试集将会出现不匹配,导致性能下降。因此,表2中的混响HMM平均性能会低于表1。同样,由于FMA在补偿阶段一直使用同一个混响模型进行补偿,而LDMA能在多个局部混响模型中进行有效地选择,所以LDMA带来的性能提升相对于固定位置声源时更明显。
综合2个试验,LDMA都有较好的性能,且在测试语音为随机位置声源时,LDMA的性能提升幅度更大,这是由于LDMA在识别阶段利用最大后验概率方法选出了最佳的混响补偿类,因此,在随机位置试验中得到的性能与固定位置时很接近。在R3中由于房间尺寸很小,房间中不同位置的声学空间差异会变得很小,这种情况下对声学空间进行聚类,类间差异也会减小,所以LDMA带来的性能提升是极其有限的。但是在R1这种相对较大的房间内,LDMA对性能的提升就很明显。
4.3 LDMA的实时性分析
实时性方面,对于固定位置声源的情况,由于LDMA不需要在多个局部混响模型中进行选择,因此对实时性并无影响。但对于随机位置声源的情况,由于LDMA在选择最佳混响模型时,需要分别加载多个混响模型,使得方法的实时性受到影响,其中混响模型的数量由聚类数决定。本实验通过在HTK源码中加入识别时起始时间点检测代码,从而计算出130个测试语音在不同聚类数下的平均识别时间。图3展示了聚类数与识别率之间的关系,图4展示了聚类数与识别单条语料时所耗时间之间的关系。

图3 不同房间中聚类数对识别率的影响Fig.3 Effect on recognition rate by clustering number in different rooms
从图3中可看到,当聚类数在2-6之间时,对识别率的提升较为明显,尤其在R1和R2这种相对较大的房间中,位置划分的作用比较明显。当聚类数大于10时,虽然识别率有所提升,但提升幅度较小。如图4所示,若在补偿时遍历所有的混响模型,LDMA识别单条语料的时间与聚类数n之间基本呈线性上升关系,n=0时,即不对RIR优化集进行聚类操作。
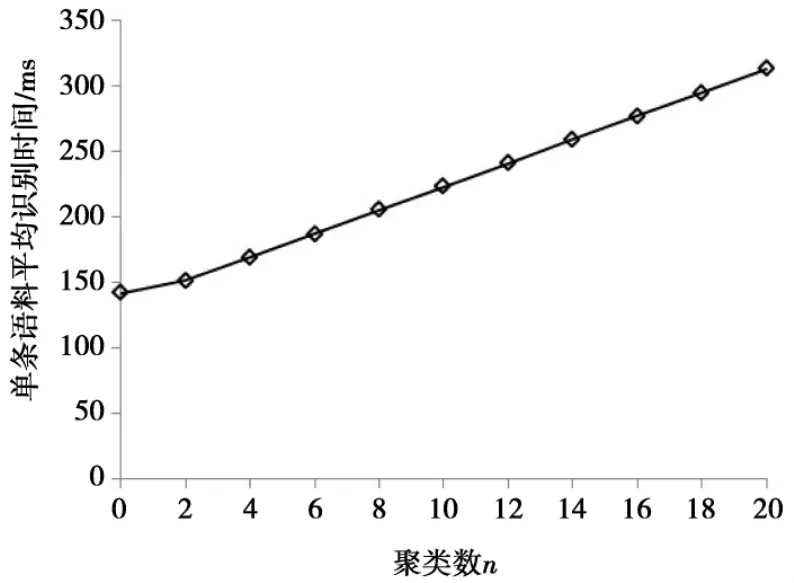
图4 LDMA实时性与聚类数关系图Fig.4 Relation between LDMA real-time and clustering number
综上所述,LDMA的聚类数选择在2-6之间,可以在保持较高实时性的情况下,有效提升混响环境中的识别率,尤其是在类似于R1和R2空间较大的房间中,分区域的进行补偿显得更为重要,性能提升更加明显。表3给出了多种识别方法的单条语料识别时间对比。

表3 LDMA与其他几种方法的实时性能对比Tab.3 Contrast of real-time performance between LDMA and several othermethods
由图3可以看到,混响HMM由于在解码阶段不需要对模型参数进行计算,所以实时性与普通HMM一样。MLLR采用了在线的非线性模型补偿函数,单条语料的识别时间有所上升。FMA方法的实时性能与LDMA在聚类数为0时相同。由于实时性能还与采样点数、特征向量维数、模型训练方法有关,通常单条语料的识别时间不超过500 ms就能满足实时性的需求[14],能看出LDMA方法可在较小的实时性能损耗情况下有效提升识别正确率。
另外,在试验中发现,靠近麦克风位置的混响模型被选中的概率远远大于其他位置的模型。这是由于实际应用当中,声源往往更多地出现在麦克风的周边位置,而很少出现在其他位置,例如房间的几个角落,所以在识别时舍弃部分混响模型将可以进一步提升方法的实时性。这可以作为未来的研究工作。
5 结论
本文利用最大后验概率的原理,基于对房间不同区域进行有区别补偿的思想,在按帧的HMM模型补偿的基础上,提出一种在封闭环境中新的模型补偿方法。实验结果表明,该方法能有效消除混响效果的影响,进一步提升远距离语音识别的精度。另外该方法可以方便地在开源语音识别工具包ATK(an application toolkit for HTK)[15]的底层库文件中实现,从而应用到语音识别的应用程序中。下一步要研究的工作就是在保持一定的识别精度的同时,通过保持一定的聚类数提升方法的实时性,可以在选择混响模型时有针对性的进行选择或者利用历史经验淘汰一些并不常用的混响模型等,这些方法都很有探讨价值。
[1]MATTHIASWölfel,MCDONOUGH John.Distant Speech Recognition[M].Germany:John Wiley& Sons Ltd.2009.
[2]GOMEZ R.Robust Speech Recognition Based on Dereverberation Parameter Optimization Using Acoustic Model Likelihood[J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(7):1708-1716.
[3]NOBUTAKA Ito,HIKARU Shimizu.Diffuse Noise Suppression sing Crystal-Shaped Microphone Arrays[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(7):2101-2110.
[4]张德会,陈光冶.复倒谱域语音信号去混响研究[J].声学技术,2009,28(1):39-44.
ZHANG Dehui,CHEN Guangye.Speech signal dereverberation with cepstral processing[J].Technical Acoustics,2009,28(1):39-44.
[5]SEHR A,HOFMANN C,MAASR.Multi-style training of hmms with stereo data for reverberation-robust speech recognition[C]//Hands-free Speech Communication and Microphone Arrays(HSCMA).Germany:IEEE Press,2011:196-200.
[6]吕勇,吴镇扬.基于最大似然多项式回归的鲁棒语音识别[J].声学学报,2010,35(1):88-96.
LV Yong,WU Zhenyang.Maximum likeli-hood polynomial regression for robust speech recognition[J].ACTA ACUSTICA,2010,35(1):88-96.
[7]SEHR A,MAAS R,KELLERMANN W.Reverberation model based decoding in the logmelspec domain for robust distant-talking speech recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(7):1676-1691.
[8]SEHR A,MAAS R,KELLERMANN W.Frame-wise hmm adaptation using state-dependent reverberation estimates[C]//International Conference on Acoustics,Speech,and Signal Processing(ICASSP).Germany:IEEE Press,2011:5484-5487.
[9]ALAVINIA S.Single channel speech/music segregation based on a novel K-means clustering schema[C]//Signal Processing and Information Technology(ISSPIT),Iran:IEEE Press,2011:567-572.
[10]BUERA L.Unsupervised Data-Driven Feature Vector
Normalization With Acoustic Model Adaptation for Robust Speech Recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(2):296-309.[11]廖启鹏,孔荣.基于最小相位分解的语音去混响[J].
通信技术,2011,44(6):78-82.
LIAO Qipeng,KONG Rong.Dereverberation based on Minimum Phase Decomposition[J].COMMUNICATIONS TECHNOLOGY,2011,44(6):78-82.
[12]YOUNG Steve,EVERMANN Gunnar,GALESMark,et
al.The HTK Book(for HTK Version 3.4)[M].UK:Cambridge University Engineering Department,2009.[13]KIM D,GALESM.Noisy Constrained Maximum-Likelihood Linear Regression for Noise-Robust Speech Recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(2):315-325.
[14]HUGGINS Daines.Pocket sphinx:A Free,Real-Time Continuous Speech Recognition System for Hand-Held Devices[C]//International Conference on Acoustics,Speech,and Signal Processing(ICASSP).USA:IEEE Press,2006:185-188.
[15]YOUNG Steve.ATK Manual(Version 1.6)[M].UK:Cambridge University Engineering Department,2007.
(编辑:田海江)
