基于自适应同源方差控制的法庭自动说话人识别
2014-02-21王华朋
王华朋, 杨 军, 吴 鸣, 许 勇
1.中国科学院噪声与振动重点实验室,北京100190
2.中国刑事警察学院刑事科学技术系,沈阳110854
法庭说话人识别或确认,即法庭语音比对,主要比对罪犯在犯罪过程中产生的语音样本和嫌疑人的语音样本,提取能反映说话人个体特征的语言特征和语音特征并加以识别或确认.随着法庭证据评估方法的发展,DNA率先采取了新的基于似然比的证据评估方法,以量化法庭证据对鉴定结论支持力度的大小.该方法逐渐在国际上获得了广泛的认同,被认为是在逻辑上和法律上都正确的法庭证据评估方法,也是符合法庭推理过程和证据解释的科学方法[1].
法庭说话人识别分为半自动识别和自动识别两种.在半自动识别方法里,通过提取到的语音特征,直接计算语音证据的似然比.这种方法需要人工挑选有价值的发音单元,然后提取其语音特征,耗费了大量的人力和时间[2-4].法庭自动说话人识别则是一种与文本无关的说话人识别技术,它通常是在普通说话人识别系统的基础上经过得分到似然比的转换,使识别得分具有明确的物理意义[5-6].它的优点是不需要大量的人工干预,并且可以处理鉴定人无法听懂的方言、俚语和不同语种的语音.但在普通的自动说话人识别中过度强调了得分和门限的作用[7],忽视了说话人得以识别的基础条件.虽然说话人语音受到情绪、生理状态、年龄和健康等状况的影响,同一人两次说相同语句的信号特征并不是完全一样的,但这种说话人自身的同源变化必须小于不同人之间的非同源变化,否则无法识别说话人.而且,每个说话人自身的同源变化都与其他人自身的同源变化不同,不能采用同一个标准进行判定.为此,本文提出了一种新的鲁棒似然比估计算法,即自适应同源方差控制算法.该算法充分挖掘嫌疑人自身得分分布的信息,将估计的同源分布的方差控制在同一录音说话人自身方差和不同人目标得分的方差之间,不但符合说话人识别的基本原理,而且显著提高了识别性能,更有利于证据力度的表达和量化.
1 法庭自动说话人识别方法
本文方法的流程图如图1所示.目标语音库包含来自多个相同说话人的语音比较对,非目标语音库包含来自不同人的语音比较对,测试语音为来源未知的语音比较对.背景模型-高斯混合模型(background model-Gaussian mixturemodel,BM-GMM)识别系统与通用背景模型-高斯混合模型(universal background model-Gaussian mixture model,UBM-GMM)系统类似,只是参考人群数据库人数较少,往往针对具体案件选择与罪犯年龄、生活环境相似的人群.在法庭调查中,嫌疑人自身的数据通常较少,其有限的数据通过BM-GMM识别系统后的得分也较少,其得分分布模型N(µS,σS)不能准确反映嫌疑人自身的同源变化特性.因此,本文采用(adapted within-source variance control,AWVC)算法融合N(µS,σS)与目标语音库得分分布模型N(µG,σG),得到了能更准确地反映当前嫌疑人同源变化特性的估计分布N(µA,σA).最后,测试语音得分的均值分别在同源分布模型和异源分布模型上计算似然值,得到量化的能反映证据对

图1 法庭自动说话人识别方法流程图Figur e 1 Flow chart of FASR method
鉴定结论支持力度的似然比值.
1.1 背景模型-高斯混合模型识别系统
本文采用的自动说话人识别系统与UBM-GMM系统类似,不同之处在于UBM-GMM系统采用的背景数据库人数非常多,一般包括多个信道和录音设备的数据库.考虑到一个案件的成本问题,BM-GMM识别系统选择与嫌疑人年龄、生活环境类似的50个说话人构成小型的背景数据库人群.通过背景数据库语音训练得到表示不同人特征分布的GMM,这个模型即为背景模型.罪犯的统计模型是通过自适应GMM算法从背景模型中计算获得的.自适应GMM算法的基本的思路是利用新的信息自动更新已训练完毕的背景模型的参数,得到某一个说话人的语音模型.该方法在个体说话人模型和背景模型之间提供了紧密的耦合,不仅具有比非耦合模型更好的识别性能,而且在训练数据不充足的条件下具有更高的鲁棒性,还具有快速计算识别得分的优势[8].在本文的BM-GMM系统中,采用单一的自适应系数来对所有的参数进行调整,即
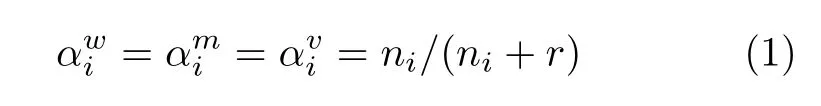
1.2 同源分布估计与异源分布模型
假设目标语音库得分分布和非目标语音库得分分布为单混合的GMM,可通过期望最大化算法训练得到其分布模型.经验表明,正态分布在识别中表现出良好的性能,于是本文的同源分布和异源分布均采用正态分布.LR的计算精确度受嫌疑人样本数量过小的影响很大,如果嫌疑人数据长度小,就不能从这些较少的得分中估计出该嫌疑人得分的准确分布.目前已有几种技术方法可以补偿数据缺乏的影响.文献[9]在计算框架中使用了近似假设的方法,即一个给定嫌疑人精确的同源分布模型可以由相同条件下不同人的目标得分来近似逼近.因此,同源分布实际上是由不同说话人的目标得分建模的.然而,经研究发现,即使在相同的条件下,不同人的目标得分也会出现不同的训练模型.因此,为了对同源分布模型进行精确估计,很多学者均采用与具体嫌疑人相关的得分信息.文献[5]提出的自适应算法如下:式中,µG和σG分别为目标得分的均值和方差,µS和σS分别为嫌疑人自身得分正态分布的均值和方差,µA和σA分别为自适应之后的同源分布的均值和方差,M为得分的数目,κ为相关因子.算法用嫌疑人的得分均值来调整不同人的目标得分均值,但这种调整与实际情况不符.由于在嫌疑人未被识别之前,不能确定嫌疑人和比较对象是否为同一个人,若采用嫌疑人的均值调节不同人目标得分的均值,必然会改变得分包含的说话人的原始信息,这不符合信息的原始分布.因此,本文主张不同人的目标得分的均值不必调整,同源得分分布的方差则使用本文提出的AWVC算法式中,α=σG/(σS+σG),µG和σG分别为目标得分的均值和方差,µS和σS分别为嫌疑人自身得分正态分布的均值和方差,µA和σA分别为自适应之后的同源分布的均值和方差.
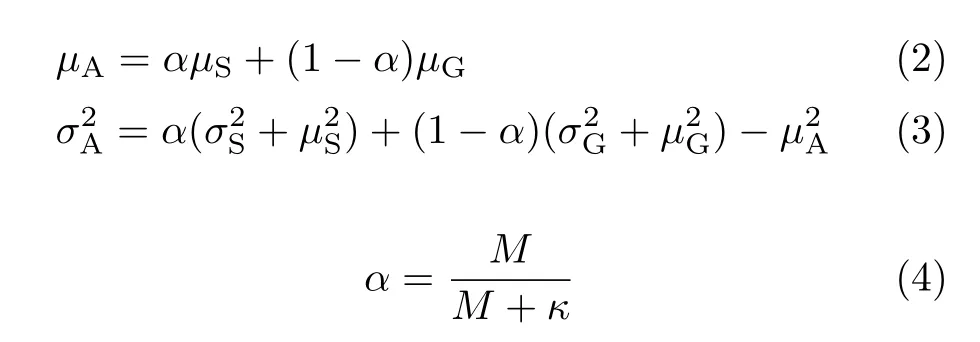
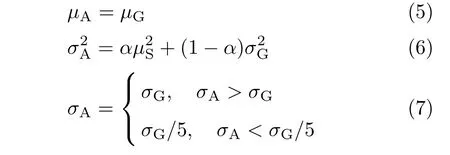
如果将N段同一个说话人的语音样本与比较对象的统计模型进行比较,那么识别系统的输出得分不会完全一致,这是因为这N段样本语音内容不同和语音自身的非平稳特性,使系统输出得分在某一均值处上下波动.这种波动反映了说话人自身的同源变化,具体大小反映在数据的方差上,但这个方差小于不同人的目标得分的方差.如果大于不同人的目标得分的方差,说明当前的测试语音得分不准确,或者语音受到传输信道、噪声或者其他干扰的影响,就应该进行相应的调整.常见情况如下:因为嫌疑人数据缺乏,所以嫌疑人分段数据得分方差通常比较小,不能反映嫌疑人自身的同源变化情况.本文根据式(6)对同源得分方差进行自适应的调整,既考虑了当前测试说话人自身得分的方差σS,又考虑了不同人目标得分的方差σG,进而在这两个方差之间进行自适应调整.嫌疑人自身的方差以权值α进行调整,不同说话人目标得分的方差以1-α进行调整.调整后的方差在嫌疑人自身的方差和不同人目标得分方差之间产生一个动态平衡,再对两方面的方差信息进行综合运用.
同样,同源得分分布的方差也不能太小,如果太小,则会在似然比的计算中出现奇异值,影响识别性能.因此,本文限制了同源得分分布的最小方差,即不能小于不同人目标得分方差的1/5,以式(7)对部分超出正常范围的方差进行调整.
文献[5]提出的嫌疑人自适应的得分到似然比的转换算法示意图见图2,本文提出的自适应同源方差控制算法示意图见图3.星号表示不同人说话人之间非目标得分的分布情况,虚线表示嫌疑人得分的分布情况,圆点表示不同人的目标得分的分布情况,实线是经过自适应动态方差控制后估计得到的同源得分分布,均用正态分布来表示.对比调整后实线发现,文献[5]算法自适应后的得分均值发生了移动,而本文算法自适应后的均值则保持在原目标得分的均值点上.
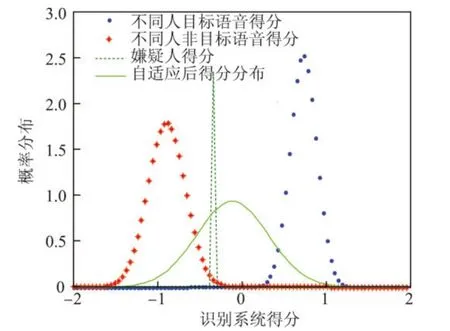
图2 文献[5]算法示意图Figure 2 Schematic plot of algorithm in references[5]
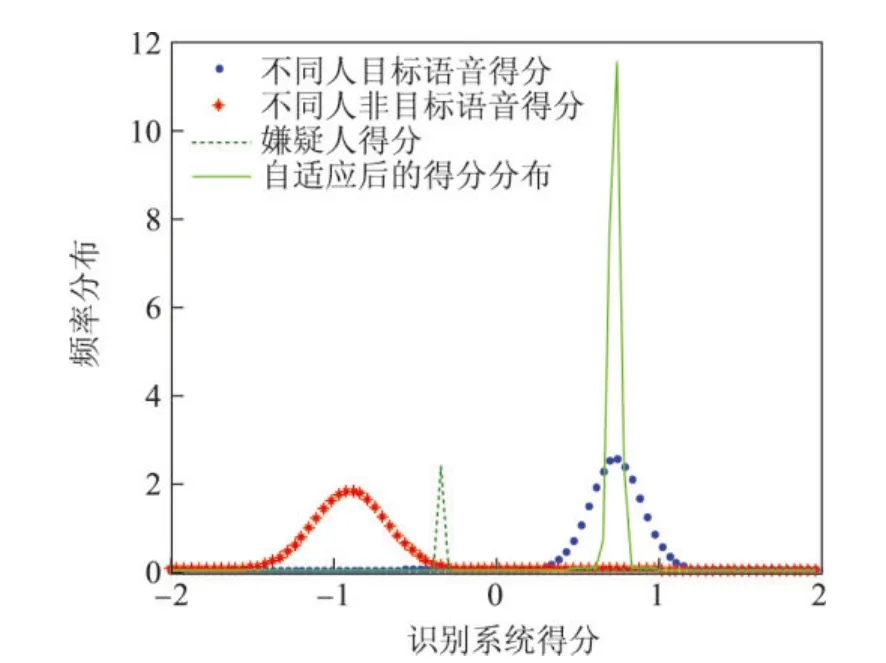
图3 自适应同源方差控制算法示意图Figure 3 Schematic plot of AWVC algorithm
1.3 得分到似然比的转换
在法庭说话人识别的研究中,似然比是最重要的研究内容,因为它可以量化证据对鉴定结论支持的力度,即提供证据强度.似然比可以表示成在一个给定的假设条件下(罪犯和嫌疑人为同一个人假设)观测到罪犯语音特征的概率与在完全相反的假设条件下(罪犯和嫌疑人为不同人假设)观测到罪犯语音特征概率的比值.似然比的分子,用来估计在罪犯样本和嫌疑人样本来自同一人的假设条件下,获得待比较样本间匹配程度的概率;似然比的分母,用来估计在罪犯样本和嫌疑人样本来自不同人的假设条件下,获得待比较样本间匹配程度的概率.因此,似然比反映了当前语音证据支持同一人的假设和支持不是同一人假设的相对强度,强度的大小反映在似然比值的大小上.似然比的值和1之间的相对距离,反映了证据强度的大小[10].在普通说话人识别系统中,识别门限可以根据需要进行调整;在法庭说话人识别中,门限1是固定的,具有实际的物理意义.似然比和1的大小关系表明,当前的语音证据支持是同一人的假设还是非同一人的假设,似然比并没有给出“是”或“否”的回答,只是量化了当前语音证据对鉴定结论支持的强度[11].如果用P表示概率,E表示证据,H0表示待比较的语音对来自同一说话人假设,H1表示待比较的语音对来自不同人的假设,那么似然比可写成
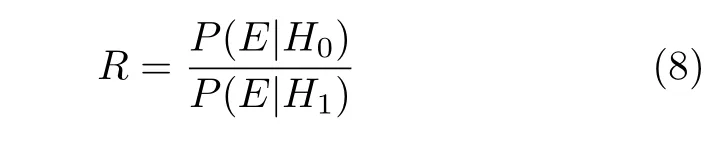
如果罪犯和嫌疑人的语音样本相似度越高,它们来自同一人的可能性越大,似然比的值也就越大.但是,这个结果还需要样本的典型性来平衡.贝叶斯理论明确指明,样本间的相似性和典型性对证据评估来说都是必不可少的.
识别得分到似然比值的转换方法可以分为两类.一类是纯校准的方法,它通过一个可逆的变换完成,输入得分的识别性能保持不变,既保留了原得分的鉴别性能,又保留了原识别系统得出的所有信息.纯校准类别的得分转换方法包括逻辑递归的方法和改进的s-cal逻辑递归方法(pool adjacent violators,PAV)算法[12]等.另一类是混合鉴别校正方法,它不仅提高了校正的结果,而且提高了系统的识别性能.因此,这种似然比计算方法并不局限于对得分的可逆转换,其目标是进一步提高输入得分的识别性能.混合鉴别校正类包括一般的似然模型方法、多层感知的神经网络方法、嫌疑人自适应的似然比计算方法等.本文提出的AWVC算法属于混合鉴别校正类,测试语音对得分均值分别在同源分布模型和异源分布模型上计算似然值,以表示测试语音特征相似特性的同源分布模型上的似然值为分子.以表示测试语音特征典型性的异源分布模型上的似然值为分母,即得到既考虑证据间相似性,又考虑到证据在人群中出现的典型性的似然比,进一步提高了原得分的识别性能.
1.4 法庭说话人识别系统性能可靠性评估
法庭自动说话人识别系统的识别性能一般使用与先验概率无关的对数似然比代价函数来评估,也是美国国家标准及技术署说话人识别技术评测中心使用的识别系统性能评估函数
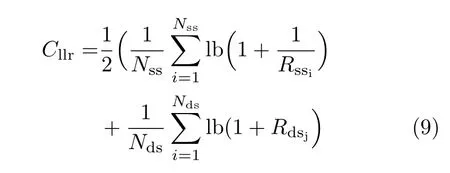
式中,Nss和Nds分别为相同说话人比较对和不同说话人比较对的数目,Rss和Rds是由相同说话人比较对和不同说话人比较对计算产生的似然比值.识别系统越可靠,Cllr的值就越低;相反,越不可靠的系统产生的Cllr值越高.
2 实验结果及讨论
2.1 实验设置
数据库是在实验室环境中录制的语音.使用传声器进行录制,原始采样频率为44 100 Hz,后经Cool Edit Pro 2.0降采样为8 kHz、16-bit的PCM文件,共包含90人的自由对话.数据库分2次录制,第1次录制的数据库命名为S1,第2次录制的数据库命名为S2,两次录制的时间间隔大约一星期,即数据库内每人在一星期左右的时间录音2次,谈话内容没有限制.为了建立更准确的说话人模型并降低计算量,数据库使用非语音段去除技术对语音文件中的静默段.随机选取50人的语料作为背景数据库,分别提取S1中的前30 s数据和S2中的前30 s数据,提取16阶的梅尔倒谱特征(Mel-frequency cepstral coefficient,MFCC)和16阶的MFCC为特征向量,维数为32,帧长为16 ms,加汉明窗,帧移位为8 ms,预加重系数为0.97.将这S1和S2的特征向量数据混合在一起作为训练背景模型,背景模型是64个混合的GMM.在特征向量与GMM的似然值计算中,选择得分最高的5个混合的平均值计算最后的似然值.参考说话人数据库人数为20,测试说话人数据库人数为20,这两个数据库中每个说话人均提取S1和S2中的前30 s数据混合,通过自适应GMM算法得到每个人的统计模型(64阶的GMM)作为罪犯的统计模型.测试语音的长度为2 min,根据测试结果可知30 s秒时长的语音具有最好的识别性能(在本文的实验条件下).因此,每30 s秒语音分成一段,共4段测试语音.这4段测试语音在BM-GMM中会得到4个嫌疑人自身的识别对数得分.
2.2 实验结果比较
在似然比结果的讨论中,似然比经常以10为底的对数值表示,因为在对数域,越大的正数对是同一人假设提供越大的支持力度,越大的负数对不同人假设提供越大的支持力度.图4是似然比值的Tippett图[13],左上的曲线表示不同说话人的对数10似然比大于等于x轴刻度的样本所占的比率;右上的曲线表示同一说话人对数10似然比小于等于x轴刻度的样本所占的比率.Tippett图中的竖线为识别阈值,似然比体系的识别阈值为1,取对数后为0,最理想的情况就是左上的线和右上的线和阈值都没有交点.图4和5中的实线是基本系统的参考识别结果(请注意两图横坐标范围不同),在两图中是相同的.图4中点划线是经本文提出的AWVC算法调整后的识别结果,图5中的点划线是文献[5]中的算法使用本文汉语数据库计算时的识别结果.
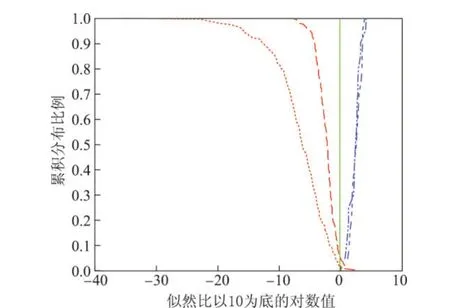
图4 AWVC算法识别结果的Tippett图Figure 4 Recognition results in Tippett plot of AWVC algorithm
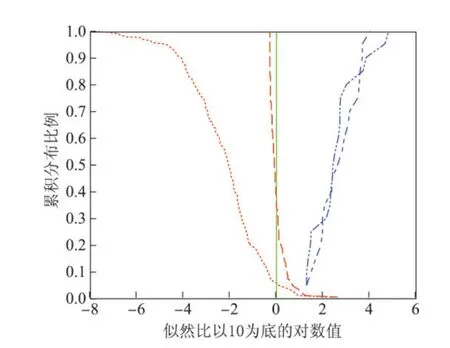
图5 文献[5]算法识别结果的Tippett图Figure 5 Recognition results in Tippett plot of algorithm in references[5]
从图4中可以看到,本文提出的自适应动态方差控制算法不仅明显提升了识别的正确率,而且显著加强了不同人比较对的支持力度,还使非同源假设的最大支持力度从约108倍提高到约1040倍,即自适应同源方差控制算法提高了系统对正确结论的支持力度,使法官和统计专家更有信心使用该语音证据.作为系统可靠性测量标准的Cllr值,未使用自适应同源方差控制之前为0.118 9,使用之后为0.059 1,系统的可靠性得到50.3%的提升.更重要的是,在保持错误否定率为0的基础上,错误认定率从5.79%下降到1.58%.本文与文献[5]使用不同的数据库,故无法进行横向比较,但是把文献[5]中的算法应用在本文的中文数据库上,识别性能不如本文提出的算法,如图5所示.
3 结语
本文提出了法庭自动说话人识别方法,成功地将普通自动说话人识别系统应用于法庭语音比对任务之中,扩展了普通基于得分的说话人识别系统的应用领域;同时提出了自适应同源方差控制算法,根据说话人识别的基本原理对说话人自身的同源得分方差分布进行了合理的自适应控制.实验结果显示,与未使用方差控制的系统和其他同类算法相比,不仅显著提高了识别率,而且使证据对结论的支持力度进一步加强,错误认定率显著降低.
[1]MORRISON G S,ZHANG C L,ROSE P.An empirical estimate of the precision of likelihood ratios from a forensic-voice-comparison system[J].Forensic Science International,2011,208:59-65.
[2]ZHANG C L,MORRISON G S,ENZINGER E,OCHOA F.Effects of telephone transmission on the performance of formant-trajectory-based forensic voice comparison-female voices[J].Speech Communication,2013,55(6):796-813.
[3]MORRISON G S.A comparison of procedures for the calculation of forensic likelihood ratios from acoustic-phonetic data:multivariate kernel density(MVKD)versus Gaussian mixture model-universal background model(GMM-UBM)[J].Speech Communication,2011,53(2):242-256.
[4]WANG Huapeng,YANG Jun,XU Yong.Forensic speaker recognition in likelihood ratio framework[J].Journal of Data Acquisition&Processing,2013,28(2):239-43.
[5]CASTRO D R.Forensic evaluation of the evidence using automatic speaker recognition systems[D].Madrid:Universidad Autonoma de Madrid,November,2007.
[6]MORRISON G S.Tutorial on logistic regression calibration and fusion:converting a score to a likelihood ratio[J].Australian Journal of Forensic Sciences,2013,45(2):173-197.
[7]POH N,KITTLER J.On the use of log-likelihood ratio based model-speci?c score normalisation in biometric authentication[C]//LNCS 4542,IEEE.The ist IAPR International Conference on.Biometrics(ICB'07),2007:614-624.
[8]REYNOLDSD A,QUATIERIT F,DUNNR B.Speaker verif ication using adapted Gaussian mixture models[J].Digital Signal Processing,2000:19-41.
[9]BOTTI F,ALEXANDER A,DRYGAJLO A.An interpretation framwork for the evaluation of evidence in forensic automatic speaker recognition with limited suspect data[C]//Proceedings of Odyssey,2004:63-68.
[10]KINOSHITA Y,OSANAI T.Within speaker variation in diphthongal dynamics:what can we compare?[C]//Proceedings of the 11th Australasian International Conference on Speech Science&Technology,Auckland,New Zealand,Canberra,Australia:Australasian Speech Science&Technology Association,2006:112-117.
[11]ROSEP.Technical forensic speaker recognition:evaluation,types and testing of evidence[J].Computer Speech and Language,2006:159-191.
[12]BRÜMMER N,PREEZ D J.Application independent evaluation of speaker detection[J].Computer Speech and Language,2006:230-275.
[13]ROSE P.Accounting for correlation in linguisticacoustic likelihood ratio-based forensic speaker discrimination[C]//Proceedings of the IEEE Odyssey Speaker and Language Recognition Workshop,2006:1-8.
