基于判别分析的基因分类
2014-02-21林薇李胜曹治清
林薇, 李胜, 曹治清
(成都中医药大学管理学院, 四川 成都 611137)
基于判别分析的基因分类
林薇, 李胜, 曹治清
(成都中医药大学管理学院, 四川 成都 611137)
利用基因表达序列识别肿瘤亚型, 具有非常重要的临床意义. 根据大肠杆菌基因图谱筛选出的信息基因, 采用判别分析法, 得到典型判别式函数, 以阈值θ=-0.6935来进行分类, 进而确定肿瘤基因“标签”.
判别分析; 基因分类; 典则判别函数
DNA微阵列(DNA microarray)也叫做基因芯片(Gene chip), 是在一种特殊玻璃片上安装成千上万个核酸探针, 最终获取关于基因序列的信息, 使用基因芯片便于定量分析基因的表达水平, 在生物分析检验能力方面, 能做到快速、高效、低成本. 如果利用基因表达序列来识别肿瘤亚型, 这将具有非常重要的临床意义.
蔡立君[1](2006)提出了一种基于遗传算法的基因分类算法, 其基本思想是利用遗传算法代替独立分量分析中的传统的估计分离矩阵算法,对基因表达式数据进行分类, 从而克服了结果不精确的问题.蒋红卫[2](2007)等人探讨了基于基因表达谱的疾病分型识别模型建模方法. 方法结合白血病基因表达谱数据分析,利用偏最小二乘判别分析(PLS-DA)对利用基因微阵列数据予以建立白血病分型模型, 通过验证, 偏最小二乘判别分析的白血病识别模型的拟合准确度和预测准确度均达到100%. 羊四清[3](2009)提出基于ICA的模式表达空间的概念,并且在此基础上, 对数据的表达形式进行了重新构造, 并根据此表达形式进行了基因的分类, 通过实验验证了此类方法的可行性. 基因表达谱的回归分析是可以处理多个基因变量间线性依存关系的统计方法, 于是研究者们提出了使用回归分析基因表达谱数据, 如Huang[4](2003)在将线性回归方法应用于肿瘤的分类研究中使用了线性回归的方法;Li.H[5](2004)等人使用互变量(Cox)回归方法分析基因表达谱数据, 用于患者的生存率预判.
判别分析又称“分辨法”, 是在分类确定的条件下, 根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法. 本文主要应用判别分析的思想, 将大肠杆菌的基因表达谱中的致癌基因筛选出来,利用典则判别函数对初始分组案例中的基因进行正确分类, 进而确定了基因“标签”.
1 基因判别函数的建立
典则判别函数基于Bayes判别思想建立, 主要用于考察各类别的观测值之间的相关关系, 然后根据建立的分类规则对原始样本重新进行分类, 通过比较预测分类与原始分类, 确定对初始样本的判别准确率.
1.1 样本的方差解释及检验
就一维总体而言, 取值的分散性可以用方差刻画. 因此用欧氏距离除以方差作为点到总体的远近, 对判别分析而言就比较合理.但是就本文在处理p维总体的判别问题时, 对应于总体方差的是协差阵∑, 为此定义
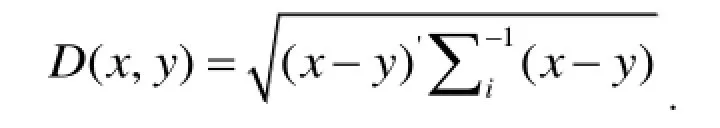
度量总体Gi中两点x,y之间的距离;
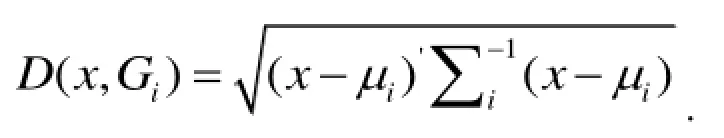
作为样本x到总体Gi的距离.
其中μi、∑i分别为总体Gi的均值向量和协差阵. 若D(x,G1)<D(x,G1), 则x∈G1; 若D(x,G1)>D(x,G1), 则x∈G2; 若D(x,G1)=D(x,G1), 则不判.
根据数据筛选出信息基因28个, 采用判别分析法, 可知判别函数的方差解释和显著性检验, 如表1, 表2

表1 特征值
a: 分析中使用了前一个典则判别函数.

表2 Wilks的Lambda
特征值表格给出了典则判别函数所能解释的方差变异, 表1说明该函数解释了所有变异. ”Wilks的Lambda”用于检验该判别函数是否具有统计学上意义, 表2从Sig值看, 在0.1的显著性水平上是比较显著的, 从而可以接受由此建立的判别规则.
1.2 典则判别函数
利用SPSS软件求出判别函数, 得到标准化的典型判别式函数f(e)为:

其中,ei(i=1,2,…,28)为筛选的信息基因.
将62个样本对应的的信息基因数据代入判别函数求出对应的62个指标值(见图1、图2)

图1 VAR00001=0的典则判别函数1
图1说明22个致癌基因的均值为-3.04, 标准偏差为0.973.
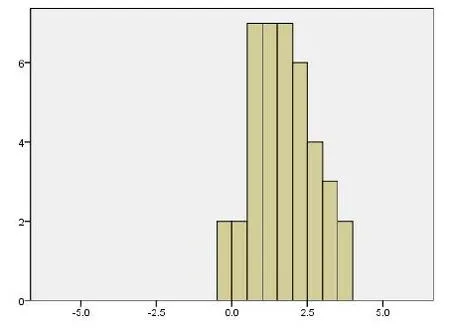
图2 VAR00001=1的典则判别函数1
图2说明随机抽取的40个基因的均值为1.67, 标准偏差为1.014.
2 基因分类结果
通过观察, 22个正常的样本的指标值都为负, 而40个癌症样本对应的指标值绝大部分都是正数, 可以发现,若指标值越小, 就越能说明此人的基因未发生突变; 若指标值越大, 就越能说明此人是癌症病人. 采用取各自中间值的方法, 将阈值θ定义为:
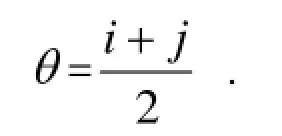
i为22个正常样本中的最大值,j为40个癌症样本中的最小值
最后根据样本的判别式得分与θ的关系进行判断:
(1)当样本的判别式f(e)>θ时, 样本的基因标签定为癌变;
(2)当样本的判别式f(e)<θ时, 样本的基因标签定为正常;
(3)当样本的判别式f(e)=θ时, 样本的基因标签不作判断.
利用SPSS软件, 采用判别分析法, 按照案例顺序的统计量, 可以知道i=-1.448,j=0.061,那么阀值θ=-0.6935,
对分析中的样本进行验证, 详情见表3的分类结果.

表3 分类结果
表3说明: 在肿瘤基因分类中, 对初始分组案例进行了完全正确的分类, 在进行交叉分组验证时, 对样本的82.3%进行分类.
3 结论
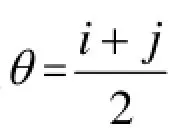
[1] 蔡立军, 林亚平, 卢新国, 等. 基于遗传算法的基因分类[J]. 电子学报, 2006, 34(11): 2115-2119.
[2] 蒋红卫, 夏结来, 李园, 等. 偏最小二乘判别分析在基因微阵列分型中的应用[J]. 中国卫生统计, 2007, 24(4): 372-374.
[3] 羊四清, 卢新国, 易叶青. 基于 ICA 模式空间的基因分类[J].计算机工程与应用, 2009, 45(23): 40-43.
[4] HUANG X, PAN W. Linear Regression and Two-class Classification with Gene Expression Data[J]. Bioinformatics, 2003, 19: 2072-2078.
[5] LI H, GUI J. Partial Coxregression analysis for Highdimensional Microarray Gene Expression Data[J]. Bioinformatics, 2004, 20: I208-I215.
[6] 林杰斌, 林川雄. SPSS12统计建模与应用实务[M]. 北京: 中国铁道出版社, 2006.
[7] 袁新生, 邵大宏. LINGO和EXCEL在数学建模中的应用[M]. 北京: 科学出版社, 2007.
Gene classification based on discriminate analysis
LIN Wei, LI Sheng, CAO Zhi-qing
(School of Management, Chengdu University of TCM, Chengdu 611137, P.R.C.)
There is important clinical significance for gene expression sequences to identify cancer subtypes. According to E.coli genome information genes, the paper uses discriminate analysis to obtain canonical discriminate function and classify with threshold θ=-0.6935. And then the cancer gene label is determined.
discriminate analysis; gene classification; canonical discriminate function
O29
A
1003-4271(2014)01-0097-04
10.3969/j.issn.1003-4271.2014.01.20
2013-11-18
林薇(1987-), 女, 助教, 硕士, 研究方向: 可靠性理论与应用; 邮箱: linwei2321@163.com.
成都中医药大学科技发展基金.
