Map Reduce模型下的并行线性时间选择算法研究
2014-02-09王永贵李鸿绪
王永贵,李鸿绪,宋 晓
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
0 引 言
线性时间选择算法被广泛应用于从若干元素中迅速确定某一个元素[1]。该算法在处理少量的数据时是有效的,但是面对大数据,算法的执行效率不能够满足人们的需要。随着网络信息技术的发展,人们可以采集并利用的数据越来越多,因此如何处理海量数据下的线性时间选择是迫切需要解决的问题。Google提出的Map Reduce[2]并行编程框架在处理海量数据问题上有着显著的优势,该模型具有良好的扩展性及容错性,能够满足人们对海量数据处理的需要。Hadoop[3]开源系统很好地实现了MapReduce编程模型,因此在对大数据处理的时候Hadoop已经成为一种不可或缺的选择。可以通过改进传统的线性时间选择算法,使其适应Map Reduce并行编程模型,从而能够有效地解决海量数据下的线性时间选择问题。
文中对Hadoop项目的研究,提出了利用Hadoop Map Reduce模型来改进线性时间选择算法,使得可以在集群的多个分布式节点上实现改进后的算法,提高线性时间选择算法的执行效率。
1 Map Reduce计算模型
Map Reduce用于研究和处理大规模数据集的并行计算[4]。Map Reduce是一种可用于数据处理的编程模型,MapReduce程序本质上是并行运行的。在Hadoop集群[5]中,用于执行MapReduce并行化任务的节点有两个角色,分别是Job Tracker和Task Tracker,一个Hadoop集群中只能有一个Job Tracker节点。Hadoop中每个Map Reduce任务会被初始化成一个Job,每个Job又会自动被分为两个运行阶段,分别是Map阶段和Reduce阶段[6],这两个阶段是用函数的形式表示,用户可以根据任务的需求来自行完成函数的编写任务,即完成Map函数和Reduce函数的编写任务。Map函数接收一个<key,value>键值对的输入,该键值对会有Hadoop内部系统提供,然后Map函数会产生中间结果,也是以<key,value>键值对的形式输出,Hadoop会将该中间结果进行适当的汇总并非配给相应的Reduce函数,Reduce函数会接收到<key,(list of values)>的键值对输入,然后对这个键值对进行处理,并输出结果,同样也是<key,value>的形式。
2 Map Reduce任务执行流程
Map Reduce任务的执行流程[7]可根据用户的需求分为7个步骤,如图1所示。各个阶段完成的任务如下:
(1)Input阶段:Hadoop会把大到影响它查找效率的文件分割成等长的小数据发送到MapReduce,等长的数据称为输入分片(input split)[8],一个分片并不是数据本身,而是对数据的引用,Hadoop会根据分片上的信息将数据分配给对应的Map任务,数据在分配给对应的Map任务之前会被制定成一定的格式。
(2)Map阶段:Map任务会从输入的分片中读取记录,然后调用用户自己定义的map函数,处理后输出结果。map函数是由JobConf.Set MapperClass提交给系统,map函数处理的是没有经过加工的数据,数据之间没有相互依赖的关系,它会对每条数据进行相应的解析,从中提取key和value值,也就是数据的特征。数据的处理没有先后关系,也不需要和上一个状态的信息进行交互,它只处理当前的数据。
(3)Sort阶段:对map输出的中间结果进行相应的排序,排序的规则可以由用户自己定义,通过设置Job-Conf.setOutput KeyComparatotClass来实现,此阶段的排序是为了提高Map Reduce的工作效率,缩短任务的执行时间,降低任务的复杂度。
(4)Combine阶段:在一些情况下,中间结果的key出现的频率可能会比较高,导致重复现象,该阶段会将这些重复的key进行合并,再发送给Reduce任务,这样不仅可以减少中间结果的数据重复,更可以降低网络的负载,提高Map Reduce的执行效率。
(5)Partition阶段:在Map输出的中间结果传递给Reduce任务之前,需要将数据进行分组,每一组会根据需求传递给不同的Reduce任务,本阶段通过key进行分组,从而确定中间数据被分发到哪个Reduce任务上去执行。
(6)Reduce阶段:通过上一阶段,Map输出的中间结果会被分配给对应的Reduce任务,这里需要处理这些中间结果及中间键值相关集合,需要合并这些中间结果,合并的任务由reduce函数来完成,最后形成较少的键值对的集合,并输出对应的结果到下一环节。
(7)Output阶段:Reduce的输出结果被存放到HDFS文件系统[9],由JobConf.setOutputFormat来指定输出的格式,并且输出的格式和Map任务的输入格式是相互对应的,因为Reduce任务的输出是可以被其他Map任务读入的,从而达到循环执行Map Reduce任务的目的。
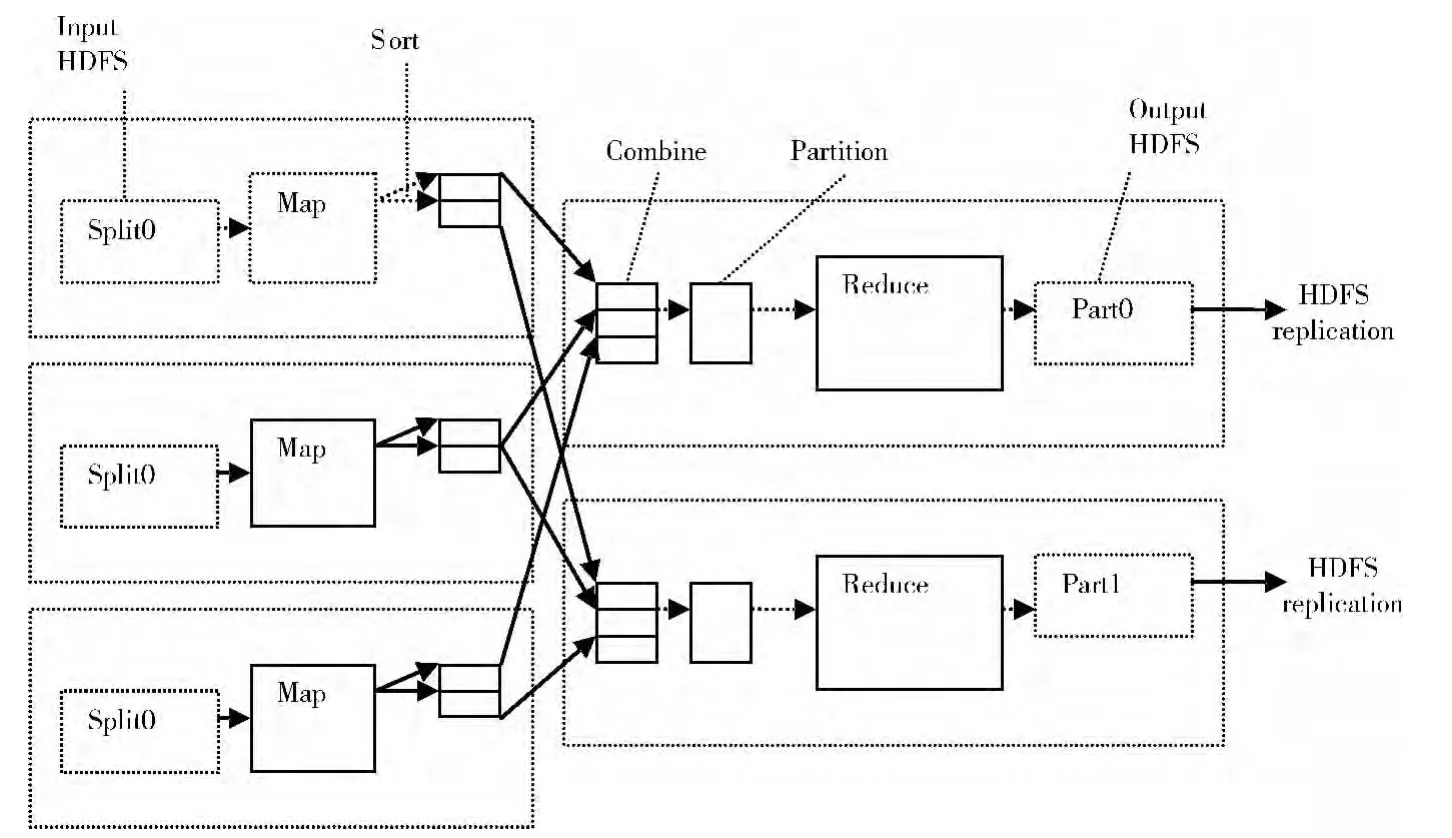
图1 MapReduce任务执行流程
3 线性时间选择算法的Map Reduce实现
3.1 线性时间选择算法
线性时间选择算法是与排序问题类似的元素选择算法。元素选择问题的一般概念为:在给定的线性序集中n个元素和一个整数k,1≤k≤n,要求找出这n个元素中第k小的元素,即如果将这n个元素依其线性排序时,排在第k个位置的元素即为要找的元素。当k=1时,找的就是最小元素;同理,当k=n时,找的就是最大元素;当k=(1+n)/2时,称为找中位数。
在某些特殊情况下,很容易设计出解选择问题的线性时间算法。例如,找n个元素的最小元素和最大元素显然可以在O (n)时间内完成。如果k≤n/log n,通过堆排序算法可以在O (n+k log n )=O (n)时间内找出第k小元素,当k≥n-n/log n时也一样。
3.2 在Map Reduce框架下的实现
线性时间选择问题在Map Reduce框架下实现的基本思路,为了清晰的表述算法步骤,用n代表元素总个数,n>0;m表示总元素被分成的组的个数,m>0;k表示要找的第k小元素,k>0;MIN_LIST表示最小元素列表,按照升k>0序排列好的数据,初始值为空;t表示最小元素列表中的元素个数,t≥0;WAITFORSEL_LIST表示各个分组输出后的最小值列表。
步骤1 将n个数据分成m组,找出每一组元素中的最小元素,并用该最小元素与MIN_LIST中的数据进行比较,若最小值列表中存在该元素则找出第二小的元素,同样将该元素与MIN_LIST比较,直到该最小元素不存在于MIN_LIST中,将各个组的最小元素汇总并统一放入WAITFORSEL_LIST中。
步骤2 找出WAITFORSEL_LIST列表中的最小元素,加入MIN_LIST中,MIN_LIST初始为空。
步骤3 将MIN_LIST中的元素个数记为t,若k=t,则MIN_LIST中的第t个元素即为要找的第k小元素,算法结束;若k>t,则回到步骤一继续执行算法。
图2描述了线性时间选择算法的Map Reduce并行化实现过程。由于Map Reduce计算模型的需要,数据记录要以行的形式进行存储[10],使得数据能够按照行来进行分片,分片的过程由MapReduce的运行环境来完成,不需要进行代码的编写。
3.3 map函数的实现
map函数实现的任务是计算出本组中的最小元素,且该元素不存在于MIN_LIST中,否则继续寻找最小元素,map函数的输入为Map Reduce运行环境分配给该map任务的元素集合和上一轮更新后的MIN_LIST,输入的数据记录为<key,value>对的形式,该键值对的含义是<行号,记录行>;每个map函数都要读入描述MIN_LIST的文件,map函数对输入的所有元素进行比较,计算出最小元素,并将该最小元素与MIN_LIST文件中的元素进行比较;输出中间结果<key,value>对的形式,该键值对的含义是<中间最小元素行号,中间最小元素记录行>。map函数的伪代码如下:
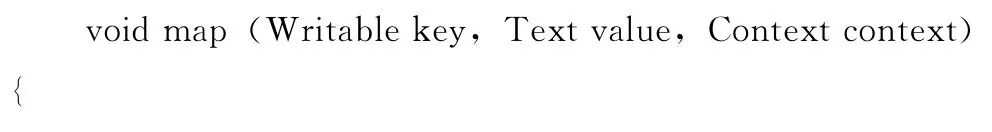

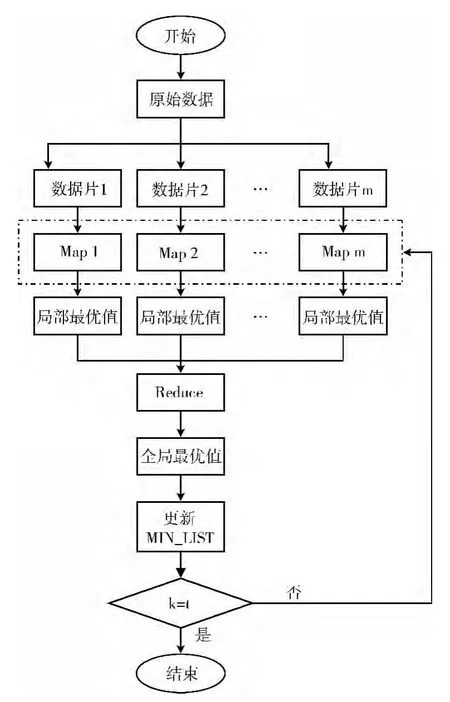
图2 线性时间选择算法的并行化实现
3.4 reduce函数的实现
reduce函数的任务是汇总map函数的输出的中间结果[11],对map函数输出的各自最小元素进行比较并找出最小元素,将最小元素加入MIN_LIST中,此时对k和t的值进行比较,如果k=t那么任务结束,要找的元素即为MIN_LIST中的最后一个元素,否则更新MIN_LIST后进行下一轮的Map ReduceJob任务。在reduce函数中,输入数据为<key,value>对的形式,该键值对的含义是<中间最小元素行号,中间最小元素记录行>;将所有的数据送给同一个reduce任务,对所有的输入数据进行比较,计算出最小值,并更新MIN_LIST描述文件;输出结果为<key,value>对的形式,该键值对的含义是<最小元素行号,最小元素记录行>。reduce函数的伪代码如下所示:
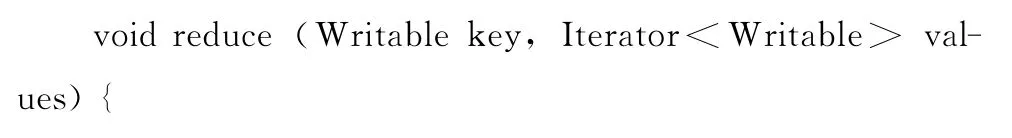

4 实验结果及分析
4.1 实验环境搭建
图3是本实验中用到的集群结构示意图,共6台机器,每台机器的硬件配置如下:CPU型号为Intel Xeon X3330,内存为8GB;硬盘2TB SATA;板载Intel双千兆网络控制器。其中1台机器作为Job Tracker和Name Node主服务节点,其他机器均作为Task Tracker和Data Node子服务节点。根据Hadoop项目的官方网站相关的方法配置Hadoop1.0.4版本的集群。
4.2 单机处理结果分析实验
实验主要完成的内容为,比较线性时间选择算法的串行实现与Hadoop集群中的一个节点在相同的硬件环境配置下[12],处理相同规模数据,从数据的读入一直到最终的数据的导出所要完成的时间。在实验的过程当中,线性时间选择算法串行采用Java编程语言来实现,实验环境Windows XP,jdk1.7.0_15。在两种实现方法的对比实验中,处理的数据文件大小为5811KB,k的取值从小到大依次递增,实验情况如图4所示,其中LTS表示传统的线性时间选择算法实验结果,PLTS表示改进后的算法实验结果。
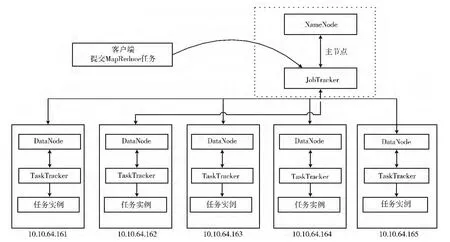
图3 集群配置结构
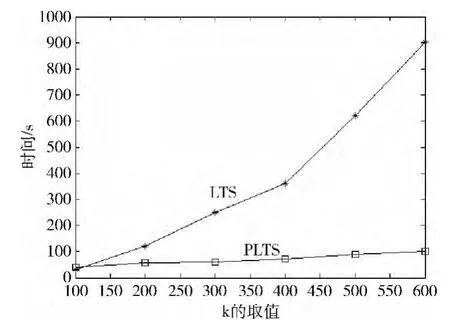
图4 单机对比实验结果
通过上述的实验表明:对相同的数据文件进行操作时,两种不同的实现方法在随着k取值的增长,产生了明显的对比,在k值较小时单机串行显示出了较好的优势,而Hadoop集群上的单节点的线性时间选择算法的并行实现显得比较笨拙,因为Hadoop集群中的作业启动和任务分配以及服务节点与数据节点之间的交互,都需要耗费一定的时间和占用的资源,而单机上的串行算法所消耗的资源要远远小于Hadoop集群所消耗的资源,从而在数据规模小的情况下节约了时间;在k值较大时,Hadoop集群上的单节点的线性时间选择算法的并行实现显示出它的优势,因为Hadoop集群具有处理较大规模数据的能力,而传统的串行实现因为运算的次数不断的增加而变得缓慢。
4.3 集群处理结果及分析
本实验的目的是在Hadoop集群中进行线性时间选择算法的并行化实现,在大规模数据处理[13]的情况下,对于k值较大时,Hadoop集群的单节点实验已经显示出了它独到的优势,那么在Hadoop集群多节点共同完成线性时间选择算法的并行化实现必然会进一步提高效率因此,可以进行针对更大规模数据的线性时间选择算法的并行化实验。本实验选择3组数据集,如表1所示,每个元素是浮点型数据,为了显示Hadoop集群对大规模数据的处理能力,我们对k采取较大的值,k取值为4000进行实验。

表1 数据集情况
实验中分别选择1,2,3,4,5个任务节点(tasktracker)来参与计算,主要考察的目标是在相同规模数据,处理相同问题的情况下,逐渐增加节点时所需要完成任务花费的时间,实验结果如图5所示。
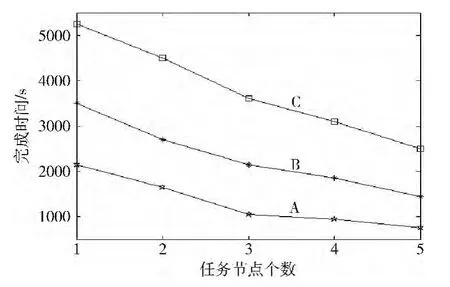
图5 线性时间选择算法Hadoop集群并行化处理结果
通过实验可以得出,在相同规模数据,处理相同问题的情况下,随着节点数的增加,完成任务所需要花费的时间就越少,因此增加节点会显著提高完成任务的效率。这足以说明Map Reduce在处理线性时间选择算法的并行化实现上有着显著的优势和可行性。
5 结束语
本文针对线性时间选择算法无法在有效的时间内处理大数据的问题,提出了利用Map Reduce模型并行实现线性时间选择算法,将文件中的数据分配给各个任务节点,各任务节点完成局部最优解的计算,然后系统将各个局部最优解汇总并计算出全局最优解。实验结果表明,MapReduce模型下的并行线性时间选择算法,在面对大规模数据时能够体现出其高效率的优势。
[1]Zhi Yitan,Yong He.Liner time algorithms for parallel machine scheduling[J].Acta Mathematica Sinica,English Series,2007,23(1):137-146.
[2]TAN Xiongpai,WANG Huiju,WANG Shan,et al.Big data analysis-competition and symbiosis of RDBMS and MapReduce[J].Journal of Software,2012,23(1):32-45(in Chinese).[覃雄派,王会举,王珊,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.]
[3]ZHAO Yanrong,WANG Weiping,MENG Dan,et al.Efficient join query processing algorithm CHMJ based on hadoop[J].Journal of Software,2012,23(8):2032-2041(in Chinese).[赵彦荣,王伟平,孟丹,等.基于Hadoop的高效连接查询处理算法CHMJ[J].软件学报,2012,23(8):2032-2041.]
[4]ZHANG Boliang,ZHOU Shuigeng,GUAN Jihong.Skyline computation under MapReduce framework[J].Journal of Frontiers of Computer Science and Technology,2011,5(5):385-397(in Chinese).[张波良,周水庚,关佶红.MapReduce框架下的Skyline计算[J].计算机科学与探索,2011,5(5):385-397.]
[5]Polo J,Carrera D.Performance-driven task co-scheduling for Map Reduce environments[C]//IEEE Network Operations and Management Symposium Conference,2010:373-380.
[6]LI Jianjiang,CUI Jian,WANG Dan,et al.Survey of Map Reduce parallel programming model[J].Acta Electronica Sinica,2011,39(11):2635-2642(in Chinese).[李建江,崔健,王聃,等.Map Reduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.]
[7]DING Linlin,XIN Junchang,WANG Guoren,et al.Efficient Skyline query processing of massive data based on map-reduce[J].Journal of Computers,2011,34(10):1785-1796(in Chinese).[丁琳琳,信俊昌,王国仁,等.基于Map-Reduce的海量数据高效Skyline查询处理[J].计算机学报,2011,34(10):1785-1796.]
[8]Shafer J,Rixner S,Cox A L.The hadoop distributed filesystem:Balancing portability and performance[C]//Proceedings of the IEEE International Symposium on Performance Analysis of Systems &Software.Washington,DC,USA:IEEE Computer Society,2010:122-133.
[9]PAN Wei,LI Zhanhuai,WU Sai,et al.Evaluatig Large graph processing in Map Reduce based on message passing[J].Journal of Computers,2011,34(10):1768-1784(in Chinese).[潘巍,李战怀,伍赛,等.基于消息传递机制的MapReduce图算法研究[J].计算机学报,2011,34(10):1768-1784.]
[10]Huang D,Shi X,Ibrahim S,et al.MR-Scope:A real-time tracing tool for Map Reduce[C].The Map Reduce of HPDC,2010:849-855.
[11]Steven J Plimpton,Karen D Devine.MapReduce in MPI for Large-scale graph algorithms[J].Parallel Computing,2011,37(9):610-632.
[12]LUAN Yajian,HUANG Chongmin,GONG Gaosheng,et al.Research on performance optimization of hadoop platform[J].Computer Engineering,2010,36(14):262-264(in Chinese).[栾亚建,黄翀民,龚高晟,等.Hadoop平台的性能优化研究[J].计算机工程,2010,36(14):262-264.]
[13]Fabrizio Marozzo,Domenico Talia,Paolo Trunfio.P2P-Map Reduce:Parallel data processing in dynamic cloud environments[J].Journal of Computer and System Sciences,2011,78(5):1382-1402.
