基于博弈多智能体的企业标准联盟治理研究
2014-02-06李代平
章 文,李代平
(1.中山大学地理科学与规划学院,广东 广州 510275;2.深圳市市场监管局标准化处,广东 深圳 5 180403;3.广东工业大学计算机学院,广东 广州 510090)
1 引言
据德国标准化学会(DIN)统计,标准化对德国的经济增长贡献率是0.9%,对法国和澳大利亚是0.8%,英国0.3%,加拿大0.2%,目前仅德国一个国家,标准化每年能够创造170 亿欧元的经济效益[1]。由于网络外部效应,当某项产品标准市场规模达到临界容量后,会产生市场的标准锁定[2],用户将倾向选择此标准而不选择其他标准,以推动联盟标准成为事实标准为主要目标的标准联盟重要性不言而喻。企业标准联盟作为知识经济时代的一种新兴、复杂的技术经济现象,蕴含了经济全球化和知识经济社会丰富的信息量[3],它是由具有一定产业关联度的企业为推动技术标准主流化而组成的联盟实体。基于标准联盟概念框架,孙耀吾等开展了对标准联盟治理的综述,并认为现有研究没有集中到联盟治理研究上来[4],而国外将博弈论越来越多运用到企业联盟形态的治理研究中[5-7]。
复杂适应系统CAS (Complex Adaptive System)由大量的进行非线性相互作用行为的主体所组成动态演进系统,行为主体具有一定的“智能”和“学习”能力,由此产生适应性的生存和发展策略导致复杂适应系统的创造性演化[8-9]。企业自身是一个复杂系统,而标准联盟更是个开放性的复杂巨系统,根据复杂适应系统理论,企业标准联盟可视为以企业为主体构建起来的复杂适应系统,联盟中的企业作为适应性主体能够与环境以及其他主体进行交互作用。企业主体在这种持续不断的交互作用过程中,“比较学习”或“积累经验”,并且依据学到的经验改变自身的结构和行为方式,从而引起整个标准联盟的演变或进化。企业这种主动与环境的反复的互相作用,是标准联盟发展的基本动因,企业分化和联盟演变都可以从企业主体的行为规律中找到根源。复杂适应系统是由大量的适应性主体所组成,适应性主体可以抽象和封装为多智能体模型ABM (Agent-Based Modeling)中的智能体Agent,对复杂适应系统的分析和建模可建立在对组成系统的Agent 的分析和建模基础之上[10-11]。这是一种自下而上的建模方法,模型由符合特定规则和能力的智能体构成,系统整体的涌现行为可视为多智能体之间以及多智能体与环境的相互作用的结果[12]。
2 发展现状
深圳多家龙头骨干企业联合科研院所和行业协会在战略性新兴产业与传统优势产业领域先后组建了包括钟表标准化技术联盟、数字对讲机企业标准联盟、贵金属及珠宝玉石饰品企业标准联盟、LED 产业标准联盟、RFID 产业标准联盟、电子商务企业标准联盟、新能源标准与知识产权联盟、金融服务业标准联盟、安防产业标准联盟、智能电视产业标准联盟和中医药企业标准联盟等11 家具有区域影响力的企业标准联盟。各联盟既有华为、中兴、海能达等各细分产业中的龙头企业作为发起单位和核心成员,同时也广泛吸纳了行业中具有发展潜力和创新活力的中小微企业。自2007年起步以来,深圳标准联盟工作逐步进入正轨,2011年和2012年,深圳标准联盟发布的联盟标准数在广东省均列首位,至2013年底已累计备案发布近百份联盟标准;深圳部分标准联盟国内市场份额占50%以上,联盟标准的经济效益正在显现,助推着深圳品牌进入更广阔的发展舞台。
深圳现正处在产业结构调整优化、产业转型升级关键性阶段。在此背景下,以标准联盟为增强企业核心竞争力和引领产业发展的有力手段,科学合理的强化联盟治理机制、推动企业标准联盟发展壮大对于深圳而言,其重要性和紧迫性显得尤为突出。深圳组建的企业标准联盟围绕推动技术创新成果标准化、促进标准与知识产权相结合、提升企业和产业竞争力的总体目标,已经对“深圳制造”向“深圳智造”的转变产生了重要影响。在后金融危机时代,深圳标准联盟正以企业抱团取暖的形式提升产业的标准化意识和区域竞争力水平,大大增强联盟中企业在“专利丛林”中的生存发展能力、增强遭遇“专利陷阱”时的应对处置能力,帮助联盟相关企业争取更大的经济效益。但与国外发展数十年相对较成熟的标准联盟相比,深圳企业标准联盟还处在培育上升期,因此在标准联盟培育、运作的实践工作中,深入探析联盟治理困境和难点是摆在当前的紧要问题,博弈多智能体模型则是模拟企业标准联盟演进方式进而挖掘其治理要点的有效分析手段。
3 模型设计
3.1 博弈结构
博弈论是研究理性经济个体在相互交往中资源投入和收益策略选择问题的科学,通过在局中找出己方最优反应策略来反映企业间的冲突和合作。在零和博弈中,所有各方的收益总和为零,一方的收益以另一方的损失为代价;在非零和博弈中,每一方的收益并不一定以其他方的损失为代价,很多情况下只有当博弈方获益时己方才获益。
技术标准的共享是标准联盟存在的基础,标准的共享实质为知识的共享,标准在约定框架下的共享能够促进联盟内各方的利益的提升,符合非零和博弈的特点。这种标准的共享、知识的复用也是企业战略联盟的主要优点,即结盟有助于企业有效的整合和运用知识[13]。但在信息对称的情况下,标准联盟是一个“囚徒困境”,战略联盟的不稳定性可用囚徒困境博弈的均衡结果来反映[14]。标准联盟建成运作后,合作一旦开始,联盟伙伴都会密切关注各方,观察有无迹象表明合作伙伴另行其事[3],因此标准联盟的运作又属于重复性博弈。联盟内企业间存在着竞争[15],背叛和机会主义行为就难以避免,联盟中存在采用不合作行为的企业,这类企业仅获取其他企业的标准与知识输出、却不共享研发与标准化成果,在特定情境下个体收益很可能会高于合作下的收益。此时标准联盟企业之间的博弈结构可用表1 所示矩阵描述。
博弈结构中R 代表着标准联盟成员合作时的收益;S 代表对方采用不合作行为、己方采用合作时的收益;T 代表对方采用合作行为、己方有不合作投机时的得益;P 代表双方采取不合作投机行为时的收益。设联盟的初始状态只有联盟发起企业,且发起企业均为合作型、占联盟总数比重为系数α,那么使用不合作收益β 系数来代表背叛收益与合作收益的比值,即β=T/R。为精简模型可令S=P=0,令R=1,此时T=R×β=β。
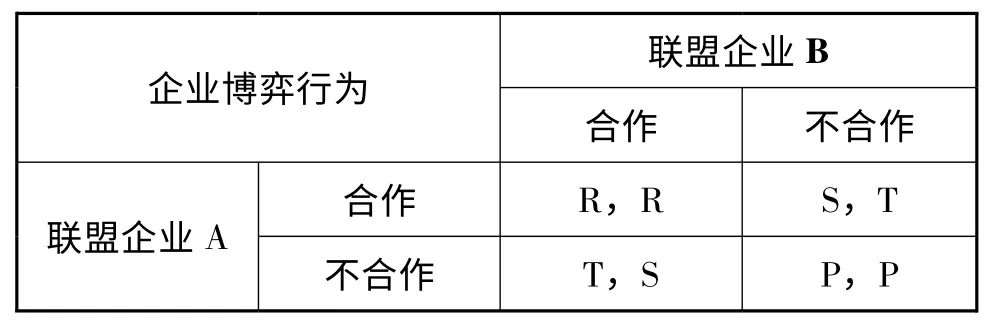
表1 标准联盟企业收益矩阵
3.2 Agent 行为定义
Agent 的博弈行为指的是主体在进行博弈时所采取的行为策略,并根据在特定环境下博弈双方所采取的策略和收益矩阵计算本次博弈的所获。假设环境是任何离散的瞬时状态的有限集合E:E={e0,e1,…},设Agent 有一个可执行动作的清单,它们改变环境的状态,设:Ac={α0,α1,…}是有限动作集合。Agent 与环境交互的基本模型如下。环境从某个状态开始,Agent 选择一个动作作用于这个状态。动作的结果是环境可能到达某些状态,在此状态的基础上,Agent 继续选择一个动作执行,环境达到可能状态集中的一个状态,然后,Agent 再选择另一个状态,如此继续下去。因此,Agent 在环境中的一次执行动作是环境状态与动作交替的一个序列r∶为表示Agent 的动作作用于环境的效果,引入状态转移函数:τ∶RAC→δ (E),其中RAC是以动作结束的可能的Agent 有限序列所组成的有限序列自己。状态转移函数建立了一个执行(假设以Agent 的动作作为结束)与可能的环境状态集合之间的映射,这些环境状态是动作执行的结果。可能出现两种情形,一是环境是与历史有关的,环境下一个状态不仅仅是由Agent 执行的动作和当前的状态决定,早时Agent 所做的动作对当前状态也起部分作用;二是允许不确定的环境。基于本文的博弈结构演化过程符合上述两种多智能体与环境互动情况的情形。标准联盟内企业第u步博弈演化环境可描述 为:eu∈τ(e0,α0,…,αu-1),式中e0为环境的初始状态,企业多智能体博弈行为可描述为αu=Ag(αu-1,eu-1,eu),即企业根据当前环境以及历史过程决定执行什么动作。
在设计多智能体仿真环境时,需要将联盟主体——企业抽象为智能体并赋予学习模仿能力,可以按照地理经济学(企业空间位置邻近)或社会经济学(合作关系邻近)相邻的事物更为相似的基本原则,当与之相邻(冯诺依曼型或Moore 型邻居)的主体采用合作行为收益较大时,则企业会模仿其合作行为,即将该合作行为作为优势策略剔除不合作劣势策略,反之亦然。
设每个企业智能体均为理性个体,通过了解以前博弈的历史、学习模仿抽象概念下附近企业的行为,不断调整博弈策略已达到己方最高收益,这个过程利用编写Agent 学习算法来实现。学习算法根据实际情况加以设计,可回溯之前多期博弈行为、或采用神经网络和遗传算法方法。在本文模型中每个企业智能体会在每次完成博弈后,根据对比自身选择策略和相邻对手选择策略的博弈所获收益结果来动态学习并修订自己的策略,以确定下次博弈将要采取的博弈策略。
4 模拟结果
4.1 情景模拟
图1 为不同情景(用α、β 系数表征)下多智能体模型仿真下的标准联盟整体发展趋势:当β<01 时,即不合作收益低于合作收益,很明显联盟企业将趋向于合作,最终联盟所有企业都采用合作行为策略,呈现出帕累托最优状态;当β=1.5 时,由于不合作收益高于合作收益,联盟发展稳定时总有一些企业会采用不合作策略以追求个体的最高收益;当β 高于一定值如β=1.8 时,联盟中企业最终均采用不合作行为策略,结果是联盟的解体,表现为收益趋向为零。为突出过程快照的特征,β=0.99 时α 取值为2%,β=1.5 时α 取值为30%,β=1.8 时α 取值为80%。这样的参数设定也揭示了在企业同质的假定下,发起成员的占比系数α 虽然决定了标准联盟是否得以成立,但标准联盟发展的趋势主要由不合作收益系数β 所决定:从图1 中可以看出即使初始化有着较高的α值,若β 过高,联盟依然可能会解体,表现在联盟企业均采用不合作行为策略。
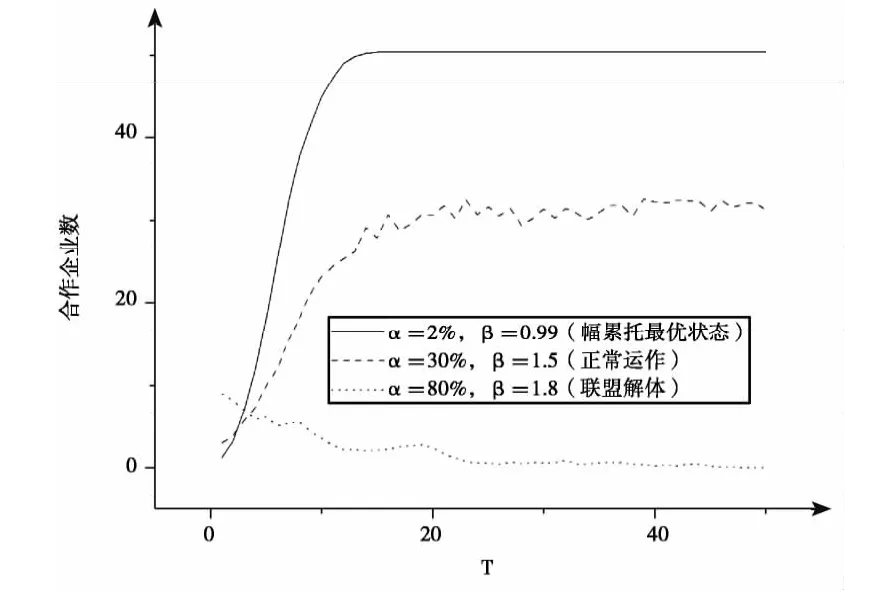
图1 不同情景下标准联盟发展趋势模拟比较
4.2 不合作收益β 系数的影响
给定系数α=30%,初始化后通过多智能体模拟得到不合作收益系数β 分别等于0.99、1.4、1.5、1.6 和1.8 条件下标准联盟总收益随时间变化曲线图如图2 所示。当不合作收益低于合作收益时(如β=0.99),联盟整体能够得到最大收益,这是一种理想状态;β 值越高,企业采用不合作行为时可能会得到更高的个体收益,与之对应的是联盟的整体收益迅速降低;当β 高于一定阀值,经过一段时间的运作,联盟整体收益将降为零,此时标准联盟名存实亡。可见在标准联盟内企业数不变的情况下,不合作收益系数β 值不但影响到联盟的发展方向,也影响着联盟整体的最大收益。
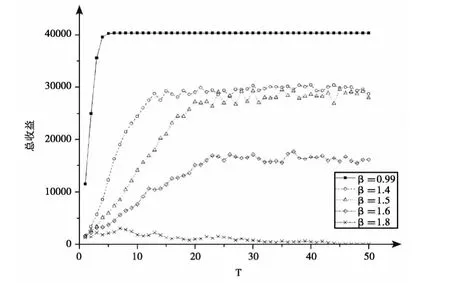
图2 不同收益系数β 下的标准联盟总收益
4.3 合作收益R 值的影响

图3 不同合作收益R 值下的标准联盟总收益
以上的仿真实验中合作收益R 值均设为1,R值虽然不会影响联盟发展趋势,但在系数α、β 一定时(如α=30%、β=1.5),R 值的改变同样会影响到联盟整体收益的大小,其反应的是成员合作程度对整体收益的影响。R 值越大,说明合作程度更深,联盟整体收益也随之增高(见图3)。对比图2 仿真结果还显示:R 值并不影响到整体收益达到最大值(即标准联盟稳定状态)的时间,只影响到最大值的大小;而β 系数既影响整体收益到达最大值的时间,也影响着标准联盟整体的最大收益。因此不合作收益β 系数的控制是标准联盟治理中的关键性环节;而提高合作收益R 值是实现较优联盟绩效的重要因素。
5 治理建议
总体来看,多智能体定性仿真环境模拟结果表明只有控制住联盟内不合作(背叛)行为的获利率β 系数,才能确保标准联盟的正常运作,以及促使提高联盟整体最大收益,同时随着合作程度的深入R 值的提高也能增加联盟总体收益。根据不同环境下标准联盟的发展演化轨迹以及联盟内企业博弈结构对标准联盟的影响,可以得到以下具体的深圳标准联盟治理建议:
标准联盟作为企业主体的集合,联盟有必要通过联盟章程等方式对企业进行自我行为的约束,明确各方的权利义务,加强技术标准与自主知识产权的保护,完善涉及知识产权技术标准的授权管理,控制住联盟的β 系数,维系联盟稳定发展;建立起一套可持续改进的协商合作机制,设立联盟组织的成员准入、标准制定、专利池构建等管理和实施监督等制度,在约定的框架下督促联盟内标准和专利等知识的互动、共享和利用,督促联盟契约型合作机制的落实;均衡各方权益、提升联盟成员参与的积极性,以实现较优的联盟绩效。
相对企业个体而言,联盟的整体合力更易较快地促成产品标准达到市场临界容量,从而迅速在市场竞争中占据有利地位。联盟标准是标准联盟的工作核心,也是关系到合作收益率保持联盟稳定的重要影响因子。企业标准联盟应及时将技术研发与标准化同步,建立专利池以减少企业实施标准的成本和风险,推动具有自主知识产权的联盟标准尽快抢占市场,以联盟形态采用标准跟随战略参与国际、国内标准的制修订,在相关领域和地区展开专利布局,与竞争对手谈判专利交叉许可,通过提高合作收益R 值来获取更高的联盟总体收益。
联盟是不同市场主体企业间的协作,一方面政府可以运用政策引导更多包括其他地区在内的产业链上企业加入深圳标准联盟,进一步深化分工合作来提高R 值,以推动联盟步入成熟的良性循环阶段;另一方面,联盟成立后政府应通过打击盗用联盟标准及其知识产权等违法行为来增加违法成本,维系标准联盟公平公正运作的法制环境来降低β 系数,以尽可能保障达到联盟企业整体收益最大化和联盟平稳运作的目的。值得注意的是,在此过程中政府工作重点应放在提供外部性强的公共服务、营造完善的市场政策环境上来,应避免对标准联盟及其企业技术标准研制等微观经济活动的直接干预。
[1]Din.The Economic Benefits of Standardization[EB/OL].2011-08-04.http://www.din.de.
[2]陶爱萍,张丹丹.技术标准锁定、创新惰性和技术创新[J].中国科技论坛,2013,(3):11-16.
[3]曾德明,彭盾,张运生.技术标准联盟价值创造解析[J].软科学,2006,(3):5-8 +22.
[4]孙耀吾,裴蓓.企业技术标准联盟治理综述[J].软科学,2009,(1):65-69.
[5]Arend RJ,Seale DA.Modeling Alliance Activity:an Iterated Prisoners' Dilemma with Exit Option[J].Strategic Management Journal,2005,26(11):1057-1074.
[6]Chen F,Fan L.Analysis on Stability of Strategic Alliance:a Game Theory Perspective[J].Journal of Zhejiang University Science a,2006,7(12):1995-2001.
[7]Zeng M,Chen X.Achieving Cooperation in Multiparty Alliances:a Social Dilemma Approach to Partnership Management[J].Academy of Management Review,2003,28(4):587-605.
[8]陈禹.复杂适应系统(CAS)理论及其应用——由来、内容与启示[J].系统辩证学学报,2001,(4):35-39.
[9]杨波,徐升华.复杂系统多智能体建模的博弈进化仿真[J].计算机工程与应用,2009,(23):6-8 +14.
[10]张江,李学伟.人工社会——基于Agent 的社会学仿真[J].系统工程,2005,23(1):13-20.
[11]田丰,李侠,李坚石.基于复杂适应系统的经济建模仿真方法[J].计算机仿真,2008,(10):266-271.
[12]Crespi V,Galstyan A,Lerman K.Top-down vs Bottom-up Methodologies in Multi-agent System Design[J].Autonomous Robots,2008,24(3):303-313.
[13]Grant RM,Baden‐fuller C.A Knowledge Accessing Theory of Strategic Alliances[J].Journal of Management Studies,2004,41(1):61-84.
[14]蔡继荣,胡培.基于合作溢出的战略联盟不稳定性研究[J].中国管理科学,2005,(4):142-148.
[15]Keil T.De-facto Standardization Through Alliances—Lessons from Bluetooth[J].Telecommunications Policy,2002,26(3):205-213.
