网络搜索引擎的设计与实现
2014-02-05郭永利卢颖颖
郭永利,卢颖颖
0 引言
随着互联网技术的飞速发展,互联网中的信息量也越来越大,如何更加有效地利用这些信息资源,已经越来越受到人们的关注。互联网中存在的信息来源十分广泛,与此同时,存在的形式也是多种多样,包括图像、文本、视频、音频等不同的形式,面对着不同来源,不同形式的海量信息,如何准确、快速地找到自己所需要的信息成为我们在使用互联网时候所面临的一个问题,因此,开发一个搜索引擎就非常必要。目前,成熟的搜索引擎如 Lycos、Yahoo、Google、百度等各有优点[1],如Google比Yahoo能更快、更准确搜索到所需信息,百度中文搜索引擎支持网页信息检索,图片,Flash,音乐等多媒体信息的检索等,而本文搜索引擎的开发是通过网络爬虫抓取信息,然后再通过一定的技术对网页信息进行提取、处理,将抓取到的信息存放在索引数据库中,通过一些查询接口实现信息检索,帮助用户在海量的信息中迅速地、准确地找到用户真正感兴趣的信息。
1 搜索引擎的设计
1.1 搜索引擎结构设计
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎主要包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。全文搜索引擎是目前广泛应用的主流搜索引擎[2-3]。它可以对被索引的文章中的每一个词建立索引,在用户检索时,检索程序就会根据事先建立好的索引进行查找,并将查找的结果反馈给用户。本文的主要工作就是使用 Java设计并实现了一个Web全文搜索引擎,搜索引擎结构设计如图1所示:
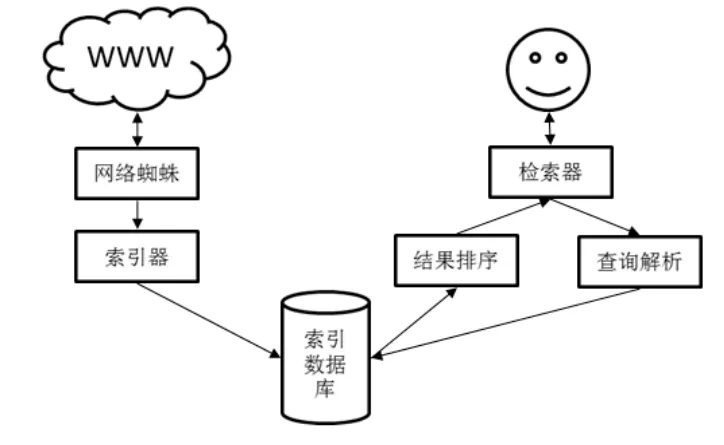
图1 搜索引擎结构
1.2 网络蜘蛛结构设计
创建搜索引擎的第一步就是要设计一个程序在海量的互联网信息中漫游,并抓取网页信息。这个程序被称为网络蜘蛛,网络蜘蛛也被称为自动搜索机器人,它主要用于分析网页上的每一个超链接,并根据超链接链到其他网页中的超链接[4],网络蜘蛛结构设计如图2所示:
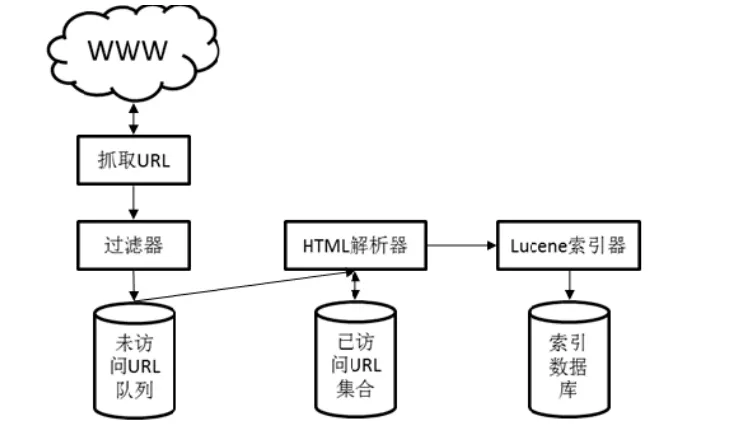
图2 网络蜘蛛结构
1.3 索引器结构设计
搜索引擎对网络蜘蛛抓取到的网页信息进行整理,这一过程称为“创建索引”。索引器结构设计如图3所示:
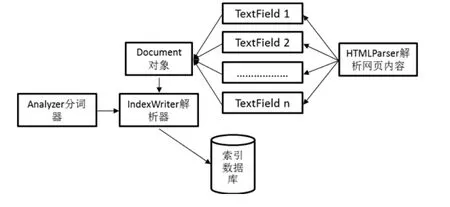
图3 索引器结构
1.4 检索器结构设计
搜索引擎每时每刻都要收到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料。检索器结构设计如图4所示:
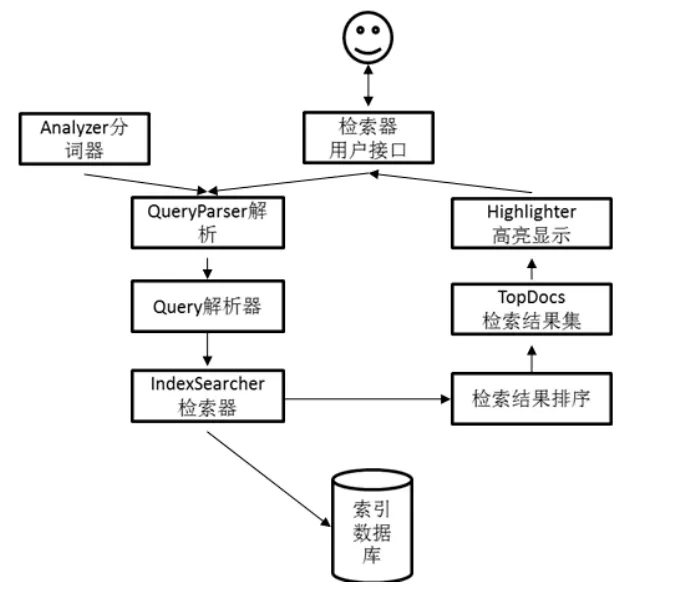
图4 检索器结构
2 网络蜘蛛的实现
2.1 网络蜘蛛爬行策略实现算法
互联网可以看成一个超级大的“图”,网络蜘蛛的遍历网页算法采用图的宽度优先遍历(BFS)算法,其爬行策略实现算法如下[5]:
1)将入口URL入队至待访问URL的队列中去。
2)URL从待访问URL队列出队,使用开源HTML解析库HTMLParser对给出的入口URL进行解析,判断抓取到的URL是否在已访问URL集合中,若不在,则将URL存储在待访问URL的队列中去(入队),若存在则什么也不做。
3)使用HTMLParser对出队的URL进行解析,解析该URL的标题、内容、关键词、创建时间等信息。
4)使用Lucene为HTMLParser解析到的网页信息创建索引。
5)出队的URL添加至已访问URL集合中去。
6)重复(2)~(5)的过程。
2.2 网络蜘蛛的具体实现
(1)数据结构:队列和散列表(哈希表)
首先要构建用于存储抓取到的URL待访问的URL队列,在构建队列时需要考虑以下两方面因素:
1)队列中将要存储的元素个数非常之多并且数量无法确定;
2)在队列的队头和队尾处经常进行删除和添加操作。
针对以上两点,使用java集合类LinkedList的链式存储结构来实现未访问URL队列。这个未访问URL队列主要用来存储爬虫抓取到的 URL,通过一系列的出队入队操作实现对网页的宽度优先遍历。
(2)要构建散列表。在根据未访问URL队列对URL进行抓取和解析的时候,还需要一个数据结构散列表来存储已经访问过的URL来避免对同一个URL的重复抓取和解析。在URL从未访问队列出队以后,首先,判断一下,它有没有在这个数据结构中,只有当该URL不在这个已访问URL集合中时才对其进行其他操作。否则,将该URL丢弃。这个数据结构需要具有以下两个特点:
1)结构中存储的URL不可以重复。
2)由于URL数量众多,考虑到查找性能问题,需要该结构能够快速地查找。
针对以上两点,采用Java集合类HashSet来实现存储已访问URL的散列表集合类。
这个已访问URL集合主要是记录网络蜘蛛已经访问过的URL,在网络蜘蛛访问一个从未访问URL队中出队的U RL时,首先判断一下这个URL是否已经在已访问URL集合中存在,不存在的时候再进行访问,这样可以避免对同一URL多次不必要的访问。
(3)网络蜘蛛抓取网页
HTMLParser是用一个纯java写的html解析库,它不依赖于其它的java库文件,主要用于改造或提取html。它能超高速解析html,而且不会出错。使用HTMLParser的HTML链接提取功能提取网页中的链接的过程如下:
1)创建过滤器,过滤a标签中的URL:NodeFilter filt er = new TagNameFilter("a");
2)创建解析器:Parser parser = new Parser();
3)使用 parser.setURL(url)和setEncoding()设置需要解析的URL和编码方式;
4)获取解析的结果:NodeList list = parser.extractAll NodesThatMatch(filter);
5)遍历得到的解析结果;
6)在将解析到的URL存入未访问URL队列之前需要对其进行一些检查,把一些错误的链接或者是无法访问的链接过滤掉。
3 索引器的实现
使用Lucene创建索引,Lucene是一个开放源代码的全文检索引擎工具包[6-8],即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。Lucene提供了五个基础的类,对文档进行索引,下面是使用Lucene为HtmlDoc实例创建索引的相关操作。
1)创建分词器,这里使用的是Lucene默认的分词器;
2)设置IndexWriter类的相关配置:
3)设置索引的保存路径:
4)创建 Lucene索引器:IndexWriter writer = new IndexWriter(dir,iwc);
5)创建Document对象:Document doc = new Document();
6)为Document对象添加HTMLField域;
7)添加 Document至索引器中去:writer.addDocument(doc);
8)关闭索引器:writer.close();
4 检索器的实现
4.1 使用Lucene执行检索
1)创建IndexReader对象读取索引器创建的索引;
2)创建分词器Analyzer对用户输入的字符串进行分词处理;
3)使用IndexReader对象创建检索器IndexSearcher;
4)使用分词器 Analyzer创建QueryParser对象,解析用户输入的检索字符串;
5)取得解析检索字符串返回的Query对象;
6)使用 Query对象执行检索将默认排序结果放置到TopDocs结果集;
7)得到检索结果总数量:hitsSize = results.totalHits;。
4.2 高亮显示检索结果
1)设置高亮显示html标签
2)创建高亮显示对象:Highlighter highlighter = new Highlighter(formatter,scorer);
3)设置高亮显示附近字符串大小:Fragmenter fragmenter = new SimpleFragmenter(200);
4)设置高亮:highlighter.setTextFragmenter(fragmenter);
5 检索测试
用户可以在检索器的文本框内输入需要检索的关键词,点击搜索按钮,检索器将自动显示与关键词相关的检索结果,搜索“上海车展”检索器返回检索结果效果。如图5所示:
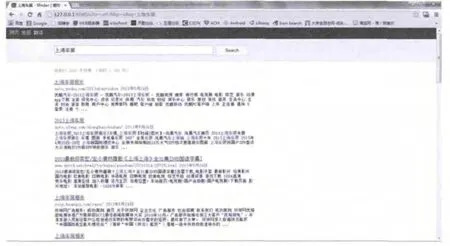
图5 检索结果示意图
6 总结
搜索引擎是一种信息检索服务系统,它可以帮助用户在互联网上快速地查找对自己有用的信息。通过网络爬虫抓取信息,然后在通过一定的技术对网页信息进行提取、处理,将抓取到的信息存放在索引数据库中,通过一些查询接口实现信息检索。本搜素引擎的设计与实现是基于全文搜索进行的,设计了网络蜘蛛、索引器和检索器的结构,并利用Jav a语言进行了搜素引擎的实现,通过检索实验,检索速度<=200ms,该搜索引擎是一个比较高效的检索工具,但是系统实现的网络蜘蛛并非真正意义上的全自动,而是必须给定网页入口并告诉网络蜘蛛要抓多少张网页,它才能正常抓取网页,同时检索策略有待进一步改进,以便进一步提升检索速度。
[1]孙宏.搜索引擎技术与发展综述[J].计算机光盘软件与应用,2012(14):10-15.
[2]李国芳.全文搜索引擎快速搭建的设计与实现[J].计算机与现代化,2012(11):18-21.
[3]克罗夫特(美).搜索引擎:信息检索实践[M].北京:机械工业出版社,2010:69-83.
[4]李浩.网络蜘蛛的研究与实现[J].科技信息,2012(26):18-23.
[5]陈建峡.基于PageRank的Lucene排序算法优化与实现[J].计算机工程与科学,2012(10):19-23.
[6]刘敏娜.基于 Lucene的中文分词技术改进[J].咸阳师范学院学报,2012(02):25-28.
[7]麦肯德利斯等(美).Lucene实战[M].北京:人民邮电出版社,2011:53-92.
[8]于天恩.Lucene搜索引擎开发权威经典[M].北京:中国铁道出版社,2008:134-182.
