基于控制区空间变异性的耕地质量监测样点布控方法
2014-01-22宋艳华毛含冰王令超杨建波
宋艳华,毛含冰,王令超,杨建波
(1.河南省科学院地理研究所,郑州450052;2.中国航空工业集团公司凯迈电子有限公司,河南洛阳471003)
0 引言
监测样点布设是实现对区域耕地质量空间监测的基础,可靠、高精度的抽样方法,是保证耕地质量监测精度的前提[1]。耕地质量受气候、土壤、地形以及利用水平和方式等因素的影响,具有空间变异性[2]。研究表明区域面积上影响耕地质量的多种因素平均值和变异程度常常受到监测尺度、监测方法和样点布局的影响[3-4]。因此,在监测手段相近,监测尺度一定的条件下,监测精度主要受观测样点数目和布局的影响[5-6]。监测样点过多,不但投入大,而且易产生信息冗余;监测样点过少,精度往往难以满足要求。即使确定了适宜的监测点数目,但由于耕地质量的空间变异性,传统的分析方法因为不能兼顾耕地质量空间变异特性,必然导致一些地方信息冗余,造成浪费,另一些地方由于信息不足难以达到要求的精度。因此只有根据耕地质量的空间变异情况,对研究区域进行耕地质量的合理分区,才能进行经济、合理的布点,从而才能以最小的投入获取最大的信息量[7-8]。为此,以河南省禹州市为研究区域,在农用地分等成果的基础上,在GIS技术支持下,利用经典统计学方法确定在一定抽样误差条件下的最优监测样点总数,再综合研究区耕地质量水平、利用水平、利用特征、收益水平等因素的空间分布对研究区进行综合控制区划分;计算各控制区内耕地质量的空间变异系数,并以此为依据实现监测样点在各控制区间的分配,以确定不同监测控制区内的样点数量;最后在各监测控制区内依据空间简单随机抽样进行样点空间布设。本研究为耕地质量监测提供了一种新的样点布控方法,经检验可显著降低估计误差。
1 研究区耕地质量概况
禹州市位于河南省中部,地处伏牛山脉与豫东平原过渡带,黄淮平原区和豫西山地丘陵区的交界处。全市土地总面积约为1 393.01 km2,地表形态复杂,地势西北高,东南低,海拔高程由西部的1 150 m降低到东南部的100 m,山地、丘陵、岗地和平原等地貌类型齐全,4种地貌类型各占土地总面积的13.90%,14.70%,30.60%和40.80%。禹州市属北暖温带大陆性季风气候区,年平均气温14.4℃,年平均降水量650 mm。标准耕作制度为一年两熟(小麦、玉米)。
本研究以禹州市2011年1∶1万耕地质量等级数据为基础[9],结合DEM 数据、土壤类型图、2011年各村典型地块投入产出数据和各乡镇农业生产及社会经济特征等数据进行监测控制区的划定,并依据各监测控制区的空间变异性进行监测样点的空间分层布控。
2011年禹州市耕地自然质量等别分布(图1)。2011年禹州市耕地面积888.06 km2,占土地总面积的64%,11等以上等别较高的耕地分布在禹州市东部、东南部和中北部颍河两岸,这些地区也是禹州市的平原和岗地区,是该市耕地质量最好、粮食产量最高、耕地最为集中的区域;10等及以下耕地分布在西部和北部山区,这些区域耕地分布破碎,面积较小,主要以山地和坡地为主,粮食产量相对较低。
2 抽样方法介绍
由图1看出,禹州市耕地质量在空间分布上虽然存在同等耕地相对集中分布的趋势,但由于不同区域间耕地利用类型、自然条件等的差异,使得耕地自然质量等别也存在显著的交叉分布趋势,再加上不同区域间耕地分散程度的差异,因此更加适合采用空间分层抽样方法进行样点布设。

图1 禹州市耕地自然质量等别分布Fig.1 Distribution of the cultivated land physical quality grades in Yuzhou County
空间分层抽样法将空间研究区域按其空间属性特征分成多个互不重复的类型或分层,先计算研究区域总体样本量,再利用一定的分配方法将样本分配到每个层中,最后在每个层内利用空间随机抽样法布设样点。
2.1 确定最佳样本数
研究区2011年耕地图斑的质量数据可以作为区域耕地质量监测样点布设的先验知识,通过验证研究区内耕地图斑的质量数据分布符合正态分布,耕地质量具有显著的空间正相关性。空间分层抽样的最佳抽样总数n采用Neyman法计算[10],Neyman法与纯随机采样计算法相比,可以更合理地利用有限的资金获得较好的实验精度。在各分层耕地面积单一指标的基础上,进一步考虑各层数据的变异情况,根据变异情况调整随机抽样法在各层之间的布设数量,以达到在有限资金条件下更优的样点代表性。Neyman法计算公式如下:
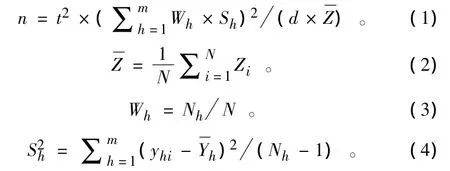
式中:n为总抽样数;t为相应水平下的t特征分布值;Wh是h层的权重;Sh为h层标准差;d为相对误差为耕地质量图斑的总体均值;Zi为第i块耕地的耕地质量值;N为研究区总耕地图斑数;Nh是h层中所有的耕地图斑数;yhi为h层中第i块耕地的质量值是h层均值。
2.2 监测样点在各空间分层间的分配
通常,分层抽样各层分配的抽样数nh采用权重法确定,计算公式如下:

基于权重法的空间分层抽样中每层样本数量主要由各层的个体数量或面积来确定,考虑到每一层个体在空间上具有不同的变异程度,变异程度小表明个体间相似度大,仅需较少的样本即可代表,反之,变异程度大表明个体差异显著,需要更多的样本才能表达总体,因此可以采用各分层耕地图斑的空间变异系数对各分层的抽样数量进行修正,即采用基于各分层空间变异系数的变异系数法为各层分配样本:
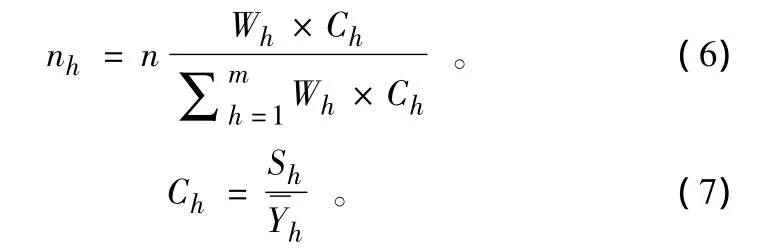
式中:nh为h层的采样点数目;Ch为h层变异系数。
3 基于综合属性的监测控制区分层
传统的分层将单个属性值相对近似的尽可能分到同一层,根据这个分层标准对空间对象分层时,在同一层的对象属性值相差可能很大,如基于乡镇的空间分层;或虽然同一层对象的属性值差别较小,但空间分布却破碎分散,如基于耕地质量等别的空间分层。从图1看出,禹州市各自然质量等别的分布虽然存在集中分布的规律,但各等别之间交叉分布的趋势也相当明显,单纯以耕地质量等别作为分层依据进行分层布设样点,恐难准确代表全县的耕地质量信息。因此,以禹州市耕地自然质量空间分布为基础,综合考虑影响耕地等级变化的自然、利用水平、收益水平以及耕地所在区域的区位、功能定位和土地管制措施,依主导因素原则和区域分异原则,分别划定多种监测背景分区,最后将各种监测背景分区叠加综合,得到最终的监测控制区,并以此作为分层布设监测样点的依据。在监测控制区内,耕地的自然条件、利用特征相似,利用水平和收益水平相当,在不同的监测控制区间则差别显著。因此,基于综合属性的监测控制区分层考虑了影响耕地质量因素的属性信息、耕地图斑的空间信息,又兼顾了同一层对象的空间相连性,更适合用于对研究区耕地质量的空间分层。
监测控制区划分的技术路线如下:在资料收集和数据整理基础上,根据气候、地貌、土壤等自然因素划分耕地“自然质量分区”;根据种植业结构、耕地利用类型、每个行政村至少一个代表地块的主要作物产量水平划分耕地“利用水平分区”;根据每个行政村至少一个代表地块的主要作物“投入—产出”和效益分析划分耕地“收益水平分区”;根据乡镇耕地利用情况、农业人口、农业产值、农民人均纯收入、人均耕地面积、粮食作物播种面积、田块破碎化程度、有效灌溉面积、机耕机播面积等耕地利用特征因素,划分“土地利用特征分区”。上述4个分区统称耕地监测“监测背景分区”(图2)。各监测背景分区的区域划分以自然裂点法为基础,结合村界进行划分,分区边界不打破村界。
将农用地分等图与“土地利用特征分区”“自然质量分区”“利用水平分区”和“收益水平分区”叠加,形成了几十个区域。将初步划定的区域合并、调整,最终形成了9个耕地等级野外监测“综合分区”,“综合分区”即为布设监测点、确定监测点监测指标体系的“监测控制区”(图3)。
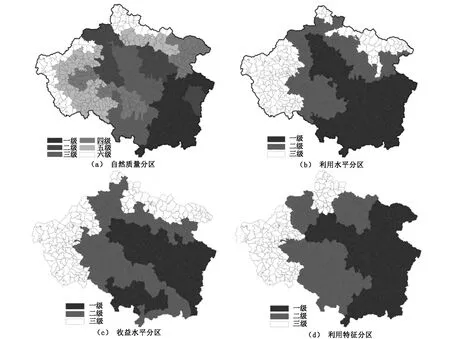
图2 禹州市耕地质量监测背景分区Fig.2 Background distribution regions of cultivated land quality monitoring in Yuzhou County

图3 禹州市耕地质量监测控制区分布Fig.3 Distribution of cultivated land quality monitoring control regions in Yuzhou County
4 监测样点布设
4.1 确定样本容量
通过统计和计算,禹州市2011年共有耕地图斑17 286个,耕地自然质量等指数总体标准差为413,总体平均值为2 277,总体变异系数为18.12。根据公式(1)~(4),在95%的置信度水平下,相对误差分别为10%和20%时,计算得出禹州市最佳抽样数分别为105个和53个。分别依据权重法(公式(5))和变异系数修正法(公式(6)~(7))为各控制区分配样点(表1)。从表1中看出:①在相同的置信度水平下,相对误差越小所需要的样点数越多。考虑到采样成本和研究目标,本研究以20%的相对误差进行不同布设方法间样点对研究区耕地质量估算精度的对比分析。②变异系数调整法与权重法的样点分配结果差异显著。权重法对耕地图斑权重最高的二区分配了26个样本,超过占总样本数的50%,但由于二区的变异系数相对较小,在所有9个指标区中位居倒数第二位,说明该区内耕地质量差别小,仅需要较少的样本即可代表整个区域,因此变异系数法为该区分配了11个监测样点,比权重法减少了近60%。同样,一区按照权重应被分配7个样点,但由于其变异系数是所有控制区中最小的,即一区中耕地质量等指数的空间差异性最小,仅需2个样点即可代表。五区权重不足2%,权重法仅分配了一个样点,但该区的变异系数为9个控制区中最高,因此需要增加样点,以提高对该控制区内耕地质量信息的代表性。六区权重18.58%,按照权重计算,该区应分配9个样点,但由于该区的变异系数较高,为所有指标区中变异系数第二大的区域,说明该区耕地图斑的质量之间存在较大差异,需要增加样点,经变异系数修正该区被分配了21个样点。

表1 基于控制区分层的分层抽样结果Tab.1 Sampling results based on the monitoring control regions
为了检验综合控制区分层的科学性,本研究也进行了在相同的置信度水平和相对误差下以自然质量等别直接作为分层依据的样点分层布设方案(表2)。
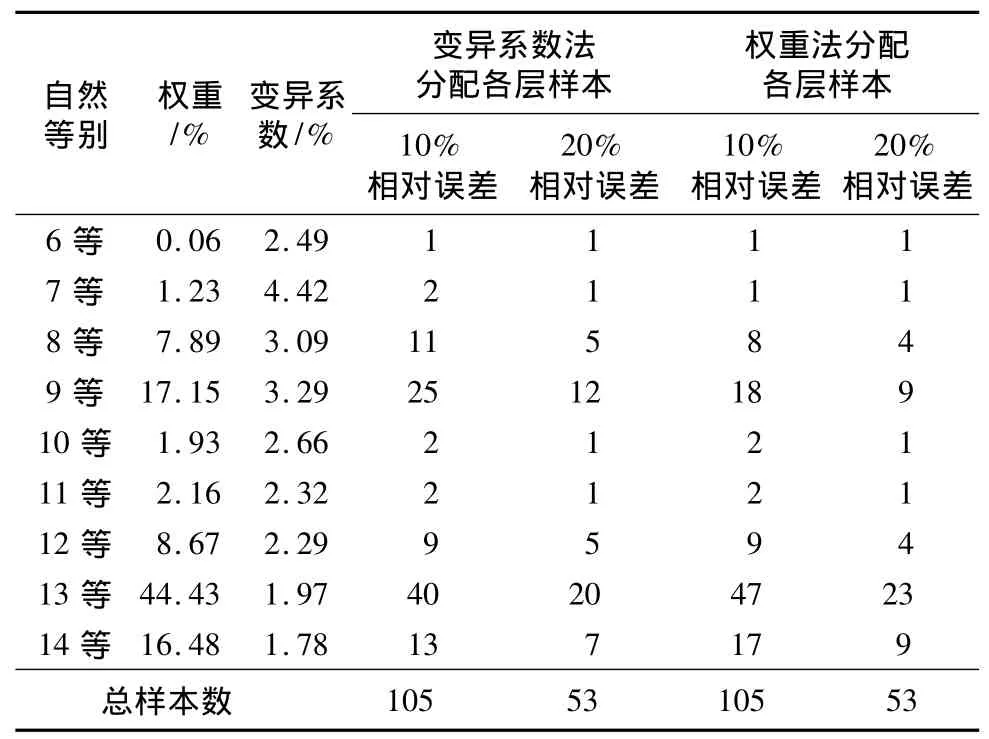
表2 基于自然质量等别的分层抽样结果Tab.2 Sampling results based on the physical quality grades of cultivated land
对比表1可以看出,表2中各分层的变异系数均较小且各层之间差别不大,原因是表2直接以耕地质量自然质量等别为分层依据,每层的耕地图斑均为同一个自然质量等别,等指数之间的变异性自然较小,因此,该表中权重法和变异系数修正法获得的各层样点数量差别不大。
4.2 不同样本布设方案的抽样精度评价
为了对比不同抽样方案的精确度,对表1和表2中的4种以监测控制区和自然质量为分层条件下的权重法和变异系数法样点分配方案,再加上常规的简单空间随机抽样共5种样点布设方案分别进行了样点空间布设。在分层抽样中,各层样点的布设方法为随机抽样法,5种方案的样点布设结果见图4。
借助地统计学方法,对5种方法抽样结果进行Kriging插值,以便评价抽样结果的精度。Kriging方法是一种非常重要的最优、无偏空间抽样插值方法,首先考虑的是空间属性在空间位置上的变异分布,确定对一个待插点值有影响的距离范围,用此范围内的采样点估计待插点的属性值[11]。经检验,禹州市耕地质量分布满足正态分布,符合采用Kriging插值的要求。采用普通克里金法(Ordinary Kriging)对抽样样点的耕地质量进行空间内插。计算插值结果的均方根误差(RMSE)作为样本有效性的评价指标[12],总体上,RMSE的值越小,样点的预测结果越理想。表3是5种插值结果精度对比表。

表3 不同布局样点下克里格插值估测误差Tab.3 Kriging estimation error of 5 kinds of sampling methods
根据表3可以得出:①自然等分层抽样法的RMSE最大,大于简单空间随机抽样,原因在于同一个等别的耕地在空间上往往分布较为分散,且常存在多个等别交叉分布的情况,以自然等别进行分层无法体现耕地空间分布规律,造成插值误差较大,故直接以耕地自然等别进行分层并不合适;②空间简单随机抽样法的RMSE相对较高,原因是研究区耕地质量总体空间变异系数较大,达18.12%,不适宜采用空间简单随机抽样;③ 控制区分层抽样法的RMSE最小,原因是综合控制区既充分考虑了耕地质量的空间分布,又综合了影响耕地质量的自然、社会、经济等因素的空间分布,控制区内耕地质量及其影响因素差别较小,而控制区之间则存在显著不同,因此利用综合控制区对耕地质量进行分层更为合理;④自然等分层和控制区分层方案下,各分层样点的两种分配方法中变异系数法比权重法分配方案精度更高;⑤由于自然等分层和控制区分层得到的各分层之间变异性不同,前者各层变异性相当,空间变异分配方案与权重法分配方案的RMSE相比有所降低,但并不显著,而控制区分层的各层样本空间变异性差别较大,空间变异分配方案与权重法分配方案的RMSE有显著降低,降低幅度超过40%,因此,在各分层之间存在显著空间变异性的情况下,基于变异系数的分层抽样分配样点法会比简单权重法的RMSE显著减小,即显著提高抽样样本对耕地质量总体的代表性。
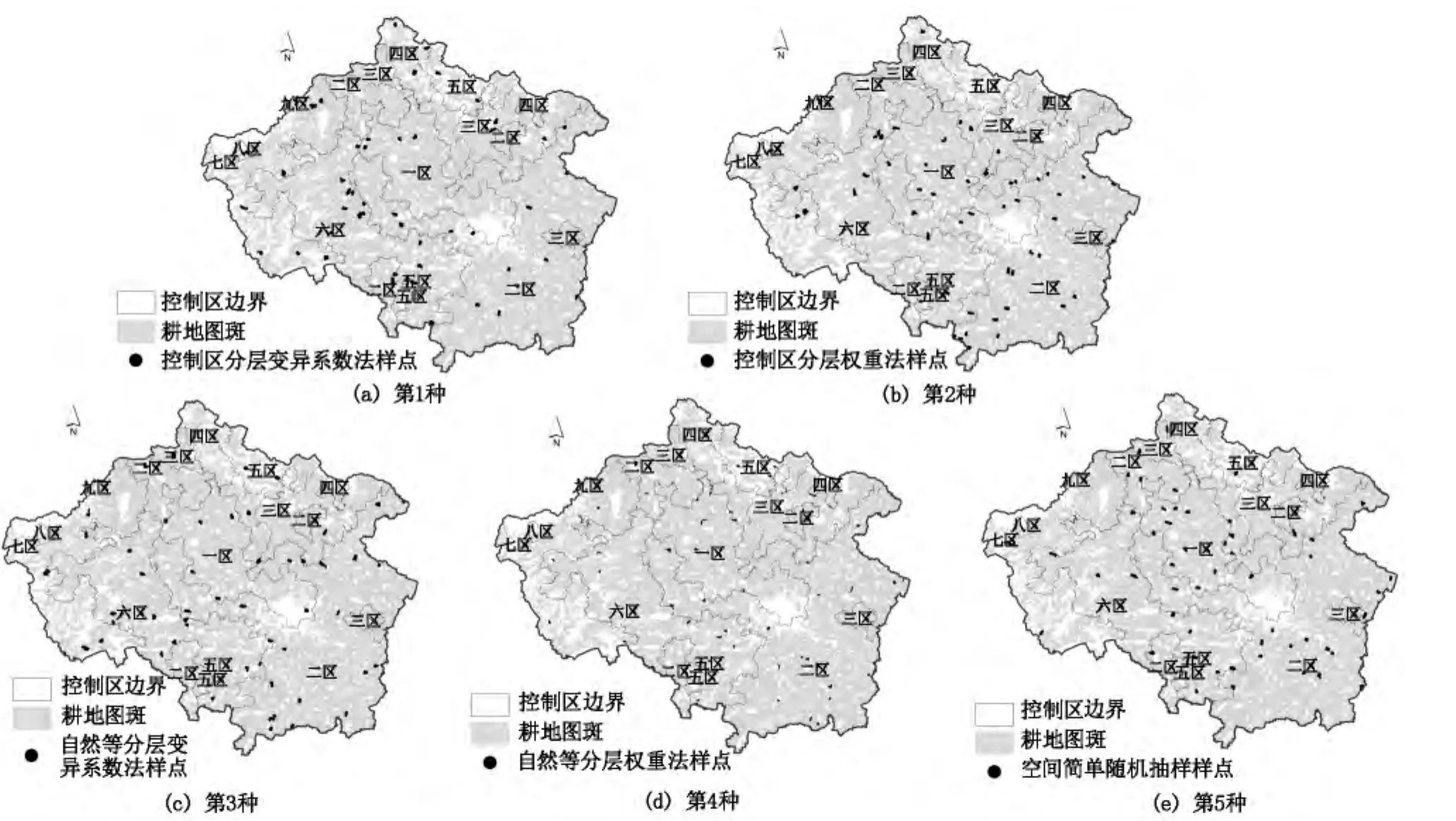
图4 基于5种样点的布设结果Fig.4 Sampling results of 5 kinds of sampling methods
为了对比控制区分层抽样法在抽样精度方面与常规法的区别,本研究又用随机抽样法随机抽取了200,500,1 000,2 000个样点,并分别计算了其RMSE误差(表4)。

表4 不同样本个数下克里格插值估测误差Tab.4 Kriging estimation error of different sample size
由表4看出,在控制区分层基础上的变异系数法布设的53个样点的RMSE误差小于简单空间随机抽样200,500,1 000个样本,与2 000个随机样本的RMSE误差相近,表明该抽样法可以显著降低样本数量、提高估算精度。
5 结论与讨论
1)抽样方案的选择应综合考虑抽样总体的空间分布,对于空间变异较大的区域,宜采用空间分层抽样进行样点布设。
2)耕地质量受多种因素的影响,因此对耕地质量图斑的空间分层应是既考虑耕地质量的空间分布,又结合影响耕地质量多种因素的综合监测控制区分层法。空间分层的合理性会显著影响空间分层抽样的精度,不合理的空间分层,抽样精度反而低于简单空间随机抽样。
3)样点总数相同的情况下,各层间样点数量的分配方案会显著影响预测精度。基于各分层变异系数修正法比权重法的抽样精度高,但各层间空间变异系数相似的情况下,精度提升幅度不显著,而对于各层间空间变异系数差异较大时,变异系数修正法会显著提高抽样精度,因此,变异系数法样本分配方案更适用于分层间空间变异性较大的分层数据。
4)为了消除人为主观因素对不同样点布设方案的影响,在所有分层抽样的各分层中均采用了空间随机法进行样点布设,并直接将该初次布设结果作为最终的布设方案进行分析。但在实际工作中还应对初次布设方案的样点进行微调以确保研究区的每种土壤类型、每类地形、每个耕地质量等别、每种耕地类型中均有监测样点存在;同时对研究区监测年度内的土地开发整理项目区、农业综合整治、农田水利建设和灾害损毁等造成耕地质量突变的区域均应布设短期监测动态样点,主要用以对项目建设前后和灾毁前后突变区域耕地质量的更新评价。
[1] 刘建红,朱文泉.耕地变化空间抽样调查方案的精度与效率分析[J].农业工程学报,2010,26(10):331-336.
[2] 王倩,尚月敏,锋锐,等.基于变异函数的耕地质量等别监测点布设分析——以四川省中江县和北京市大兴区为例[J].中国土地科学,2012,26(8):80-86.
[3] 曾宏达,杨玉盛,陈光水,等.不同尺度下森林土壤特性空间变异与取样策略[J].亚热带资源与环境学报,2008,3(3):32-39.
[4] 王淑英,路苹,王建立,等.不同研究尺度下土壤有机质和全氮的空间变异特征——以北京市平谷区为例[J].生态学报,2008,28(10):4957-4964.
[5] 杨建宇,汤赛,郧文聚,等.基于Kriging估计误差的县域耕地等级监测布样方法[J].农业工程学报,2013,29(9):223-230.
[6] 陈飞香,戴慧,胡月明,等.区域土壤空间抽样方法研究[J].地理与地理信息科学,2012,28(6):53-56.
[7] 王景雷,孙景生,刘祖贵,等.作物需水量观测站点的优化设计[J].水利学报,2005,36(2):225-231.
[8] 姜城,杨俐苹,金继运,等.土壤养分变异与合理取样数量[J].植物营养与肥料学报,2001,7(3):262-270.
[9] 宋艳华,王令超,樊雷,等.基于空间传递的耕地质量等别追溯法汇总技术研究[J].地域研究与开发,2013,32(6):106-110.
[10] 杨奇勇,杨劲松.基于GIS的土壤盐分空间变异及盐分监测样点合理布设研究[J].灌溉排水学报,2011,30(2):10-14.
[11] Griffith D A,Bennett R J,Haining R P.Statistical Analysis of Spatial Data in the Presence of Missing Observations:A Methodological Guide and An Application to Urban Census Data[J].Environment and Planning A,1989,21(11):1511-1523.
[12] 阎波杰,潘瑜春,赵春江,等.区域土壤重金属空间变异及合理采样数确定[J].农业工程学报,2008,24(S):260-264.
