基于说话人特有特征集的GMM和i-矢量方法的说话人识别
2014-01-17沈思秋齐彦云
沈思秋,吕 勇,杨 芸,齐彦云
(河海大学 计算机与信息学院,江苏 南京 210096)
高斯混合模型(Gaussian Mixture Modeling:GMM)[1]和隐马尔可夫模型(Hidden Markov Modeling:HMM)[2]已经被成功应用于多种分类识别中,最大似然估计(MLE)和期望最大(EM)算法能有效地估计模型的参数。然而,模型域方法存在一个明显的缺陷,那就是被建模的模型是独立的,也就是说,当为一个类建立一个模型后,这个模型不考虑其它类的数据。换句话说,其它类的数据不能够被用来优化分类识别效果。因此,建立这样的模型会增大误识率。在数据训练过程中,如果能获取本类特有的特征,且利用这个特征能有效地识别出其他类的数据,这样就可以提高分类器的分类识别能力。
现在的很多研究中,通过增强分类器对其它类数据的识别能力的方法来提高识别性能的文献主要有以下两类:
1)除去两个类所共同拥有的且相近的特征。
2)调整模型的参数,使得它们在特征域中能很好的分开。
一些方法被提出来用以提高GMM的分类能力,通用背景的高斯混合模型 (Universal ackground Model-Gaussian Mixture Model:UBM-GMM)是其中一种已经被广泛使用的方法。UBM模型的建立过程使用了所有可能的说话人的数据。在训练过程中,用最大后验概率(MAP)算法对说话人的特定模型进行调整,使它适应于UBM。
文献[3]提出了基于最小分类误差(Minimum Classification Error:MCE)的算法。在这个方法中,所有的说话人的声音都被用来估计别的说话人所属的类,这是一个比较有效的方法。然而,当说话人数非常多的时候,这种方法因计算量迅速增大而变得不适用。文献[4]指出,i-矢量方法是说话人分类识别领域中有效的方法,它能将输入的高维数据变为低维数据,且保留住输入数据的相应信息,文献[5]中的联合因子分析框架就用到了这种方法。
当存在两个发音相似的说话人时,这篇文章在音素层次上对他们进行区分。文中首先提取出说话人特定的特征集,再用基于GMM和i-矢量的方法对说话人进行识别。实验结果表明,这篇文章提出的方法的识别准确率要优于传统的基于GMM以及i-矢量的方法。
本文剩余部分组织如下:下一节强调了说话人特定特征集的获取;所使用的基于GMM的方法在第2节进行介绍;第3节介绍i-矢量方法;第4节介绍了本文的实验步骤;第5节对实验结果进行了分析与讨论;最后一节对全文进行总结。
1 说话人特定特征集的提取
文献[6]提出了一种基于高斯混合模型(GMM)的方法,该方法提取出每一个类独有的特征,并只用该特征对说话人进行识别。在测试过程中,提取出每一个类别特有的特征矢量,从而提高识别器的识别性能。该方法的其中一个缺陷是:如果无法从用于测试的发声中找到合适的特征,则识别结果的准确率就无法得到保证。该方法的另一个缺陷是:在测试阶段提取与鉴定每个类别所独有的特征的过程中存在大量运算,因为每个发声中可能还存在其它类别的特征,要将其排除,故这会降低系统的实时性。如果一个说话人的声音中只包含了本类别所特有的特征,那么运算消耗的时间可以减少,但在实际过程中,出现这种情况几乎是不可能的。
本文研究了说话人特有的特征集对说话人识别结果的影响,主要工作分为以下3个步骤:
1)为每一个说话人找出与他发声相似的其他说话人(称为干扰者)。
2)将每个说话人的发声和他的干扰者的发声相比较,提取出他特有的特征集。
3)将上一步结束后得到的结果用于测试识别。
文献[7]用TIMIT语音集对以上方法的结果进行了实验,但在训练与测试过程中,作者只考虑了每个人仅存在一个干扰者的情况。该文献的方法产生误识率的一个原因是:该文章用对数似然值的均值来产生不同的声学特征集,如果某些音素中的样本较少,则这种方法产生的结果不可靠。该文献所使用的TIMIT语音集中,音素含有的样本很少,某些音素甚至只有2个样本,因此,通过对数似然值产生的声学特征集非常不可靠,有时甚至是错误的。为了避免这种情况产生,可以建立自己的语音库。本文建立了自己的语音库,确保了每个音素有足够的样本数(至少有30个)。
此外,在文献[7]中,只考虑了每个人仅存在一个干扰者的情况。另一方面,如果每个说话人存在不止一个的干扰者,则可以通过与所有这些干扰者的发声逐个进行比较的方法提取出这个人所特有的特征集。讲到这里,某些人可能会产生疑惑,他们可能认为通过这种方法提取到的特征集并不仅仅属于该说话人的,它们也是这位说话人的干扰者的特征。在一个闭集中考虑有n个人的说话人识别过程,即每个说话人是这n个人中的其中之一,每个人所特有的音素可以通过以下两种方法来获得:
1)将剩余的n-1个人全都视为干扰者。
2)从剩余的n-1个人中选取一部分作为干扰者。
若使用第一种方法,则运算量相对较大,此外,由于其他的n-1个干扰者的发声并不一定与该说话人的发音有相似性,故本文使用第二种方法。
当要提取某个说话人的音素特征时,这个人称为目标说话人,将目标说话人的特征与所选取的干扰者逐个进行比对,比较两人发声中音素和模型的相似性就可以得到目标说话人特有的特征。具体过程如下:
设S为目标说话人提取到的特征,即

假设M、N为所选取的S的两个干扰者,由于他们的发声与S相似,故M发声中的某些特征会跟S的某些特征相同。设M中有如下特征跟S的相同:

N中有如下特征跟S的相同:

则通过逐一比较,可得到说话人特有的特征集为:

可见,S2中的特征参数已经排除了si和sk,即这些参数是说话人S所特有的。得到S2后,再用基于GMM和i-矢量的方法对说话人进行识别。
本文将美尔频率倒谱系数(MFCC)作为特征参数。研究表明,人耳对声音的频率分辨能力是不均匀的,对低频的分辨率较高,对高频的分辨率较低[4]。人耳对频率在1 kHz以下的声音的感知能力遵循线性关系,而对频率在1 kHz以上的声音的感知能力遵循的是对数频率坐标上的线性关系。MFCC考虑到了人耳的这种特点,它先将频谱转变为美尔频标的非线性频谱,接着再转换到倒谱域上。美尔频率Mel(f)与实际频率f间的关系式如下:
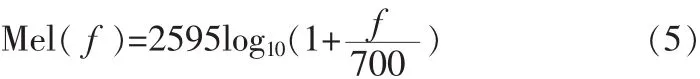
若将美尔频率在整个频带上进行等间距划分,则可得到一系列中心频率。再以每个中心频率为中点,以上一个和下一个中心频率为截止频率,构建一系列三角带通滤波器,再将其变换到实际频域中,就可得到图1所示的美尔滤波器组。

图1 美尔滤波器组Fig.1 Mel filter banks
美尔频率倒谱系数的提取步骤框图下所示:
1)对输入的语音信号进行数字化以及加窗、分帧等预处理过程,得到各帧的时域信号x(n)。
2)对时域信号x(n)进行离散傅里叶变换,得到每帧信号的短时幅度频谱X(K):

其中,N为帧长。
3)用美尔滤波器组对求得的短时幅度频谱X(K)进行加权求和,得到美尔谱S(m):

其中,S(m)为第m个美尔滤波器的输出,M为滤波器个数,Wm(k)为第m个美尔滤波器在频率k处的加权因子。
4)对美尔滤波器组的所有输出取对数,并且作离散余弦变换(DCT),就可得到 MFCC:

其中,L是MFCC的维数。
由于本文是在音素层次上提取说话人发声的特征,故需要将发声进行分帧处理,使得每帧语音信号含有若干个音素,再求取各帧信号的MFCC。
2 使用到说话人特定音素的基于GMM的方法
首先介绍一下GMM模型的基本概念。基于GMM的说话人识别的原理是对每一个说话人建立一个高斯混合模型 (概率模型),该模型的参数由说话人的特征参数的分布决定的,因此,表征了说话人的身份。为了方便,假设每个人有相同形式的概率密度函数,但每个人的概率密度函数中的参数不同,这时说话人模型就是在特定概率密度函数形式下的一组参数。
对M个高斯概率密度函数进行加权求和,即可求得M阶混合高斯模型(GMM)的概率密度函数,即:
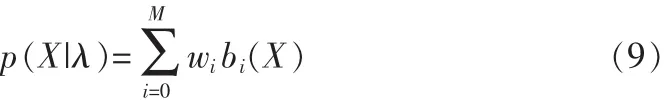
其中,M是模型的阶数,X是一个P维随机向量,wi(i=1,2,…,M)代表混合权重,bi(X)代表子分布,每一个子分布是P维的联合高斯概率分布,表达式如下:

上式中的右边第三项,即协方差矩阵可以是对角阵或一般的矩阵。为了简化计算过程,本文使用对角阵,即:
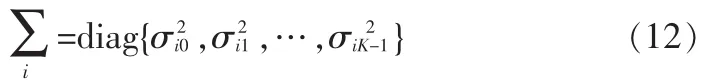

其中,Xm和uim分别是X和ui的第m个分量。
基于GMM的说话人识别过程主要包括模型训练和说话人识别这两个过程。在训练阶段,将说话人发声的特征通过参数估计,为每个说话人确定一组参数,从而建立模型。在说话人识别阶段,通过分析测试语音的特征与被建立的模型的相似度来进行识别。
以上介绍的是传统的基于GMM的说话人识别方法。在模型训练阶段,需要用说话人发声的特征参数进行参数估计,本文用于估计的特征参数是每个说话人他自己所特有的,他所特有的特征参数的提取方法在上一小节中作了详细说明。
3 i-矢量方法
在基于i-矢量的方法中,一个长度可变的语音向量被投影到一个低维的线性子空间中,这个子空间的基是根据EM算法估计出来的。话语的这种低维表示方式被称为i-矢量。传统的联合因素分析方法是分别为说话人的发声本身和其它可变因素各找一个子空间,其中,可变因素的空间中包含着一些信息,这些信息可以用来区别多个说话人。基于这个原因,文献[8]的作者用一个空间来模仿这两个可变因素,他将这个空间称为总可变空间。他的基本假设是:说话人本身以及其它因素所依赖的GMM矢量M可以用以下模型来表示:

其中,m是说话人本身以及其它因素所依赖的矢量T是一个低秩的矩阵,代表总可变空间降维后的部分,w是一个标准正态分布矢量。
T被称为总可变矩阵,向量w中的元素代表在降维后的空间中各个说话人。这些特征矢量便是身份矢量(i-矢量)。
本文所使用的i-矢量不是一般的特征矢量,而是每个说话人他自己所特有的特征矢量。T可采用文献[9]中的EM算法估计得到,w可根据文献[9]中的MAP算法估计得到。
4 实验步骤
在本文的实验中,创建了自己的语音库,从TIMIT语音库中收集了142个英文句子,每个句子中的音素至少有30个(英语中共有45个音素),如果将静默也看成是一个音素,那么本文共涉及到46个音素。在实验中,用16 kHz的采样频率来录制语音,选取50个人作为说话人(其中43个女人,7个男人),他们的年龄都在20-35岁之间,他们的每个发声持续时间大约为3秒钟,用文献[10]中的Forced Viterbi alignment算法对整个语音数据在音素水平上进行分段。
对于每个说话人说的142个句子中,130个句子用于训练,12个句子用于测试,为每个说话人训练出一个含有128个混合元素的高斯混合模型,提取出语音的美尔频率倒谱系数(MFCC)作为特征。为了找到干扰者,用所有说话人的模型对每个说话人的130个训练发声进行测试,这里每个说话人的干扰者数量为3,根据有序对数似然值来找出这3个干扰者。找出所有说话人他们各自的干扰者后,就得到了一份干扰者清单。
为了得到每个说话人特有的特征集,在训练过程中要用说话人本身以及他的干扰者的模型对他及其干扰者的音素进行检测。每一个音素的平均对数似然值是通过该说话人跟他的干扰者计算出来的。根据有序的平均对数似然值,可认为起初的20个音素是不同的声学音素,这样可得到每个说话人与他的干扰者所不同的音素。重复这个过程,直到遍历完所有说话人的音素,为了减小计算量,提取出每个人20个音素中的前6个音素作为该说话人特有的音素,对其进行特征提取,便可得到说话人特有的特征集。
在基于高斯混合模型的方法中,对于每个说话人,对该说话人特有的特征参数进行参数估计,为每个说话人建立一组参数,参数个数为128,从而为他建立了模型。用同样的方法对该说话人的干扰者也进行同样的建模过程。在基于i-矢量的方法中,用说话人特有的特征参数作为i-矢量,为每个说话人建立一个含有128个参数的UBM,并且把每一个人的142个句子集中在一起,总可变矩阵可通过集中起来的数据估计得到。i-矢量的维数设为400,它通过摘录每个说话人的测试用的发声来获得。
用本文提出的上述方法来对说话人进行识别时,误识率要比传统的基于GMM和i-矢量的方法低,具体对识别结果的分析见下节。
5 实验结果分析
为了获得说话人的特征,要求用于测试的每个发声至少含有6个因素,每个因素的持续时间大约为80 ms,故将每个测试语音分为一帧帧时间长度为500 ms的信号。
第一组实验不考虑噪声的影响。在测试人数为50人、不含噪声的情况下,传统的基于GMM的方法和使用说话人特定特征集的基于GMM方法的识别结果如表1所示。

表1 传统GMM方法和本文方法识别结果Tab.1 Traditional methods of GMM and the proposed method of recognition results
从表一可见,使用了说话人特定的特征集后,能够使基于GMM的说话人识别的误识率降低3.9%.
表二显示了在不含噪声的情况下,传统的基于i-矢量方法和使用了说话人特定特征集的i-矢量的说话人识别结果。

表2 传统i-矢量方法和本文方法识别结果Tab.2 Traditional methods of i-vector and the proposed method of recognition results
从表2可见,使用了说话人特定的特征集后,能够使基于i-矢量方法的说话人识别的误识率降低4.6%.
对比表一和表二中的第一种方法,可以发现在不考虑噪声的环境下,无论是哪种方法,当使用了说话人特定的特征集后,识别的准确率都会提高。
下面的第二组实验显示了在信噪比分别为0 dB、10 dB、20 dB和30 dB的情况下,本文的方法和传统的基于GMM和i-矢量方法各自的识别结果。图2显示了本文使用的基于GMM方法和传统的基于GMM方法在各种信噪比下的识别结果。
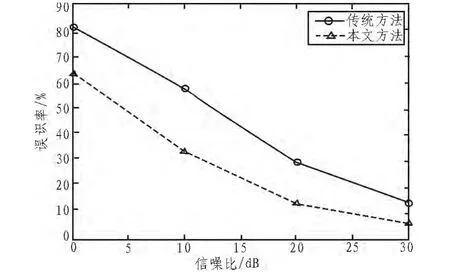
图2 本文方法和传统的基于GMM方法的结果比较Fig.2 The comparison of results of the proposed method and traditional methods based on GMM
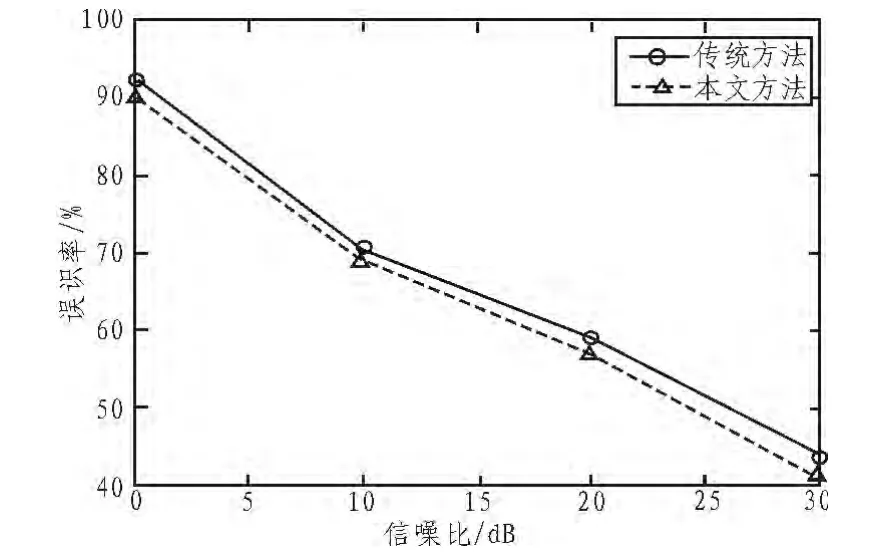
图3 本文方法和传统的i-矢量方法的结果比较Fig.3 The comparison of results of the proposed method and traditional methods based on i-vector
通过第二组实验结果可以发现,当使用了说话人特有的特征集后,无论采用基于GMM的方法还是基于i-矢量的方法,识别结果都要优于相应的传统的方法。此外,也可以发现基于GMM的方法的结果要明显优于基于i-矢量方法的识别结果。
6 结 论
本文通过使用说话人特有的特征参数并用基于GMM和i-矢量的方法来对说话人进行识别。实验结果显示,无论是在纯净环境下还是在含有噪声的环境下,本文方法的误识率均要低于传统的基于GMM和i-矢量的方法,即识别的准确率有了提高。
但是,通过第二组实验可以发现,当得到了说话人特有的特征集后,若采用基于GMM的方法,则在信噪比较高时,可以得到较为理想的识别结果,但是当信噪比较低时,识别结果同样得不到保证。因此,如何提高在低信噪比环境下的识别准确率是接下去要研究的问题。
[1]Kim W,Hansen JHL.Feature compensation in the cepstral domain employing model combination[J].Speech Commun 2009;51:83-96.
[2]Lü Y,Wu H,Zhou L,et al.Multi-environment model adaptation based on vector Taylor series for robust speech recognition[J].Pattern Recognition,2010,43(9):3093-3099.
[3]Juang B H,Chou W,Lee C H.Minimum classificatio n error rate methods for speech recognition[J].IEEE Trans.on Speech and Audio Processing,1997,5(3):257-265.
[4]Dehak N,Kenny P,Dehak R,et al.Front-end factor analysis for speaker verification[J].IEEE Transactions on Audio,Speech, and Language Processing,2011:788-798.
[5]Kenny P,Boulianne G,Ouellet P,et al.Joint factor analysis versus eigenchannels in speaker recognition [J].IEEE Transactions on Audio, Speech and Language Processing,2007:1435-1447.
[6]Arun Kumar C, Bharathi B,Nagarajan T.A discriminative GMM technique using product of likelihood Gaussians[J].IEEE TENCON,2009.
[7]Bharathi B,Vijayalakshmi P,Nagarajan T.Speaker identification using utterances correspond to speaker-specific-text[J].IEEE Students technology symposium(Techsym),2011.
[8]Dehak N,Dehak R,Kenny P,et al.Support vector machines versus fast scoring in the low-dimensional total variability space for speaker verification [J].in INTER-SPEECH,Brighton,2009.
[9]Glembek O,Burget L,Matejka P,et al.Simplification and Optimization of i-vector extraction[J].In proceedings of IEEE International conference on Acoustics, Speech, and Signal Processing,2011:4516-4519.
[10]Brugnara F,Falavigna D,Omologo M.Automatic segmentation and labeling of speech based on hidden markov models[J].Speech Com-munication,1993,12(4):357-370.
