基于TCAM的低能耗正则表达式匹配算法
2014-01-06丁麟轩黄昆张大方
丁麟轩,黄昆,张大方
(1. 湖南大学 信息科学与工程学院,湖南 长沙 410082;2. 中国科学院 计算技术研究所,北京 100190)
1 引言
近年来,随着网络应用的日益增多,网络安全面临着越来越严峻的挑战。网络入侵检测与防御系统(NIDPS, network intrusion detection/prevention system)是网络安全防御的主要手段,它通过实时监测网络流量,检查和阻止网络攻击[1]。深度分组检测[2](DPI, deep packet inspection)是 NIDPS、防火墙和应用层交换机的核心部件,不仅检查数据分组的头部信息,而且检查数据分组的有效载荷。由于正则表达式具有丰富和灵活的表达能力,目前主流的 NIDPS,例如 Snort[3]、Bro[4]、TippingPoint[5]、Cisco[6]广泛采用正则表达式匹配算法进行DPI操作。
三态内容可寻址存储器(TCAM, ternary content addressable memory)是一种快速并行查找的专门硬件。TCAM在一个时钟周期内并行查找所有表项,返回与关键字匹配的第一条表项的地址。TCAM具备三态表示特性,即TCAM表项可存储0、1和“*”,其中“*”表示无关位,可以匹配0或1。在网络处理应用中,TCAM通常与静态随机存储器(SRAM,static random access memory)结合在一起使用,在关键字查找匹配成功后,TCAM将匹配的表项地址发送到SRAM,输出SRAM中保存的相应信息。与TCAM相比,SRAM的存储空间大且能耗低。
近年来,研究者提出了多种基于TCAM的正则表达式匹配算法[7~9],实现线速 DPI。基于 TCAM的正则表达式匹配算法采用 TCAM 表示确定型有限自动机(DFA, deterministic finite automaton),即将状态迁移表的每条状态迁移边存储在一条TCAM表项中,每条表项由TCAM和SRAM两部分组成:源状态和输入字符存储在TCAM部分,目的状态及其他相关信息存储在与TCAM部分对应的 SRAM部分。基于TCAM的正则表达式匹配算法的查找过程如下:首先,将当前状态和输入字符组合成一个关键字,在TCAM中查找与该关键字匹配的表项;然后,根据匹配的表项地址,访问相应的SRAM部分,获取迁移的目的状态;最后,将目的状态作为当前状态,读入下一个输入字符,重复执行相似的TCAM查找,直至输入字符结束。
已有基于 TCAM 的正则表达式匹配算法主要关注减少TCAM存储开销,很少关注减少TCAM能耗。TCAM虽然匹配查找速率快,但是存在能耗高等缺点。在正则表达式匹配中,导致TCAM高能耗的原因是:给定一个查找的关键字(即当前状态和输入字符),TCAM将该关键字与TCAM中存储的所有迁移边表项进行并行比较。例如,存储空间大小为18 MB的TCAM一次查找操作所需能耗高达15 W[10],这将导致嵌入TCAM芯片的路由器、交换机或者其他硬件设备能耗过载。同时,随着网络应用的发展,网络攻击和应用日益复杂化,特征规则集条数不断增多且描述越来越复杂,存储DFA所需的 TCAM 存储空间也越来越大,从而导致TCAM能耗开销进一步提高。
本文提出一种基于字符索引的正则表达式匹配算法,减少TCAM的能耗。该算法的核心思想是:将TCAM分为索引块和存储块;DFA的字母表存储在TCAM索引块中,每个字符的索引范围存储在对应的 SRAM 中;状态迁移边的源状态存储在TCAM 存储块中,目的状态存储在对应的 SRAM中。该算法的匹配查找过程如下:首先,在TCAM索引块中查找当前的输入字符,在对应的SRAM中获取相应的索引范围;然后,根据索引范围启动对应的TCAM存储块,匹配当前状态,在SRAM中获取迁移的目的状态。
本文的主要贡献是:1)提出了基于字符索引的DFA(CIDFA, character-indexed DFA),减少匹配时激活的TCAM块数,降低TCAM能耗;2)针对Snort和 Bro特征规则集开展实验,结果表明,与DFA相比,CIDFA在 TCAM 能耗上平均减少了92.7%,在 TCAM 存储空间开销上平均减少了32.0%,在吞吐量上平均提高了57.9%。
2 相关工作
DPI技术的核心是正则表达式匹配算法,基于硬件的正则表达式匹配算法主要从压缩存储空间等方面开展研究。基于FPGA的算法[11~14]实现了非确定性有限自动机(NFA, nondeterministic finite automata),基于ASIC的算法[15~18]则实现了DFA。Kumar等人[15,16]提出了基于D2FA的正则表达式匹配算法,压缩了 DFA的迁移边,Smith等人[19,20]提出了基于 XFA的正则表达式匹配算法,压缩了DFA的状态。在基于TCAM的算法方面,Meiners等人[8]提出了共享迁移边、融合状态迁移表等优化算法压缩了DFA的存储空间,将DFA实现在较小的TCAM片上,Peng等人[9]利用NFA和DFA结构上的关联,提出了链式DFA压缩算法,保证匹配速度的同时,压缩了DFA的状态空间。在数据分组分类领域,Meiners等人[21~23]提出了多种TCAM表项压缩算法,降低TCAM的存储空间开销。
TCAM具有查找速度快、存储空间小等特性,且能耗与存储空间成正比,在部署大规模设备的网络环境中,如何降低TCAM能耗成为研究热点。在IP查找和数据分组分类领域,研究者提出了多种低能耗的TCAM方案,Zane等人[24]提出了适用于IP查找的 CoolCAM,将路由表拆分成多个子表,通过将IP地址映射到路由表的一个子表,缩小查找范围。Spitznagel等人[25]改进了CoolCAM的结构,提出了适用于数据分组分类的Extended TCAM,将一个索引过滤器与多个 TCAM 存储块相连,限制TCAM查找过程中激活的TCAM块数。Ma等人[10]提出了SmartPC,将源IP地址和目的IP地址组成的地址对作为预分类器,数据分类器中的规则按照地址对的范围,启发式地存储在不同的 TCAM 块中,且每条规则仅存储在一个TCAM块中。SmartPC仅需激活预分类器和部分TCAM块,即可完成规则匹配。SmartPC在能耗上平均减少了88%,索引开销小于TCAM存储空间的4%,是目前所知最优的低能耗分组分类算法。
与上述低能耗TCAM方案不同,本文第一次提出基于TCAM的低能耗正则表达式匹配算法。本文的方法将TCAM分为索引块和存储块,DFA的字母表存储在TCAM索引块中,源状态存储在TCAM存储块中。匹配查找过程时,首先在TCAM索引块中查找当前读入的字符,根据SRAM中返回的索引范围,启动对应的TCAM存储块,完成查找。本文的方法不仅降低TCAM能耗,而且减少DFA所需的存储空间,同时提高匹配吞吐量。
3 基于字符索引的正则表达式匹配算法
3.1 基于TCAM的正则表达式匹配
对于给定的特征规则集,在TCAM上实现正则表达式匹配的步骤如下:首先,构造特征规则集的DFA;然后,构建DFA的TCAM表,即将DFA的每条状态迁移边存储在一条TCAM表项中。每条表项由TCAM和SRAM两部分组成:源状态和输入字符存储在TCAM部分,目的状态存储在与TCAM部分对应的SRAM部分。该算法的匹配查找过程如下:首先,将当前状态和输入字符组合成一个关键字,启动TCAM的全部表项查找该关键字,返回与该关键字匹配的第一条表项的地址;然后,根据匹配表项的地址,获取SRAM中存储的目的状态;最后,将目的状态作为当前状态,读入下一个输入字符,重复执行相似的 TCAM 查找,直至输入字符结束。
图 1给出了特征规则集{.*ab.*c}的 DFA和TCAM表,图1(a)中,初始状态为0,匹配状态为3,“[^]”表示非字符子集,[^ab]表示除了a和b以外的其他输入字符。图1(b)中,TCAM表的表项总数与DFA的迁移边条数相同,源状态和目的状态对应状态迁移表中状态的二进制编码,输入字符为三态编码,特征规则集中出现的输入字符为该字符的二进制 ASCII码,其他字符用“********”表示,“********”可匹配除特征规则集中字符之外的任意输入字符。
3.2 TCAM分块存储和字符索引
TCAM是分块存储的,每个TCAM块中包含了固定数目的TCAM表项。TCAM提供部分激活的机制,即查找过程中可以仅启动TCAM中的部分TCAM 块,而不必启动整个 TCAM。利用 TCAM部分激活机制的前提是:必须保证在激活的少数TCAM块中进行准确无误的查找。本文通过字符索引达到这一目的。

图1 特征规则集{.*ab.*c}的DFA和TCAM表
算法1给出了TCAM分块存储和构建字符索引的伪代码。其中,TransitionTable表示特征规则集的状态迁移表,TCAMTable表示特征规则集对应的TCAM表,StorBlock表示存储块,IndexBlock表示索引块,blockSize表示每个 TCAM 块的大小。第1)~3)行代码是由状态迁移表构建TCAM表的步骤,即将状态迁移表的每条状态迁移边保存在 TCAM表中,每条迁移边由三元组成:源状态srcID、输入字符input和目的状态destID。第4)~10)行代码为构建存储块的步骤,首先,将TCAM表中的表项按照输入字符升序排列,计算输入字符相同的TCAM表项数,赋值给变量minStorEntryNum,根据TCAM块的大小,计算每个输入字符所需的存储块数,赋值给变量storBlockNum;然后,将srcID和destID组合为存储块表项,按照TCAM块的大小构建存储块。由于storBlockNum存储块中包含的表项总数大于或等于minStorEntryNum,故在最后一个存储块中可能存在未使用的TCAM表项,本文采用无关位(“*”)填满这些表项,保证TCAM中没有空白的表项。第11)~15)行代码表示构建索引块的步骤,首先,将storBlockNum个存储块的编号storBlockID存储在每个输入字符input的索引范围indexRange中;然后,按照TCAM块的大小构建索引块。
算法1 BlockOrganized(TransitionTable)
1) for eachtransitioninTransitionTabledo
2)TCAMTablePushBack (srcID,input,destID);
3) end for
4) for eachentryinTCAMTabledo
5) Sort(entryinascending order ofinput);
6)minStorEntryNum= Count(entrywith sameinput);
7)storBlockNum=Ceil(minStorEntryNum/block-Size);
8)StorEntryPushBack(srcID,destID);
9) end for
10)StorBlock= Partition(StorEntrysrcID,block-Size);
11) for eachinputinalphabetTabledo
12)indexRangeInsert(storBlockIDaccording tostorBlockNum);
13)IndexEntryPushBack(input,indexRange);
14) end for
15)IndexBlock= Partition (IndexEntryinput,blockSize)
图2给出了图1应用本文算法后的结构示意,其中, TCAM块的大小为4,TCAM索引块保存TCAM 存储块编号的二进制编码,用于指示每个字符对应的存储块范围;TCAM 存储块保存源状态的二进制编码,对应的SRAM部分保存目的状态的二进制编码。

图2 特征规则集{.*ab.*c}的分块存储和字符索引
基于字符索引的正则表达式匹配算法的查找过程如下:首先,在TCAM索引块中查找当前的输入字符,返回SRAM中的存储块编号;然后,根据存储块编号启动对应的TCAM存储块,匹配当前状态,在SRAM中获取迁移的目的状态;最后,将目的状态作为当前状态,读入下一个输入字符,重复执行相似的TCAM查找,直至输入字符结束。
比较图 2和图 1可知,本文的算法将基于TCAM的正则表达式匹配分为2个阶段:第1个阶段查找TCAM索引块,第2个阶段查找TCAM存储块。本文的算法在能耗、存储空间、吞吐量等重要指标上的变化将在下一节汇总详细讨论。
4 实验评估
在正则表达式处理软件[26]的基础上,本文采用C/C++设计实现了DFA和CIDFA,并运行在CPU为Intel Xeon X5506、内存为16 GB的计算机上。在软件模拟实验中,本文采用 TCAM 仿真工具[27]模拟DFA和CIDFA的TCAM能耗、存储空间开销和吞吐量等性能指标。
4.1 实验方法
本文处理的特征规则集来自于Snort和Bro特征库,其中,R1~R9取自Snort特征库, R10取自Bro特征库。特征规则集的参数如表1所示,其中,通配符表达式的主要形式为{.*{子表达式}.*{子表达式}},“.*”表示匹配任意数目的输入字符。计数器表达式的主要形式为{[c1…cn]{n}},“[c1…cn]”表示匹配输入字符为“c1”至“cn”中的任意一个,“{n}”表示重复出现n次。由特征规则集生成DFA时,通配符表达式容易引起DFA状态空间急剧增大[20],导致存储自动机所需的TCAM空间开销增加,能耗也随之增大。
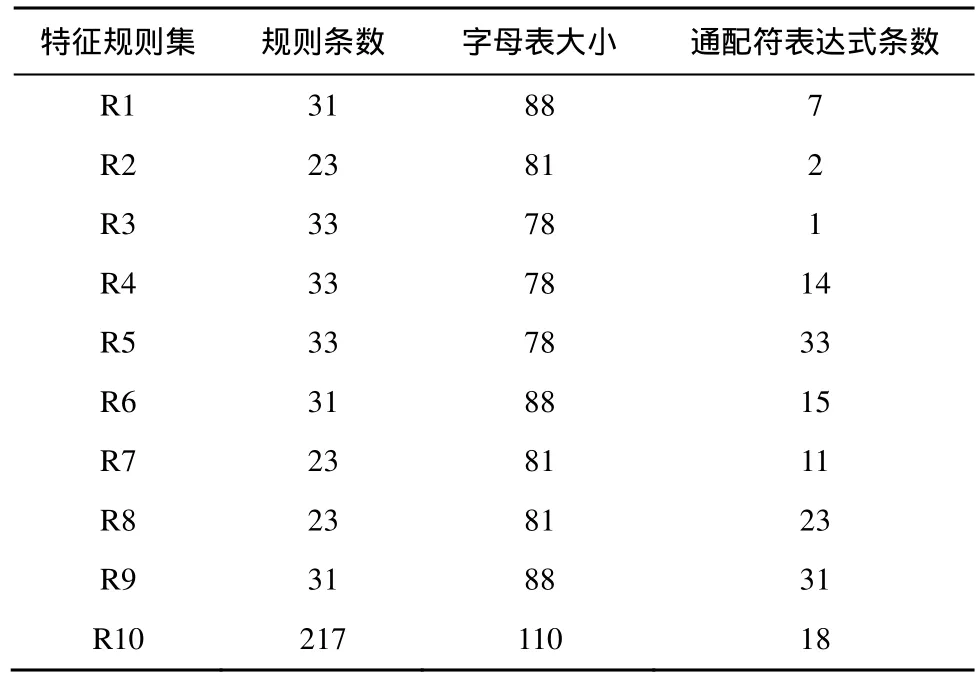
表1 特征规则集的参数统计
本文采用的特征规则集中,通配符表达式条数占规则总数的1.3%~42.3%,DFA状态的规模为5 000~100 000个,存储状态迁移表的TCAM包含400 000~8 000 000条表项,能够模拟不同规模的DFA在本文算法下性能的改变。
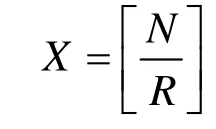
TCAM存储空间的大小为TCAM宽度与表项数的乘积,其中,表项数由 TCAM 块的大小与TCAM块数的乘积决定。DFA占用的TCAM宽度为源状态和输入字符占用的比特数之和。本文采用的特征规则集的字母表为ASCII码,输入字符占用的比特数为8 bit,对于状态数为S的DFA,源状态占用的比特数为,故 DFA占用的 TCAM 宽度为(W+8)bit,其 TCAM 存储空间开销为W=[lbS]。对于CIDFA,索引块的TCAM宽度为输入字符的比特数,即8 bit,存储块的TCAM宽度为源状态占用的比特数,即Wbit,CIDFA的TCAM存储空间开销S2=8RY1+WRY2。
本文以吞吐量衡量算法的匹配速率。吞吐量为每次读入字符的比特数与TCAM查找时延之商,对于单步长正则表达式匹配算法,每次读入一个ASCII字符,为 8 bit。假定上述X、Y1和Y2个 TCAM块的查找时延分别为Dx、Dy1和Dy2,DFA的吞吐量为8/Dx,CIDFA的吞吐量为8/(Dy1+Dy2)。
4.2 能耗
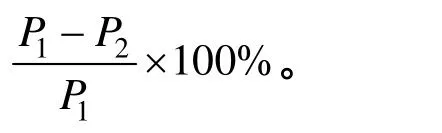
图3给出了10个特征规则集在TCAM能耗上减少的比例。不同 TCAM 块大小下,CIDFA在TCAM能耗上减少的比例为78.8%~98.5%,平均减少比例为92.7%。当TCAM块大小为32时,CIDFA在TCAM能耗上减少的比例最小,为8.8%~84.8%,平均减少比例为80.3%。随着TCAM块大小的增加,CIDFA在TCAM能耗上减少的比例不断提高,当TCAM块大小为1 024时,CIDFA在TCAM能耗上减少的比例达到最大,为98.0%~98.5%,平均减少比例为98.2%。
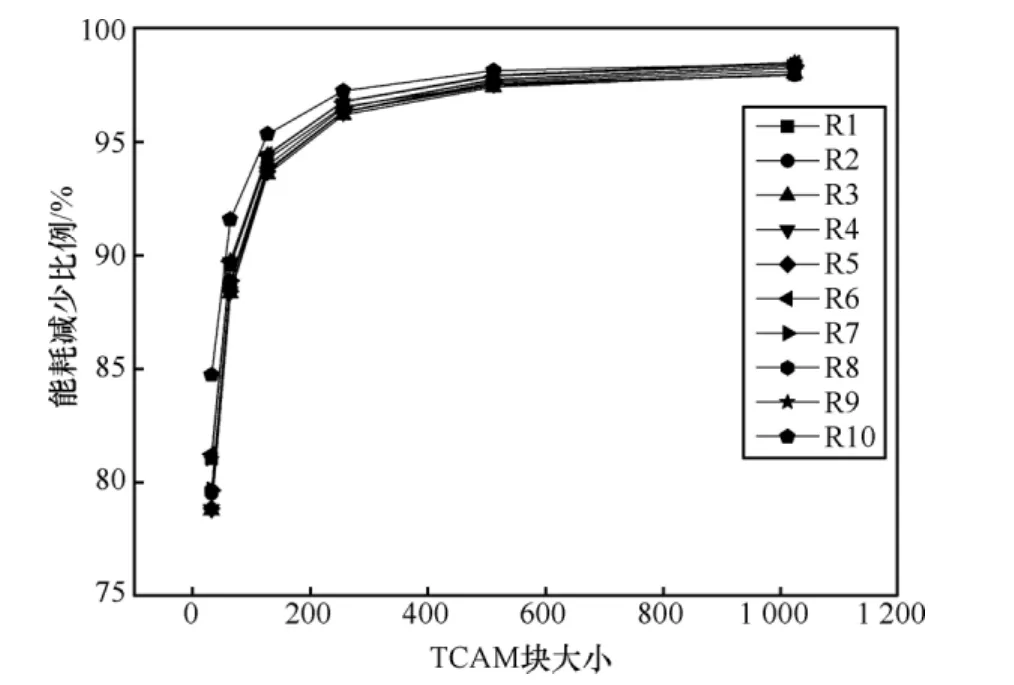
图3 能耗减少比例
图4给出了当TCAM块大小为64、256和1 024时,DFA与 CIDFA的 TCAM能耗比较。不同TCAM 块大小下,同一特征规则集对应的 DFA的TCAM能耗基本一致;随着TCAM块大小的增加,同一特征规则集对应的CIDFA的TCAM能耗不断减少。
4.3 存储空间开销和吞吐量
本文采用 4.1节中介绍的方法计算 DFA和CIDFA的TCAM存储空间开销和吞吐量。
在存储空间方面,DFA的TCAM片上保存状态迁移边的源状态和输入字符。CIDFA额外开销了一部分TCAM空间作为索引块,但是,TCAM片上仅保存状态迁移边的源状态。
表2给出了DFA和CIDFA的TCAM存储空间开销比较。与DFA相比,CIDFA在TCAM存储空间开销上平均减少了 32.0%。对于不同大小的TCAM块,同一特征规则集对应的DFA和CIDFA的TCAM存储空间开销分别相同。
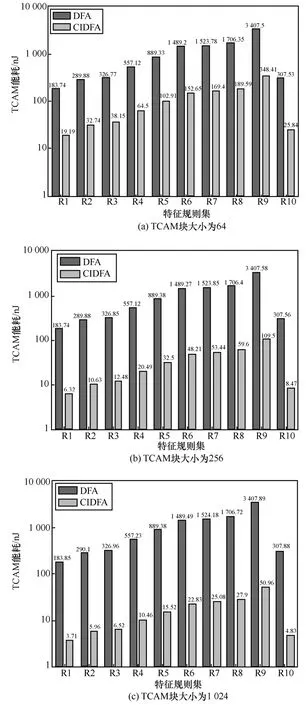
图4 不同TCAM块大小下,DFA与CIDFA的TCAM能耗比较
吞吐量决定了算法的匹配速率,由于 DFA和CIDFA每次匹配操作处理的比特数相同,故算法的吞吐量由匹配时的查找时延决定。DFA的查找时延为启动全部TCAM块完成查找操作的时间,CIDFA的查找时延为启动TCAM索引块和TCAM存储块完成查找的时间之和。

表2 DFA和CIDFA的TCAM存储空间开销比较
表3给出了DFA和CIDFA的吞吐量比较。与DFA相比,CIDFA在吞吐量上平均提高了57.9%。对于不同大小的TCAM块,同一特征规则集对应的DFA吞吐量相同;随着 TCAM 块大小的增加,同一特征规则集对应的CIDFA吞吐量不断下降。当TCAM块大小为32,CIDFA的吞吐量达到最大,比DFA提高50.3%~99.5%;当TCAM块大小为1 024时,CIDFA的吞吐量最低,比DFA提高36.6%~ 70.9%。
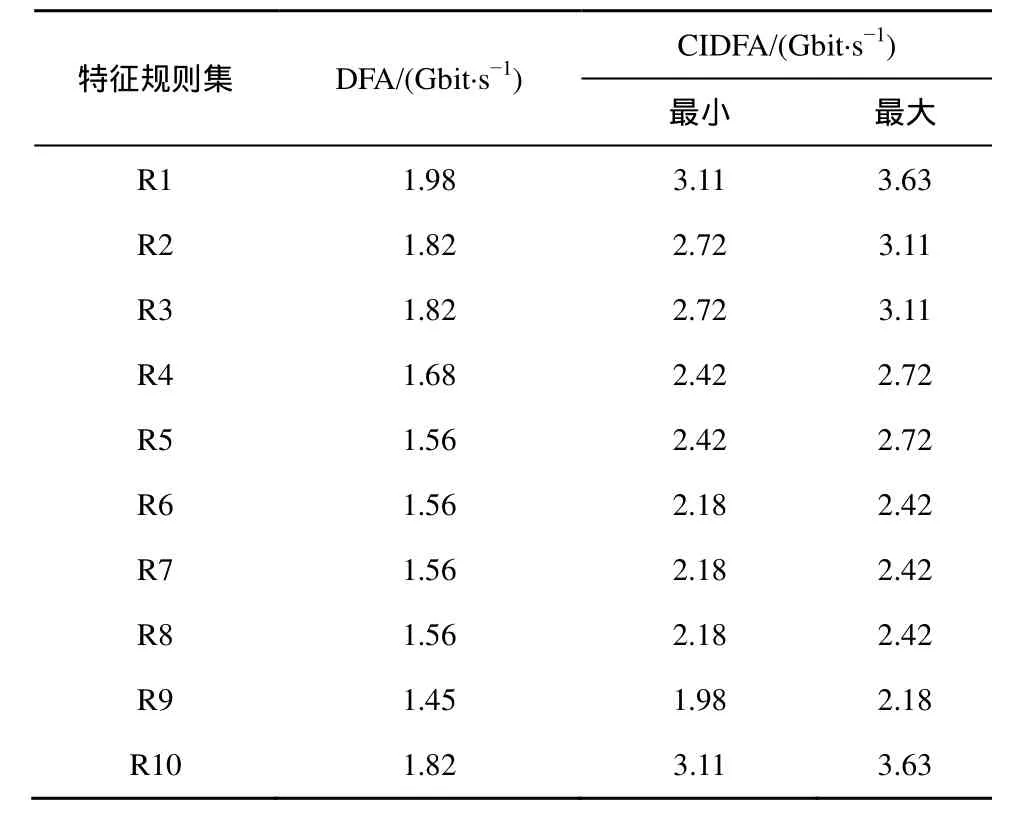
表3 DFA和CIDFA的吞吐量比较
5 结束语
本文提出了一种基于字符索引的正则表达式匹配算法,该算法将TCAM分为索引块和存储块,其中,索引块中保存DFA的字母表,存储块中保存DFA的源状态。匹配时,首先在索引块中查找当前读入的字符,然后,仅启动与读入字符对应的部分存储块,即可完成查找操作。该算法能够避免启动全部的存储块,从而达到降低能耗的目的。
针对实际特征规则集的实验表明:与 DFA相比,CIDFA在能耗上平均减少了92.7%,在存储空间平均开销上平均减少了32.0%,在吞吐量上平均提高了57.9%。因此,CIDFA是一种低能耗的高效TCAM 方案,不仅确保查找速率,而且显著降低TCAM能耗和存储空间。
本文的算法可应用于数据中心网络中大规模流量识别技术,有助于减少数据中心网络中成千上万台交换机的能耗,下一步的研究方向是实现基于TCAM的多步长正则表达式匹配算法。
[1] PAXSON V, ASANOVIC K, DHARMAPURIKAR S,et al.Rethinking hardware support for network analysis and intrusion prevention[A].Proceeding of USENIX Workshop on Hot Topics in Security[C]. Vancouver, Canada, 2006.
[2] SOMMER R, PAXSON V. Enhancing byteleve network intrusion detection signatures with context[A]. Proceeding of ACM Conference on Computer and Communications security[C]. Washington, DC, USA,2003, 262- 271.
[3] Snort::rules[EB/OL]. http://www.snort.org/start/rules, 2013-12-01.
[4] The bro network security monitor[EB/OL]. http:// bro-ids.org, 2013.
[5] HP TippingPoint S1200N IPS A7500 module[EB/OL]. http://h17007.www1.hp.com/us/en/products/network-security/HP_TippingPoint_S1200N_IPS_A7500_Module/index.aspx?jumpid=reg_r1002_usen,2013-12-01.
[6] Intrusion prevention system(IPS)-Cisco systems[EB/OL]. http://www.cisco.com/en/US/products/ps5729/Products_Sub_Category_Home.html,2013-12-05.
[7] YU F, KATZ R, LAKSHMAN T V. Gigabit rate packet patternmatching using TCAM[A]. Proceeding of IEEE International Conference on Network Protocols[C]. Berlin, Germany, 2004.
[8] MEINERS C R, PATEL J, NORIGE E,et al. Fast regular expression matching using small TCAMs for network intrusion detection and prevention systems[A]. Proceeding of the 19th USENIX Security Symposium[C]. Washington, DC, USA, 2010, 8.
[9] PENG K, TANG S, CHEN M,et al. Chain-based DFA deflation for fast and scalable regular expression matching using TCAM[A]. Proceeding of ACM/IEEE Symposium on Architectures for Networking and Communications Systems[C]. Brooklyn, NY, USA, 2011.
[10] MA Y, BANERJEE S. A smart pre-classifier to reduce power consumption of TCAMS for multi-dimensional packet classification[A].Proceeding of ACM Conference of the Special Interest Group on Data Communication[C]. Helsinki, Finland, 2012.
[11] SIDHU R, PRASANNA V K. Fast regular expression matching using FPGA[A]. Proceeding of IEEE International Symposium on Field-Programmable Custom Computing Machines[C]. Rohnert Park,CA, USA, 2001.
[12] CLARK C R, SCHIMMEL D E. Scalable pattern matching on high-speed networks[A]. Proceeding of IEEE International Symposium on Field-Programmable Custom Computing Machines[C]. Napa Valley, CA, USA, 2004.
[13] SOURDIS I, PNEVMATIKATOS D. Pre-decoded CAMs for efficient and high-speed NIDS pattern matching[A]. Proceeding of IEEE International Symposium on Field-Programmable Custom Computing Machines[C]. Napa Valley, CA, USA, 2004.
[14] MOSCOLA J, LOCKWOOD J, LOUI R P,et al. Implementation of a content-scanning module for an internet firewall[A]. Proceeding of IEEE International Symposium on Field-Programmable Custom Computing Machines[C]. Napa Valley, CA, USA, 2003.
[15] KUMAR S, DHARMAPURIKAR S, YU F,et al. Algorithms to accelerate multiple regular expressions matching for deep packet inspection[A]. Proceeding of ACM Conference of the Special Interest Group on Data Communication[C]. Pisa, Italy, 2006.
[16] KUMAR S, TURNER J, WILLIAMS J. Advanced algorithms for fast and scalable deep packet inspection[A]. Proceeding of ACM/IEEE Symposium on Architectures for Networking and Communications Systems[C]. San Jose, CA, USA, 2006.
[17] BECCHI M, CADAMI S. Memory-efficient regular expression search using stae merging[A]. Proceeding of IEEE International Conference on Computer Communications[C]. Anchorage, Alaska, USA, 2007.
[18] BECCHI M, CROWLEY P. An improved algorithm to accelerate regular expression evaluation[A]. Proceeding of ACM/IEEE Symposium on Architectures for Networking and Communications Systems[C]. San Jose, CA, USA, 2008.
[19] SMITH R, ESTAN C, JHA S. XFA: faster signature matching with extended automata[A]. Proceeding of IEEE Symposium on Security and Privacy[C]. Oakland, CA, USA, 2008.
[20] SMITH R, ESTAN C, JHA S,et al. Deflating the big bang: fast and scalable deep packet inspection with extended finite automata[A].Proceeding of ACM Conference of the Special Interest Group on Data Communication[C]. Seattle, WA, USA, 2008.
[21] MEINERS C R, LIU A X, TORNG E. TCAM Razor: a systematic approach towards minimizing packet classifiers in TCAMs[A]. Proceeding of IEEE International Conference on Network Protocols[C].Beijing, China, 2007.
[22] LIU A X, MEINERS C R, ZHOU Y. All-match based complete redundancy removal for packet classifiers in TCAMs[A]. Proceeding of IEEE International Conference on Computer Communications[C].Phoenix, AZ, USA, 2008.
[23] MEINERS C R, LIU A X, TORNG E. Bit weaving: a non-prefix approach to compressing packet classifiers in TCAMs[A]. Proceeding of IEEE International Conference on Network Protocols[C]. Princeton,NJ, USA, 2009.
[24] ZANE F, NARLIKAR G, BASU A. CoolCAMs: power-efficient TCAMs for forwarding engines[A]. Proceeding of IEEE International Conference on Computer Communications[C]. San Francisco,USA, 2003.
[25] SPITZNAGEL E, TAYLOR D, TURNER J. Packet classification using extended TCAMs[A]. Proceeding of IEEE International Conference on Network Protocols[C]. Atlanta, Georgia, USA, 2003.
[26] Regular expression processor[EB/OL].http://regex.wustl.edu/index.php/Main_Page, 2013-12-01.
[27] AGRAWAL B, SHERWOOD T. Modeling TCAM power for next generation network devices[A]. Proceeding of IEEE International Symposium on Performance Analysis of Systems and Software[C].Austin, TX, USA, 2006.
