一种改进的最好优先搜索策略算法
2014-01-02余兆钗傅化权
余兆钗 傅化权
(闽江学院计算机科学系,福建 福州 350108)
0 引言
我国域名总数为1844万个,其中“.CN”域名总数较去年同期增长44.2%,达到1083万,在中国域名总数中占比达58.7%,我国网站总数为320万个,较去年同期增长19.4%。除了互联网中新的网页不断增加,互联网中原有的网页也会因为各种原因被删除,有研究指出:50%网页的平均生命周期大约为50天,互联网中每天都新的网页增加,每天都网页被删除。面对海量的网络资源,如何加快搜索引擎信息的更新频率,成了重要的课题。
网络爬虫是搜索引擎的重要组成部分,搜索引擎存储的信息资源就是由网络爬虫在海量的互联网中搜索下载的,加快网络爬虫的搜索速度,是加快搜索引擎信息更新的有效手段。
1 基于内容评价最好优先搜索策略
(1)页面信息提取。网络爬虫从主题种子集队列中,挑选一个页面价值度最高的URL,网络爬虫访问该URL页面并下载页面,保存在本地。
(2)页面解析过滤。对下载的页面,首先去除页面中的javascript脚本语言、CSS样式;然后去除网页中的HTML标签,得到页面的正文文本。同时提取页面中超链接URL。
(3)页面分词。页面得到正文文本后,计算正文文本相邻字的相似度。对于相关度大于阈值,将其划分出来,归类为词语;小于阈值的,另作其他处理。
(4)页面关键字提取。分词得到的页面词语,首先对它们做预处理,过滤词语中是虚词、人称代词、叠词、数量、连词、介词、语句助词等对页面内容无关的词语。依据词语在页面正文中所占比例按照大小排序,去除一定数量比例大的词语和比例小的词语,剩余的词语选取排列在靠前的作为关键字。
(5)页面关键字加权重。对于选出的关键字进行加权计算,一般采用采用TF-IDF词频统计方法。
(6)页面主题相关度计算。页面关键字加权计算完以后,再根据向量空间模型(VSM)进行页面与主题的相关度计算。如果相关度高,就加入到搜索队列中,作为以后搜索到对象;相关度低或不相关,丢弃这个网页。
2 改进的最好优先搜索策略
网站开发者在开发一个网站时,通常会根据网页的主题,为每个网页划分各个目录,这样每个目录存放的网页主题都是有一定相关性的。比如新浪新闻网站的目录结构,在新浪新闻网目录下划分了国内新闻、国际新闻、社会新闻、新闻评论等子目录,分别管理着不同模块的新闻信息。子目录孙目录下的网页主题,相关性更强。因此我们利用这一特点,对最好优先搜索策略做了改进。
根据网站的结构,如果一个网页的URL是另一个网页URL的网站目录,例如:新浪新闻 http://news.sina.com.cn/是新浪国内新闻 http://news.sina.com.cn/China/的目录,称新浪新闻 http://news.sina.com.cn/为上行链,称新浪国内新闻 http://news.sina.com.cn/China/下行链。 同时再为每个网页的URL分别设置父链、祖先链。如果搜索的网页有上行链,则设置该URL的祖先链为这个网页的上行链,否则为空;父链则是用于存放提取这个URL的网页的URL。
永州市涔天河库区位于湘江流域上游,是永州地区重要的水源地,其流域控制面积为2423平方公里,多年平均产水量26亿立方米,正常蓄水位254.26 m,总库容1.05亿立方米。该工程是湘江流域上游龙头水利工程,扩建后将形成湖南省最大的灌区。涔天河库区扩建工程可谓“牵一发而动全身”,不仅占用了大量的土地资源,而且对周围环境也产生了巨大的影响。水库扩建工程浩大,大量人力物力的投入,以及对区域物质能量的扰动,使流域生态系统的稳定性受到一定程度的影响。
最好优先搜索策略改进的主要思想:当网络爬虫在进行最好优先搜索时,如果遇到一个与主题相关的网站,就将这个网站内的所有具有相同目录的网页直接下载,并将这些URL放到搜索队列中,作为以后搜索到对象,跳过对这些URL进行网页相关度计算。
最好优先搜索策略改进算法流程图如图1所示,描述如下:
(1)将原始URL集加入到网络爬虫搜索队列中,运行网络爬虫。
(2)在搜索队列中提取一个请求路径A,搜索下载网页,提取A网页中新的请求路径B。
(3)对比请求路径,将请求路径B和A的祖先链比较,如果请求路径B的开头为A的祖先链,则标记B的祖先链为A的祖先链且B的父链为A,加入到搜索队列中,跳转到步骤(2);否则比较A的父链和请求路径B进行比较;如果请求路径B的开头为A的父链,B的祖先链为A的父链且B的父链也A,加入到搜索队列中,跳转到步骤(2),否则将请求路径B和A比较,如果B的开头为A,则B的祖先链为A且B的父亲链为A,跳转到步骤(2),否则标记A的父链的B,祖先链为空,跳转到步骤(4)。
(4)对新提取出请求路径URL,下载网页,对网页进行预处理,获取纯文本。
(5)纯文本分词,提取关键字作为网页的特征项。
(6)特征项的权重计算,计算网页中的特征项的权重。
(7)相似度计算,利用向量空间模型计算网页与主题之间的相似度。如果相似度大于或等于阈值f,则网页与主题相关,加入到搜索队列中;反之,丢弃这个URL。
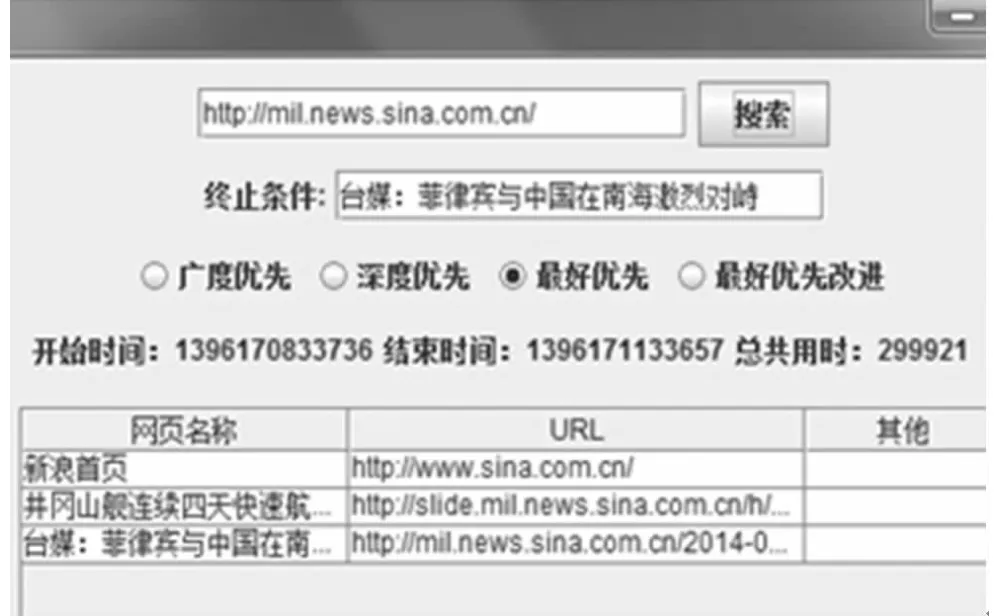
图1 最好优先搜索策略搜索结果
3 实验结果与分析
本实验的硬件环境:CPU是 Pentium Dual-Core E6700,内存4GB。
软件环境:操作系统Windows XP,变成软件Eclipse V3.5。

图2 最好优先搜索策略改进后的搜索结果
实验内容是在给定一个新浪军事新闻 :http://mil.news.sina.com.cn/的请求路径,并指定其终止的条件是:“台媒:菲律宾与中国在南海激烈对峙”,分别利用改进前与改进后的算法进行搜索,然后计算运行的时间。图1是改进前的算法用时299921毫秒,在图2是改进后算法的用时为233676毫秒。可以看出改进后的算法明显提高了搜索速度。
4 结论
由于网站开发过程中,大部分开发人员都会根据主题为每个网页划分各个目录,每个目录存放的网页主题都是相似的,因此在网络爬虫搜索过程中,碰到目录相同的网页,直接放入搜索队列中,这样省去了这些网页的分析评价时间,从而提高爬虫的搜索效率。根据这种思路对最好优先搜索算法做了改进,并进行了实验验证,实验结果表明改进后的算法明显提高了搜索速度。
[1]李耀华,杨海燕.论网络爬虫搜索策略[J].山西广播电视大学学报,2013(2):48-50.
[2]S.E.Robertson.Theprobability ranking principle in IR[J].Journal of Documentation,1977,33:294-304.
